







这是我在组会上讲的文章,当时跟着论文的行文思路来讲的,可惜没能讲得很清楚。现在打算用我自己的思路来介绍这篇文章,希望用尽可能易懂的方法来讲解清楚。也希望通过博客总结,来进一步提升自己的理解。
——致我的第一次组会报告
Image-Based Localization
首先介绍一下什么是Image-Based Localization。随着计算机视觉的发展,现在人们可以利用 SfM(structure from motion) 技术利用场景的图片集合来进行三维重建,得到场景的点云模型。这类软件有几种开源实现,比如 Bundler, VisualSfM。基于图像的定位系统就是利用已知的场景三维模型,通常是点云模型,来对新的图像进行定位,得到拍摄这副图像的相机在三维空间中的位置和朝向。

图1. Imaged-based Localization Standard Pipeline
如上图所示,右边是场景的点云模型的一部分,左上角是查询图像,基于图像的定位就是要求得对应的相机的位置和姿态(点云中红色锥形表示了相机的位置和朝向)。
通常这种定位系统需要离线建立好场景的点云模型,定位的时候,对查询对象首先提取局部特征,通常是 SIFT, 然后需要建立图像的2D特征和点云模型中3D点的对应关系,在得到足够多的2D-3D Matches 之后,利用RANSAC和Pnp 算法,就可以求得相机六个自由度的位置和姿态。
这里的关键是如何寻找到合适的2D-3D匹配关系,通常点云模型中每一个3D还会包含有重建出这个3D点所对应的所有的2D图像特征,一般是通过3D点所包含的2D特征和特性的2D特征的匹配关系,来得到3D点和特性的2D特征的匹配关系,但是在具体寻找匹配关系时,会有很多种思路和策略。
Voting-Based Camera Pose Estimation
介绍了什么是image-based localization之后,下面就开始介绍这篇论文中提到的定位策略。
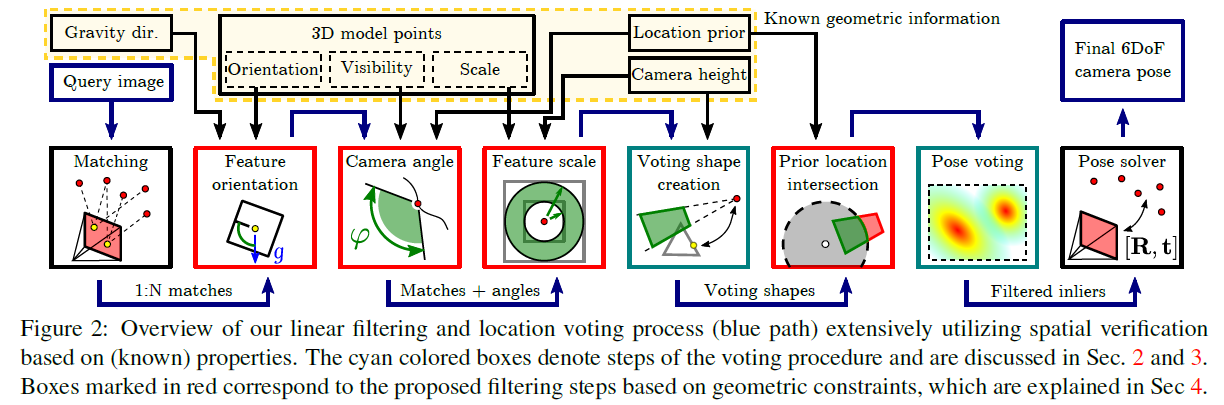
上图是本文中提出的定位流程图,对查询图像,首先得到每个特征一对多的匹配关系,然后把所有这些匹配关系通过一系列的几何滤波,滤除掉大部分错误的匹配关系,然后再构建文章中提出的 Voting Shape,如果有位置先验信息(比如GPS位置),可以进一步约束 Voting Shape。这里对每一个2D-3D匹配关系都可以构建出一个 Voting Shape,类似于Hough voting,对区域进行一个投票,最后票数最多的区域所表示的姿态就认为是真实的相机姿态,然后得到内点,最后对这些内点通过RANSAC和PnP算法,求得最终的姿态。
Find Reliable 2D-to-single-3D Matches VS Find Extended 2D-to-many-3D Matches
传统寻找2D-3D匹配的方法中,需要在数据库2D描述子中寻找查询图像的2D描述子的最近邻(Nearest Neighbor ),一般会找到最近邻和次近邻,然后通过 Iowe’s Ratio Test 来判断这样的匹配是否是一个正确的匹配。Ratio Test 在计算机视觉中特征匹配时用得很多,也很有效。
我把这种策略称为 Find Reliable 2D-to-single-3D Matches ,也就是对于一个查询2D特征,来找到一个可靠的3D点来得到一个2D-3D匹配关系。这是因为后面再计算姿态时是使用的RANSAC来随机采样,如果你的内点率不高的话,RANSAC采样方法很难得到正确的结果。
但是这种 ratio test 有其内在的缺陷性,当场景变得越来越大时,那么数据库中就会有越来越多的三维点和描述子,也就是说描述子空间中的描述子的密度会越来越大。
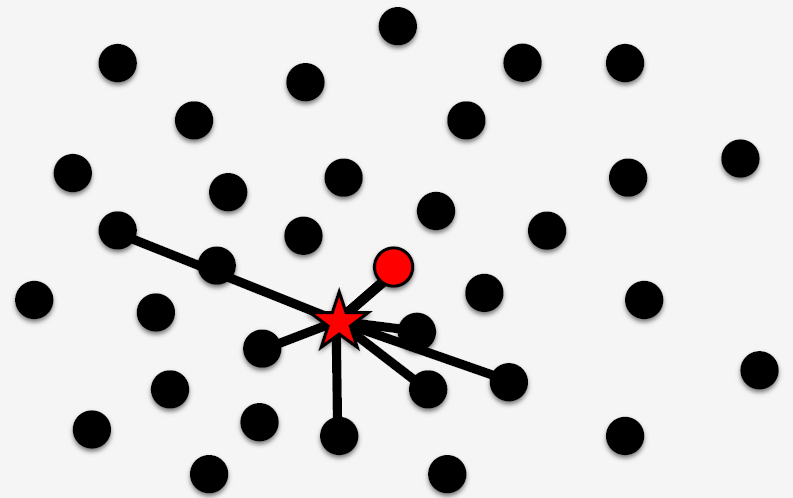
如上图所示,假设对于查询特征(红色五角星)在数据中真实匹配时红色球,但是数据库中还有很多特征也和查询特征很相似,那么这种情况下还使用 ratio test 的话,并不能得到一个理想的匹配结果(要么得不到一个匹配,要么得到错误的匹配关系)。
所以为了解决随着场景增大,使用 ratio test 得不到正确匹配的问题,论文提出要为查询图像的每一个2D特征来找 N 个匹配关系,也就是一对多的匹配关系,然后通过一些几何约束关系来滤除掉明显错误的匹配,通过投票的方式得到相机的位置和姿态。
Assumptions
首先,论文做出了一些必要的假设。
- Assumption 1: The 3D scene model is gravity aligned, and the ground plane is approximated.
- Assumption 2: Given the camera intrinsic calibration K and gravity direction.
- Assumption 3: The height of query camera is close to ground plane within certain interval.
假设2中要求知道相机的内参,同时能知道相机的重力方向,文章中重力方向的获取是通过计算图片的垂直消隐点来得到的。同样假设2中,也要知道重力方向,这样就可以把整个模型的坐标系和重力方向对齐,地平面是通过数据库中相机的位置插值得到的。
这篇论文中提出的这种模型之所以能够work,很大程度上就是因为对场景有很强的先验,对查询相机也有很强的约束在里面。
Reformulate the Pose Estimation Problem
有了上面的假设了之后,就可以把相机姿态估计这个问题进行简化了。
首先假设我们经过第一步已经得到了所有特征一对多匹配的结果了(后面会再说如何得到一对多匹配关系的具体方法)。
现在就有很多个2D-3D匹配关系了,同时3D点在空间中的位置是已经知道的。先考虑最简单的情况,假设已经相机的高度为 h , 并且相机的
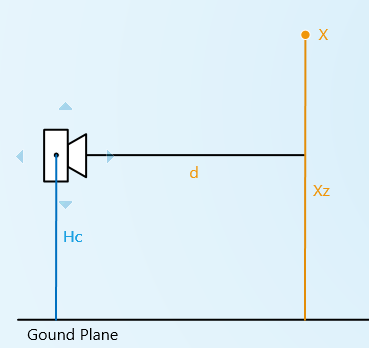
如图所示,假设2D特征点的图像像素坐标为
那么如果这个2D-3D匹配关系是正确的话,相机观察到这样一个匹配关系,那么相机可能的位置在 xy 平面上就是一个圆,圆心就是3D点在 xy 平面上的投影 X′ ,半径就是深度 d 。
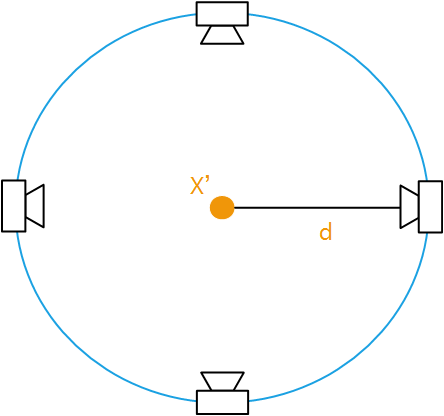
那么,对每一个这样的2D-3D匹配,都可以在
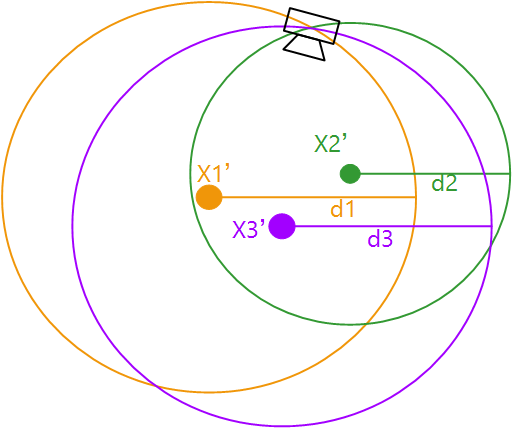
如上图所示,假如有三个正确的2D-3D对应关系,那么可以得到三个圆,三个圆相交的位置就是相机的位置。
当然实际的匹配关系中会有很多错误的匹配,但是可以采用类似 Hough Tranform 中的方法,对区域进行划分,然后投票,得到票数最多的区域,就是得到的相机位置。
Accounting for uncertainty
上一章节是假设了已知准确的相机高度,是理想情况,实际上并不知道相机的准确高度,假设2 中只是假设了相机的高度是在地平面附近的一个区间中。同时2D-3D对应关系中,3D点反投影到像平面上面也会有一定的误差。所以需要把这些不确定性都考虑进来。
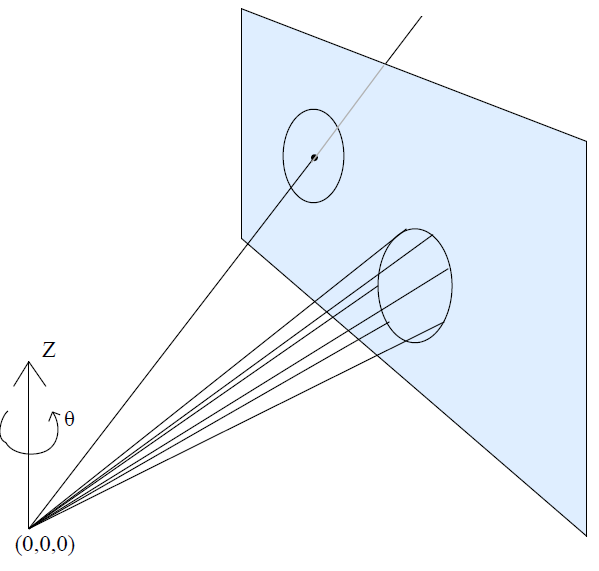
首先,对于一个2D-3D匹配关系,光心、2D像点、3D点并不能同时准确地在一条直线上,考虑到一定的误差,可以认为把3D点反投影到像平面上,会和2D像点的误差在
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









