






我有点懒,文章没有排版,就是直接黏贴,为的更多的是自己的记录,如果有人看希望别介意!
2.tfidf 有两种方式,一种是先转换为词频矩阵再转换成tfidf矩阵,另外一种是直接转换成tfidf矩阵,
CountVectorizer和TfidfTransformer、
TfidfVectorizer
http://blog.csdn.net/eastmount/article/details/50323063
Scikit-Learn中TF-IDF权重计算方法主要用到两个类:CountVectorizer和TfidfTransformer。
1.CountVectorizer
CountVectorizer类会将文本中的词语转换为词频矩阵,例如矩阵中包含一个元素a[i][j],它表示j词在i类文本下的词频。它通过fit_transform函数计算各个词语出现的次数,通过get_feature_names()可获取词袋中所有文本的关键字,通过toarray()可看到词频矩阵的结果。
代码如下:
从结果中可以看到,总共包括9个特征词,即:
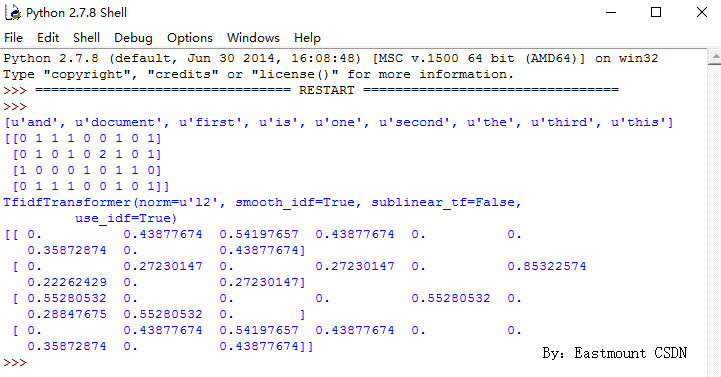
[u'and', u'document', u'first', u'is', u'one', u'second', u'the', u'third', u'this']
同时在输出每个句子中包含特征词的个数。例如,第一句“This is the first document.”,它对应的词频为[0, 1, 1, 1, 0, 0, 1, 0, 1],假设初始序号从1开始计数,则该词频表示存在第2个位置的单词“document”共1次、第3个位置的单词“first”共1次、第4个位置的单词“is”共1次、第9个位置的单词“this”共1词。所以,每个句子都会得到一个词频向量。
2.TfidfTransformer
TfidfTransformer用于统计vectorizer中每个词语的TF-IDF值。具体用法如下:
输出结果入下所示:
3.别人示例
如果需要同时进行词频统计并计算TF-IDF值,则使用核心代码:
vectorizer=CountVectorizer()
transformer=TfidfTransformer()
tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))
下面给出一个liuxuejiang158大神的例子,供大家学习,推荐大家阅读原文:
python scikit-learn计算tf-idf词语权重 - liuxuejiang
# coding=utf-8 mydoclist = [u'温馨 提示 : 家庭 畅享 套餐 介绍 、 主卡 添加 / 取消 副 卡 短信 办理 方式 , 可 点击 文档 左上方 短信 图标 即可 将 短信 指令 发送给 客户', u'客户 申请 i 我家 , 家庭 畅享 计划 后 , 可 选择 设置 1 - 6 个 同一 归属 地 的 中国移动 网 内 号码 作为 亲情 号码 , 组建 一个 家庭 亲情 网 家庭 内 ', u'所有 成员 可 享受 本地 互打 免费 优惠 , 家庭 主卡 号码 还 可 享受 省内 / 国内 漫游 接听 免费 的 优惠'] from sklearn.feature_extraction.text import CountVectorizer # count_vectorizer = CountVectorizer(min_df=1) # term_freq_matrix = count_vectorizer.fit_transform(mydoclist) # print "Vocabulary:", count_vectorizer.vocabulary_ # # from sklearn.feature_extraction.text import TfidfTransformer # # tfidf = TfidfTransformer(norm="l2") # tfidf.fit(term_freq_matrix) # # tf_idf_matrix = tfidf.transform(term_freq_matrix) # print tf_idf_matrix.todense() # from __future__ import print_function from sklearn.feature_extraction.text import TfidfVectorizer tfidf_vectorizer = TfidfVectorizer(min_df=0) tfidf_matrix = tfidf_vectorizer.fit_transform(mydoclist) str = '' for i in tfidf_vectorizer.vocabulary_: str += ' ' + i print str print tfidf_matrix.todense() new_docs = [u'一个'] new_term_freq_matrix = tfidf_vectorizer.transform(new_docs) print tfidf_vectorizer.vocabulary_, type(tfidf_vectorizer.vocabulary_) str = '' for i, j in sorted(tfidf_vectorizer.vocabulary_.items(), key=lambda d: d[1]): str += ' ' + i print str print [v for v in sorted(tfidf_vectorizer.vocabulary_.values())] print sorted(tfidf_vectorizer.vocabulary_.items(), key=lambda d: d[1]) print new_term_freq_matrix.todense()















 624
624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









