







本文的概念和结构部分摘自循环神经网络惊人的有效性(上),代码部分来自minimal character-level RNN language model in Python/numpy 我对代码做了详细的注释
循环神经网络
序列 普通神经网络和卷积神经网络的一个显而易见的局限就是他们的API都过于限制:他们接收一个固定尺寸的向量作为输入(比如一张图像),并且产生一个固定尺寸的向量作为输出(比如针对不同分类的概率)。不仅如此,这些模型甚至对于上述映射的演算操作的步骤也是固定的(比如模型中的层数)。RNN之所以如此让人兴奋,其核心原因在于其允许我们对向量的序列进行操作:输入可以是序列,输出也可以是序列,在最一般化的情况下输入输出都可以是序列。下面是一些直观的例子:
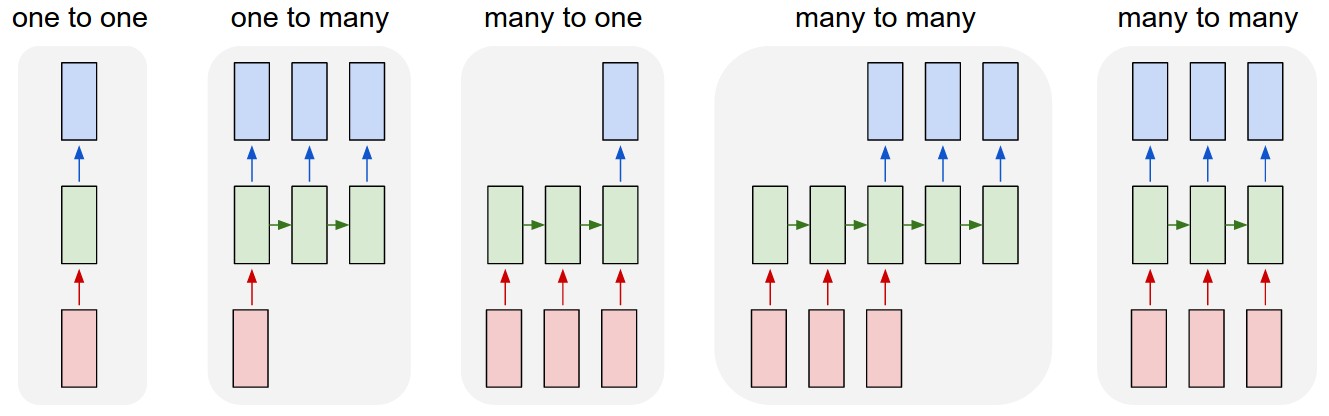
上图中每个正方形代表一个向量,箭头代表函数(比如矩阵乘法)。输入向量是红色,输出向量是蓝色,绿色向量装的是RNN的状态(马上具体介绍)。从左至右为:
非RNN的普通过程,从固定尺寸的输入到固定尺寸的输出(比如图像分类)。
输出是序列(例如图像标注:输入是一张图像,输出是单词的序列)。
输入是序列(例如情绪分析:输入是一个句子,输出是对句子属于正面还是负面情绪的分类)。
输入输出都是序列(比如机器翻译:RNN输入一个英文句子输出一个法文句子)。
同步的输入输出序列(比如视频分类中,我们将对视频的每一帧都打标签)。
注意在每个案例中都没有对序列的长度做出预先规定,这是因为循环变换(绿色部分)是固定的,我们想用几次就用几次。
如你期望的那样,相较于那些从一开始连计算步骤的都定下的固定网络,序列体制的操作要强大得多。并且对于那些和我们一样希望构建一个更加智能的系统的人来说,这样的网络也更有吸引力。我们后面还会看到,RNN将其输入向量、状态向量和一个固定(可学习的)函数结合起来生成一个新的状态向量。在程序的语境中,这可以理解为运行一个具有某些输入和内部变量的固定程序。从这个角度看,RNN本质上就是在描述程序。实际上RNN是具备图灵完备性的,只要有合适的权重,它们可以模拟任意的程序。然而就像神经网络的通用近似理论一样,你不用过于关注其中细节。实际上,我建议你忘了我刚才说过的话。
如果训练普通神经网络是对函数做最优化,那么训练循环网络就是针对程序做最优化。
无序列也能进行序列化处理。你可能会想,将序列作为输入或输出的情况是相对少见的,但是需要认识到的重要一点是:即使输入或输出是固定尺寸的向量,依然可以使用这个强大的形式体系以序列化的方式对它们进行处理。例如,下图来自于DeepMind的两篇非常不错的论文。左侧动图显示的是一个算法学习到了一个循环网络的策略,该策略能够引导它对图像进行观察;更具体一些,就是它学会了如何从左往右地阅读建筑的门牌号。右边动图显示的是一个循环网络通过学习序列化地向画布上添加颜色,生成了写有数字的图片。

左边:RNN学会如何阅读建筑物门牌号。右边:RNN学会绘出建筑门牌号。
必须理解到的一点就是:即使数据不是序列的形式,仍然可以构建并训练出能够进行序列化处理数据的强大模型。换句话说,你是要让模型学习到一个处理固定尺寸数据的分阶段程序。
RNN的计算。那么RNN到底是如何工作的呢?在其核心,RNN有一个貌似简单的API:它接收输入向量x,返回输出向量y。然而这个输出向量的内容不仅被输入数据影响,而且会收到整个历史输入的影响。写成一个类的话,RNN的API只包含了一个step方法:
- 1
- 2
- 1
- 2
每当step方法被调用的时候,RNN的内部状态就被更新。在最简单情况下,该内部装着仅包含一个内部隐向量 h 。下面是一个普通RNN的step方法的实现:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
上面的代码详细说明了普通RNN的前向传播。该RNN的参数是三个矩阵:W_hh, W_xh, W_hy。隐藏状态self.h被初始化为零向量。np.tanh函数是一个非线性函数,将激活数据挤压到[-1,1]之内。注意代码是如何工作的:在tanh内有两个部分。一个是基于前一个隐藏状态,另一个是基于当前的输入。在numpy中,np.dot是进行矩阵乘法。两个中间变量相加,其结果被tanh处理为一个新的状态向量。如果你更喜欢用数学公式理解,那么公式是这样的:
其中tanh是逐元素进行操作的。
我们使用随机数字来初始化RNN的矩阵,进行大量的训练工作来寻找那些能够产生描述行为的矩阵,使用一些损失函数来衡量描述的行为,这些损失函数代表了根据输入x,你对于某些输出y的偏好。
更深层网络 RNN属于神经网络算法,如果你像叠薄饼一样开始对模型进行重叠来进行深度学习,那么算法的性能会单调上升(如果没出岔子的话)。例如,我们可以像下面代码一样构建一个2层的循环网络:
- 1
- 2
- 1
- 2
换句话说,我们分别有两个RNN:一个RNN接受输入向量,第二个RNN以第一个RNN的输出作为其输入。其实就RNN本身来说,它们并不在乎谁是谁的输入:都是向量的进进出出,都是在反向传播时梯度通过每个模型。
更好的网络。需要简要指明的是在实践中通常使用的是一个稍有不同的算法,这就是我在前面提到过的长短基记忆网络,简称LSTM。LSTM是循环网络的一种特别类型。由于其更加强大的更新方程和更好的动态反向传播机制,它在实践中效果要更好一些。本文不会进行细节介绍,但是在该算法中,所有本文介绍的关于RNN的内容都不会改变,唯一改变的是状态更新(就是self.h=…那行代码)变得更加复杂。从这里开始,我会将术语RNN和LSTM混合使用,但是在本文中的所有实验都是用LSTM完成的。
字母级别的语言模型
现在我们已经理解了RNN是什么,它们何以令人兴奋,以及它们是如何工作的。现在通过一个有趣的应用来更深入地加以体会:我们将利用RNN训练一个字母级别的语言模型。也就是说,给RNN输入巨量的文本,然后让其建模并根据一个序列中的前一个字母,给出下一个字母的概率分布。这样就使得我们能够一个字母一个字母地生成新文本了。
在下面的例子中,假设我们的字母表只由4个字母组成“helo”,然后利用训练序列“hello”训练RNN。该训练序列实际上是由4个训练样本组成:1.当h为上文时,下文字母选择的概率应该是e最高。2.l应该是he的下文。3.l应该是hel文本的下文。4.o应该是hell文本的下文。
具体来说,我们将会把每个字母编码进一个1到k的向量(除对应字母为1外其余为0),然后利用step方法一次一个地将其输入给RNN。随后将观察到4维向量的序列(一个字母一个维度)。我们将这些输出向量理解为RNN关于序列下一个字母预测的信心程度。下面是流程图:
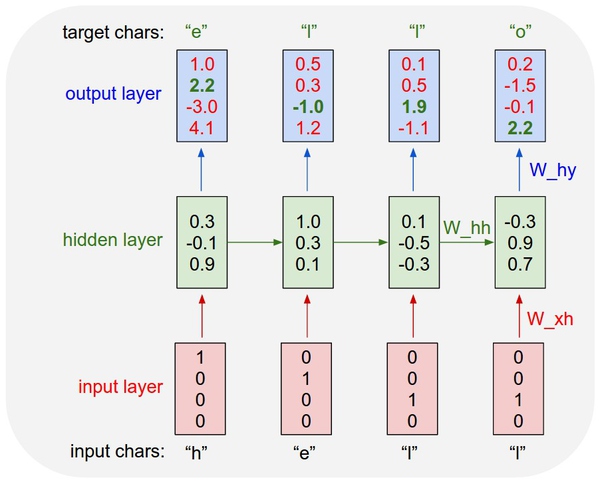
一个RNN的例子:输入输出是4维的层,隐层神经元数量是3个。该流程图展示了使用hell作为输入时,RNN中激活数据前向传播的过程。输出层包含的是RNN关于下一个字母选择的置信度(字母表是helo)。我们希望绿色数字大,红色数字小。
举例如下:在第一步,RNN看到了字母h后,给出下一个字母的置信度分别是h为1,e为2.2,l为-3.0,o为4.1。因为在训练数据(字符串hello)中下一个正确的字母是e,所以我们希望提高它的置信度(绿色)并降低其他字母的置信度(红色)。类似的,在每一步都有一个目标字母,我们希望算法分配给该字母的置信度应该更大。因为RNN包含的整个操作都是可微分的,所以我们可以通过对算法进行反向传播(微积分中链式法则的递归使用)来求得权重调整的正确方向,在正确方向上可以提升正确目标字母的得分(绿色粗体数字)。然后进行参数更新,即在该方向上轻微移动权重。如果我们将同样的数据输入给RNN,在参数更新后将会发现正确字母的得分(比如第一步中的e)将会变高(例如从2.2变成2.3),不正确字母的得分将会降低。重复进行一个过程很多次直到网络收敛,其预测与训练数据连贯一致,总是能正确预测下一个字母。
更技术派的解释是我们对输出向量同步使用标准的Softmax分类器(也叫作交叉熵损失)。使用小批量的随机梯度下降来训练RNN,使用RMSProp或Adam来让参数稳定更新。
注意当字母l第一次输入时,目标字母是l,但第二次的目标是o。因此RNN不能只靠输入数据,必须使用它的循环连接来保持对上下文的跟踪,以此来完成任务。
在测试时,我们向RNN输入一个字母,得到其预测下一个字母的得分分布。我们根据这个分布取出得分最大的字母,然后将其输入给RNN以得到下一个字母。重复这个过程,我们就得到了文本!现在使用不同的数据集训练RNN,看看将会发生什么。
为了更好的进行介绍,我基于教学目的写了代码, 只有100多行















 2258
2258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









