










伪分布式参考:http://blog.csdn.net/manageer/article/details/51061802
集群环境:
centos6.5 master 192.168.145.129
centos6.5 slave1 192.168.145.130
centos6.5 slave2 192.168.145.136配置步骤:
1.配置三台主机的hostname:(以192.168.145.129为例 其它的修改对应的hostname即可,重启系统后生效)
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master #修改成对应主机的hostname
NETWORKING_IPV6=yes
IPV6_AUTOCONF=no2.配置三台主机的hosts文件内容如下:(集群节点hosts是一致的)
127.0.0.1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
192.168.145.129 master
192.168.145.130 slave1
192.168.145.136 slave23.在三台主机上创建如下创建目录:
/home/work/dfs/name
/home/work/dfs/tmp4.将三台主机设置成ssh免登录
在三台电脑上执行如下代码:
配置SSH实现基于公钥方式无密码登录生成公钥
[root@master ~]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
生成SSH认证公钥,连续回车即可
[root@master ~]#cd ~/.ssh #切换至root用户的ssh配置目录
[root@master ~]#ls
id_rsa id_rsa.pub
配置授权
[root@master ~]#cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[root@master ~]# chmod 700 ~/.ssh
[root@master ~]# chmod 600 ~/.ssh/authorized_keys
将slave1,slave2两台主机的authorized_keys内容追加到master主机的authorized_keys文件中;接着将master的authorized_keys文件替换slave1,slave2的同名文件这样三台电脑就能相互ssh免密码登录了。4.将hadoop2.7.2解压到master主机的/usr/local目录下 (下面都是配置的master主机上的hadoop)
[root@master hadoop-2.7.2]# ll
total 64
drwxr-xr-x. 2 10011 10011 4096 Jan 25 16:20 bin
drwxr-xr-x. 3 10011 10011 4096 Jan 25 16:20 etc
drwxr-xr-x. 2 10011 10011 4096 Jan 25 16:20 include
drwxr-xr-x. 3 10011 10011 4096 Jan 25 16:20 lib
drwxr-xr-x. 2 10011 10011 4096 Jan 25 16:20 libexec
-rw-r--r--. 1 10011 10011 15429 Jan 25 16:20 LICENSE.txt
drwxr-xr-x. 3 root root 12288 Apr 17 19:41 logs
-rw-r--r--. 1 10011 10011 101 Jan 25 16:20 NOTICE.txt
-rw-r--r--. 1 10011 10011 1366 Jan 25 16:20 README.txt
drwxr-xr-x. 2 10011 10011 4096 Jan 25 16:20 sbin
drwxr-xr-x. 4 10011 10011 4096 Jan 25 16:20 share
[root@master hadoop-2.7.2]# pwd
/usr/local/hadoop-2.7.25.配置Hadoop环境变量
export HADOOP_HOME=/usr/local/hadoop-2.7.2
export JAVA_HOME=/home/work/jdk1.7.0 #配置成自己的jdk目录
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH6.配置$HADOOP/etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/work/dfs/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>7.配置$HADOOP/etc/hadoop/core-site.xml
# The java implementation to use.
export JAVA_HOME=${JAVA_HOME}
改成:(亲测不改也行,只要jdk环境变量配置了JAVA_HOME就可以)
# The java implementation to use.
export JAVA_HOME=/home/work/jdk1.7.0
8.配置$HADOOP/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/work/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/home/work/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>9.配置$HADOOP/etc/hadoop/slaves
master
slave1
slave2
- 将master上的hadoop复制到slave1,slave2
scp -r /usr/local/hadoop-2.7.2 root@slave1:/usr/local
scp -r /usr/local/hadoop-2.7.2 root@slave2:/usr/local11.在master主机上启动hadoop就可以了
[root@master hadoop-2.7.2]# sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
16/04/17 21:33:25 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-namenode-master.out
slave1: starting datanode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-datanode-slave1.out
slave2: starting datanode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-datanode-slave2.out
master: starting datanode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-datanode-master.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-master.out
16/04/17 21:33:54 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.7.2/logs/yarn-root-resourcemanager-master.out
slave2: starting nodemanager, logging to /usr/local/hadoop-2.7.2/logs/yarn-root-nodemanager-slave2.out
slave1: starting nodemanager, logging to /usr/local/hadoop-2.7.2/logs/yarn-root-nodemanager-slave1.out
master: starting nodemanager, logging to /usr/local/hadoop-2.7.2/logs/yarn-root-nodemanager-master.out
[root@master hadoop-2.7.2]#jps
22939 ResourceManager
23393 Jps
23044 NodeManager
22596 DataNode
22785 SecondaryNameNode
22493 NameNode
slave1主机上进程:
[root@slave1 hadoop-2.7.2]# jps
5484 QuorumPeerMain
7123 Jps
6864 DataNode
6968 NodeManager
slave2主机上进程:
[root@slave2 hadoop-2.7.2]# jps
6736 Jps
6496 DataNode
6600 NodeManager
[root@slave2 hadoop-2.7.2]#
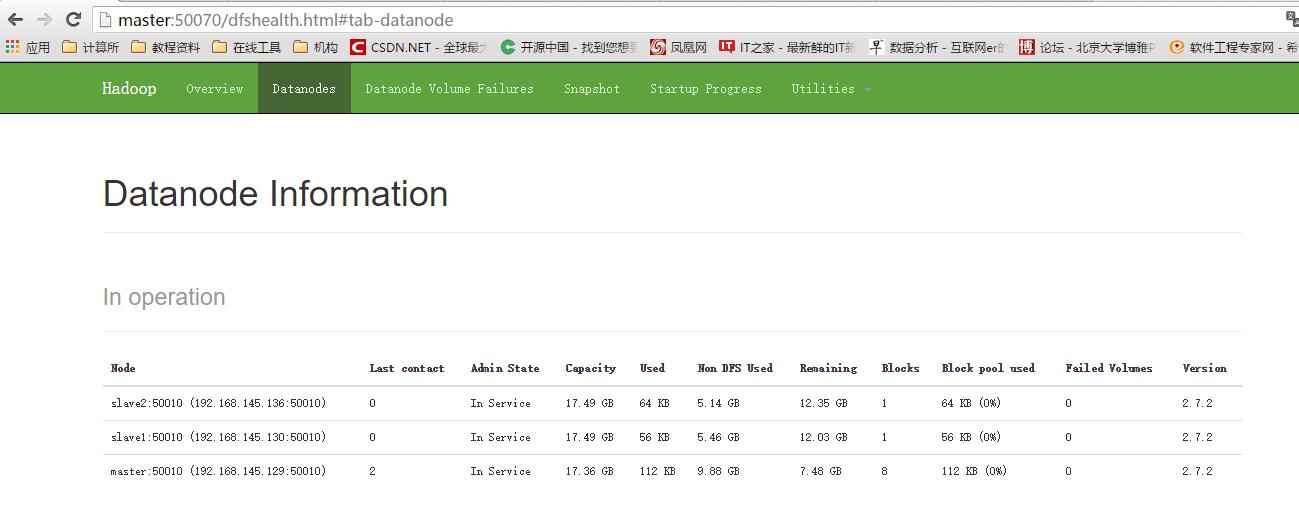
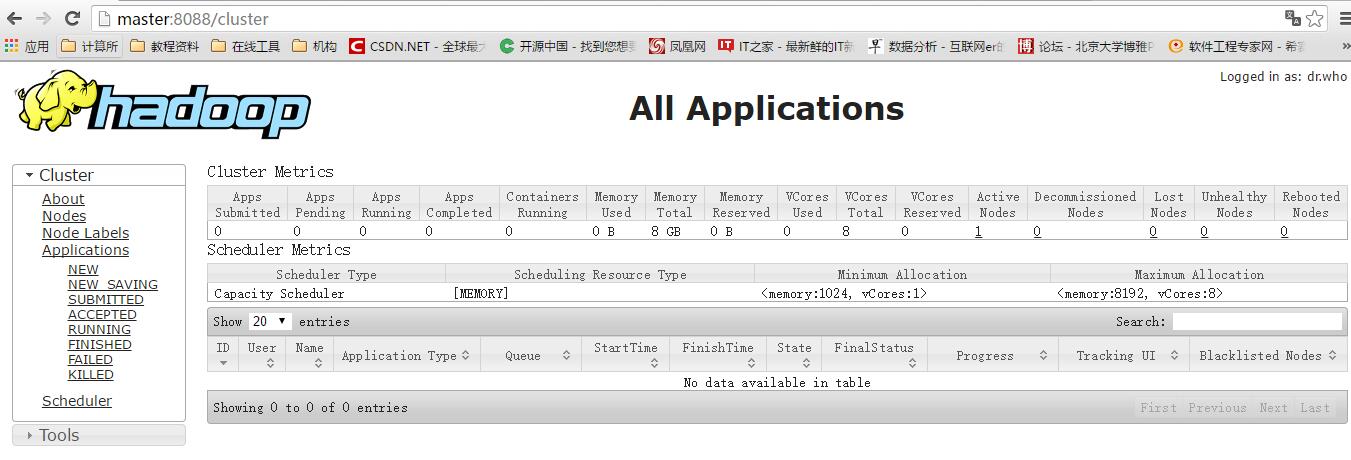
在浏览器里可以访问下面的三个链接:
http://master:50070
http://master:8088
http://master:9000
ps:
1.我是在windows系统里安装了vmware虚拟创建了三台linux系统
浏览器访问的是在windows系统下访问的,master能访问到主机是因为windows下的hosts目录页进行了设置:
C:\Windows\System32\drivers\etc\hosts
192.168.145.129 master
192.168.145.130 slave1
192.168.145.136 slave22.如果在虚拟机里可以访问这三个链接在宿主计算机(windows)里无法访问那就是防火墙的问题:
1) 重启后生效
开启: chkconfig iptables on
关闭: chkconfig iptables off
2) 即时生效,重启后失效
开启: service iptables start
关闭: service iptables stop
也可以用setup>firwall configuration>空格来选择是否启用,没有*是关闭>ok退出














 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









