







MaxCompute用量明细账单分析最佳实践
MaxCompute中计算资源的计费方式分为包年包月和按量计费两种,产品每天会以Project为维度进行计费(账单会在第二天上午6点前生成)。
用量详情账单字段说明
查看自己的MaxCompute用量详情,可以到控制台中如下菜单进行查询并导出到本地:
账单明细字段如下:
- 项目编号:当前账号或子账号对应的主账号的MaxCompute Project列表。
- 计量信息编号:以存储、计算、上传和下载的任务ID为计费信息编号,SQL为InstanceId,上传和下载为Tunnel SessionId。
- 数据分类:Storage(存储)、ComputationSql(计算)、UploadIn(内网上传)、UploadEx(外网上传)、DownloadIn(内网下载)、DownloadEx(外网下载)。按照计费规则其中只有红色部分为实际计费项目。
- 存储(Byte):每小时读取的存储量,单位为Byte。
- 开始时间/结束时间:按照实际作业执行时间进行计量,只有存储是按照每个小时取一次数据。
- SQL读取量(Byte):SQL计算项,每一次SQL执行时SQL的Input数据量,单位为Byte。
- SQL复杂度(Byte):每次执行SQL的复杂度,为SQL计费因子之一。
- 公网上行流量(Byte)、公网下行流量(Byte):分别为公网上传和下载的数据量,单位Byte。
- MR/Spark作业计算(CoreSecond):MapReduce/Spark作业的计算时单位为CoreSecond,需要转换为计算时Hour。
- SQL读取量_访问OTS(Byte)、SQL读取量_访问OSS(Byte):外部表实施收费后的读取数据量,单位Byte。
- 计算资源规格(按量计费):对应计量信息所在项目所属的计算资源规格,若值为NULL,则表示按量计费标准版;若值为OdpsDev,则表示按量计费开发者版。
- 计算资源规格(包年包月):对应计量信息所在项目所属的计算资源规格。若值为NULL,则表示包年包月标准版;若值为OdpsPlus160CU150TB、 OdpsPlus320CU300TB、OdpsPlus600CU500TB,则分别表示存储密集型160套餐、存储密集型320套餐,存储密集型600套餐。
- DataWorks调度任务ID:计量作业在DataWorks上的调度节点ID。若值NULL,则表示非DataWorks调度节点提交的Job;若值为一串数字ID,则表示Job对应DataWorks调度节点ID。您可以在DataWorks对应的项目中使用该ID搜索到具体任务。
下面将自己的20200415-20200425时间段内的MaxCompute用量账单详情导出到本地,然后在MaxCompute中创建表用于存储账单数据,进而进行相应的账单数据分析。包括如下几个部分:
- 创建数据表并导入数据
- 通过SQL分析账单数据
创建数据表并导入数据
1. 将20200415-20200425时间段MaxCompute用量明细数据导出到本地,保存文件为:odps_20200415_20200425_oms_data.csv。
2. 使用如下命令创建数据表,用于保存账单数据:
DROP TABLE IF EXISTS maxcomputefee ;
CREATE TABLE IF NOT EXISTS maxcomputefee (
projectid STRING COMMENT '项目编号',
feeid STRING COMMENT '计费信息编号',
type STRING COMMENT '数据分类,包括Storage、ComputationSQL、DownloadEx等',
storage BIGINT COMMENT '存储(Byte)',
endtime DATETIME COMMENT '结束时间',
computation_sql_input BIGINT COMMENT 'SQL/交互式分析 读取量(Byte)',
computation_sql_complexity DOUBLE COMMENT 'sql复杂度',
uploadex BIGINT COMMENT '公网上行流量Byte',
download BIGINT COMMENT '公网下行流量Byte',
cu_usage DOUBLE COMMENT 'MR计算时*second',
input_ots BIGINT COMMENT '访问OTS的数据输入量',
input_oss BIGINT COMMENT '访问OSS的数据输入量',
starttime DATETIME COMMENT '开始时间',
source_type String COMMENT '计算资源',
source_id String COMMENT 'DataWorks调度任务ID'
);3. 使用tunnel命令将本地数据上传数据至数据表,命令如下:
odps@ YITIAN_BJ_MC>tunnel upload /Users/yitian/Documents/MaxCompute/maxcompute-data/odps_20200415_20200425_oms_data.csv maxcomputefee -c "UTF-8" -h "true" -dfp "yyyy-MM-dd HH:mm:ss";
4. 上传完成后,使用如下命令检查数据导入情况:
select count(*) from maxcomputefee;返回结果为:
1996查询数据前十条,检查数据导入是否正确:
select * from maxcomputefee limit 10;返回结果如下:

通过SQL分析账单数据
数据导入到MaxCompute之后,就可以进行相应的数据分析过程了,具体的分析示例如下。
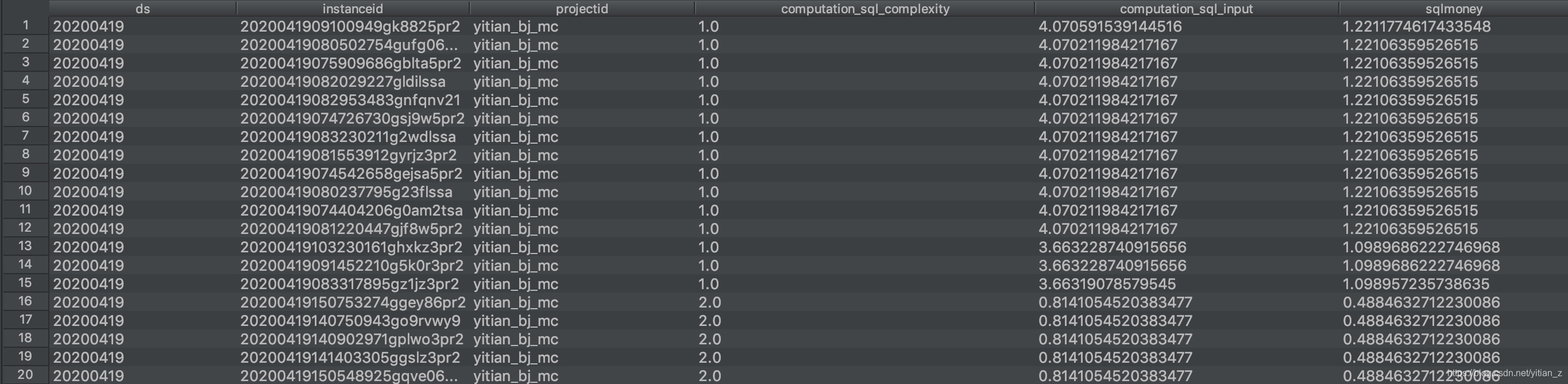
示例1:分析SQL费用。云上用户使用MaxCompute,95%的用户通过SQL即可满足需求,SQL也在消费增长中占了很大比例。说明:一次SQL计算费用=计算输入数据量*SQL复杂度*单价(0.3元/GB)
-- 分析SQL费用
select to_char(endtime, 'yyyymmdd') as ds,
feeid as instanceid,
projectid,
computation_sql_complexity,
sum((cast(computation_sql_input as bigint) / 1024 / 1024 / 1024)) as computation_sql_input,
sum((cast(computation_sql_input as bigint) / 1024 / 1024 / 1024)) * computation_sql_complexity * 0.3 as sqlmoney
from maxcomputefee
where type='ComputationSql'
and computation_sql_input is not null
and computation_sql_complexity is not null
and to_char(endtime, 'yyyymmdd') >= '20200415'
group by to_char(endtime, 'yyyymmdd'), feeid, projectid, computation_sql_complexity
order by sqlmoney desc
limit 20;返回结果如下:
示例2:分析作业增长趋势。通常费用的增长是由于重复执行或调度属性配置不合理造成的作业量暴涨。
-- 分析作业增长趋势
select to_char(endtime, 'yyyymmdd') as ds,
projectid,
count(*) as tasknum
from maxcomputefee
where type='ComputationSql' and to_char(endtime, 'yyyymmdd') >= '20200415'
group by to_char(endtime, 'yyyymmdd'), projectid
order by tasknum desc
limit 20;返回结果如下:

示例3:分析存储费用。说明 存储费用的计费规则相对复杂。明细中是按每个小时取一次得出的数据。按照MaxCompute存储计费规则,会先整体24小时求和,再将平均之后的值进行阶梯收费。详情请参见存储费用(按量计费)。
-- 分析存储费用
select t.ds,
t.projectid,
t.storage,
case when t.storage < 0.5 then 0.1
when t.storage >= 0.5 and t.storage <= 10240 then t.storage * 0.0072
when t.storage > 10240 and t.storage <= 102400 then (10240 * 0.0072 + (t.storage - 10240) * 0.006)
when t.storage > 102400 then (10240 * 0.0072 + (102400 - 10240) * 0.006 + (t.storage - 102400) * 0.004)
end as storage_fee
from (
select to_char(starttime, 'yyyymmdd') as ds,
projectid,
sum(storage / 1024 / 1024 / 1024) / 24 as storage
from maxcomputefee
where type='Storage' and storage is not null and storage > 0
and to_char(starttime, 'yyyymmdd') >= '20200415'
group by to_char(starttime, 'yyyymmdd'), projectid
) t
order by storage_fee desc
limit 20;返回结果如下:

根据执行结果可以分析得出如下结论:
- 由于数据量很小,因此这里的存储开销很比较少。
- 对于数据量比较大时的存储优化,建议为表设置生命周期,删除长期不使用的临时表等。
示例4:分析下载费用。对于公网或者跨Region的数据下载,MaxCompute将按照下载的数据量进行计费。说明 计费公式为一次下载费用=下载数据量*单价(0.8元/GB)
-- 分析下载费用
select to_char(starttime, 'yyyymmdd') as ds,
projectid,
sum((download/1024/1024/1024)*0.8) as download_fee
from maxcomputefee
where type='DownloadEx'
and to_char(starttime, 'yyyymmdd') >= '20200415'
and download is not null
group by to_char(starttime, 'yyyymmdd'), projectid
order by download_fee desc
limit 20;返回结果如下:

示例5:分析MapReduce作业消费。说明 MapReduce任务当日计算费用=当日总计算时*单价(0.46元)
-- 分析MapReduce作业消费(暂时无数据)
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds,
projectid,
(cu_usage/3600)*0.46 AS mr_fee
FROM maxcomputefee
WHERE type = 'MapReduce'
and cu_usage is not null
AND TO_CHAR(starttime, 'yyyymmdd') >= '20200415'
GROUP BY TO_CHAR(starttime, 'yyyymmdd'), projectid, cu_usage
ORDER BY mr_fee DESC
limit 20;示例6:分析外部表作业(OTS和OSS)。说明 一次SQL外部表计算费用=计算输入数据量*SQL复杂度(1)*单价(0.03元/GB)
--分析OTS外部表SQL作业消费(暂时无数据)
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds,
projectid,
(input_ots/1024/1024/1024)*1*0.03 AS ots_fee
FROM maxcomputefee
WHERE type = 'ComputationSql'
AND input_ots is not null
AND TO_CHAR(starttime, 'yyyymmdd') >= '20200415'
GROUP BY TO_CHAR(starttime, 'yyyymmdd'), projectid, input_ots
ORDER BY ots_fee DESC
limit 20;
--分析OSS外部表SQL作业消费(暂时无数据)
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds,
projectid,
(input_oss/1024/1024/1024)*1*0.03 AS ots_fee
FROM maxcomputefee
WHERE type = 'ComputationSql'
AND input_oss is not null
AND TO_CHAR(starttime,'yyyymmdd') >= '20200415'
GROUP BY TO_CHAR(starttime,'yyyymmdd'), projectid, input_oss
ORDER BY ots_fee DESC
limit 20;示例7:分析Lightning查询费用。说明 一次Lightning查询费用 = 查询输入数据量*单价(0.03元/GB)
-- 分析Lightning查询费用(暂时无数据)
SELECT to_char(endtime,'yyyymmdd') as ds,
feeid as instanceid,
projectid,
computation_sql_complexity,
SUM((computation_sql_input / 1024 / 1024 / 1024)) as computationsqlinput,
SUM((computation_sql_input / 1024 / 1024 / 1024)) * computation_sql_complexity * 0.03 AS sqlmoney
FROM maxcomputefee
WHERE TYPE = 'LightningQuery'
--AND to_char(endtime,'yyyymmdd') >= '20190112'
AND computation_sql_input is not null
AND computation_sql_complexity is not null
GROUP BY to_char(endtime, 'yyyymmdd'), feeid, projectid, computation_sql_complexity
ORDER BY sqlmoney DESC
LIMIT 20;示例8:分析Spark计算费用。说明 Spark任务当日计算费用 = 当日总计算时*单价(0.66元/计算时)
--分析Spark作业消费(暂时无数据)
SELECT TO_CHAR(starttime, 'yyyymmdd') AS ds,
projectid,
(cu_usage/3600)*0.66 AS mr_fee
FROM maxcomputefee
WHERE type = 'spark'
AND cu_usage it not null
AND TO_CHAR(starttime, 'yyyymmdd') >= '20200415'
GROUP BY TO_CHAR(starttime, 'yyyymmdd'), projectid, cu_usage
ORDER BY mr_fee DESC
limit 20;














 1844
1844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









