






转载自:https://blog.csdn.net/Jae_Peng/article/details/79562432
众所周知,HashMap 是一个用于存储Key-Value键值对的集合,每一个键值对也叫做 Entry。
这些个键值对(Entry)分散存储在一个数组当中,这个数组就是HashMap的主干。
HashMap 数组每一个元素的初始值都是 Null。

对于HashMap,我们最常使用的是两个方法:Get 和 Put。
- Put 方法的原理
调用 Put 方法的时候发生了什么呢?
比如调用 hashMap.put(“apple”, 0) ,插入一个Key为“apple”的元素。这时候我们需要利用一个哈希函数来确定Entry的插入位置(index):
index = Hash(“apple”)
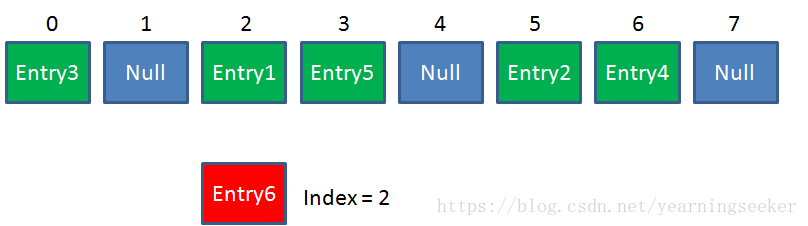
假定最后计算出的index是2,那么结果如下:

但是,因为 HashMap 的长度是有限的,当插入的 Entry 越来越多时,再完美的 Hash 函数也难免会出现 index 冲突的情况。
比如下面这样:
这时候该怎么办呢?我们可以利用链表来解决。
HashMap 数组的每一个元素不止是一个 Entry 对象,也是一个链表的头节点。
每一个 Entry 对象通过 Next 指针指向它的下一个 Entry 节点。当新来的Entry映射到冲突的数组位置时,只需要插入到对应的链表即可:
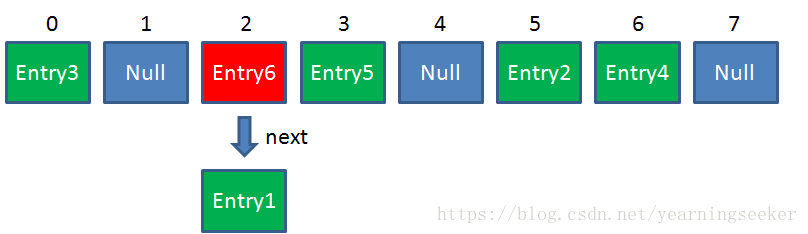
需要注意的是,新来的Entry节点插入链表时,使用的是“头插法”。至于为什么不插入链表尾部,后面会有解释。
- Get方法的原理
使用 Get 方法根据 Key 来查找 Value 的时候,发生了什么呢?
首先会把输入的 Key 做一次 Hash 映射,得到对应的 index:
index = Hash(“apple”)
由于刚才所说的 Hash 冲突,同一个位置有可能匹配到多个Entry,这时候就需要顺着对应链表的头节点,一个一个向下来查找。假设我们要查找的Key是 “apple”:
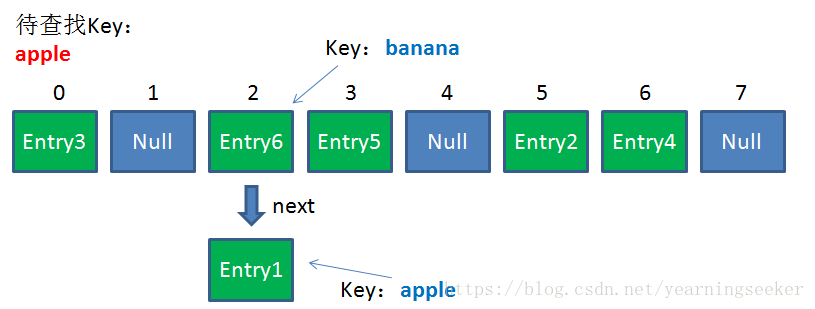
第一步,我们查看的是头节点 Entry6,Entry6 的 Key是banana,显然不是我们要找的结果。
第二步,我们查看的是 Next 节点 Entry1,Entry1 的 Key 是 apple,正是我们要找的结果。
之所以把 Entry6 放在头节点,是因为 HashMap 的发明者认为,后插入的 Entry 被查找的可能性更大。
HashMap的默认长度是16 ,自动扩展或初始化时,长度必须是2的幂
目的:服务于从Key映射到index的Hash算法
之前说过,从Key映射到HashMap数组的对应位置,会用到一个Hash函数:
index = Hash(“apple”)
如何实现一个尽量均匀分布的Hash函数呢?我们通过利用Key的HashCode值来做某种运算。
Hash算法的实现采用了位运算的方式
如何进行位运算呢?有如下的公式(Length是HashMap的长度):
index = HashCode(Key) & (Length -
1)
下面我们以值为“book”的 Key 来演示整个过程:
1. 计算 book 的 hashcode,结果为十进制的 3029737,二进制的101110001110101110 1001。
2. 假定 HashMap 长度是默认的16,计算Length-1的结果为十进制的15,二进制的1111。
3. 把以上两个结果做与运算,101110001110101110 1001 & 1111 = 1001,十进制是9,所以 index=9。(与运算:和,同位上都为1则为1,否则为0
可以说,Hash 算法最终得到的 index 结果,完全取决于 Key 的 Hashcode 值的最后几位。
为什么长度必须是2的幂
假设 HashMap 的长度是10,重复刚才的运算步骤:

单独看这个结果,表面上并没有问题。我们再来尝试一个新的 HashCode 101110001110101110
1011 :

让我们再换一个 HashCode
101110001110101110 1111 试试 :

是的,虽然 HashCode 的倒数第二第三位从0变成了1,但是运算的结果都是1001。
也就是说,当 HashMap 长度为10的时候,有些index结果的出现几率会更大,而有些index结果永远不会出现(比如0111)!
这样,显然不符合Hash算法均匀分布的原则。
反观长度16或者其他2的幂,Length-1 的值是所有二进制位全为1,比如15是1111,7是111,这种情况下,index 的结果等同于 HashCode 后几位的值。
只要输入的 HashCode 本身分布均匀,Hash 算法的结果就是均匀的。
HashMap扩容与Rehash
HashMap的容量是有限的。当经过多次元素插入,使得HashMap达到一定饱和度时,Key映射位置发生冲突的几率会逐渐提高。
这时候,HashMap需要扩展它的长度,也就是进行Resize。

影响发生Resize的因素有两个:
1.Capacity
HashMap的当前长度。上一期曾经说过,HashMap的长度是2的幂。
2.LoadFactor
HashMap负载因子,默认值为0.75f。
衡量HashMap是否进行Resize的条件如下:
HashMap.Size >= Capacity * LoadFactor
HashMap的resize不是简单的把长度扩大,而是经历以下两个步骤
1.扩容
创建一个新的Entry空数组,长度是原数组的2倍。
2.ReHash
遍历原Entry数组,把所有的Entry重新Hash到新数组。为什么要重新Hash呢?因为长度扩大以后,Hash的规则也随之改变。
让我们回顾一下Hash公式:
index = HashCode(Key) & (Length - 1)
当原数组长度为8时,Hash运算是和111B做与运算;新数组长度为16,Hash运算是和1111B做与运算。Hash结果显然不同。
Resize前的HashMap:

Resize后的HashMap:

ReHash的Java代码如下:
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry














 3360
3360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









