






原理:
apriori原理是说如果某个项集时频繁的,那么它的所有子集也是频繁的。
反过来说,如果一个项集是非频繁集,那么它的所有超集也是非频繁的。
apriori算法的实现:
首先,创建数据集:
def loadDataSet():
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return map(frozenset, C1) #将C1转换成frozenset集,以方便后面C1作为字典的key
dataSet=loadDataSet()
C1=createC1(dataSet)
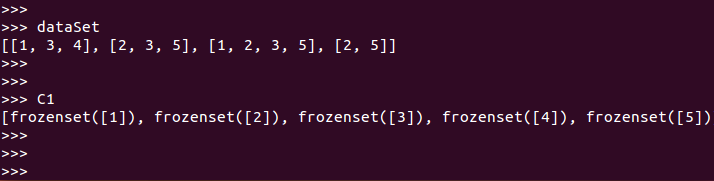
然后,找出符合最小支持度的频繁项集:(D=dataSet; Ck=C1; minSupport=0.5)
def scanD(D, Ck, minSupport):
ssCnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid):
if not ssCnt.has_key(can): ssCnt[can]=1 #两个for之后,ssCnt={{frozenset([4]): 1, frozenset([5]): 3,
else: ssCnt[can] += 1 # frozenset([2]): 3, frozenset([3]): 3, frozenset([1]): 2}
numItems = float(len(D))
retList = []
supportData = {}
for key in ssCnt:
support = ssCnt[key]/numItems
if support >= minSupport:
retList.insert(0,key)
supportData[key] = support
return retList, supportData
retList,supportData=scanD(dataSet,C1,0.5)
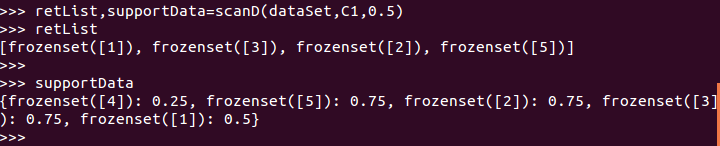
至此,我们得到了两组数据:retList和supportData,其中,retList是大于最小支持度 的frozenset集,而supportData是所有候选频繁项集的支持度字典(后面会使用)。
接下来,我们需要生成所有满足最小支持度的频繁项集(apriori是主函数,主函数调用aprioriGen产生候选频繁项集):
def aprioriGen(Lk, k): #creates Ck
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1, lenLk):
L1 = list(Lk[i])[:k-2]; L2 = list(Lk[j])[:k-2]
L1.sort(); L2.sort()
if L1==L2: #if first k-2 elements are equal
retList.append(Lk[i] | Lk[j]) #符号“|”在python中是集合合并的意思
return retList
def apriori(dataSet, minSupport = 0.5):
C1 = createC1(dataSet)
D = map(set, dataSet)
L1, supportData = scanD(D, C1, minSupport)
L = [L1]
k = 2
while (len(L[k-2]) > 0):
Ck = aprioriGen(L[k-2], k)
Lk, supK = scanD(D, Ck, minSupport) #scan DB to get Lk
supportData.update(supK)
L.append(Lk)
k += 1
return L, supportData
L,supportData=apriori(dataSet,0.5)
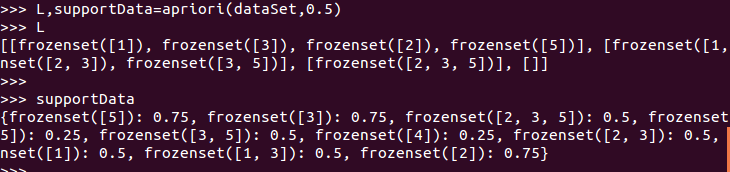
经过以上几个步骤,产生了所有的频繁项集L,现在需要从频繁项集中挖掘关联规则(generateRules是主函数,rulesFromConseq产生候选规则集合,calcConf对规则进行评估并产生出规则):
def generateRules(L, supportData, minConf=0.7): #supportData is a dict coming from scanD
bigRuleList = []
for i in range(1, len(L)): #only get the sets with two or more items
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if (i > 1):
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
else:
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
prunedH = [] #create new list to return
for conseq in H:
conf = supportData[freqSet]/supportData[freqSet-conseq] #calc confidence
if conf >= minConf:
print freqSet-conseq,’–>’,conseq,’conf:’,conf
brl.append((freqSet-conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
if (len(freqSet) > (m + 1)): #try further merging
Hmp1 = aprioriGen(H, m+1) #create Hm+1 new candidates
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1): #need at least two sets to merge
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
rules=generateRules(L,supportData,0.7)
















 3055
3055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









