






Graphs and Sessions
tensorflow使用数据流图的方式来表示独立操作之间的相互依赖计算。这就导致了,如果你使用低级别api进行tensorflow编程的时候,首先必须构建数据流图(dataflow graph)。然后将该数据流图放入Session中运行,此时可以运行数据流图的整个部分,也可以只运行部分数据流图。
如果你直接考虑使用低级api进行编程,这篇向导将是非常用的。虽然高级api(keras和tf.estimator.Estimator隐藏了数据流图的实现细节,但是这篇向导对你理解高级api的具体实现也是非常有用的。
为什么要用数据流图
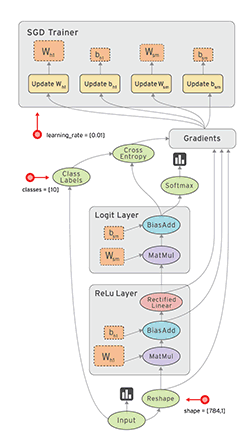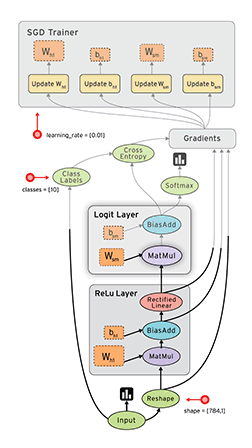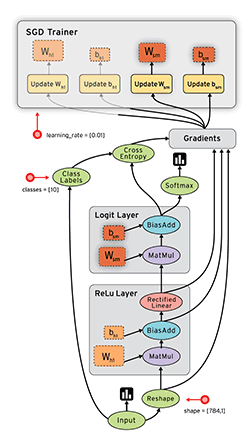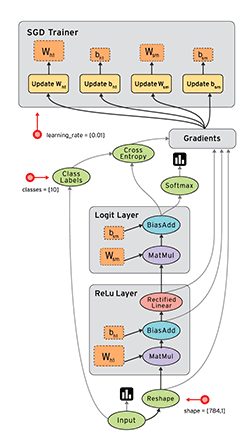
对于并行计算来说,数据流是一个非常普遍的模型。结点表示了基本的计算单元,边表示了计算节点需要或者产生的数据。比如在tensorflow中,tf.matmul操作将对对应到一个单独结点,以及两个输入数据边,一个输出数据边。
tensorflow在执行你的程序时,使用数据流有如下几个好处:
- 并行化:在并行化程序中,对于系统来说,显示的使用边来表示操作间的依赖是非常容易识别的
- 分布式执行:如果显示的边来表示操作间的值,对于tensorflow来说,是非常好将程序切分为几个部分,这些部分可能遍布在不同机器不同设备上。tensorflow会在设备间实现通信和协调。
- 编译:tensorflow的XLA编译器,可以利用数据流图的信息产生一个更加快速的代码。比如,融合相邻的操作。
- 可移植性:数据流图其实是独立与编程语言存在的。比如你可以用python构建一个数据流图,保存起来。然后用c++加载这个模型,实现一个低延迟的对外服务接口。
tf.Graph是什么
tf.Graph主要包含着两种信息:
- 图结构:图的节点和边,表示独立操间如何组合在一起,但没有规定应该如何使用它们。图结构就像一个可装备的代码结构:侵入它能获取一些非常有用的信息
- 图的集合:tensorflow提供了一个非常普通机制来存储图中的元数据。tf.add_to_collection能使你将一个对象绑定到某一个Key上,tf.GraphKeys定义了一些标准键,tf.get_collection:会获得固定Key下所有的对象数据。一些tensorflow库中都会有这个特性:例如当你用tf.Variable创建一个对象时,他会默认添加到代表全局变量和可训练变量的集合中。当你后来创建一个tf.train.Saver o和 tf.train.Optimizer,这些集合中的变量会作为默认参数。
构建tf.Graph
大部分tensorflow程序开始于数据流图的构建阶段,在这个阶段,你调用tensorflow的api,构建tf.Operation 结点和tf.Tensor边,然后将他们加入到tf.Graph实例中,tensorflow中提供了一个默认图,在相同上下文,这个默认图是一个隐式参数。例如:
- 调用
tf.constant(42.0),会产生一个单独的操作,这个操作的值为42.0,将其加入到默认图中,然后返回一个tensor,这个tensor表示着这个常量的值。- 调用
tf.matmul(x, y),会产生一个单一的操作,这个操作会将两个tensor的值进行相乘。将其加入到默认图中,然后返回一个tensor,这个tensor表示着两个tensor x和y相乘的结果- 执行
v = tf.Variable(0)将增加一个操作到默认图中,这个操作将会存储一个可写的tensor值,该值在tf.Session.run方法执行时候修改。tf.Variable对象的一些方法也会产生操作,比如assign和assign_add。这些方法被执行的时候,将会修改储存的值。tf.train.Optimizer.minimize会产生一系列的操作和tensor到默认图中,这些都可以用来计算梯度,并返回一个tf.Operation,
大多数程序仅仅只需要默认图,对于更高级的使用案例,可以看programming_with_multiple_graphs。
调用tensorflow的大部分api,只是将操作和tensor加入到默认图中,但是并不会真正的执行他们。当你组建完一个数据流图,获得了一个tensor或者操作对象,这个对象能代表整个计算图,例如获得一个梯度下降对象,然后将这个对象交给tf.Session().run()运行,才会真正的执行
命名操作
tf.Graph对每个他所包含的tf.Operation对象定义了一个命名空间。tensorflow会自动的给一个唯一的名字对你的tf.Operation对象,但是这个名字是一个毫无意义的字符串。如果我们人为的给这个对象一个描述更加有意义的名字,会增加代码的可读性。TensorFlow提供了两种方法用于覆盖系统自动产生的名字:
- 能够创建一个新的
tf.Operation或者返回一个tf.Tensot对象的函数都会接受一个可选的name参数,例如tf.constant(42.0, name="answer")方法会创建一个名为answer的tf.Operation对象,并返回一个命名为answer:0的tf.Tensor对象。如果默认图已经包含了一个命名为answer的操作,这时候tensorflow会在其后缀增加_1, _2, ...,以保证命名唯一。 tf.name_scope会在具体的上下文中,给名字增加一个前缀。
图形化工具使用命名空间来对操作进行分组,这样可以减少可视化的复杂程度。
注意:tf.Tensor对象是在tf.Operation后隐式的命名,tf.Tensor对象命名规则为:
操作放在不同的设备
如果你想你的TensorFlow程序使用多台不同的机器,
tf.device方法提供了一种简便方法,将所有操作放在同意设备的同一个具体的上下文中。
设备规范犹如下格式:
Tensor-like对象
一些tensorflow的操作对象需要一个或者多个
tf.Tensor对象作为参数输入,例如tf.matmul需要两个tf.Tensor对象。为了便利,这些方法都可以接收一个Tensor-like对象,来代替tf.Tensor对象。这些方法的内部会调用tf.convert_to_tensor方法,将这些对象转换为tf.Tensor对象。Tensor-like对象包含如下几个类型:
tf.Tensortf.Variablenumpy.ndarraylist (and lists of tensor-like objects)Scalar Python types: bool, float, int, str你可以使用
tf.register_tensor_conversion_function自定义一些tensor-like对象。
注意:每次你使用Tensor-like对象时候,tensorflow都会默认创建一个新的tensor对象。如果某个Tensor-like对象特别大,比如一个非常大的List。如果你多次使用这个对象,这是可能会超出内存。为了编码这个问题,你可以人为的调用tf.convert_to_tensor,将Tensor-like对象转换为tensor对象,后面只需要使用这个新的tensor对象即可。在Session中执行图
tensorflow使用
tf.Session类来表示客户端程序和c++运行时程序之间的关联。tf.Session对象提供了访问本地设备和分布式运行环境远程机器的方法,它也缓存了一些关于你构建的数据流图的基本信息。因此你能有效的运行多次,使用相同的计算图。构建一个tf.Session
如果你使用tensorflow低级别的api来创建
tf.Session,你可以用如下流程:- 本地设备构建
session:with tf.Session() as sess 远程创建一个
session:with tf.Session("grpc://example.org:2222")因为一个
tf.Session对象能够访问一些物理资源,比如GPUs和网关信息。在with块中,他也可以用来管理上下文。当你退出这个with块的时候,这个Session会自动关闭。也可以不使用这个with块创建Session,但是这时候你应用显示的调用tf.Session.close,如果你想关闭这个Session对象。注意:一些tensorflow高级api,比如
tf.train.MonitoredTrainingSession和tf.estimator.Estimato。这些高级api将会直接为你管理和创建Session。这些api也会接受一些可选参数target和config,这些参数的意义和下面介绍的相同。
tf.Session.init接受三个可选的参数:
target:如果这个参数为空,这个Session仅仅使用当前机器的设备。你也可以定义一个url,用于指定一个远程的tensorflow服务器。这个服务器将会提供session访问它所控制设备的权利。可以查看tf.train.Server知道创建一个tensorflow的细节。graph:默认的情况下,一个tf.Session对象将会被绑定到当前的默认图中。如果你的程序使用了多个图,那么在你构建Session对象的时候,你必须显示的指定一个tf.Graph对象。Config:这个参数让你制定一个具体的tf.ConfigProto实例,这个对象会控制当前Session的行为使用
tf.Session.run来执行程序tf.Session.run方法是运行一个tf.Operation或者估计tf.Tensor的主要运行机制。你可以传递一个或者多个tf.Operation或者tf.Tensor对象到tf.Session.run方法这个方法中。然后Tensorflow将会执行这些操作。
tf.Session.run方法要求你指定一个fetches队列。这个队列决定了返回的值类型。这个队列存放可以是tf.Operation、tf.Tensor、tensor-like类型的对象。这些fetches决定了tf.Graph图中,哪一个子图将会被执行并产生结果。这个子图必须包含在fetches队列中所有的操作。
tf.Session.run也会可选择的传递一个名为feeds的字典参数。这个字典可以建立一个从tf.Tensor(一般是tf.placehoder的tensor)对象到值(一般是python的scalars、lists、Numpy数组)的映射。
可视化图
tensorflow也提供了一些工具,帮你理解数据流图中的代码。数据流图可视化工具是
TensorBoard的一个组成部分,这个工具可以使你的数据流图很直观的在浏览器中展现。最简便的可视化方式是将tf.Graph传递到tf.summary.FileWriter方法中。
如果你正在使用一个比较高级别的api,例如tf.estimator.Estimator,tf.Graph将会自动保存到你定义的文件夹参数(model_dir)
在多个图中编码
注意:当正在训练模型时,管理代码最常用的方式就是使用图。一般情况下,评估模型和预测模型所使用的图是不一样的。此外,默认情况下,像
tf.train.Saver这些对象会使用变量名检查每个一个变量。当你使用上述方式编程时,你可以在多个进程中构建图。也可以在同一个进程中,构建多个图。
正如上面所说,tensorflow提供了一个默认图,这个默认图是相同上下文中所有tensorflow的api方法的一个隐含参数。对于一些应用来说,一个图也许是足够的。然而tensorflow也提供了一些方法管理这个默认图,这对于一些高级应用是非常有帮助的。例如:
tf.Graph对象定义了tf.Operation对象的命名空间,每一个tf.Operation对象在一个上下文中(Graph)中必须有唯一的上下文。如果某个tf.Operation对象的名字已经存在,tensorflow会通过增加后缀(_1,_2,_3,...)的方式,以保证它的名字唯一。当然你也可以直接显示的指定名字。默认图都会存储它内部的
tf.Operation和tf.Tensor对象信息。如果你的程序创建了非常多且无连接的子图,这时候,对于每个子图,分别使用tf.Graph对象是更加高效的。这样一些无关的状态,可以尽早的被垃圾回收期回收。
你可以使用
tf.Graph.as_default,指定不同的子图作为当前的默认子图。














 87
87











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









