






谷歌翻译的,文章末尾有原文链接
介绍
正如我们在前几篇文章中已经看到的,B+树是类树结构中的(键、值)存储方法。B+树有一个根,任意数量的中间节点(通常为一个)和一个叶节点。在这里,所有叶子节点都将存储实际的记录。中间节点只有指向叶子节点的指针;它没有任何数据。任何节点都只有两个叶子。这是任何B+树的基础。
考虑下面的学生表。这可以存储在B+树结构中,如下所示。我们可以看到它将记录分成两部分,并分成左节点和右节点。左节点的值将小于或等于根节点的所有值,而右节点的值将大于根节点。第2级的中间节点只有指向叶子节点的指针。中间节点中显示的值只是指向下一层的指针。所有叶节点都将以排序的顺序拥有实际记录。
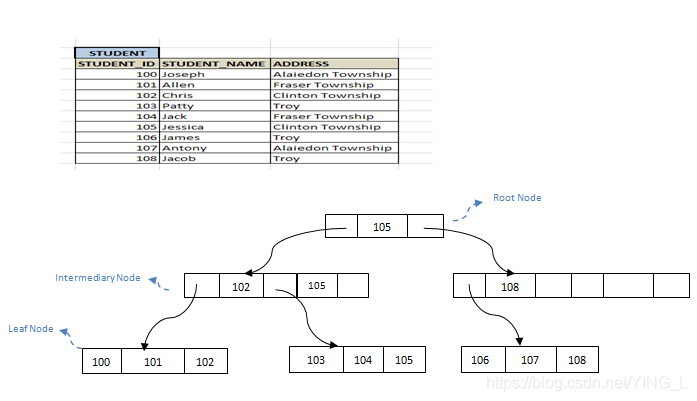
如果我们必须搜索任何记录,它们都可以在叶子节点中找到。因此,由于叶节点的距离相等,搜索任何记录将花费相同的时间。而且它们都是有序的。因此,搜索记录就像顺序搜索,不需要花费太多时间。
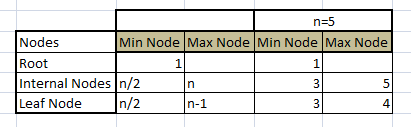
假设B +树的顺序为n(它是分支的数量 - 上面的树结构共有5个分支,因此顺序为5),然后它可以有n / 2到n个中间节点和n / 2到n- 1叶节点。在我们上面的例子中,n = 5即; 它有5个来自root的分支。然后它可以具有范围从3到5的中间节点。并且它可以具有从3到4的叶节点。
B+树的主要作用
-
排序中间节点和叶节点:
由于它是平衡树,因此应对所有节点进行排序。 -
快速遍历和快速搜索:
一个人应该能够非常快速地遍历节点。这意味着,如果我们必须搜索任何特定记录,我们应该能够非常轻松地通过中间节点。这是通过对中间节点处的指针和叶节点中的记录进行排序来实现的。任何记录都应该很快得到。这是通过保持树中的平衡并使所有节点保持相同距离来实现的。
-
没有溢出页面:
B +树允许部分填充所有中间节点和叶节点 - 在设计B +树时它将定义一些百分比。填充节点的百分比称为填充因子。如果节点达到填充因子限制,则称为溢出页面。如果节点太空,则称为下溢。在上面的示例中,具有108的中间节点是下溢的。并且叶节点没有部分填充,因此它是溢出的。在理想的B +树中,除了根节点之外不应该有溢出或下溢。
在B+树中搜索记录
假设我们想在下面的B +树结构中搜索65。首先,我们将获取中间节点,该节点将指向可包含65的记录的叶节点。因此,我们在中间节点中找到50到75个节点之间的分支。然后我们将被重定向到最后的第三个叶节点。在这里DBMS将执行顺序搜索以找到65.假设我们必须搜索60而不是65.在这种情况下会发生什么?我们将无法在叶节点中找到。在B +树中搜索期间不允许插入/更新/删除。
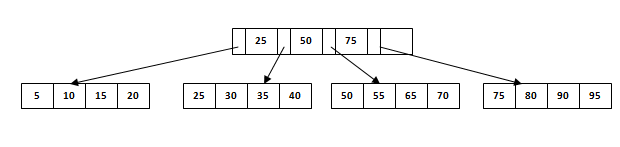
假设我们必须在下面的结构中插入记录60。它会去3 次叶子节点55后既然是平衡树和叶子节点已经满了,我们不能插入记录那里。但它应插入那里而不影响填充因子,平衡和顺序。因此,这里唯一的选择是拆分叶节点。但是我们如何拆分节点呢?
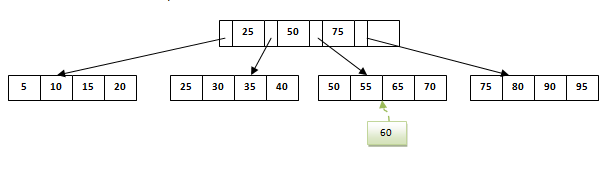
第3个叶节点应该具有值(50,55,60,65,70)并且其当前根节点为50.我们将在中间拆分叶节点,以便不改变其平衡。因此,我们可以将(50,55)和(60,65,70)分组为2个叶节点。如果这两个必须是叶节点,则中间节点不能从50分支。它应该有60个添加到它然后我们可以有指向新叶节点的指针。
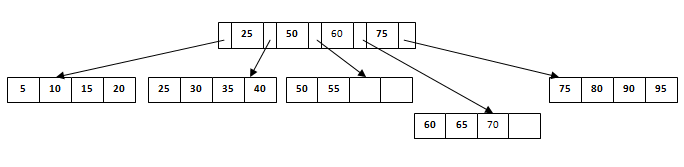
这是我们在有溢出时插入新条目的方式。在正常情况下,很容易找到适合的节点并将其放在该叶节点中。
在B+树中删除
假设我们必须从上面的例子中删除60。在这种情况下会发生什么?我们必须从第 4 个叶子节点以及中间节点中删除60 个。如果我们从中间节点删除它,树将不满足B +树规则。所以我们需要修改它有一个平衡的树。从B +树上面删除60并重新排列节点后,将显示如下。
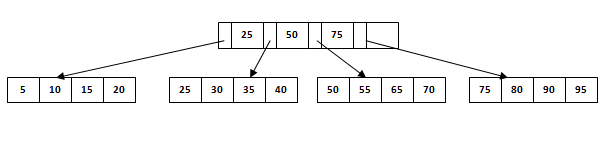
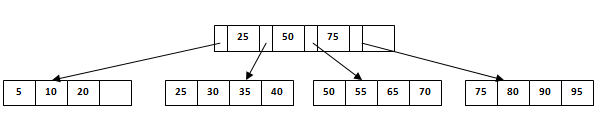
假设我们必须从上面的树中删除15。我们将遍历第一个叶子节点,只需从该节点删除15个。由于树是平衡的并且没有出现在中间节点中,因此不需要任何重新安排。
B+树扩展
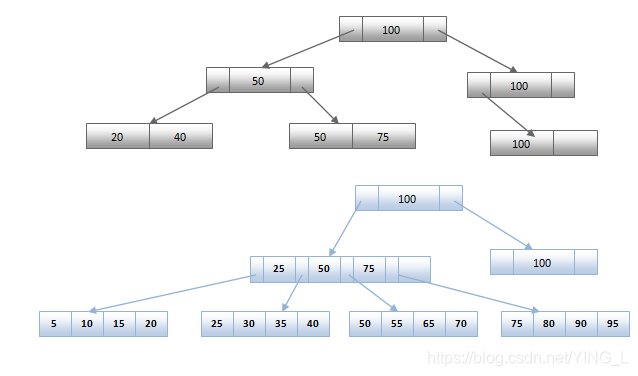
随着数据库中记录数量的增长,需要对中间节点和叶节点进行广泛分割和扩展,以保持树的平衡。这称为B +树扩展。随着它的广泛传播,对记录的搜索变得更快。
创建B +树的主要目标是更快地遍历记录。随着分支的扩展,它需要较少的磁盘I / O来获取记录。需要获取的记录以对数时间段提取。假设我们有K个搜索键值 - 这是n个节点的中间节点中的指针。然后我们可以在log (n / 2)(K)中获取b +树中的任何记录。
假设每个节点需要40bytes来存储索引,每个磁盘块为40Kbytes。这意味着我们可以拥有100个节点(n)。假设我们有100万个搜索键值 - 这意味着我们有100万个中间指针。然后我们可以访问日志50(1000000)=一次访问4个节点。因此,获取树中的任何节点仅花费4毫秒。现在我们可以猜测将B +树扩展到更多中间节点的优势。随着中间节点的传播越来越多,在B +树中获取记录的效率更高。
请看下面的两个图表,了解它如何与B +树扩展区别开来。
B+树索引文件
以上B +树的概念用于将记录存储在辅助存储器中。如果使用此概念存储记录,则将这些文件称为B +树索引文件。由于该树是平衡和排序的,所有节点将处于相同的距离,并且只有叶节点具有实际值,使得在B +树索引文件中搜索任何记录变得容易和快速。即使在B +树中插入/删除也不会花费太多时间。因此,B +树形成了存储记录的有效方法。
搜索,插入和删除记录的方式与我们上面看到的方式相同。由于它是一个余额树,它会搜索文件中记录的位置,然后获取/插入/删除记录。如果由于插入/删除/更新而发现树将不平衡,则它会对节点进行适当的重新排列,以便不更改B +树的定义。
下面是学生详细信息如何存储在B +树索引文件中的简单示例。
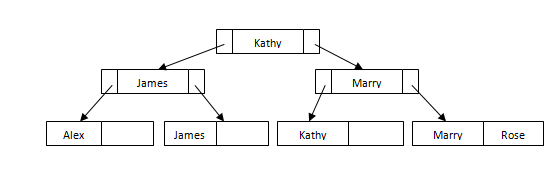
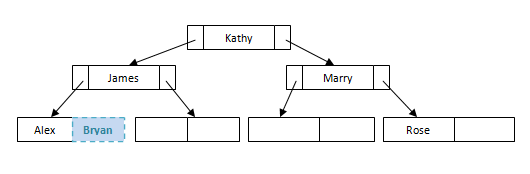
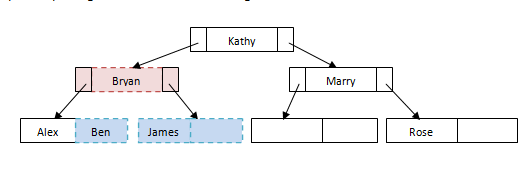
假设我们有一个新学生布莱恩。他在哪里适合文件?他将适合1 日叶节点。由于此叶节点未满,我们可以轻松地将其添加到节点中。
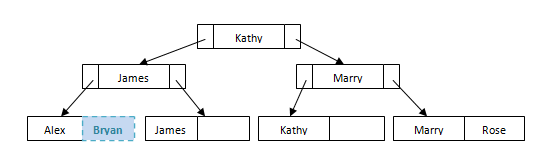
但是如果我们想要将另一名学生Ben插入此文件会怎样?需要对节点进行一些重新安排以维持文件的平衡。
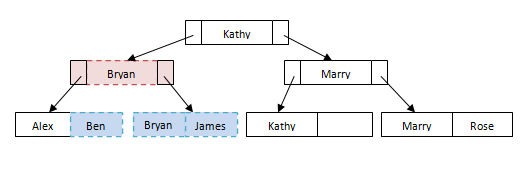
当我们执行删除时也会发生同样的事情。
B+树索引文件的好处
- 随着文件在数据库中的增长,性能保持不变。它不像ISAM那样降级。这是因为所有记录都保存在叶节点处,并且所有节点都与根等距离。此外,如果有任何溢出,它会自动重新组织结构。
- 即使插入和删除很复杂,也可以在几秒钟内完成。
- 叶节点只允许部分/半填充,因为记录大于指针。
B树索引文件
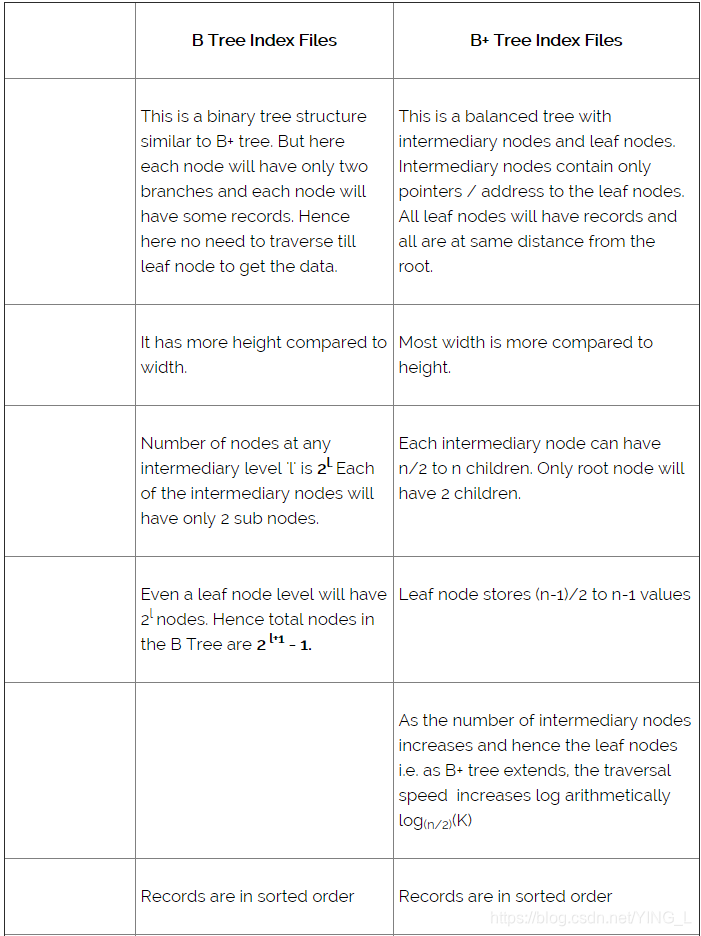
B树索引文件类似于B +树索引文件,但它使用二进制搜索概念。在此方法中,每个根将仅分支到两个节点,并且每个中间节点也将具有该数据。并且叶节点将具有最低级别的数据。但是,在此方法中,也会对记录进行排序。由于所有中间节点也都有记录,因此减少了遍历叶子节点的数据。一个简单的B树可以表示如下:
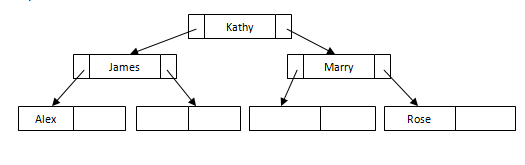
请参阅上面相同示例中此树结构与B +树之间的差异。这里没有重复或指针直到叶节点。所有记录都存储在所有节点中。如果我们需要插入任何记录,它将作为B +树索引文件完成,但它将确保每个节点仅分支到两个节点。如果任何节点中没有足够的空间,它将拆分节点并存储记录。
插入的简单示例
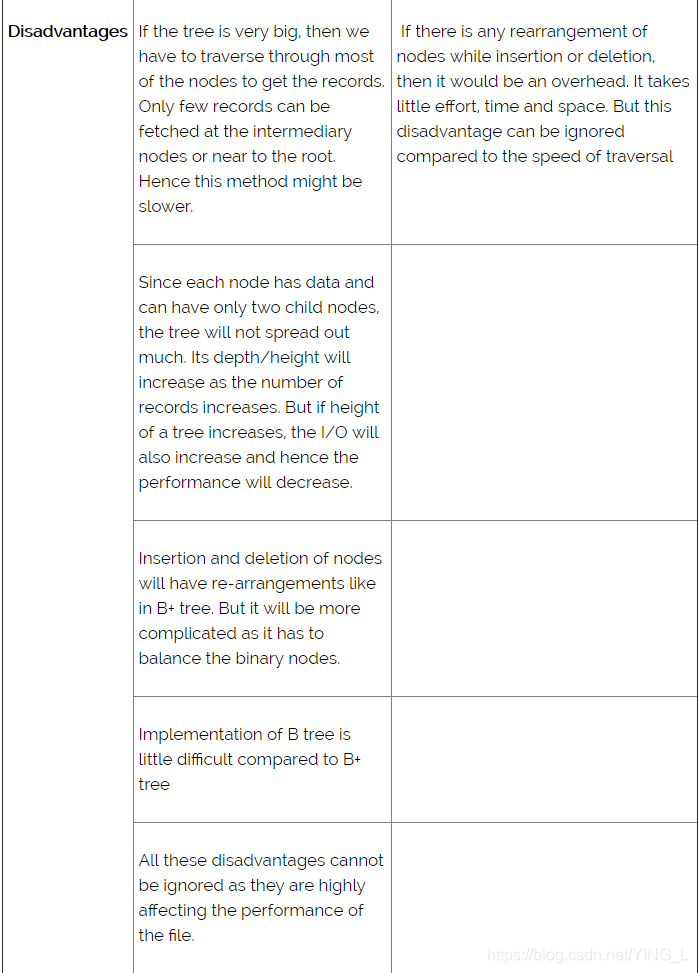
B树和B+树索引文件之间的区别
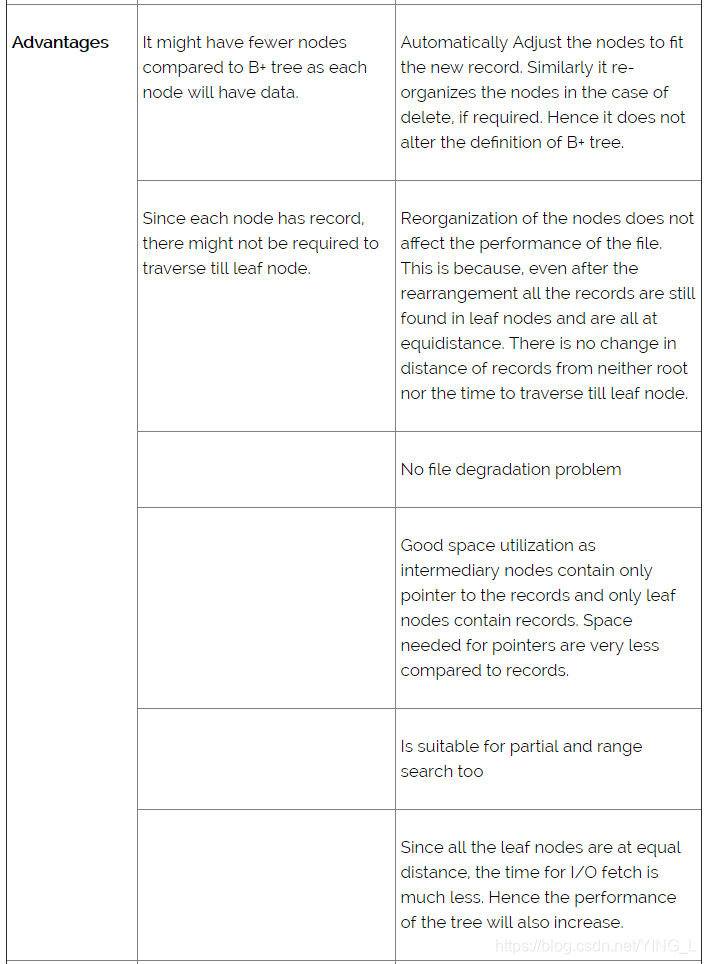
比较上面B +树索引文件和B树索引文件的例子之间的差异。你可以看到它们几乎相似,但它们几乎没有区别。这种微小差异本身对数据库性能有更大的影响。
B+树索引
这是数据库中的标准索引,其中主键或表中用于索引的最常用搜索键列。它具有与上面讨论的相同的特征。因此,它在检索数据方面是有效的。这些索引可以以不同的形式存储在B +树中。根据它们的组织方式,有4种类型的B +树索引。
- 索引组织表: -这里数据本身充当索引,整个记录存储在B +索引文件中。
- 降序索引: -索引键在B +树文件中以降序存储。
- 反向键索引: - 在此索引方法中,索引键列值以相反的顺序存储。例如,假设在STUDENT表中的STD_ID上创建索引。假设STD_ID具有值100,101,102和103.则反向键索引将分别为001,101,201和301。
- B +树集群索引: -这里,表的集群密钥用于索引。因此,此方法中的每个索引都将指向具有相同群集键的记录集。














 1495
1495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









