







本文用来记录大数据的各项技术,用作技术提纲
一、数据接入
kafka 消息管道 可配置多个缓存副本(推荐)Flume 直接写到目的地,Cloudera开源的一套日志传输系统,和Scribe类似。
Scribe Facebook开源的一套日志传输系统,将源日志传输到Hadoop等分布式文件系统中。
Sqoop 用于传统数据库和Hadoop之间的数据传输。
RDL 结构化和非结构化数据传输组件
Chukwa
Avro
Minos
二、ETL
KettleTalend
三、存储
1、HDFS2、NoSQL
HBase
MongoDB
Cassandra
3、SQL
GBase
MonetDB
GreenPlum
4、缓存
Redis
四、批量处理
Hive 把SQL转为MapReduce任务MapReduce
Pig
五、实时处理
Spark StreamingStorm
六、查询OLAP
ImpalaSpark SQL 跑在Spark上 处理的数据流,推荐
Presto
Drill
七、数据挖掘
R,Mahout八、可视化
Saiku 多维数据查询可视化ECharts
HighCharts
Tableau
Qlik
Pentaho
九、全局-监控
Ganglia
Nagios
十、全局-元数据管理
mysqlZookeeper
Hcatalog
十一、全局-任务调度器
Oozie 多个任务间调度,一般用这个,用于复杂的任务调度Azkaban
Yarn 一般用于调度mapreduce任务,用于简单的任务调度
十二、平台维护
cdh
【友人方案】
虚拟化openstack数据采集是flume+kafka
数据存储用hbase
文件存储nfs
计算用spark
平台维护用的cdh5 百度搜索cdh
检索用的solr
前端展现D3js
【从日志统计到大数据分析】百度
https://zhuanlan.zhihu.com/p/20390103?refer=sangwf
经验总结
1、百度用户行为(百科、搜索、知道等)存成一个逻辑大表, 1000字段,实际根据时间、业务类型,分区分表
并用列存储,宽表结构信息存在数据库中,宽表内容存在HDFS中
2、数据源很重要,成功了一半
结构化日志源 Google Protocol Buffer
格式前后兼容;解析效率高;节省存储和带宽;数据带有Schema
3、Event模型很有效,用户行为分析时,先把数据整理成前面大表,
以免在杂乱数据中分析
4、结构化数据源用Parquet存储很合适,再用impla分析。protobuf行存储不适合
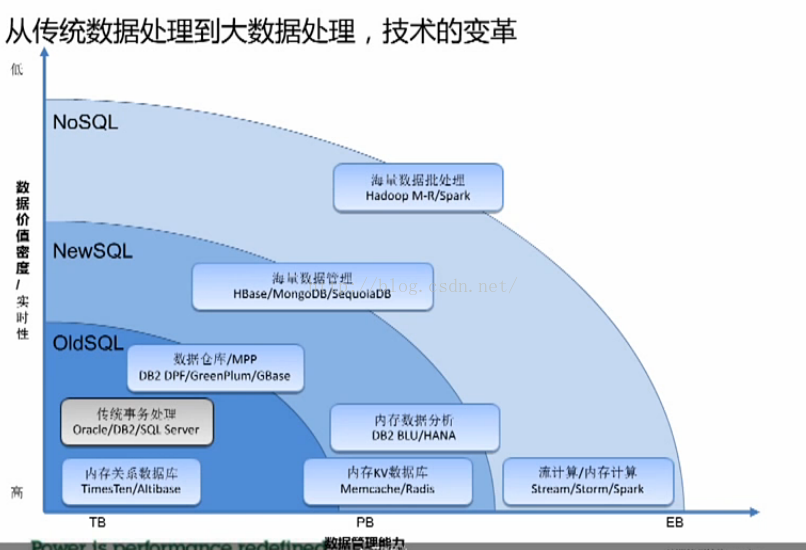
数据层如何选择:















 2205
2205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











