







1 概述
软件架构是一门学问,并且是一门很深邃的学问,从本篇文章开始,我们就来聊聊架构,所用到的主流语言为.NET、Java和php。本篇文章作为架构的开篇文章,主要从广度上叙述软件架构的发展与演变,从软件架构系列第二篇文章开始,将结合具体的产品或项目实例,来与大家分享架构。
本篇文章先简要概述一下设计模式和OO设计的七大原则,然后在与大家分享网站是如何一步一步演变的。
如下一张架构图,如果你觉得有点困难,那么说明基础比较薄弱(参加的项目架构比较少,架构实战也比较少),至少在软件架构方方面,那么建议区研究些架构实战的书籍,再来阅读,效果也许会好很多。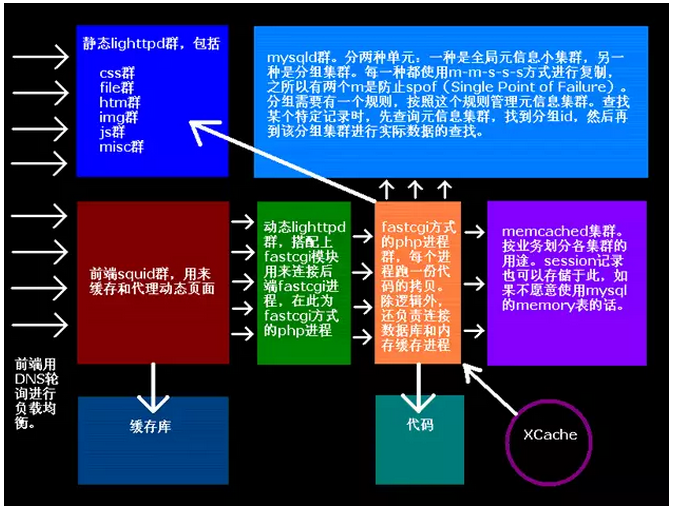
2 设计模式概述
2.1 设计模式之间的关系
下图为软件设计模式之间的关系,几乎对所有语言管用

2.2 二十三种设计模式概述
二十三种设计模式,按照种类来划分,一般分为创建型模式、行为型模式和结构型模式。
(1)创建型:单例模式、工厂模式(简单工厂模式、工厂方法模式和抽象工厂模式)、建造者模式、原型模式
(2)行为型:观察者模式、策略模式、模板方法模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式
(3)结构模式:适配器模式、装饰模式、代理模式、外观模式、桥接模式、组合模式、享元模式
2.3 研究设计模式建议
关于设计模式的研究,建议大家看国外四人帮的书,基础较好的朋友,不仅要研究java,.NET,更要研究C++(如果你有较强的C++功底,当你去研究C++的时候,你会受益匪浅)
3 OO七大设计原则概述
面向对象设计的七大原则。可归结为:单一职责原则、开闭原则、里氏替换原则、依赖倒置原则、接口隔离原则、合成/聚合复用原则、迪米特法则。
3.1 单一职责原则SRP(Simple Responsibility Principle)
单一职责原则,就是一个设计元素只做一件事。什么是“只做一件事”?就是少管闲事。现实中也是如此,如果让一个人认真的去做一件事,那么任何人都有信心可以做到很出色。就一个类而言,应该仅有一个引起它变化的原因,如果你能想到两个或是多个动机去改变一个类,那么这个类就具有两个或是多个职责。应该把多余的职责分离出去,分别在创建一个类去完成每一个职责。
3.2 开闭原则OCP(Open Close Principle)
很简单,一句话:“Closedfor Modification;Open for Extension",意思是,”对变更关闭;对扩展开放“。开闭原则的动机很简单:软件是变化的。一个软件实体应当对修改关闭,对扩展开放。也就是说,在设计一个模块的时候,应当对这个模块可以在不被修改的前提下被扩展。换言之,应当可以在不必修改源代码的情况下改变这个模块的行为,在保持系统一定稳定性的基础上,对系统进行扩展。这是面向对象设计(OOD)的基石,也是最重要的原则。OCP说明了软件设计应该尽可能地是架构稳定而又容易满足不同的需求。
3.3 里氏替换原则LSP(Liskov Substitution Principle)
a.由BarbarLiskov(芭芭拉.里氏)提出,是继承复用的基石。
b.严格表达:如果每一个类型为T1的对象o1,都有类型为T2的对象o2,使得以T1定义的所有程序P在所有的对象o1都代换称o2时,程序P的行为没有变化,那么类型T2是类型T1的子类型.换言之,一个软件实体如果使用的是一个基类的话,那么一定适用于其子类,而且它根本不能察觉出基类对象和子类对象的区别.只有衍生类可以替换基类,软件单位的功能才能不受影响,基类才能真正被复用,而衍生类也能够在基类的基础上增加新功能。
c.反过来的代换不成立
d.<墨子.小取>中说:"白马,马也; 乘白马,乘马也.骊马(黑马),马也;乘骊马,乘马也."
e.该类西方著名的例程为:正方形是否是长方形的子类(答案是"否")。类似的还有椭圆和圆的关系。
f.应当尽量从抽象类继承,而不从具体类继承,一般而言,如果有两个具体类A,B有继承关系,那么一个最简单的修改方案是建立一个抽象类C,然后让类A和B成为抽象类C的子类.即如果有一个由继承关系形成的登记结构的话,那么在等级结构的树形图上面所有的树叶节点都应当是具体类;而所有的树枝节点都应当是抽象类或者接口.
g."基于契约设计(DesignBy Constract),简称DBC"这项技术对LISKOV代换原则提供了支持.该项技术BertrandMeyer伯特兰做过详细的介绍:
使用DBC,类的编写者显式地规定针对该类的契约.客户代码的编写者可以通过该契约获悉可以依赖的行为方式.契约是通过每个方法声明的前置条件(preconditions)和后置条件(postconditions)来指定的.要使一个方法得以执行,前置条件必须为真.执行完毕后,该方法要保证后置条件为真.就是说,在重新声明派生类中的例程(routine)时,只能使用相等或者更弱的前置条件来替换原始的前置条件,只能使用相等或者更强的后置条件来替换原始的后置条件.
3.4 依赖倒置原则DIP(Dependency Inversion Principle)
a.表述:抽象不应当依赖于细节,细节应当依赖于抽象.(Programto an interface, not an implementaction)
b.表述二:针对接口编程的意思是说,应当使用接口和抽象类进行变量的类型声明,参量的类型声明,方法的返还类型声明,以及数据类型的转换等.不要针对实现编程的意思就是说,不应当使用具体类进行变量的类型声明,参量类型声明,方法的返还类型声明,以及数据类型的转换等.
要保证做到这一点,一个具体的类应等只实现接口和抽象类中声明过的方法,而不应当给出多余的方法.
只要一个被引用的对象存在抽象类型,就应当在任何引用此对象的地方使用抽象类型,包括参量的类型声明,方法返还类型的声明,属性变量的类型声明等.
c.接口与抽象的区别就在于抽象类可以提供某些方法的部分实现,而接口则不可以,这也大概是抽象类唯一的优点.如果向一个抽象类加入一个新的具体方法,那么所有的子类型一下子就都得到得到了这个新的具体方法,而接口做不到这一点.如果向一个接口加入了一个新的方法的话,所有实现这个接口的类就全部不能通过编译了,因为它们都没有实现这个新声明的方法.这显然是接口的一个缺点.
d.一个抽象类的实现只能由这个抽象类的子类给出,也就是说,这个实现处在抽象类所定义出的继承的登记结构中,而由于一般语言都限制一个类只能从最多一个超类继承,因此将抽象作为类型定义工具的效能大打折扣.
反过来,看接口,就会发现任何一个实现了一个接口所规定的方法的类都可以具有这个接口的类型,而一个类可以实现任意多个接口.
e.从代码重构的角度上讲,将一个单独的具体类重构成一个接口的实现是很容易的,只需要声明一个接口,并将重要的方法添加到接口声明中,然后在具体类定义语句中加上保留字以继承于该接口就行了.
而作为一个已有的具体类添加一个抽象类作为抽象类型不那么容易,因为这个具体类有可能已经有一个超类.这样一来,这个新定义的抽象类只好继续向上移动,变成这个超类的超类,如此循环,最后这个新的抽象类必定处于整个类型等级结构的最上端,从而使登记结构中的所有成员都会受到影响.
f.接口是定义混合类型的理想工具,所为混合类型,就是在一个类的主类型之外的次要类型.一个混合类型表明一个类不仅仅具有某个主类型的行为,而且具有其他的次要行为.
g.联合使用接口和抽象类:
由于抽象类具有提供缺省实现的优点,而接口具有其他所有优点,所以联合使用两者就是一个很好的选择.
首先,声明类型的工作仍然接口承担的,但是同时给出的还有一个抽象类,为这个接口给出一个缺省实现.其他同属于这个抽象类型的具体类可以选择实现这个接口,也可以选择继承自这个抽象类.如果一个具体类直接实现这个接口的话,它就必须自行实现所有的接口;相反,如果它继承自抽象类的话,它可以省去一些不必要的的方法,因为它可以从抽象类中自动得到这些方法的缺省实现;如果需要向接口加入一个新的方法的话,那么只要同时向这个抽象类加入这个方法的一个具体实现就可以了,因为所有继承自这个抽象类的子类都会从这个抽象类得到这个具体方法.这其实就是缺省适配器模式(DefauleAdapter).
h.什么是高层策略呢?它是应用背后的抽象,是那些不随具体细节的改变而改变的真理.它是系统内部的系统____隐喻.
3.5 接口隔离原则ISP(Interface Segregation Principle)
a.一个类对另外一个类的依赖是建立在最小的接口上。
b.使用多个专门的接口比使用单一的总接口要好.根据客户需要的不同,而为不同的客户端提供不同的服务是一种应当得到鼓励的做法.就像"看人下菜碟"一样,要看客人是谁,再提供不同档次的饭菜.
c.胖接口会导致他们的客户程序之间产生不正常的并且有害的耦合关系.当一个客户程序要求该胖接口进行一个改动时,会影响到所有其他的客户程序.因此客户程序应该仅仅依赖他们实际需要调用的方法.
3.6 合成/聚合复用原则CARP(Composite/AggregateReuse Principle)
在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分;新的对象通过这些向对象的委派达到复用已有功能的目的.这个设计原则有另一个简短的表述:要尽量使用合成/聚合,尽量不要使用继承.
3.7 迪米特法则(Law of Demeter LoD)又叫做最少知识原则LKP(Least KnowledgePrinciple)
对其他对象有尽可能少的了了解.
迪米特法则最初是用来作为面向对象的系统设计风格的一种法则,与1987年秋天由IanHolland在美国东北大学为一个叫做迪米特(Demeter)的项目设计提出的,因此叫做迪米特法则[LIEB89][LIEB86].这条法则实际上是很多著名系统,比如火星登陆软件系统,木星的欧罗巴卫星轨道飞船的软件系统的指导设计原则.
没有任何一个其他的OO设计原则象迪米特法则这样有如此之多的表述方式,如下几种:
a.只与你直接的朋友们通信(Onlytalk to your immediate friends)
b.不要跟"陌生人"说话(Don'ttalk to strangers)
c.每一个软件单位对其他的单位都只有最少的知识,而且局限于那些本单位密切相关的软件单位.
就是说,如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用,如果其中的一个类需要调用另一个类的某一个方法的话,可以通过第三者转发这个调用。
3.8 常说的OO五大原则
单一职责原则;开放闭合原则;里氏替换原则;依赖倒置原则;接口隔离原则;
4 软件架构的演变概述
4.1 最初阶段:运用程序和数据库部署在同一台服务器上
由于刚开始,用户比较少,谈不上访问量,高并发等,因此一台服务器即可解决需求

4.2 第二阶段:物理分离WebServer和数据库
最开始,由于某些想法,于是在互联网上搭建了一个网站,这个时候甚至有可能主机都是租借的,但由于这篇文章我们只关注架构的演变历程,因此就假设这个时候已经是托管了一台主机,并且有一定的带宽了。这个时候由于网站具备了一定的特色,吸引了部分人访问,逐渐你发现系统的压力越来越高,响应速度越来越慢,而这个时候比较明显的是数据库和应用互相影响,应用出问题了,数据库也很容易出现问题,而数据库出问题的时候,应用也容易出问题。于是进入了第一步演变阶段:将应用和数据库从物理上分离,变成了两台机器,这个时候技术上没有什么新的要求,但你发现确实起到效果了,系统又恢复到以前的响应速度了,并且支撑住了更高的流量,并且不会因为数据库和应用形成互相的影响。
看看这一步完成后系统的图示:
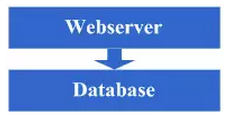
4.3 第三阶段:增加页面缓存
好景不长,随着访问的人越来越多,你发现响应速度又开始变慢了,查找原因,发现是访问数据库的操作太多,导致数据连接竞争激烈,所以响应变慢。但数据库连接又不能开太多,否则数据库机器压力会很高,因此考虑采用缓存机制来减少数据库连接资源的竞争和对数据库读的压力。这个时候首先也许会选择采用squid等类似的机制来将系统中相对静态的页面(例如一两天才会有更新的页面)进行缓存(当然,也可以采用将页面静态化的方案),这样程序上可以不做修改,就能够很好的减少对WebServer的压力以及减少数据库连接资源的竞争,OK,于是开始采用squid来做相对静态的页面的缓存。
看看这一步完成后系统的图示:
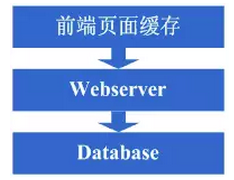
这一步涉及到了这些知识体系:
前端页面缓存技术,例如squid,如想用好的话还得深入掌握下squid的实现方式以及缓存的失效算法等。
4.4 第四阶段:增加页面片段缓存
增加了squid做缓存后,整体系统的速度确实是提升了,WebServer的压力也开始下降了,但随着访问量的增加,发现系统又开始变的有些慢了。在尝到了squid之类的动态缓存带来的好处后,开始想能不能让现在那些动态页面里相对静态的部分也缓存起来呢,因此考虑采用类似ESI之类的页面片段缓存策略,OK,于是开始采用ESI来做动态页面中相对静态的片段部分的缓存。
看看这一步完成后系统的图示:
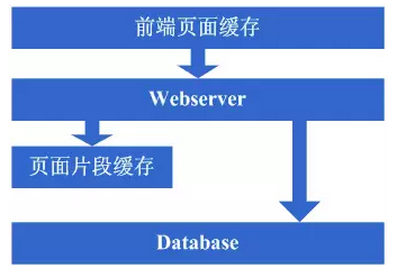
这一步涉及到了这些知识体系:
页面片段缓存技术,例如ESI等,想用好的话同样需要掌握ESI的实现方式等;
4.5 第五阶段:数据缓存
在采用ESI之类的技术再次提高了系统的缓存效果后,系统的压力确实进一步降低了,但同样,随着访问量的增加,系统还是开始变慢。经过查找,可能会发现系统中存在一些重复获取数据信息的地方,像获取用户信息等,这个时候开始考虑是不是可以将这些数据信息也缓存起来呢,于是将这些数据缓存到本地内存,改变完毕后,完全符合预期,系统的响应速度又恢复了,数据库的压力也再度降低了不少。
看看这一步完成后系统的图示:
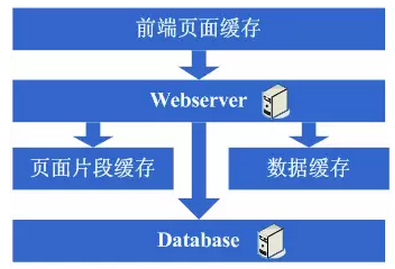
这一步涉及到了这些知识体系:
缓存技术,包括像Map数据结构、缓存算法、所选用的框架本身的实现机制等。
4.6 第六阶段: 增加WebServer
好景不长,发现随着系统访问量的再度增加,webserver机器的压力在高峰期会上升到比较高,这个时候开始考虑增加一台webserver,这也是为了同时解决可用性的问题,避免单台的webserver down机的话就没法使用了,在做了这些考虑后,决定增加一台webserver,增加一台webserver时,会碰到一些问题,典型的有:
a.如何让访问分配到这两台机器上,这个时候通常会考虑的方案是Apache自带的负载均衡方案,或LVS这类的软件负载均衡方案;
b.如何保持状态信息的同步,例如用户session等,这个时候会考虑的方案有写入数据库、写入存储、cookie或同步session信息等机制等;
c.如何保持数据缓存信息的同步,例如之前缓存的用户数据等,这个时候通常会考虑的机制有缓存同步或分布式缓存;
d.如何让上传文件这些类似的功能继续正常,这个时候通常会考虑的机制是使用共享文件系统或存储等;
在解决了这些问题后,终于是把webserver增加为了两台,系统终于是又恢复到了以往的速度。
看看这一步完成后系统的图示:
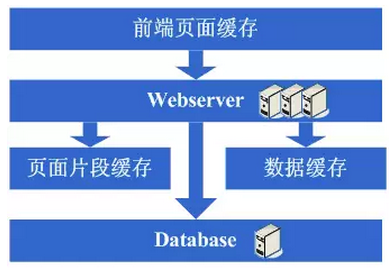
这一步涉及到了这些知识体系:
负载均衡技术(包括但不限于硬件负载均衡、软件负载均衡、负载算法、linux转发协议、所选用的技术的实现细节等)、主备技术(包括但不限于ARP欺骗、linuxheart-beat等)、状态信息或缓存同步技术(包括但不限于Cookie技术、UDP协议、状态信息广播、所选用的缓存同步技术的实现细节等)、共享文件技术(包括但不限于NFS等)、存储技术(包括但不限于存储设备等)。
4.7 第七阶段:分库
享受了一段时间的系统访问量高速增长的幸福后,发现系统又开始变慢了,这次又是什么状况呢,经过查找,发现数据库写入、更新的这些操作的部分数据库连接的资源竞争非常激烈,导致了系统变慢,这下怎么办呢?此时可选的方案有数据库集群和分库策略,集群方面像有些数据库支持的并不是很好,因此分库会成为比较普遍的策略,分库也就意味着要对原有程序进行修改,一通修改实现分库后,不错,目标达到了,系统恢复甚至速度比以前还快了。
看看这一步完成后系统的图示:
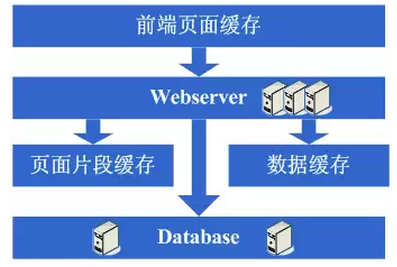
这一步涉及到了这些知识体系:
这一步更多的是需要从业务上做合理的划分,以实现分库,具体技术细节上没有其他的要求;
但同时随着数据量的增大和分库的进行,在数据库的设计、调优以及维护上需要做的更好,因此对这些方面的技术还是提出了很高的要求的。
4.8 第八阶段:分表、DAL和分布式缓存
随着系统的不断运行,数据量开始大幅度增长,这个时候发现分库后查询仍然会有些慢,于是按照分库的思想开始做分表的工作。当然,这不可避免的会需要对程序进行一些修改,也许在这个时候就会发现应用自己要关心分库分表的规则等,还是有些复杂的。于是萌生能否增加一个通用的框架来实现分库分表的数据访问,这个在ebay的架构中对应的就是DAL,这个演变的过程相对而言需要花费较长的时间。当然,也有可能这个通用的框架会等到分表做完后才开始做。同时,在这个阶段可能会发现之前的缓存同步方案出现问题,因为数据量太大,导致现在不太可能将缓存存在本地,然后同步的方式,需要采用分布式缓存方案了。于是,又是一通考察和折磨,终于是将大量的数据缓存转移到分布式缓存上了。
看看这一步完成后系统的图示:
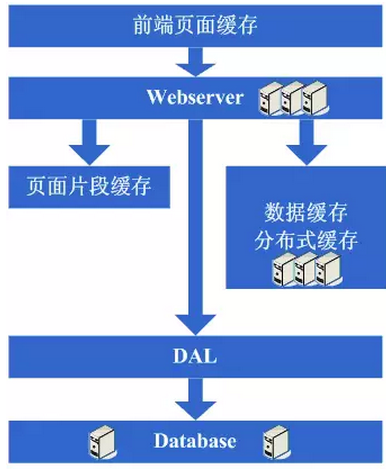
这一步涉及到了这些知识体系:
分表更多的同样是业务上的划分,技术上涉及到的会有动态hash算法、consistenthash算法等;
DAL涉及到比较多的复杂技术,例如数据库连接的管理(超时、异常)、数据库操作的控制(超时、异常)、分库分表规则的封装等;
4.9 第九阶段:增加更多的WebServer
在做完分库分表这些工作后,数据库上的压力已经降到比较低了,又开始过着每天看着访问量暴增的幸福生活了。突然有一天,发现系统的访问又开始有变慢的趋势 了,这个时候首先查看数据库,压力一切正常,之后查看webserver,发现apache阻塞了很多的请求,而应用服务器对每个请求也是比较快的,看来是请求数太高导致需要排队等待,响应速度变慢。这还好办,一般来说,这个时候也会有些钱了,于是添加一些webserver服务器,在这个添加webserver服务器的过程,有可能会出现几种挑战:
a.Apache的软负载或LVS软负载等无法承担巨大的web访问量(请求连接数、网络流量等)的调度了,这个时候如果经费允许的话,会采取的方案是购买硬件负载平衡设备,例如F5、Netsclar、Athelon之类的,如经费不允许的话,会采取的方案是将应用从逻辑上做一定的分类,然后分散到不同的软负载集群中;
b.原有的一些状态信息同步、文件共享等方案可能会出现瓶颈,需要进行改进,也许这个时候会根据情况编写符合网站业务需求的分布式文件系统等;
在做完这些工作后,开始进入一个看似完美的无限伸缩的时代,当网站流量增加时,应对的解决方案就是不断的添加webserver;
看看这一步完成后系统的图示:

这一步涉及到了这些知识体系:
到了这一步,随着机器数的不断增长、数据量的不断增长和对系统可用性的要求越来越高,这个时候要求对所采用的技术都要有更为深入的理解,并需要根据网站的需求来做更加定制性质的产品。
4.10 第十阶段:数据读写分离和廉价存储方案
突然有一天,发现这个完美的时代也要结束了,数据库的噩梦又一次出现在眼前了。由于添加的webserver太多了,导致数据库连接的资源还是不够用,而这个时候又已经分库分表了,开始分析数据库的压力状况,可能会发现数据库的读写比很高,这个时候通常会想到数据读写分离的方案。当然,这个方案要实现并不容易,另外,可能会发现一些数据存储在数据库上有些浪费,或者说过于占用数据库资源,因此在这个阶段可能会形成的架构演变是实现数据读写分离,同时编写一些更为廉价的存储方案,例如BigTable这种。
看看这一步完成后系统的图示:
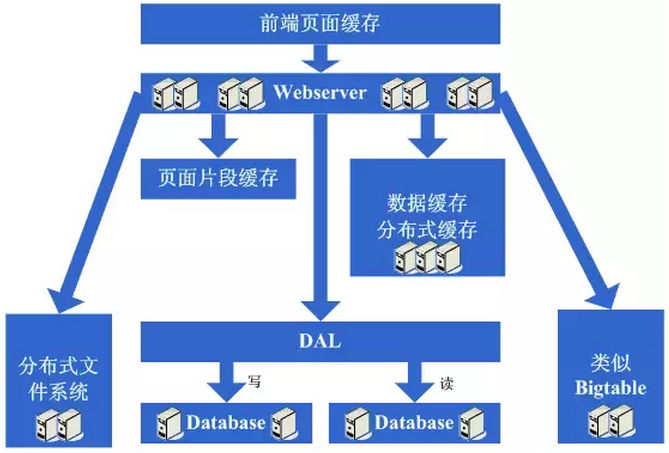
这一步涉及到了这些知识体系:
数据读写分离要求对数据库的复制、standby等策略有深入的掌握和理解,同时会要求具备自行实现的技术;
廉价存储方案要求对OS的文件存储有深入的掌握和理解,同时要求对采用的语言在文件这块的实现有深入的掌握。
4.11 最后阶段:进入大型分布式应用时代和廉价服务器群梦想时代
经过上面这个漫长而痛苦的过程,终于是再度迎来了完美的时代,不断的增加webserver就可以支撑越来越高的访问量了。对于大型网站而言,人气的重要毋庸置疑,随着人气的越来越高,各种各样的功能需求也开始爆发性的增长。这个时候突然发现,原来部署在webserver上的那个web应用已经非常庞大 了,当多个团队都开始对其进行改动时,可真是相当的不方便,复用性也相当糟糕,基本是每个团队都做了或多或少重复的事情,而且部署和维护也是相当的麻烦。因为庞大的应用包在N台机器上复制、启动都需要耗费不少的时间,出问题的时候也不是很好查,另外一个更糟糕的状况是很有可能会出现某个应用上的bug就导 致了全站都不可用,还有其他的像调优不好操作(因为机器上部署的应用什么都要做,根本就无法进行针对性的调优)等因素,根据这样的分析,开始痛下决心,将系统根据职责进行拆分,于是一个大型的分布式应用就诞生了,通常,这个步骤需要耗费相当长的时间,因为会碰到很多的挑战:
a.拆成分布式后需要提供一个高性能、稳定的通信框架,并且需要支持多种不同的通信和远程调用方式;
b.将一个庞大的应用拆分需要耗费很长的时间,需要进行业务的整理和系统依赖关系的控制等;
c.如何运维(依赖管理、运行状况管理、错误追踪、调优、监控和报警等)好这个庞大的分布式应用。
经过这一步,差不多系统的架构进入相对稳定的阶段,同时也能开始采用大量的廉价机器来支撑着巨大的访问量和数据量,结合这套架构以及这么多次演变过程吸取的经验来采用其他各种各样的方法来支撑着越来越高的访问量。
看看这一步完成后系统的图示:
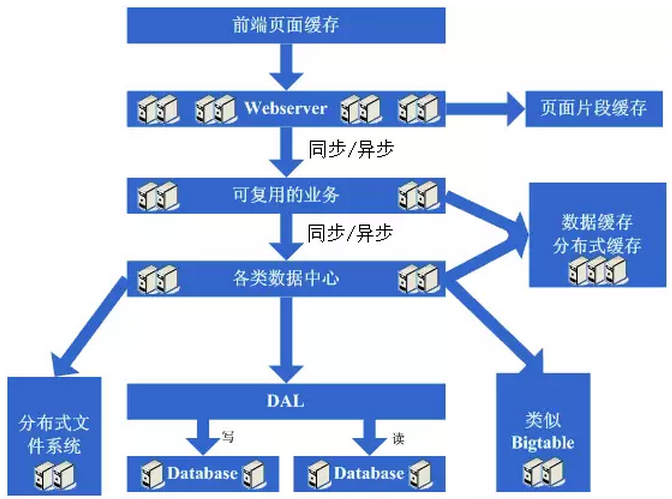
这一步涉及到了这些知识体系:
这一步涉及的知识体系非常的多,要求对通信、远程调用、消息机制等有深入的理解和掌握,要求的都是从理论、硬件级、操作系统级以及所采用的语言的实现都有清楚的理解。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









