







概述
Shuffle,即混洗、洗牌,顾名思义就是对数据打乱重新分配。Shuffle发生在Map输出至Reduce的输入过程之间。主要分为两部分
- Map任务输出的数据进行分组、合并、排序,并写入本地磁盘
- Reduce任务拉取数据进行合并、排序
Shuffle过程
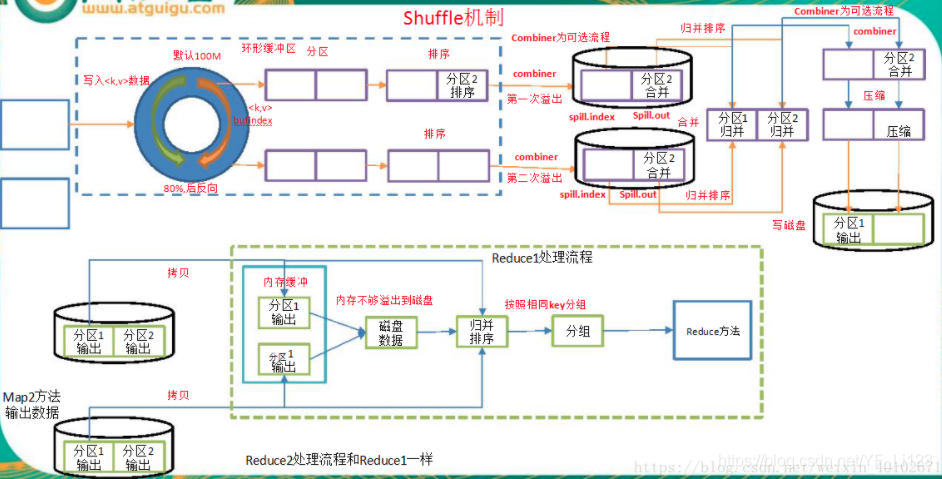
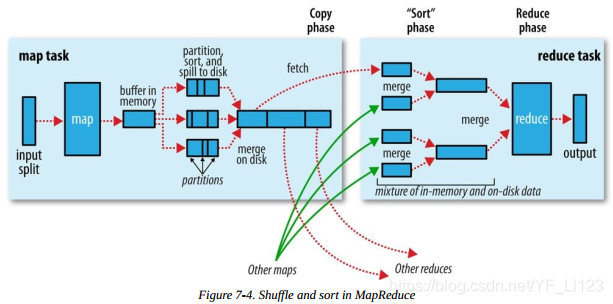
Map端
- Map端输出时,会先将数据写入内存的环形缓冲区,默认大小100M,可通过参数设置
- 当缓冲区的内容大小达到阈值(默认0.8,可通过参数设置),便有一个后台线程将写入缓冲区的数据溢写到磁盘。溢写的过程中Map任务仍然可以写数据到缓冲区,一旦缓冲区写满,Map任务将会被阻塞,知道后台线程写磁盘结束
- 数据溢写到磁盘时会计算输出key的分区,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 636
636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









