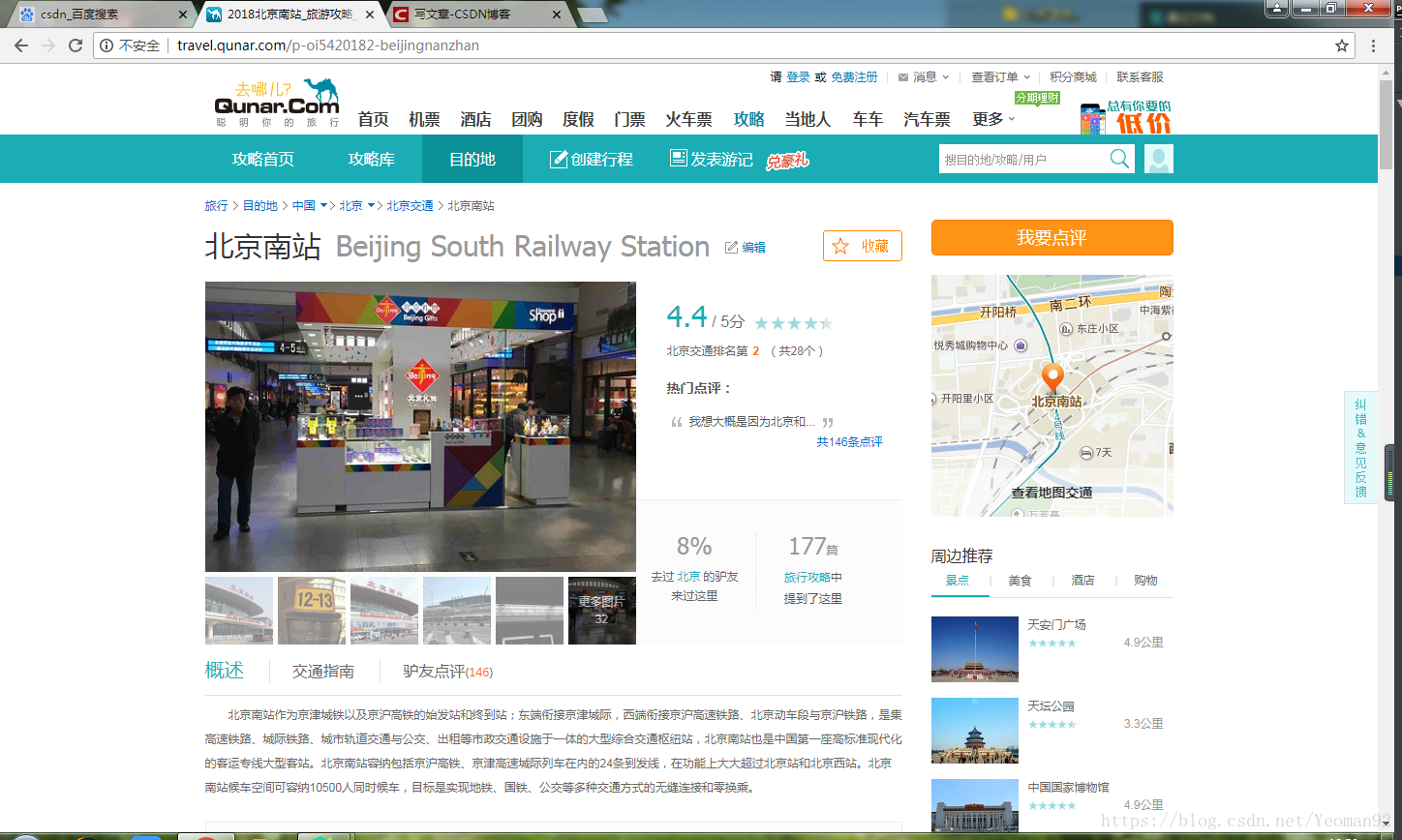
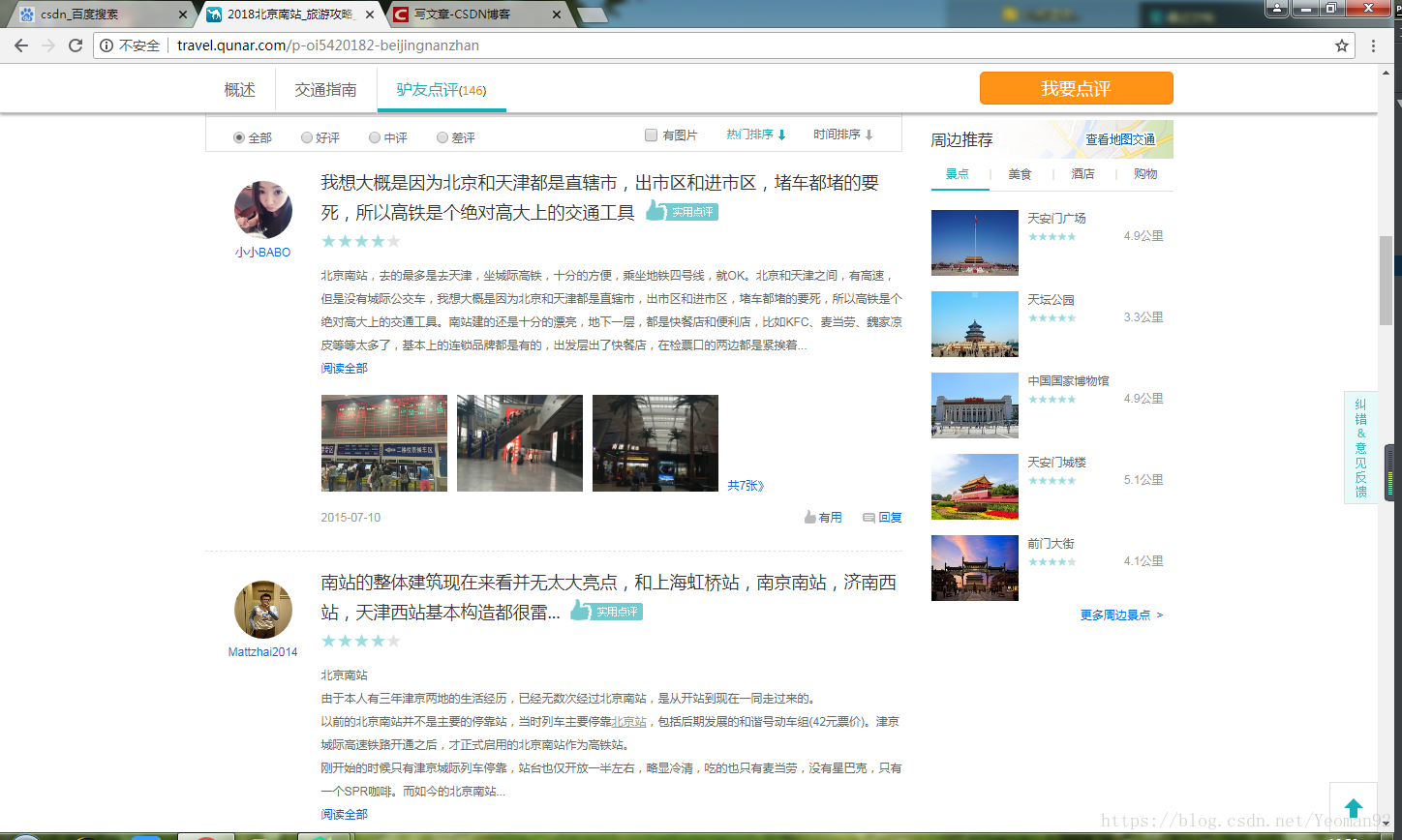
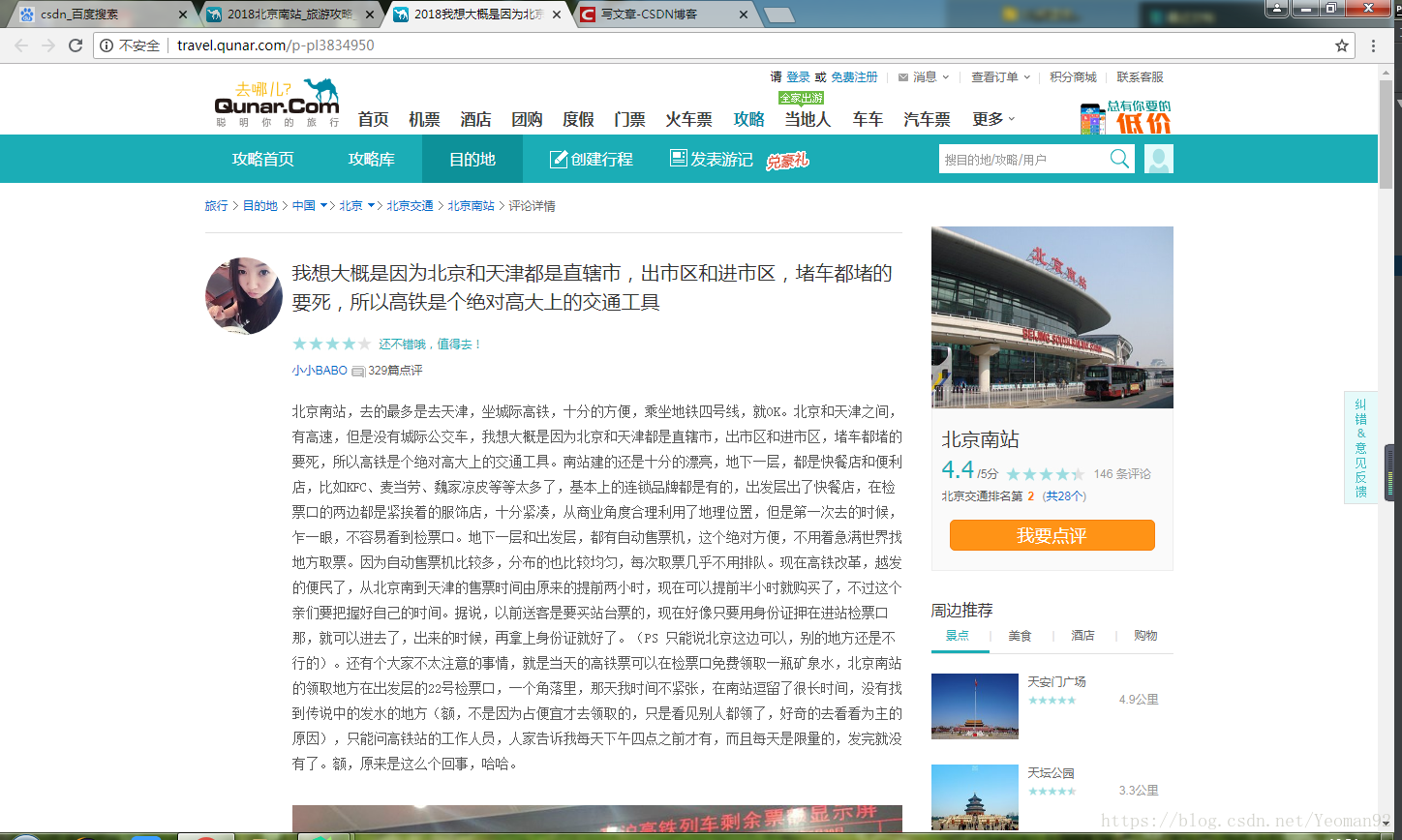
爬取页面截图
词云效果
title


代码
数据抓取
import urllib.request
from lxml import etree
import os
def get_page(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
def get_data_comment(html):
selector = etree.HTML(html)
str_title = selector.xpath('//div[@class="comment_title"]/h2/text()')[0]
list_comment = selector.xpath('//div[@class="comment_content"]/p/text()')
str_comment = ''
for comment in list_comment:
str_comment += comment + ' '
print(str_title)
return str_title.replace('\n', ''), str_comment.replace('\n', '')
def write_data_wc(item_name, write_str):
print(write_str)
path_file = "./data/wc/" + item_name + ".txt"
with open(path_file, 'w', encoding='utf8') as file:
file.write(write_str)
def write_data(write_str):
path_file = "./data/data.txt"
with open(path_file, 'a', encoding='utf8') as file:
file.write(write_str)
def craw(root_url):
path_file = "./data/data.txt"
if os.path.exists(path_file):
os.remove(path_file)
html = get_page(root_url)
selector = etree.HTML(html)
str_total_num = selector.xpath('//div[@class="b_paging"]/a[last()-1]/text()')[0]
total_num = int(str_total_num)
url_front = 'http://travel.qunar.com/p-oi5420182-beijingnanzhan-1-'
list_url = []
for i in range(1, total_num + 1):
list_url.append(url_front + str(i))
lsit_url_comment_page = []
for url in list_url:
html = get_page(url)
selector = etree.HTML(html)
lsit_url_comment_pre_page = selector.xpath('//ul[@id="comment_box"]/li/div[@class="e_comment_main"]//div[@class="e_comment_title"]/a/@href')
for index, url_comment in enumerate(lsit_url_comment_pre_page):
lsit_url_comment_page.append(url_comment)
str_title = ''
str_comment = ''
for url in lsit_url_comment_page:
print(url)
html = get_page(url)
str_title_pre, str_comment_pre = get_data_comment(html)
str_write = '@@title@@' + '\t\t' + str_title_pre + '\n' + '@@comment@@' + '\t\t' + str_comment_pre + '\n' + '--------------------------------------------' + '\n'
write_data(str_write)
str_title += str_title_pre + ' '
str_comment += str_comment_pre + ' '
write_data_wc('title', str_title.replace('\n', '').replace(' ', ''))
write_data_wc('comment', str_comment.replace('\n', ''))
if __name__ == '__main__':
craw(root_url = 'http://travel.qunar.com/p-oi5420182-beijingnanzhan')
词云
from os import path
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
import jieba
def load_txt(item_name):
with open('./data/wc/' + item_name +'.txt', 'r', encoding='utf8') as file_item:
str_item = file_item.read()
return str_item
def fenci(str_text):
seg_list = list(jieba.cut(str_text, cut_all=True))
return seg_list
def count_keywords(item_name):
str_item = load_txt(item_name)
list_keywords = fenci(str_item)
dict_keywords_item = {}
for keyword in list_keywords:
if len(keyword) > 1:
if keyword not in dict_keywords_item:
dict_keywords_item[keyword] = 1
else:
dict_keywords_item[keyword] += 1
if '' in dict_keywords_item:
del dict_keywords_item['']
return dict_keywords_item
def wordcloud(item_name, mask_img):
dict_keywords_item = count_keywords(item_name)
image = Image.open("./img/mask/" + mask_img)
graph = np.array(image)
wc = WordCloud(font_path='./fonts/MSYH.TTC', background_color="black", max_words=50, mask=graph,
stopwords=set(STOPWORDS))
wc.generate_from_frequencies(dict_keywords_item)
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.figure()
plt.imshow(graph, cmap=plt.cm.gray, interpolation='bilinear')
plt.axis("off")
wc.to_file(path.join("./img/" + item_name + '.png'))
if __name__ == '__main__':
wordcloud('title', 'mask.png')
wordcloud('comment', 'mask.png')






















 2637
2637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









