









对模型进行评估的平台通常需要支持任务调度、指标分析、可视化、报告管理、用户管理、日志管理、邮件管理等功能。
平台需求分析
以金融风控场景中的用户信用资质评估为例,在通过一系列数据分析建模,得到一个用户信用资质的模型。对于此类模型的评估,主要考虑以下几点:
- 模型评估的样本收集。模型产品种类多,训练是基于多种数据源和数据流量进行的。模型评估首先要解决样本收集问题。样本收集功能较独立,所以应将其解耦,以便后续模块接入。
- 样本数据的特征计算。有了样本,需要特征工程处理,将数据转化为特征,此过程需要接入特征计算服务,以API形式提供,这样,特征可以通过接入特征计算服务的接口来获得。
- 特征数据的入模计算。获取特征数据后,需要对特征数据入模计算,一般采用Web框架加载模型文件,平台需要进行参数适配和模块封装。
- 模型结果的指标评估。模型需要从稳定性、准确性、性能这3方面进行评估。平台需要将评估模型的指标计算逻辑抽象成通用模块,并以接口形式来提供以方便调用,这样大量的指标计算高内聚在一个独立的模块中,通过扩展指标的计算能力,提高平台覆盖范围的评估能力。
- 对评估报告进行管理。需要支持报告查看及历史轨迹追溯,从项目流程角度,需支持邮件推送方式,发给相关人员,及报告的发布、查看、推送、追溯等功能。
- 模型评估过程可视化。通过直方图、密度图等可视化操作,降低数据理解成本。在集成开源的可视化工具包方面,平台需考虑通用性和专业性。另外,在不方便直接调用工具包的指标,可考虑前后端交互方式、技术实现成本、前端渲染效果及加载效率等。
- 打造流程闭环。模型评估平台需要通过与模型管理平台、模型部署平台的交互打通整个项目流程,实现模型从开发、评估、版本管理到部署上线的流程闭环。
- 保障数据安全。
平台架构设计
通过前文,模型评估平台大致可包括样本管理模块、配置管理模块、任务管理模块、模型评估模块、用户管理模块等。架构图如下:
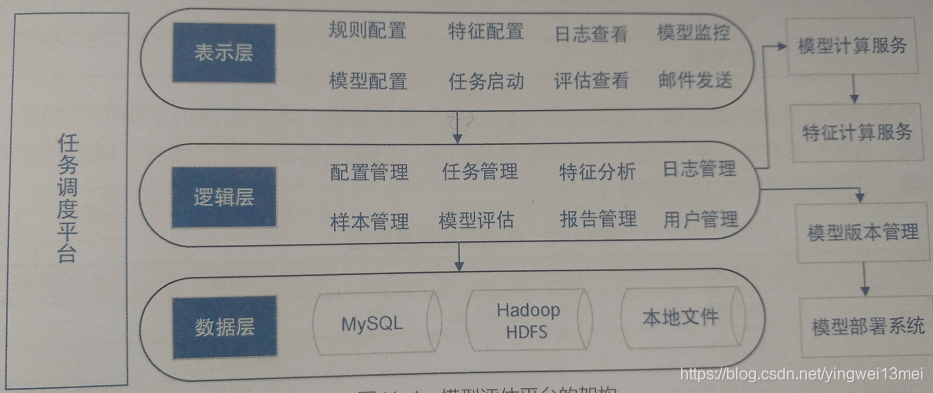
工作原理如下:
- 通过配置管理模块为模型生成一个配置项,存到数据库中,且为该模型生成唯一ID。然后在数据库中生成一条规则信息,为该规则生成唯一ID(该ID唯一标识规则,可通过规则ID得到规则的所有信息)。规则包含任务所需的模型基本信息、样本基本信息、验证环境信息。
- 任务管理模块管理整个任务调度,通过规则信息ID获取该任务依赖的模型名称及版本、样本数量、接口地址、任务运行环境等信息。然后生成一个任务,并为每个任务生成一个任务ID。任务启动后,可通过Hadoop streaming执行MapReduce 任务进行样本处理。处理样本后,调用模型服务,最终得到样本的模型表现结果,并将其存储在HDFS上。
- 模型评估模块将HDFS上的模型表现结果存到本地,并进行指标分析,并将指标分析结果存到MySQL数据库中,为其生成唯一ID。
- 报告管理模型将模型评估模块生成的指标分析结果进行整理,生成评估报告,并将报告保存在数据库中,同时为其生成唯一ID。
- 用户管理模块管理公司内部账号系统,为不同用户设置不同权限。
- 模型开发者确认模型评估报告后,模型评估平台将验证通过的模型版本打包上传到模型版本管理平台。然后通过与模型部署系统的联动,触发模型部署环节,最后通过回调方式更新模型上线的状态。该过程使得模型评估、模型版本管理、模型部署形成闭环。
1、 配置管理模块
配置管理模块主要包括 模型信息模块、规则信息管理模块、邮件报告模块。
模型信息模块主要对模型属性进行管理,包括模型信息配置、模型名称、模型版本、模型调用接口、关联模型(对于新模型来说,线上暂时没有相应的调用流量和日志,需要关联一个旧模型来进行前期的样本收集)、关联版本(关联模型的版本)、模型大小。模型信息配置见下表
| 配置项 | 内容 |
|---|---|
| 模型名称 | Model_v2 |
| 模型大小 | 30.2M |
| 模型版本 | V1.0 |
| 模型调用接口 | /model/getmodel |
| 关联模型 | Model_v1 |
| 关联版本 | V3.0 |
规则信息管理模块复杂整个任务执行中依赖的元信息管理,用户通过前端进行规则配置,规则包含执行任务调度时所需的参数信息,如模型名称、模型版本、样本信息和执行环境等。任务规则信息配置详见表:
| 配置项 | 内容 |
|---|---|
| 规则ID | 10001 |
| 模型名称 | Model_V2 |
| 模型版本 | V1.0 |
| 样本方式 | 自动获取/手动上传 |
| 样本数量 | 20000 |
| 执行环境 | 离线、在线(沙盒、小流量) |
邮件报告模块管理邮件和报告两部分。
| 配置项 | 内容 |
| 邮件标题 | Model_v2模型评估报告 |
| 邮件组 | model_group@...com |
| 报告ID | 20001 |
| 主送人 | xyz@XXX.com |
| 抄送人 | XXX@.com |
2.任务管理模块
任务的启动可通过前端一键式触发。它与规则是多对一的关系,同一个规则可通过多次启动生成多个任务,但一个任务只能由一个规则生成。任务间相互独立,各任务在各自进程上运行,互不影响。任务执行完后,最终生成的评估报告相互独立,任务与报告一一对应。
任务的精细管理和有序调度使得模型评估过程顺利进行。通过任务与规则ID的关联可得到任务的依赖信息,这些信息包含了任务执行的环境、任务执行所需数据、任务间的顺序关系。利用任务与报告ID的关系可得到模型评估报告,评估报告是任务最终的执行结果。
任务管理模块的任务流有两条线。一是定时调度任务,以便后期扩展时采用AirFlow工作流平台来管理一组具有依赖关系的作业任务。---这类调度任务主要服务于模型监控,主要在采集完模型线上的表现数据后,进行指标计算,然后可视化展现,监控。一旦模型效果衰减,能够及时发现,更新模型。 另一类任务流是实时触发任务,改类任务的流程是用户完成模型配置和规则配置后,通过Web进行触发。任务一旦启动,会依次进行样本抽取、与依赖服务交互、指标计算分析流程。
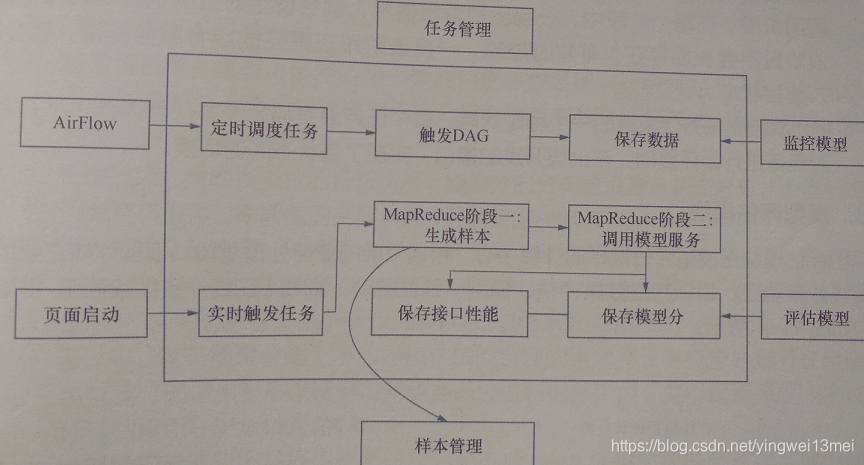
任务管理模块采用多进程任务并发功能。任务间相互独立,互不影响,同时在某个任务内通过对不同状态之间的迁移,实现对任务的多样化管理。可以重运行、暂停、结束任务。任务状态分3种---初始状态、执行状态和终止状态。

- 初始状态是任务生成后的第一个状态。如果任务没有被进程获取到,它将一直存在于任务池中,等待执行。任务执行顺序是先进先出的模式,按照任务生成时间的先后顺序进行调度。
- 执行状态是任务的中间状态,标记着任务执行的不同阶段,通过状态码可以实时跟踪任务的执行状态。该阶段包括样本处理阶段、在线服务调用阶段、离线服务调用阶段。在每个阶段中,一旦出现异常,会对状态码进行标记。该阶段不会长期存在,有超时控制。一旦该阶段正常完成或服务异常,就会进入终止状态。
- 终止状态是任务结束后的一个稳定态。
3. 模型评估模块
主要包括离线效果验证、模型在线效果评估、模型一致性验证(离线/在线一致性验证)。架构如下
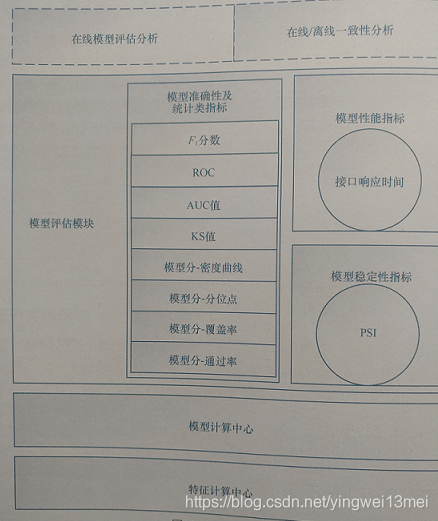
评估指标包括模型覆盖率、通过率、密度曲线、分位点、接口响应时间、ROC、AUC、PSI、KS值。
该模块的流程如下:
通过任务信息获取对应样本,使用这批样本请求特征计算中心的服务,并得到对应的特征结果,将特征结果输入模型计算中心后得到模型计算数据,然后对数据进行性能分析、稳定性指标计算、准确性指标计算。
下面是核心指标的计算逻辑:
- 模型覆盖率:模型可预测的用例数和用例总数之比。针对样本进行的模型覆盖率统计能评估出模型对用户的覆盖程度,取值范围0~1.
- 密度曲线:反映模型分的分布情况。应符合正态分布,该指标可作为调整模型通过率阈值的参考,供业务决策方决策。
- 百分位数及统计值:包括百分位数、非空率、非零率、平均值、中间值。
- 通过率。基于模型分的上下边界值,按照合理的递增步长将模型分划分在合理的等级范围(递增步长可以根据不同业务标准进行调整)内,并通过每个区间的比例统计评估模型分的分布情况。
- 模型接口响应时间。
4.数据存储模块
数据存储模块是模型评估中数据存储的基础,对外提供操作存储介质的API,对内负责与关系数据库、HDFS和HBase交互。数据存储模块架构如图:

数据存储模块主要对源数据、程序计算的中间数据及最终结果数据进行管理。
目前数据有两种。一种是输入配置信息,另一种是中间数据(包括程序计算的临时数据及模型服务计算的结果数据)。结果数据包括模型指标和性能报表信息。不同类型数据存放在对应的存储介质中。
| 不同阶段的数据 | 数据类型 | 存储介质 |
| 源数据 | 配置信息 | MySQL |
| 中间数据 | 模型结果数据 | HDFS |
| 最终数据 | 模型指标分析结果 | MySQL/HDFS |
| 最终数据 | 样本结果 | HDFS |
数据库设计包括表设计和索引设计。模型评估平台中主要的表及索引见下表。
| 表名 | 索引 | 作用 | 核心字段 |
| 规则表 | 规则ID | 规则保存及查询 | 模型名称/样本数量 |
| 模型表 | 模型ID、模型名 | 模型保存及查询 | 模型名称/模型版本 |
| 任务表 | 任务ID | 任务保存及状态查询 | 任务ID/任务状态 |
| 报告表 | 报告ID | 报告存储及查询 | 报告ID/结果ID |
| 结果表 | 结果ID | 结果源数据存储 | 结果ID/结果类型 |
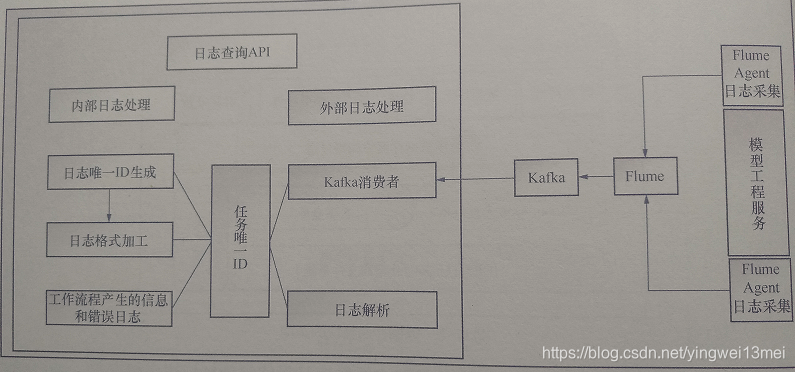
5. 日志管理模块
日志管理模块主要负责对采集到的不同产品的业务日志进行分析,记录平台本身产生的业务工作流日志,对日志等级进行划分(分为正常业务日志和错误日志)。为了保证日志服务的高可靠性,通常使用Flume+Kafka组件。
模型评估平台展示
模型配置规则
配置规则是任务调度依赖的规则集,规定了模型验证过程中依赖的环境、样本数据,及模型本身的相关信息。配置规则的核心是将规则、模型、任务进行提炼,并赋予不同的属性。这方便了用户操作,同时也有利于系统扩展。
为了配置模型规则,首先需要将待验证的模型 基本信息进行配置和保存。
新模型开发完成后,要对其评估,并在平台添加新模型。代码如下
def addmodel(self):
model_list=list()
param_list=['modelName','modelApi','modelVersion','assModel']
for value in param_list:
model_list.append(self.get_argument(value))
sql="insert into model" \
"(model-name, api-url, version, associate-module)" \
"values ('%s','%s','%s','%s')"%(model_list[0],model_list[1],model_list[2],model_list[3]))
try:
data=client.insert(sql)
except Exception as e:
Log.error("model table insert fail")
return 1, "model insert error", None
return 0, 'model add success', data
模型配置完成后,需要生成一个验证规则,为后期启动任务做准备。规则配置是模型信息、样本信息和执行环境的组合。该配置支持增、删、改、查,实现如下:
class RuleHandler(tornado.web.RequestHandler):
def post(self):
url=self.request.uri
#根据路由判断操作类型
opType=url.split("/")[-1][:4]
if opType=="save":
status,msg,data=self.saveRule()
elif opType=="update":
status,msg,data=self.updateRule()
elif opType=="scan":
status,msg,data=self.scanRule()
elif opType=="del":
status,msg,data=self.deleteRule()
eles:
res=generate_response(1,"api request failed",None)
self.finish(res)
res=generate_response(status,msg,data)
self.finish(res)
以添加规则为例:
def saveRule(self):
try:
#获取需要保持的规则字段
Type=self.get_argument('type')
isUpload=self.get_argument("generationMode")
sampleNum=self.get_argument("sampleNum")
#Type 0 代表模型,表示规则类型,后续可扩展
if Type=='0':
modelName=self.get_argument("modelName")
modelVersion=self.get_argument("modelVersion")
#参数异常值检查
emptyParams=''
if modelName='':
emptyParams="'模型名'"
if modelVersion='':
emptyParams="'模型版本'"
if isUpload='':
emptyParams="'样本生成方式'"
if sampleNum='':
emptyParams="'样本数'"
if len(emptyParams)>0"
return 1, "缺少参数,参数{empty}不能为空".format(empty=emptyParams),None
sql="insert into rule_config" \
"(model_name,model_version,type,is_upload,sample_num)" \
"values('{ModelName}','{Modelversion}','{Type}','{IsUpload}','{SampleNum}'}" \
.format(ModelName=modelName, Modelversion=modelversion, Type=type, IsUpload=isUpload, SampleNum=sampleNum)
except Exception as e:
print("保存规则时获取参数错误: {exce}".format(exce=e))
return 1,"保存规则时获取参数错误: {exce}".format(exce=e),None
try:
data=client.insert(sql)
except Exception as e:
print("保存规则入库时发生错误: {exce}".format(exce=e))
return 1, "规则信息保持失败",None
return 0, "规则保存成功",data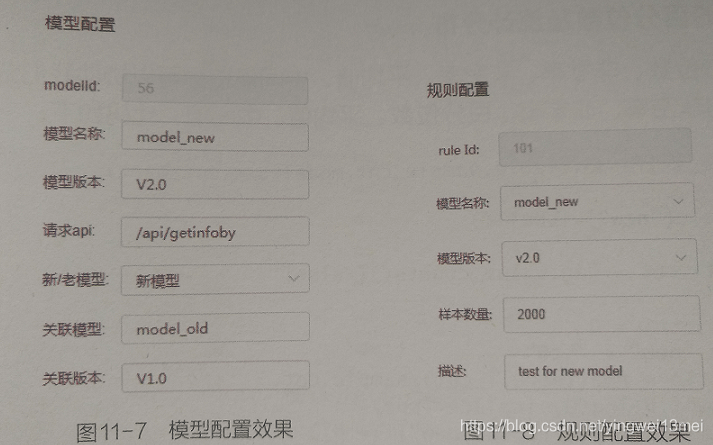
模型评估指标
1、密度曲线
2、模型分的百分位数及统计分布
3、模型分的通过率
4、覆盖率: 有表现的样本与样本总数的比值,在风控领域有一定意义。
5、模型稳定性-PSI(Population Stability Index),衡量模型分的分布差异
6、模型在线/离线Gap分布
7、接口响应时间分布
模型评估报告
模型评估报告包含--样本分析和模型评估
- 样本分析,包含样本的时间维度、数量等
- 模型评估,不仅有模型分统计类指标,模型准确性指标,还包括性能类指标(接口响应时间)、模型稳定性指标(PSI),以及与模型关联的特征指标(模型的特征维数,特征重要性)。
总结
平台特性如下:
- 平台具有通用性。它涵盖了模型稳定性、准确性和模型性能。
- 功能易扩展
- 学习成本低。通过将业务应用划分为界面层、业务逻辑层、数据访问层、屏蔽了复杂的模型评估流程,通过数据、任务、结果的可视化,展示了功能配置简单、易操作、可解释性这些特点。
平台收益:
- 提高组织效能,缩短项目周期。
- 提高数据安全性
- 加强数据的沉淀和共享。通过平台统一入口,一方面,数据得到有效沉淀和积累;另一方面,有效利用了集群资源,减少重复操作,使样本数据,特征数据,模型数据可以共享。
- 提高项目团队成员的技术能力。通过平台化、工程化思维,提高团队成员分析和解决问题的能力。














 1663
1663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









