









spark 2.1 设置日志级别很简单 下面几行代码就可以搞定 主要是下面画横线的代码
val conf = new SparkConf().setAppName("FlumePollWordCount").setMaster("local[2]") val sc = new SparkContext(conf) sc.setLogLevel("WARN") val ssc = new StreamingContext(sc, Seconds(5))
spark streaming 是实时计算
spark core 之类的涉及到rdd的是离线计算
所以说spark即是实时计算,又有离线计算
spark streaming 的第一个例子
利用 nc -lk 8888 在192.168.235.128的8888端口开启一个输入消息的应用
在IDEA上建立一个spark streaming的程序
package com.wxa.spark.four
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object StreamingWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("StreamingWordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
val ssc =new StreamingContext(sc ,Seconds(5))
//Dstream 是个特殊的RDD (有序)
val ds =ssc.socketTextStream("192.168.235.128",8888)
val result = ds.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
result.print() //这里不能用print(result) print是一个action
ssc.start()
ssc.awaitTermination()
}
}
spark 和 flume相结合
flume-poll.conf 文件的编写+IDEA端FlumePollWordCount代码编写
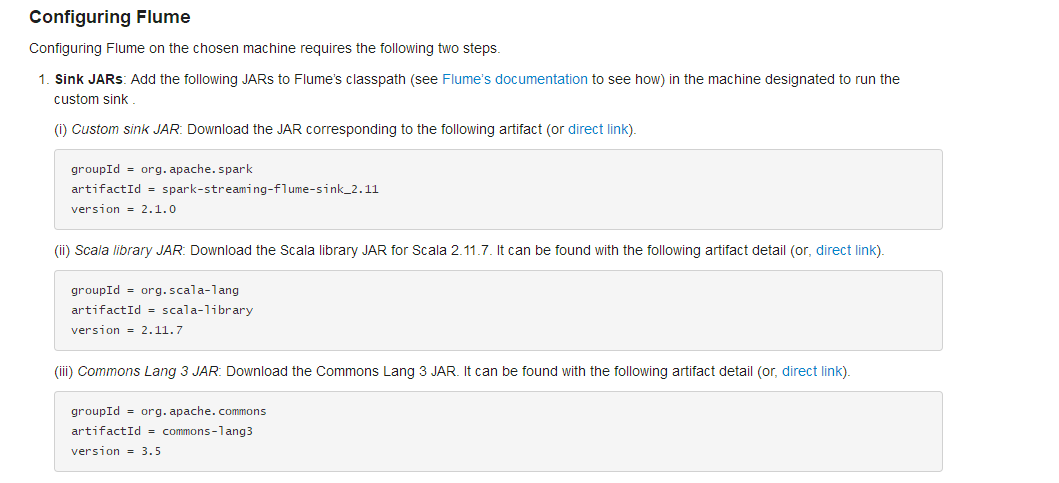
先把下面的三个jar包下载下来 放到 flume的lib目录下
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /export/data/flume
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink
a1.sinks.k1.hostname = master
a1.sinks.k1.port = 8888
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1IDEA端:package com.wxa.spark.five
import java.net.InetSocketAddress
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object FlumePollWordCount {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("FlumePollWordCount").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5))
//从flume中拉取数据(flume的地址)
val address = Seq(new InetSocketAddress("192.168.235.128", 8888))
val flumeStream = FlumeUtils.createPollingStream(ssc, address, StorageLevel.MEMORY_AND_DISK)
val words = flumeStream.flatMap(x => new String(x.event.getBody().array()).split(" ")).map((_,1))
val results = words.reduceByKey(_+_)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
flume-push.conf 文件的编写+IDEA端FlumePushWordCount 代码
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /export/data/flume
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = avro
#这是接收方
a1.sinks.k1.hostname = 192.168.235.1 //这是widows上的地址
a1.sinks.k1.port = 8888
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
IDEA端:object FlumePushWordCount {
def main(args: Array[String]) {
// val host = args(0)
// val port = args(1).toInt
val conf = new SparkConf().setAppName("FlumeWordCount").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5))
//推送方式: flume向spark发送数据
val flumeStream = FlumeUtils.createStream(ssc, "192.168.235.1", 8888) //这是widows上的地址
//flume中的数据通过event.getBody()才能拿到真正的内容
val words = flumeStream.flatMap(x => new String(x.event.getBody().array()).split(" ")).map((_, 1))
val results = words.reduceByKey(_ + _)
results.print()
ssc.start()
ssc.awaitTermination()
}
}spark streaming和flume结合图形概述
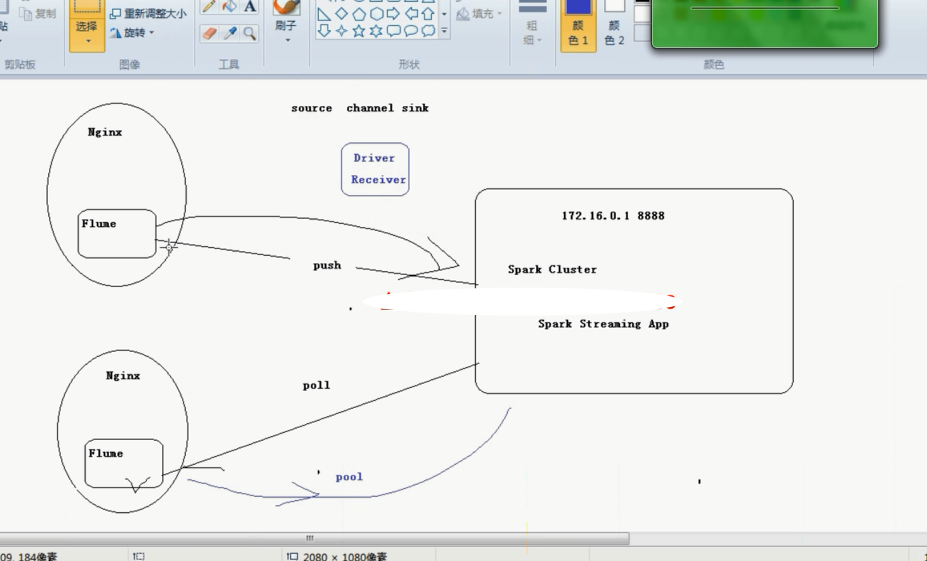
spark如果只与flume结合有它的弊端,spark会在woker的excutor中开启一个reciver而不是在driver里面开启一个recevier,所以在集群中跑的时候需要指定的是woker的地址,由于所有的东西都是由一个reciver来处理的所以当数据量大的时候,recevier可能负载不过来
sparkstreaming 和kafka的结合
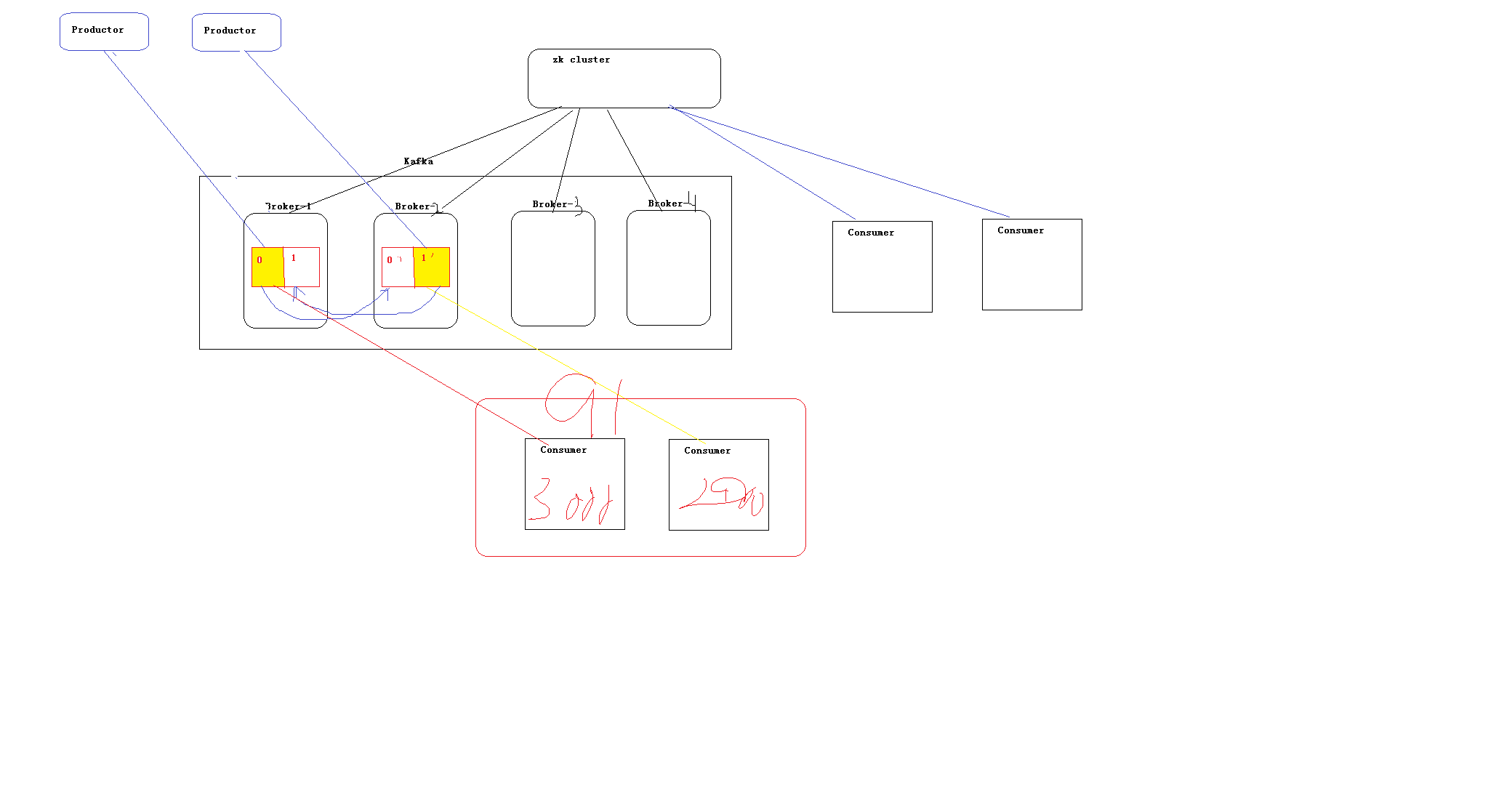
producer和brokerlist建立连接,consumer与zk建立连接,consumer分组的意义在于:同一分组的机子多台机子当一台机子用,比如producer产生5000条数据,有两台机子是同一个分组的 机子1最后消费了3000条数据,机子2消费了2000条数据,加起来消费了5000条数据
添加pom配置
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka_2.11</artifactId> <version>1.6.3</version> </dependency>
话不多说上代码
package com.wxa.spark.five
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by root on 2016/5/21.
*/
object KafkaWordCount {
val updateFunc = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
//iter.flatMap(it=>Some(it._2.sum + it._3.getOrElse(0)).map(x=>(it._1,x)))
iter.flatMap { case (x, y, z) => Some(y.sum + z.getOrElse(0)).map(i => (x, i)) }
}
def main(args: Array[String]) {
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc, Seconds(5))
ssc.checkpoint("f://ck2") //等同于sc的setCheckpointDir
//"alog-2016-04-16,alog-2016-04-17,alog-2016-04-18"
//"Array((alog-2016-04-16, 2), (alog-2016-04-17, 2), (alog-2016-04-18, 2))"
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val data = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap)
val words = data.map(_._2).flatMap(_.split(" "))
val wordCounts = words.map((_, 1)).updateStateByKey(updateFunc, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
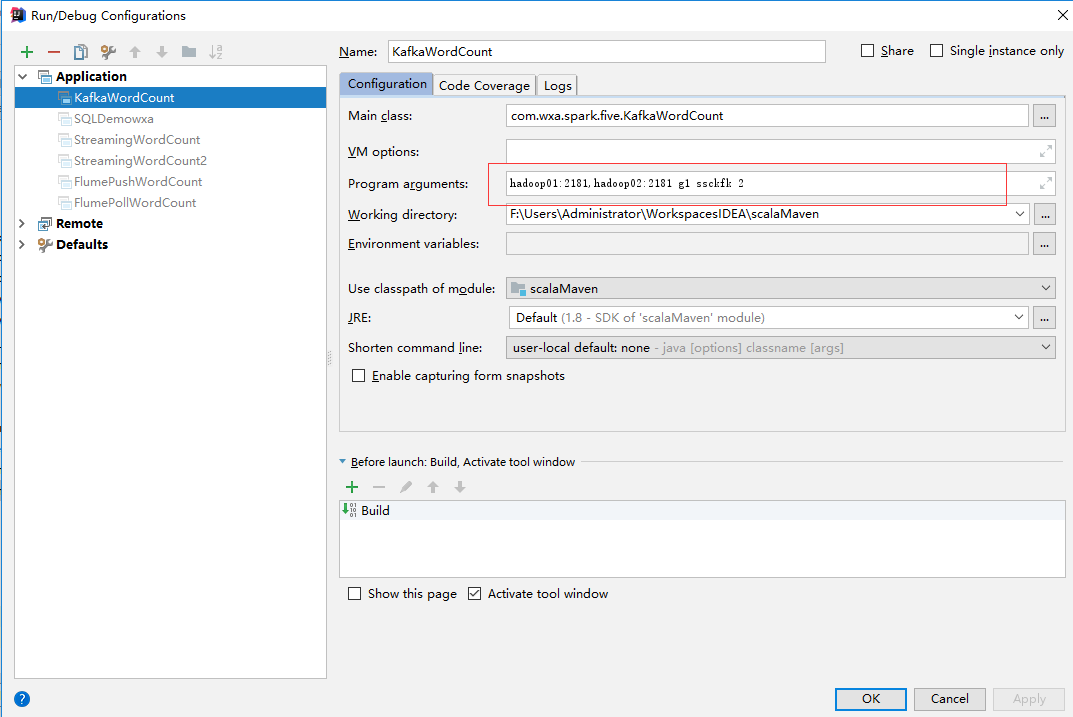
}传入的参数如下图
Spark升级到2.0后测试stream-kafka测试报java.lang.NoClassDefFoundError: org/apache/spark/Logging错误
解决方案:
spark-core_2.11-1.5.2.logging.jar包的下载地址
解决方法详解:将上面的jar包下载下来,放到如下图所示 spark2.1.0(本人用的是这个版本)的jar目录下
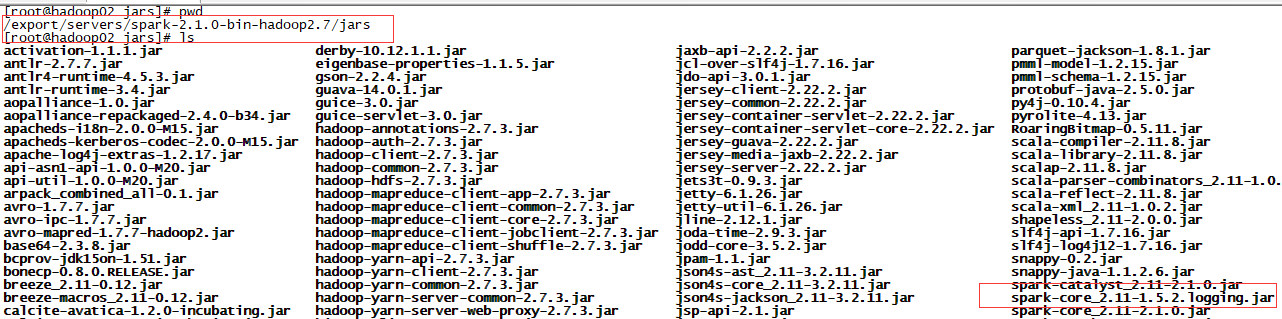
在IDEA 中点击
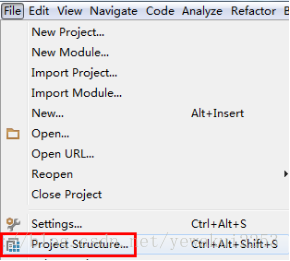
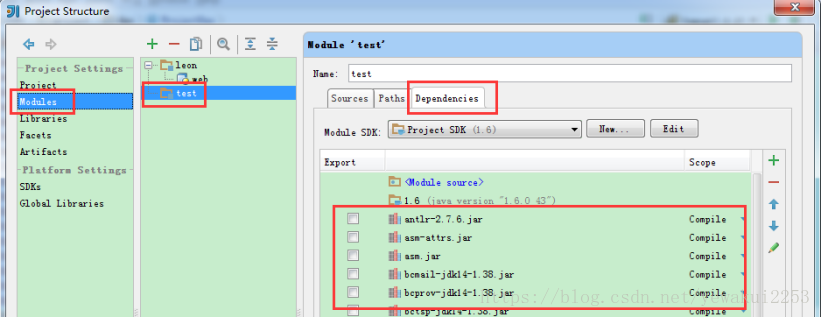
在dependencies中 导入jar包
即可解决java.lang.NoClassDefFoundError: org/apache/spark/Logging错误
接下来要解决的是弄一个生产者
kafka-console-producer.sh --broker-list hadoop01:9092 hadoop02:9092 --topic ssckfk
往里面输入数据IDEA端的sprkstreaming 就可以接收到
窗口函数(主要的是reduceByKeyAndWindow这个函数)
示例图:两者并没有重复计算 10:15 这个数据
计算的时间段内的数据
如:
18:10:00 到 10:15 这段 是30 10:15 到 10:25 是 70

package com.wxa.spark.sixday
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Milliseconds, Seconds, StreamingContext}
/**
* Created by ZX on 2016/4/19.
*/
object WindowOpts {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("WindowOpts").setMaster("local[2]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc, Milliseconds(5000))
val lines = ssc.socketTextStream("192.168.235.128", 9999)
val pairs = lines.flatMap(_.split(" ")).map((_, 1))
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(15), Seconds(10)) //窗口的长度和滑动间隔必须是批次的倍数才行
//Map((hello, 5), (jerry, 2), (kitty, 3))
windowedWordCounts.print()
// val a = windowedWordCounts.map(_._2).reduce(_+_)
// a.foreachRDD(rdd => {
// println(rdd.take(0))
// })
// a.print()
// //windowedWordCounts.map(t => (t._1, t._2.toDouble / a.toD))
// windowedWordCounts.print()
// //result.print()
ssc.start()
ssc.awaitTermination()
}
}
spark+kafka 的两种连接方式
方式一 (有reciver)通过zk进行连接
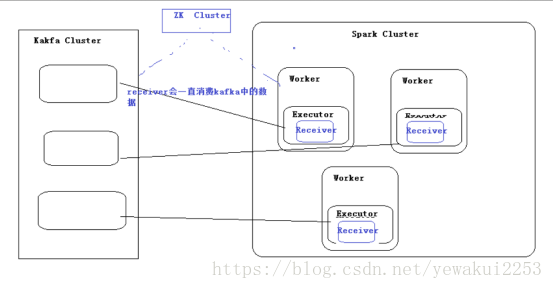
方式二 (没有reciver)通过broker list 来连接
相比较前一种优点:
1 高效
2 要自己管理偏移量(前一种是交给zk管理偏移量),但是更加灵活
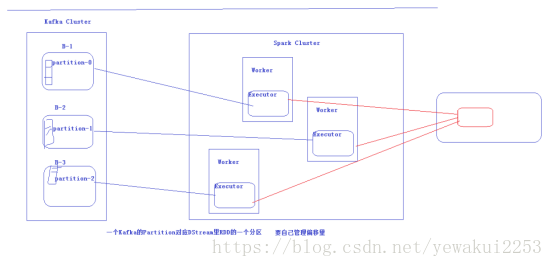
必须新建一个 org.apache.spark.streaming.kafka 的包 才能在自己写的kafkamanager中正常使用kafkacluster
kafkamanager 代码
package org.apache.spark.streaming.kafka
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.Decoder
import org.apache.spark.SparkException
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.KafkaCluster.LeaderOffset
import scala.reflect.ClassTag
/**
* 自己管理offset
*/
class KafkaManager(val kafkaParams: Map[String, String]) extends Serializable {
private val kc = new KafkaCluster(kafkaParams)
/**
* 创建数据流
*/
def createDirectStream[K: ClassTag, V: ClassTag, KD <: Decoder[K]: ClassTag, VD <: Decoder[V]: ClassTag](
ssc: StreamingContext, kafkaParams: Map[String, String], topics: Set[String]): InputDStream[(K, V)] = {
val groupId = kafkaParams.get("group.id").get
// 在zookeeper上读取offsets前先根据实际情况更新offsets
setOrUpdateOffsets(topics, groupId)
//从zookeeper上读取offset开始消费message
val messages = {
val partitionsE = kc.getPartitions(topics)
if (partitionsE.isLeft)
throw new SparkException(s"get kafka partition failed: ${partitionsE.left.get}")
val partitions = partitionsE.right.get
val consumerOffsetsE = kc.getConsumerOffsets(groupId, partitions)
if (consumerOffsetsE.isLeft)
throw new SparkException(s"get kafka consumer offsets failed: ${consumerOffsetsE.left.get}")
val consumerOffsets = consumerOffsetsE.right.get
KafkaUtils.createDirectStream[K, V, KD, VD, (K, V)](
ssc, kafkaParams, consumerOffsets, (mmd: MessageAndMetadata[K, V]) => (mmd.key, mmd.message))
}
messages
}
/**
* 创建数据流前,根据实际消费情况更新消费offsets
* @param topics
* @param groupId
*/
private def setOrUpdateOffsets(topics: Set[String], groupId: String): Unit = {
topics.foreach(topic => {
var hasConsumed = true
val partitionsE = kc.getPartitions(Set(topic))
if (partitionsE.isLeft)
throw new SparkException(s"get kafka partition failed: ${partitionsE.left.get}")
val partitions = partitionsE.right.get
val consumerOffsetsE = kc.getConsumerOffsets(groupId, partitions)
if (consumerOffsetsE.isLeft) hasConsumed = false
if (hasConsumed) {// 消费过
/**
* 如果streaming程序执行的时候出现kafka.common.OffsetOutOfRangeException,
* 说明zk上保存的offsets已经过时了,即kafka的定时清理策略已经将包含该offsets的文件删除。
* 针对这种情况,只要判断一下zk上的consumerOffsets和earliestLeaderOffsets的大小,
* 如果consumerOffsets比earliestLeaderOffsets还小的话,说明consumerOffsets已过时,
* 这时把consumerOffsets更新为earliestLeaderOffsets
*/
val earliestLeaderOffsetsE = kc.getEarliestLeaderOffsets(partitions)
if (earliestLeaderOffsetsE.isLeft)
throw new SparkException(s"get earliest leader offsets failed: ${earliestLeaderOffsetsE.left.get}")
val earliestLeaderOffsets = earliestLeaderOffsetsE.right.get
val consumerOffsets = consumerOffsetsE.right.get
// 可能只是存在部分分区consumerOffsets过时,所以只更新过时分区的consumerOffsets为earliestLeaderOffsets
var offsets: Map[TopicAndPartition, Long] = Map()
consumerOffsets.foreach({ case(tp, n) =>
val earliestLeaderOffset = earliestLeaderOffsets(tp).offset
if (n < earliestLeaderOffset) {
println("consumer group:" + groupId + ",topic:" + tp.topic + ",partition:" + tp.partition +
" offsets已经过时,更新为" + earliestLeaderOffset)
offsets += (tp -> earliestLeaderOffset)
}
})
if (!offsets.isEmpty) {
kc.setConsumerOffsets(groupId, offsets)
}
} else {// 没有消费过
val reset = kafkaParams.get("auto.offset.reset").map(_.toLowerCase)
var leaderOffsets: Map[TopicAndPartition, LeaderOffset] = null
if (reset == Some("smallest")) {
val leaderOffsetsE = kc.getEarliestLeaderOffsets(partitions)
if (leaderOffsetsE.isLeft)
throw new SparkException(s"get earliest leader offsets failed: ${leaderOffsetsE.left.get}")
leaderOffsets = leaderOffsetsE.right.get
} else {
val leaderOffsetsE = kc.getLatestLeaderOffsets(partitions)
if (leaderOffsetsE.isLeft)
throw new SparkException(s"get latest leader offsets failed: ${leaderOffsetsE.left.get}")
leaderOffsets = leaderOffsetsE.right.get
}
val offsets = leaderOffsets.map {
case (tp, offset) => (tp, offset.offset)
}
kc.setConsumerOffsets(groupId, offsets)
}
})
}
/**
* 更新zookeeper上的消费offsets
* @param rdd
*/
def updateZKOffsets(rdd: RDD[(String, Long)]) : Unit = {
val groupId = kafkaParams.get("group.id").get
val offsetsList = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
for (offsets <- offsetsList) {
val topicAndPartition = TopicAndPartition(offsets.topic, offsets.partition)
val o = kc.setConsumerOffsets(groupId, Map((topicAndPartition, offsets.untilOffset)))
if (o.isLeft) {
println(s"Error updating the offset to Kafka cluster: ${o.left.get}")
}
}
}
}
DirectKafkaWordCount代码
package com.wxa.spark.five
import kafka.serializer.StringDecoder
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.kafka.{KafkaManager, KafkaUtils}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DirectKafkaWordCount {
/* def dealLine(line: String): String = {
val list = line.split(',').toList
// val list = AnalysisUtil.dealString(line, ',', '"')// 把dealString函数当做split即可
list.get(0).substring(0, 10) + "-" + list.get(26)
}*/
def processRdd(rdd: RDD[(String, String)]): Unit = {
val lines = rdd.map(_._2)
val words = lines.map(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.foreach(println)
}
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println(
s"""
|Usage: DirectKafkaWordCount <brokers> <topics> <groupid>
| <brokers> is a list of one or more Kafka brokers
| <topics> is a list of one or more kafka topics to consume from
| <groupid> is a consume group
|
""".stripMargin)
System.exit(1)
}
Logger.getLogger("org").setLevel(Level.WARN)
val Array(brokers, topics, groupId) = args
// Create context with 2 second batch interval
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
sparkConf.setMaster("local[*]")
sparkConf.set("spark.streaming.kafka.maxRatePerPartition", "5")
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// Create direct kafka stream with brokers and topics
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String](
"metadata.broker.list" -> brokers,
"group.id" -> groupId,
"auto.offset.reset" -> "smallest"
)
val km = new KafkaManager(kafkaParams) //和KafkaUtils.createDirectStream()创建直接流基本一致
val messages = km.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
// messages.foreachRDD(rdd => {
// if (!rdd.isEmpty()) {
// // 先处理消息
// processRdd(rdd)
// // 再更新offsets
// km.updateZKOffsets(rdd)
// }
// })
ssc.start()
ssc.awaitTermination()
}
}















 2149
2149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











