







Python和C语言实现:GitHub 代码地址
1、 排序算法概述
排序算法(英语:Sorting algorithm)是一种能将一串数据依照特定顺序进行排列的一种算法。
1.1、算法分类
十种常见排序算法可以分为两大类:
非线性时间比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此称为非线性时间比较类排序。
线性时间非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。
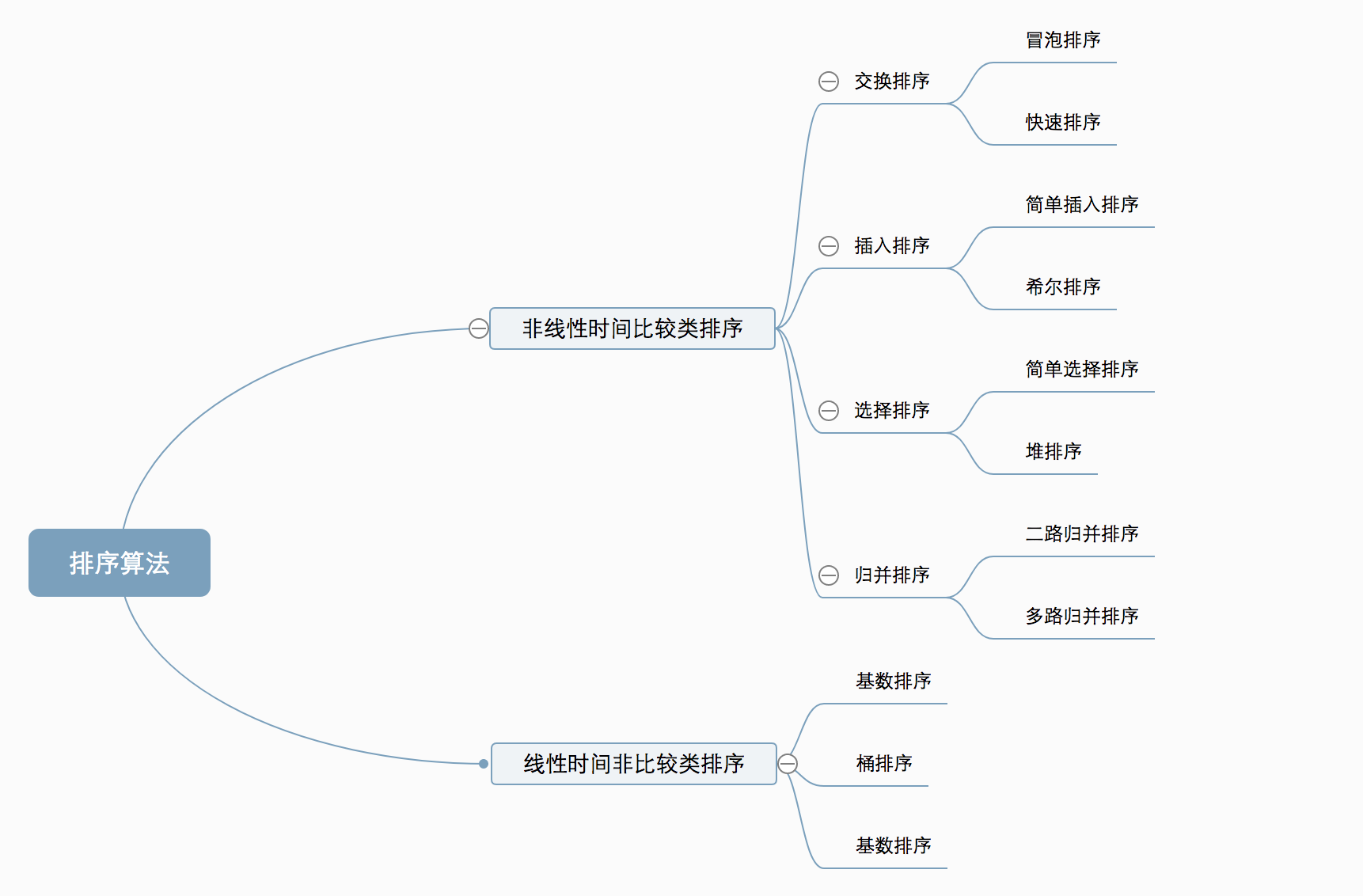
排序算法分类
1.2、算法复杂度
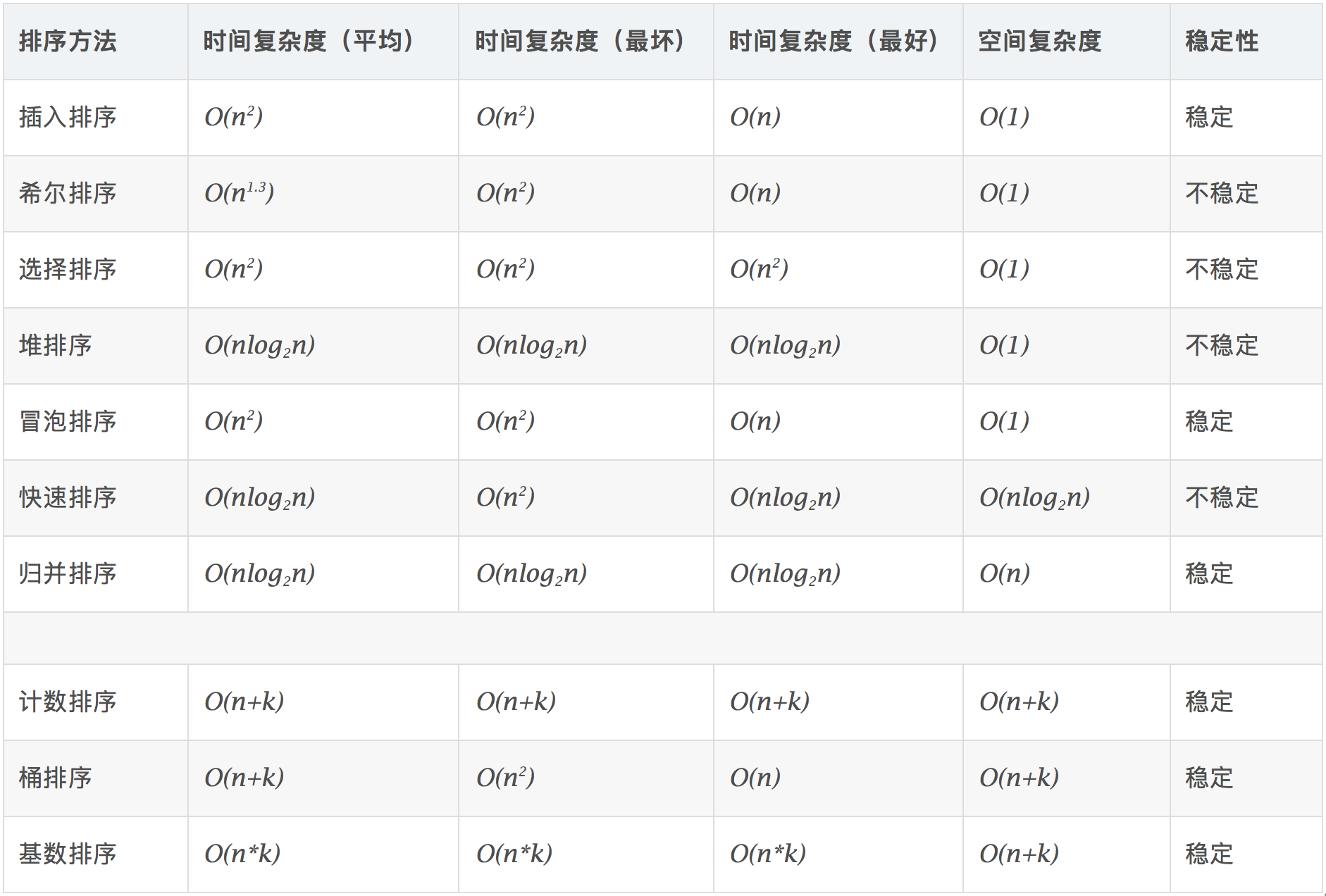
算法复杂度
1.3、相关概念
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
2、冒泡排序(Bubble Sort)
冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。
2.1、算法描述(参考《大话数据结构》)
比较相邻的元素。如果第一个比第二个大,就交换它们两个;
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
针对所有的元素重复以上的步骤,除了最后一个;
重复步骤1~3,直到排序完成。
2.2、冒泡排序算法动画演示
冒泡排序的动画演示
2.3、冒泡排序完整代码
# coding: utf-8
import random
'''
冒泡排序(Bubble Sort)
思路:
1.比较相邻的元素。如果第一个比第二个大,就交换它们两个;
2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
3.针对所有的元素重复以上的步骤,除了最后一个;
4.重复步骤1~3,直到排序完成。
参见 https://blog.csdn.net/yeqiang19910412/article/details/81482061
编程环境:
Python3.5.2
作者:
CSDN博客:https://my.csdn.net/yeqiang19910412
Github:https://github.com/YeQiang1075736553
日期:
2018.8.13
'''
#############################
# Bubble sort
# Time complexity:
# - Best: O(n)
# - Average: O(n^2)
# - Worst: O(n^2)
# Space complexity: O(1)
# Stability: Yes
#############################
class Sort():
def __init__(self,data_list):
self.data_list = data_list
self.length = len(data_list)
def bubble_sort(self):
"""冒泡排序"""
list = self.data_list
for i in range(self.length-1,0,-1):
for j in range(i):
if list[j] > list[j+1]:
list[j],list[j+1] = list[j+1],list[j]
return list
def bubble_sort_advanced(self):
"""改进冒泡排序,,当某一轮跑完,不存在数据交换时,代表已排序完成,此时退出,时间复杂度为O(n^2)"""
list = self.data_list
flag = True # 记录是否发生交换信息
for i in range(self.length-1,0,-1):
# 如果上一轮存在数据交换
if flag:
flag = False
for j in range(i):
if list[j] > list[j+1]:
list[j], list[j+1] = list[j+1], list[j]
flag = True # 如果有数据交换
# 否则,目前序列已经排序完毕
else:
break
return list
def bubble_sort_advanced_2(self):
"""双向冒泡排序(鸡尾酒排序),因为未发生交换操作的区域是有序的,故每轮扫描下来可以更新上下边界,减少扫描范围"""
list = self.data_list
low = 0
high = self.length-1
while low < high:
swap_pos = low # 先假设最后一次发生交换操作的位置为low
for i in range(low,high): # 顺序扫描list[low...high-1]
if list[i] > list[i+1]:
list[i],list[i+1] = list[i+1],list[i]
swap_pos = i
high = swap_pos
for i in range(high,low,-1): # 逆序扫描list[low+1...high]
if list[i] < list[i-1]:
list[i],list[i-1] = list[i-1],list[i]
swap_pos = i
low = swap_pos
return list
if __name__ == '__main__':
data = [54,26,93,17,77,31,44,55,20]
sort = Sort(data)
# data_list = []
# for i in range(100):
# data_list.append(random.randint(0, 100))
# print("冒泡排序")
# bubble_sort = sort.bubble_sort()
# print(bubble_sort)
# print("改进冒泡排序")
# bubble_sort = sort.bubble_sort_advanced()
# print(bubble_sort)
print("双向冒泡排序")
bubble_sort = sort.bubble_sort_advanced_2()
print(bubble_sort)主要参考文献1、2、3、4。
3、快速排序(Quick Sort)
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
3.1、算法描述(参考《大话数据结构》)
快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
3.2、快速排序算法优化
3.2.1、最基本的快速排序
代码:
def quick_sort(self,data_list,start,end):
"""快速排序,时间复杂度为O(nlog₂n)"""
if start < end:
pivot = self.partition(data_list,start,end) # 基准位置
self.quick_sort(data_list,start,pivot-1)
self.quick_sort(data_list,pivot+1,end)
def partition(self,data_list,start,end):
# low为序列左边的由左向右移动的游标
low = start
# high为序列右边的由右向左移动的游标
high = end
# 设定起始元素为要寻找位置的基准值
pivot_key = data_list[start]
while low < high:
# 如果low和high未重合,high指向的元素值大于基准值,则high向左移动
while low < high  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 54
54











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









