




 作者在本地电脑搭建Hadoop集群,加内存后启动三台机器时,一台节点无法加入集群。查看日志发现是集群id不一致问题。网友给出两种解决办法,一是重新格式化namenode,但因有数据未采用;二是修改VERSION文件,作者采用此方法,最终成功解决问题。
作者在本地电脑搭建Hadoop集群,加内存后启动三台机器时,一台节点无法加入集群。查看日志发现是集群id不一致问题。网友给出两种解决办法,一是重新格式化namenode,但因有数据未采用;二是修改VERSION文件,作者采用此方法,最终成功解决问题。
之前在自己本地的电脑上安装了3个linux机器来搭建hadoop集群,前面一段时间是使用三台来进行练习,后面发现电脑内容有点紧,就切换为两台。最近给电脑加了内存之后,就想把三台一起启动了。但是发现之前一直没用的那台没能起来,就去查看日志。

到mini3机器的日志目录,查看日志:
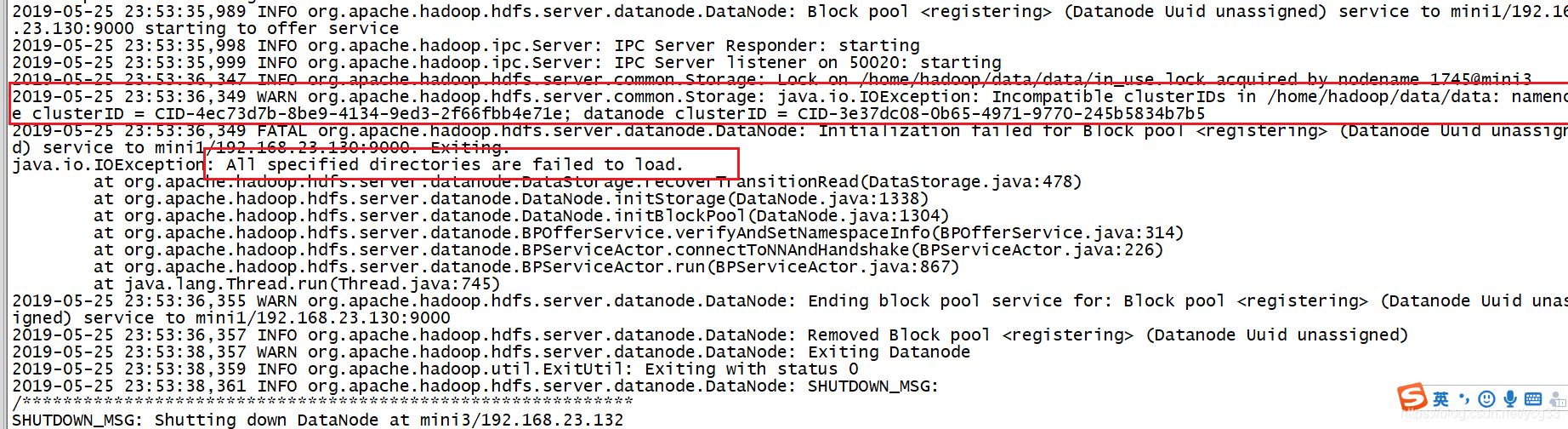
由错误日志可以看出来是当前机器的集群id和nameNode的集群id不相同,导致该节点无法加入集群
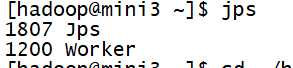
通过查看java进程也能看到该机器上的datanode没有启动。
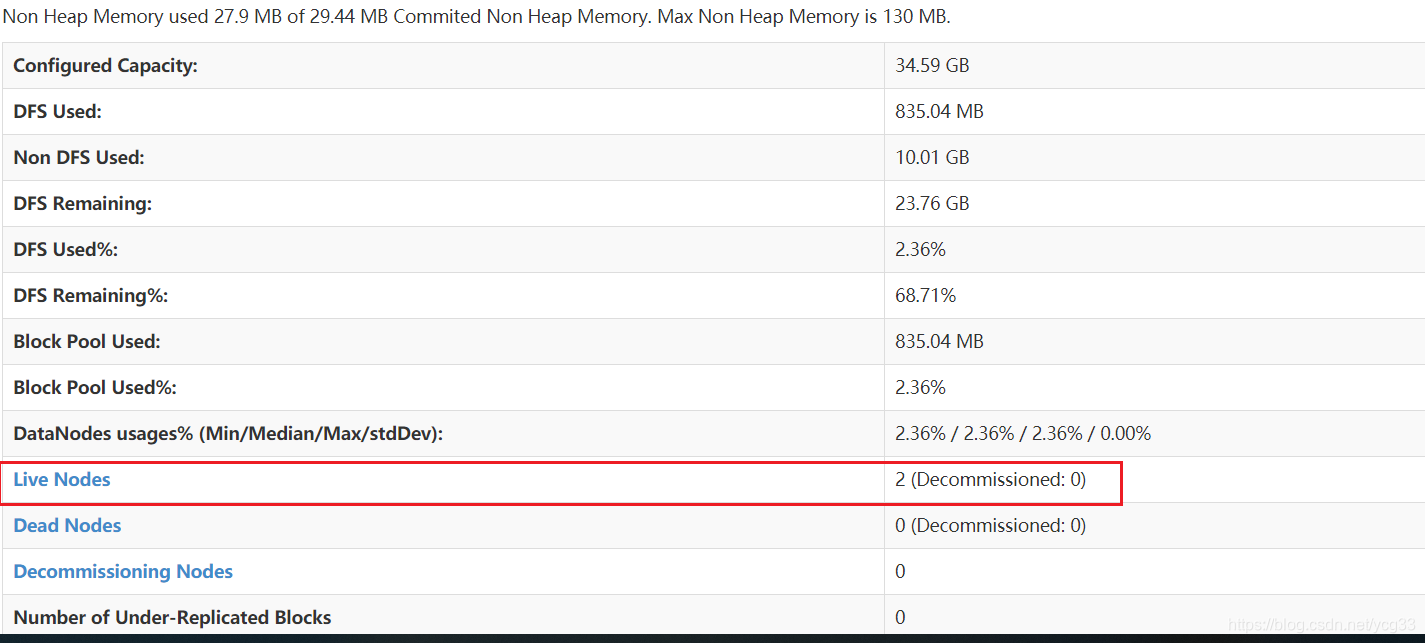
从ui界面也能确定目前是只有2个节点
解决办法:
从网友给出来的解决办法有两种:
(1)重新格式化namenode
直接删除tmp/dfs,然后格式化hdfs即可(./hdfs namenode -format)重新在tmp目录下生成一个dfs文件
但是因为集群中已经有部分数据,这跟生产上是一样的【不能随意删除数据】
所以我没有采用这种方式
(2)修改VERSION文件即可,将nameNode里version文件夹里面的内容修改成和namenode一致的
这种方式符合我的预期,所以我就采用了这种方式。具体操作步骤如下
a)比较namenode和正常启动的datanode的信息
namenode上的信息
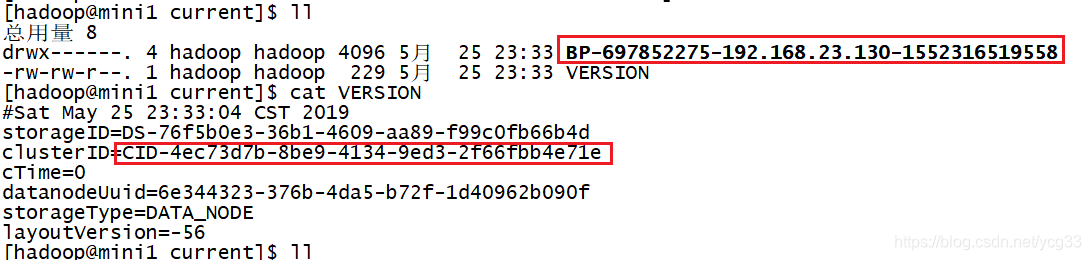
正常的datanode上的信息
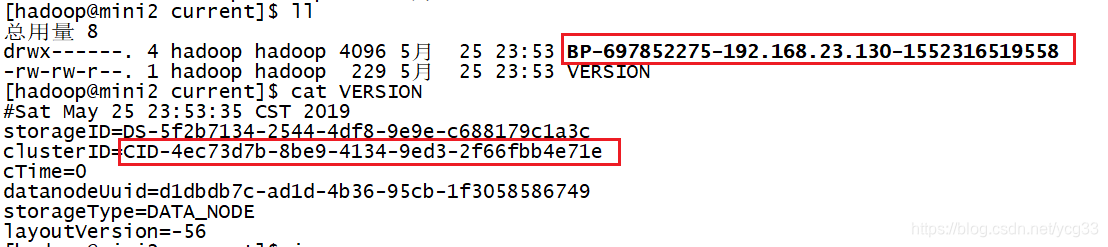
b)查看没有正常启动的datanode上的信息
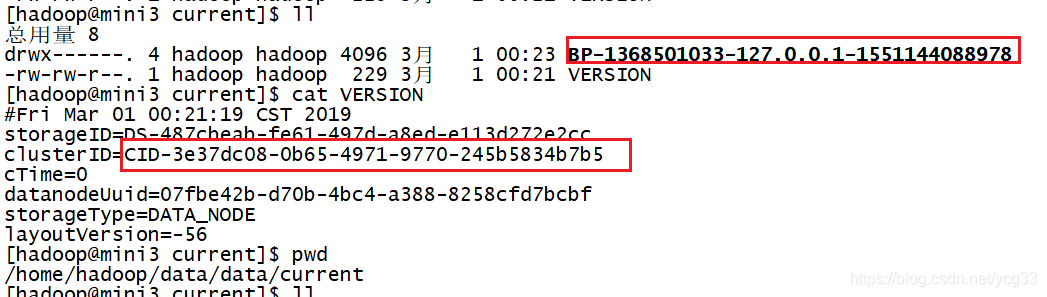
可以看到该节点的信息和集群id和namenode的都不是不一样的,所以就不能加入集群
c)把正常启动的datanode上的BP-XXX 拷贝到没启动的机器上,并删除没启动机器上原来的BP-XXX

4)修改正常启动的datanode上的VERSION文件的集群id
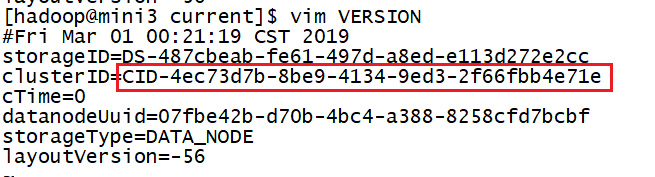
检查信息是否一致
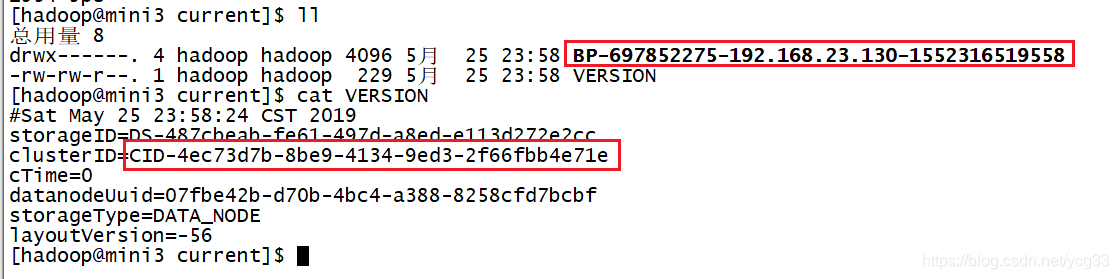
信息一致之后,重新启动集群

通过ui界面可以看到节点已经正常启动
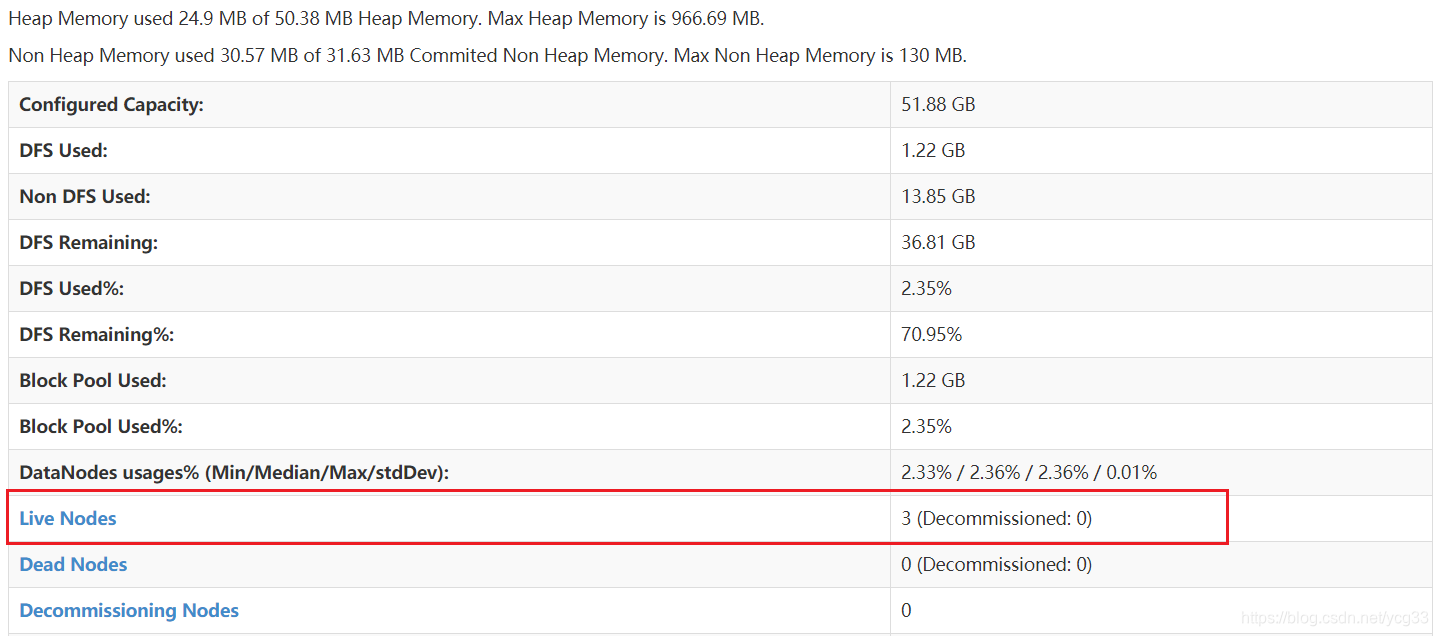
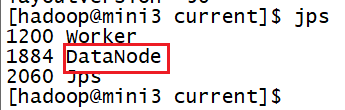
问题解决

















 1928
1928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









