







接触到pooling主要是在用于图像处理的卷积神经网络中,但随着深层神经网络的发展,pooling相关技术在其他领域,其他结构的神经网络中也越来越受关注。一个典型的卷积神经网络结构图,其中的卷积层是对图像的一个邻域进行卷积得到图像的邻域特征,亚采样层就是使用pooling技术将小邻域内的特征点整合得到新的特征。
作用
pooling的结果是使得特征减少,参数减少,但pooling的目的并不仅在于此。
pooling目的是为了保持某种不变性(旋转、平移、伸缩等)
分类
常用的有mean-pooling,max-pooling和Stochastic-pooling三种。
mean-pooling,即对邻域内特征点只求平均,
max-pooling,即对邻域内特征点取最大。
根据相关理论,特征提取的误差主要来自两个方面:
(1)邻域大小受限造成的估计值方差增大;
(2)卷积层参数误差造成估计均值的偏移。
一般来说
mean-pooling能减小第一种误差(邻域大小受限造成的估计值方差增大),更多的保留图像的背景信息,
max-pooling能减小第二种误差(卷积层参数误差造成估计均值的偏移),更多的保留纹理信息。
Stochastic-pooling则介于两者之间,通过对像素点按照数值大小赋予概率,再按照概率进行亚采样,在平均意义上,与mean-pooling近似,在局部意义上,则服从max-pooling的准则。
LeCun的“Learning Mid-Level Features For Recognition”对前两种pooling方法有比较详细的分析对比,如果有需要可以看下这篇论文。
pooling的反向传播
原则:把1个像素的梯度传递给4个像素,但是需要保证传递的loss(或者梯度)总和不变
对于mean pooling,真的是好简单:假设pooling的窗大小是2x2, 在forward的时候啊,就是在前面卷积完的输出上依次不重合的取2x2的窗平均,得到一个值就是当前mean pooling之后的值。backward的时候,把一个值分成四等分放到前面2x2的格子里面就好了。如下
forward: [1 3; 2 2] -> [2]
backward: [2] -> [0.5 0.5; 0.5 0.5]
max pooling就稍微复杂一点,forward的时候你只需要把2x2窗子里面那个最大的拿走就好了,backward的时候你要把当前的值放到之前那个最大的位置,其他的三个位置都弄成0。如下
forward: [1 3; 2 2] -> 3
backward: [3] -> [0 3; 0 0]
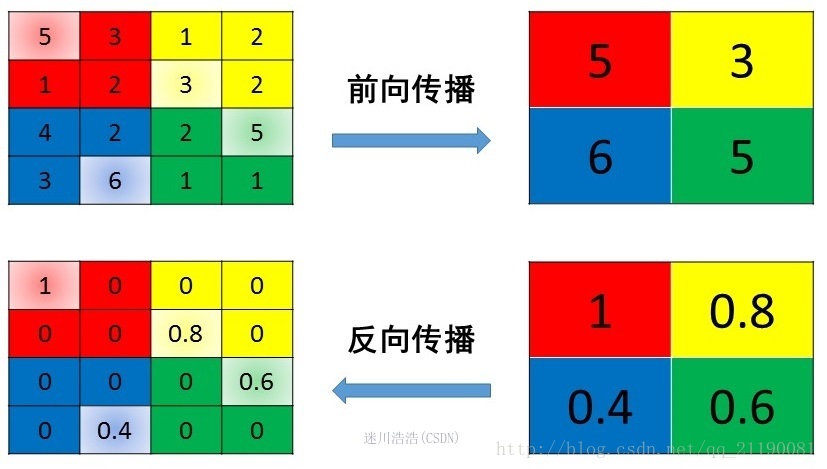
1、mean pooling
mean pooling的前向传播就是把一个patch中的值求取平均来做pooling,那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,这样就保证池化前后的梯度(残差)之和保持不变,还是比较理解的,图示如下
mean pooling比较容易让人理解错的地方就是会简单的认为直接把梯度复制N遍之后直接反向传播回去,但是这样会造成loss之和变为原来的N倍,网络是会产生梯度爆炸的。
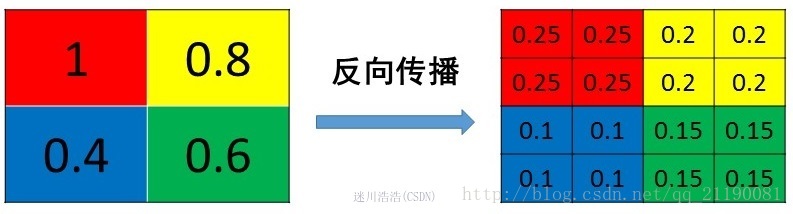
2、max pooling
max pooling也要满足梯度之和不变的原则,max pooling的前向传播是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。所以max pooling操作和mean pooling操作不同点在于需要记录下池化操作时到底哪个像素的值是最大
源码中有一个max_idx_的变量,这个变量就是记录最大值所在位置的,因为在反向传播中要用到,那么假设前向传播和反向传播的过程就如下图所示
https://blog.csdn.net/junmuzi/article/details/53206600
https://blog.csdn.net/qq_21190081/article/details/72871704
对全局平均池化(GAP)过程的理解
对学习Class Activation Mapping(CAM)原文献的时候提到的全局平均池化GAP方法做个简单的知识补充。
所谓的全局就是针对常用的平均池化而言,平均池化会有它的filter size,比如 2 * 2,全局平均池化就没有size,它针对的是整张feature map.
全局平均池化(Global average Pooling)由 M. Lin, Q. Chen, and S. Yan. Network in network. Interna-
tional Conference on Learning Representations, 2014.提出来。
用个简单的例子来说明它的过程,作用请看原文献或者百度。
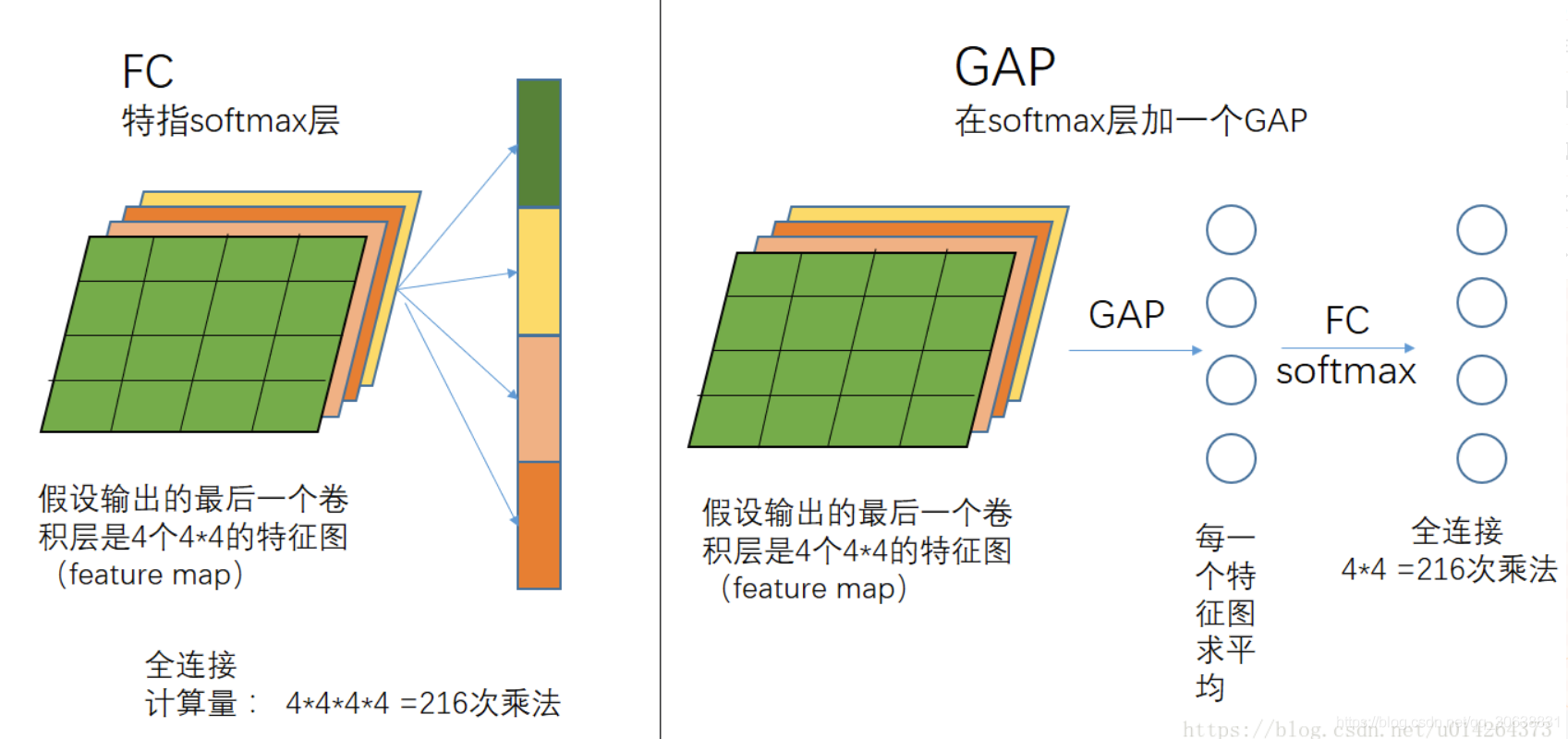
一个feature map 全局平均池化后得到一个值,再进行全连接(softmax)就会少很多参数。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









