







参加了Python实战课程,此为第一节课的练习总结
成果
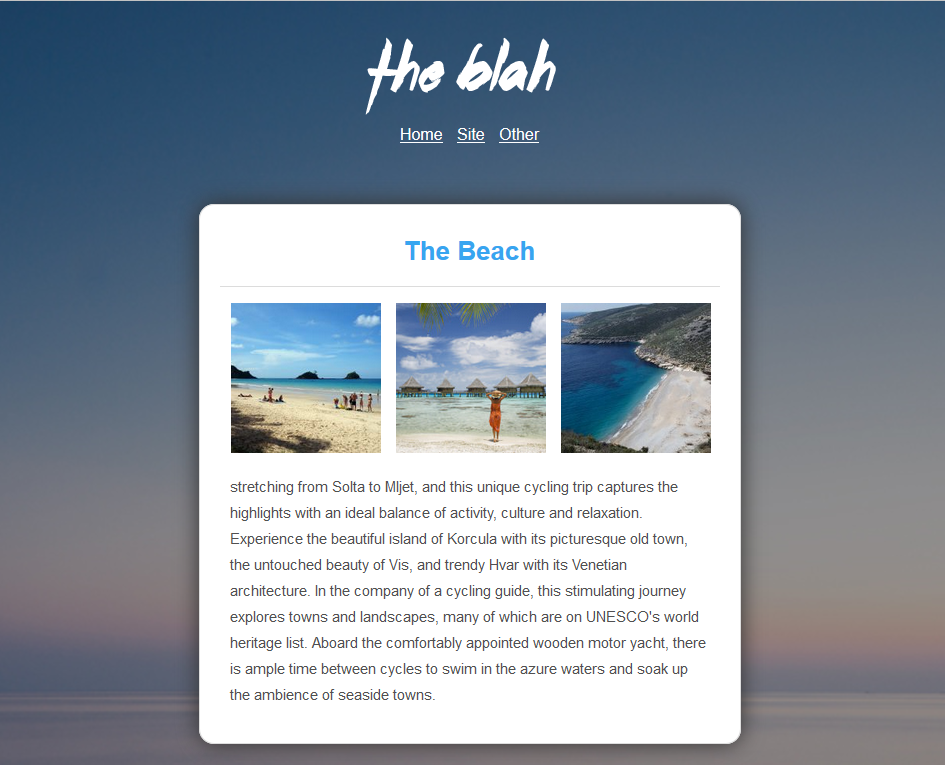
HTML代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>The Blah</title>
<link rel="stylesheet" type="text/css" href="homework.css">
</head>
<body>
<div class="header">
<img src="images/blah.png">
<ul class="nav">
<li><a href="#">Home</a></li>
<li><a href="#">Site</a></li>
<li><a href="#">Other </a></li>
</ul>
</div>
<div class="main-content">
<h2>The Beach</h2>
<hr />
<ul class="photos">
<li><img src="images/0001.jpg" width="150" height="150"></li>
<li><img src="images/0003.jpg" width="150" height="150"></li>
<li><img src="images/0004.jpg" width="150" height="150"></li>
</ul>
<p>stretching from Solta to Mljet, and this unique cycling trip captures the highlights with an ideal balance of activity, culture and relaxation. Experience the beautiful island of Korcula with its picturesque old town, the untouched beauty of Vis, and trendy Hvar with its Venetian architecture. In the company of a cycling guide, this stimulating journey explores towns and landscapes, many of which are on UNESCO's world heritage list. Aboard the comfortably appointed wooden motor yacht, there is ample time between cycles to swim in the azure waters and soak up the ambience of seaside towns. </p>
</div>
<div class="footer">
<p>©MUGGLECODING</p>
</div>
</body>
</html>总结
- 了解了网页结构组成。
- js是用于控制html页面代码,实现复杂的页面效果或功能
- css用于功能html如何展示,让页面展示的美观漂亮
- html用于描述网页结构。
- 学会了如何使用css结构去控制页面样式(css是老师写好的)














 4281
4281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









