






Target Speaker Extraction for Multi-Talker Speaker Verification
Wei Rao1
, Chenglin Xu2,3
, Eng Siong Chng2,3
, Haizhou Li1
1Department of Electrical and Computer Engineering, National University of Singapore, Singapore
1新加坡国立大学电气与计算机工程系
2School of Computer Science and Engineering, Nanyang Technological University, Singapore
2新加坡南洋理工大学计算机科学与工程学院
3Temasek Laboratories, Nanyang Technological University, Singapore
3新加坡南洋理工大学电子科技实验室
elerw@nus.edu.sg, xuchenglin@ntu.edu.sg
speaker verification,Speaker diarization, overlapped multi-talker speech
https://www.isca-speech.org/archive/Interspeech_2019/pdfs/1410.pdf
Abstract
摘要
The performance of speaker verification degrades significantly when the test speech is corrupted by interference from non- target speakers. Speaker diarization separates speakers well only if the speakers are not overlapped. However, if multiple talkers speak at the same time, we need a technique to separate the speech in the spectral domain. In this paper, we study a way to extract the target speaker’s speech from an overlapped multi-talker speech. Specifically, given some reference speech samples from the target speaker, the target speaker’s speech is firstly extracted from the overlapped multi-talker speech, then the extracted speech is processed in the speaker verification sys- tem. Experimental results show that the proposed approach sig- nificantly improves the performance of overlapped multi-talker speaker verification and achieves 64.4% relative EER reduction over the zero-effort baseline.
当测试语音受到非目标说话人干扰时,说话人验证性能明显下降。只有当扬声器没有重叠时,扬声器二值化才能很好地分离扬声器。然而,如果多个通话者同时通话,我们需要一种技术来分离频谱域中的语音。本文研究了一种从重叠多人语音中提取目标说话人语音的方法。具体来说,给定目标说话人的参考语音样本,首先从重叠多说话人语音中提取目标说话人的语音,然后在说话人验证系统中对提取的语音进行处理。实验结果表明,该方法显著提高了重叠式多人说话人验证的性能,在零努力基线上的相对EER降低了64.4%。
- Introduction
The performance of speaker verification degrades significantly when the speech is corrupted by interference speakers. Speaker diarization can be useful for speaker verification with non- overlapping multi-talker speech [1–6]. It can effectively ex- clude unwanted speech segments when the speakers only slightly overlap [7, 8]. However, such system fails when multi- talkers speak simultaneously most of the time.
当语音被干扰说话人破坏时,说话人验证性能显著下降。说话人二值化可用于非重叠多说话人语音的说话人验证[1–6]。当说话人只稍微重叠时,它可以有效地排除不需要的语音片段[7,8]。然而,当多个通话者同时通话时,这种系统会失败。
One possible solution is to separate the multi-talker speech into different speakers using a speech separation system, such as deep clustering [9], deep attractor network [10], permutation invariant training [11–13], and so on. While speech separation performance has been improved recently, the number of speak- ers has to be known in prior for these approaches to work well. However, the number of speakers in the test speech is unknown in many real-world applications.
一种可能的解决方案是使用语音分离系统(如深度聚类[9]、深度吸引子网络[10]、置换不变训练[11–13]等)将多人语音分离成不同的说话人。虽然语音分离性能最近有所提高,但要使这些方法工作良好,必须事先知道说话人的数量。然而,在许多实际应用中,测试语音中的说话人数量是未知的。
In speaker verification, what we are interested in is the target speaker’s speech. We are not interested in speech of other speakers. The speaker extraction mechanism requires some clean speech samples from the target speaker as the refer- ence [14–18]. In the context of speaker verification, the target speaker’s enrollment speech can be used as such reference. We can construct a multi-talker speaker verification system by us- ing a target speaker extraction front-end, that is followed by a traditional speaker verification system such as i-vector/PLDA system [19–22]. We call the processing pipeline as SE-SV.
在说话人验证中,我们感兴趣的是目标说话人的语音。我们对其他演讲者的演讲不感兴趣。说话人提取机制需要从目标说话人中提取一些干净的语音样本作为参考[14–18]。在说话人验证的背景下,目标说话人的注册语音可以作为这样的参考。我们可以使用目标说话人提取前端来构造一个多说话人说话人验证系统,然后是传统的说话人验证系统,如i-vector/PLDA系统[19-22]。我们称处理管道为SE-SV。
In this paper, we explore the interaction between the speaker verification system and the target speaker extraction networks. The speaker extraction networks are SBF-MTSAL [16] and SBF-MTSAL-Concat [16]. Experimental results sug- gest that SE-SV significantly improves the performance of speaker verification on overlapped multi-talker speech over both zero-effort system and the oracle speaker diarization system.
本文探讨了说话人识别系统与目标说话人提取网络之间的交互作用。说话人提取网络是SBF-MTSAL[16]和SBF-MTSAL-Concat[16]。实验结果表明,在零努力系统和oracle说话人二值化系统上,SE-SV算法显著提高了重叠多说话人语音的说话人验证性能。
The remainder of the paper is organized as follows. Sec- tion 2 introduces our proposed SE-SV framework in this paper. Section 3 and Section 4 report the experimental setup and re- sults. Then, the conclusions and future works are presented in Section 5.
论文的其余部分安排如下。第二部分介绍了本文提出的SE-SV框架。第三节和第四节介绍了实验装置和结果。第五章为结论与展望。
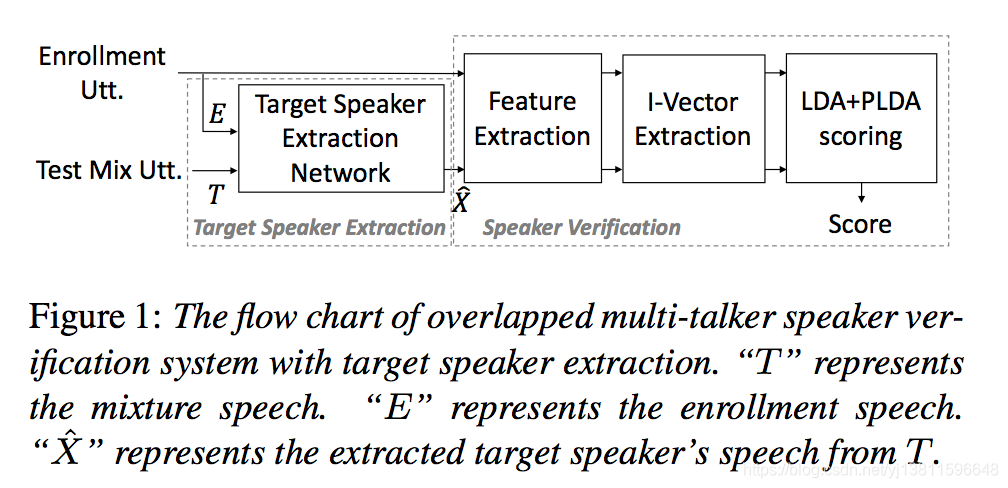
2. Multi-Talker Speaker Verification with Speaker Extraction
Fig. 1 illustrates the framework of the proposed overlapped multi-talker speaker verification system with target speaker ex- traction (SE-SV). The framework consists of a target speaker extraction module and a speaker verification system. Specif- ically, the enrollment speech E is used as the reference sam- ple for the speaker extractor to extract target speech from the mixture T . The extracted speech Xˆ instead of the original test multi-talker mixture T is used to extract i-vector for speaker verification.
图1示出了所提出的具有目标扬声器扩展(SE-SV)的重叠多扬声器验证系统的框架。该框架由目标说话人提取模块和说话人验证系统组成。具体地说,注册语音E用作说话人提取器从混合语音T中提取目标语音的参考样本。用提取出的语音Xˆ代替原来的测试混音T来提取i矢量进行说话人验证。
In this paper, we compare the use of two target speaker ex- traction methods and their interaction with speaker verification system: (1) SpeakerBeam front-end with magnitude and tem- poral spectrum approximation loss (SBF-MTSAL) [16] and (2) SBF-MTSAL with concatenation framework (SBF-MTSAL- Concat) [16]. Both methods are the extensions to SpeakerBeam front-end (SBF) [15].
本文比较了两种目标说话人的提取方法及其与说话人确认系统的相互作用:
(1)具有幅度和TEM波谱近似损失(SBF MTSAL)〔16〕和
(2)SBF MTSAL的级联波束前端(SBF MTSAR-CONTAT)〔16〕。
这两种方法都是SpeakerBeam前端(SBF)[15]的扩展。
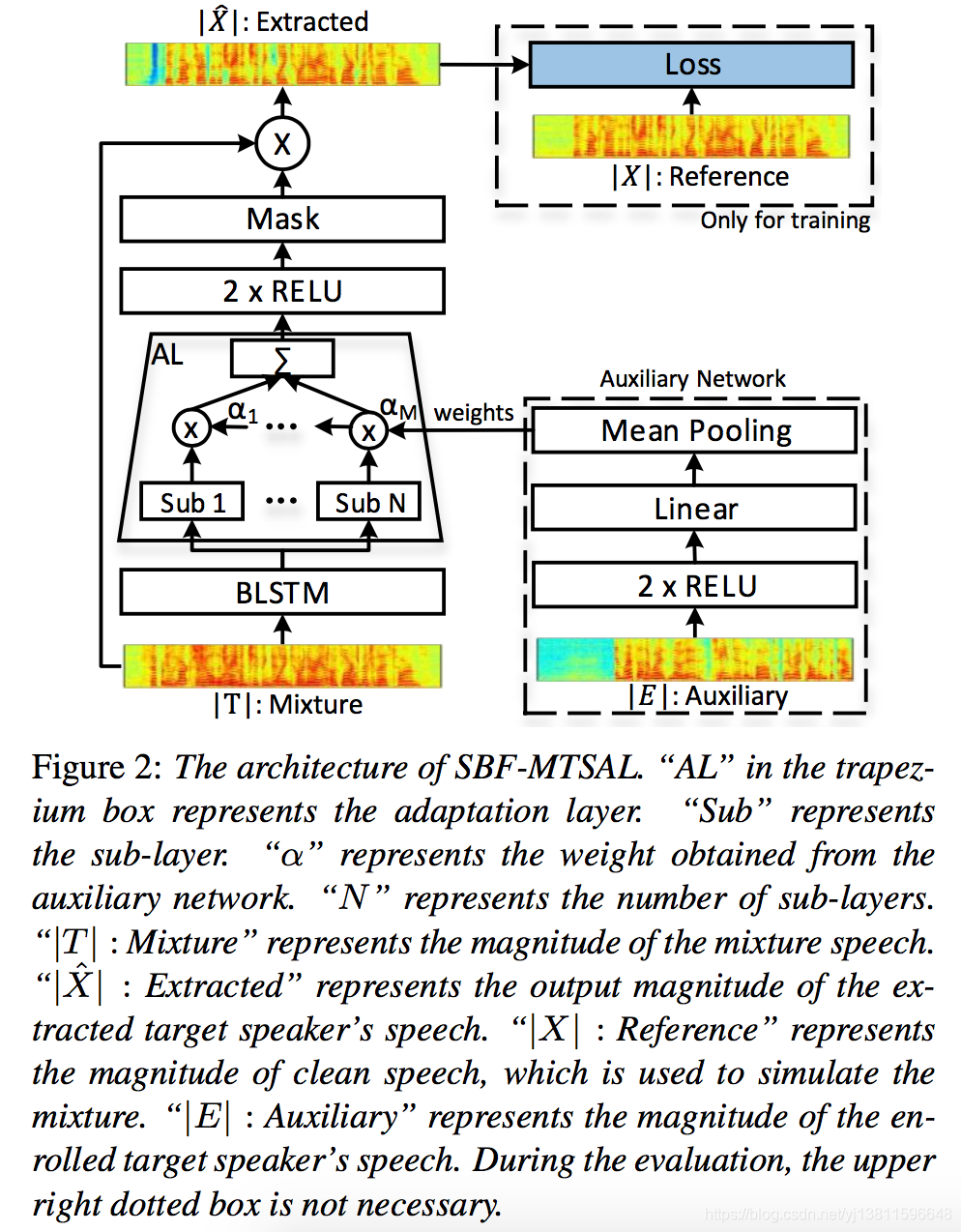
2.1. SBF-MTSAL
Fig. 2 shows the architecture of SBF-MTSAL [16]. The SBF- MTSAL framework consists of a speaker extraction network and an auxiliary network. The auxiliary network learns adap- tation weights from the target speaker’s voice E, which is dif- ferent from the utterance of the target speaker in the mixture. The adaptation weights contain speaker characteristics. They are used to weight the sub-layers in the adaptation layer of the mask estimation network with a context adaptive deep neural network (CADNN) structure [23].
图2示出了SBF-MTSAL的体系结构[16]。SBF-MTSAL框架由说话人提取网络和辅助网络组成。辅助网络从目标说话人的语音E中学习权重,这与混合中的目标说话人的发音不同。自适应权重包含说话人特征。它们用于使用上下文自适应深神经网络(CADNN)结构对掩模估计网络的自适应层中的子层进行加权[23]。
Instead of optimizing the network for an objective loss be- tween ideal binary mask and the estimated mask [15], SBF-MTSAL computes a magnitude and temporal spectrum approx- imation loss to estimate a phase sensitive mask [24] due to its better performance [12, 16]. The magnitude and its dynamic in- formation (i.e., delta and acceleration) are used in calculating the objective loss for temporal continuity. The objective loss is defined as,
SBF-MTSAL没有为理想二元掩模和估计掩模之间的目标损耗优化网络[15],而是计算幅度和时间频谱近似损耗,以估计相位敏感掩模[24],因为它的性能更好[12,16]。震级及其动态信息(即增量和加速度)用于计算时间连续性的目标损失。客观损失的定义是,

where the extracted speech |Xˆ | is equal to M ⊙ |T |, and M is the estimated phase sensitive mask for target speaker. |T | and |X| are the magnitudes of the mixture and the target speaker’s clean speech, where θy and θx are their corresponding phase angles. wd and wa are the weights, which are tuned as 4.5 and 10.0 in this work. fd(·) and fa(·) are the delta and acceleration computation functions [25].
其中,所提取的语音| Xˆ|等于M记者| T |,M是目标说话人的估计相位敏感掩模。|T |和| X |是混合语音和目标说话人干净语音的震级,其中θy和θX是它们对应的相位角。wd和wa是权重,在这项工作中分别调整为4.5和10.0。fd(·)和fa(·)是delta和加速度计算函数[25]。
With the magnitude and temporal spectrum approximation loss, the mask estimation network and the auxiliary network obtaining the adaptive weights are jointly optimized.
利用幅度和时间谱近似损失,对掩蔽估计网络和辅助网络获得自适应权值进行联合优化。
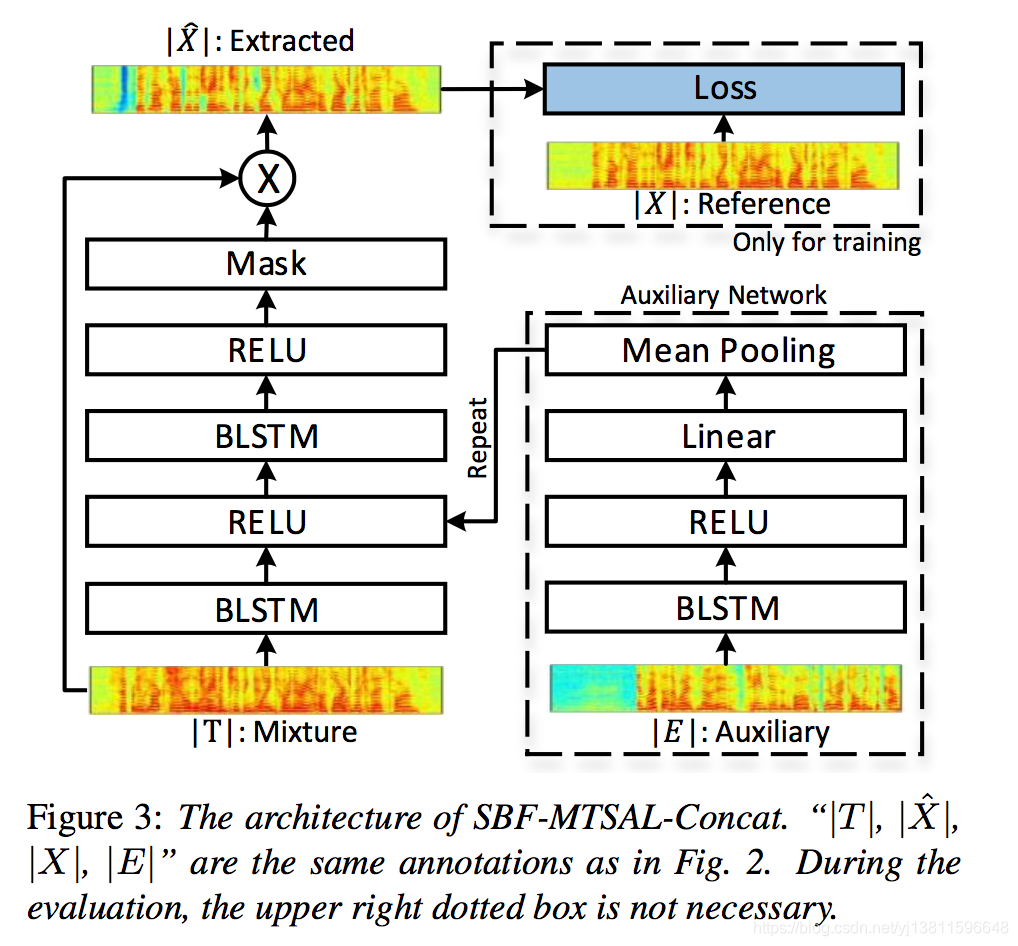
2.2. SBF-MTSAL-Concat
Fig. 3 illustrates the architecture of SBF-MTSAL-Concat framework [16] that extracts target speaker’s speech from the mixture. Different from the adaptive weights learned from frame level features by the auxiliary network in the SBF- MTSAL, the auxiliary network in SBF-MTSAL-Concat learns a speaker embedding from a different utterance of target speaker by a bidirectional long short-term memory networks (BLSTM). The BLSTM learns contextual information from the history and future frames of a whole utterance. The D dimensional speaker embedding (V ∈ RD) is obtained by mean pooling the learnt contextual information over all frames.
图3示出了从混合物中提取目标说话人的语音的SBF-MTSAL-Concat框架的架构。与SBF MTSAL中的辅助网络从帧级特征中学习的自适应权重不同,SBF MTSAR-CONTAT中的辅助网络通过双向长短期记忆网络(BLSTM)从说话人的不同话语中嵌入说话人。BLSTM从整个话语的历史和未来框架中学习语境信息。通过将学习到的上下文信息汇集到所有帧上,得到了D维说话人嵌入(V∈RD)。
Then, the speaker embedding representing speaker charac- teristics is repeatedly concatenated with the activation of an- other BLSTM in the mask estimation network. The concate- nated representations containing the mixture and target speaker information are used to estimate a phase sensitive mask with the same loss function as defined in equation (1). The loss is mini- mized to jointly optimize the mask estimation network and the auxiliary network that learns speaker embedding.
然后,将代表说话人特征的说话人嵌入与掩模估计网络中另一个BLSTM的激活重复连接。利用包含混合说话人信息和目标说话人信息的具体表示来估计具有等式(1)中定义的相同损失函数的相位敏感掩模。将损失最小化,共同优化掩蔽估计网络和学习说话人嵌入的辅助网络。
- ExperimentalSetup
3.1. SpeechData
WSJ0 corpus [26] was used to simulate the two-speaker mixed database for target speaker extraction and speaker verification experiments. We selected the utterances from WSJ0 corpus by following [9]. These utterances were considered as Clean Dataset and divided into three sets: training, development, and evaluation. Specifically, 11,560 utterances from 50 male and 51 female speakers were selected from WSJ0 “si tr s” set as the training and development sets. Among these utterances, 8,769 utterances were used as training set and another 2,791 utterances were selected as development set. The evaluation set included 1,857 enrollment utterances and 1,478 test utterances from 10 male and 8 female speakers in the WSJ0 “si dt 05” and “si et 05” sets. We down-sampled the database to 8kHz. The utterances in the database have an average duration of 7 seconds.
利用WSJ0语料库[26]对两人混合数据库进行了目标说话人提取和说话人验证实验。我们根据文献[9]从WSJ0语料库中选取话语。这些话语被认为是干净的数据集,分为三组:训练、发展和评价。具体来说,来自50名男性和51名女性演讲者的11560个话语被选入WSJ0“si-tr s”集合作为训练和发展集合。在这些话语中,8769个话语被用作训练集,另外2791个话语被选为发展集。评价集包括来自WSJ0“si dt 05”和“siet05”两个测试集中10名男性和8名女性的1857个注册语和1478个测试语。我们把数据库的采样频率降到了8kHz。数据库中的话语平均持续时间为7秒。
We used the Clean Dataset to generate the Two-speaker Mixed Dataset1, which also consisted of training, development, and evaluation sets. Each set was generated by the correspond- ing clean dataset. Specifically, the training set of two-speaker mixed dataset included 20, 000 mixtures which were generated by randomly mixing the utterances in the training set of clean dataset; Similarly, 5, 000 and 3, 000 mixed utterances were gen- erated as the development set and test utterances in the eval- uation set for the two speaker mixed database, respectively. Considering the interference speech as noise, the SNR of each mixture was randomly selected between 0dB and 5dB. The en- rollment utterances in the evaluation set of two-speaker mixed database were kept same as the those in the clean dataset.
我们使用干净的数据集生成两个说话人混合数据集1,(1,The database simulation code is available at: https:// github.com/xuchenglin28/speaker_extraction)其中还包括训练集、开发集和评估集。每个集合都是由相应的clean数据集生成的。具体而言,两个说话人混合数据集的训练集包括20, 000个混合,它们是通过在干净数据集的训练集中随机混合话语生成的;同样,5, 000个和3, 000个混合话语被作为两个说话者混合数据库的评估集中的开发集和测试话语生成,分别是。将干扰语音作为噪声,在0dB和5dB之间随机选取各混合语音的信噪比。双说话人混合数据库评价集中的滚动语句与干净数据集中的滚动语句保持一致。
In the simulation of two-speaker mixture, the first selected speaker was chosen as target speaker, the other one was inter- ference speaker. The utterance of the target speaker from the original WSJ0 corpus was used as reference speech. Another different utterance of this target speaker was randomly selected to be used as input to the auxiliary network. The mixtures were generated based on the rule of maximum duration. For example, if the duration of utterance A is 10 seconds and that of utterance B is 5 seconds, the duration of two speaker mixture would be 10 seconds. Therefore, the overlapped percentage of this mixture utterance is 50%. Figure 4 shows the overlapped percentage of two speaker mixture on training set, development set, and test utterances of evaluation set in the two-speaker mixed database. Most of two speaker mixtures are highly overlapped with the average length of 8.5 seconds.
在两个说话人混合的仿真中,首先选择一个说话人作为目标说话人,另一个为干扰说话人。将原始WSJ0语料库中目标说话人的话语作为参考语。该目标说话者的另一种不同的话语被随机地选择用作辅助网络的输入。混合物是基于最大持续时间的规则产生的。例如,如果话语A的持续时间为10秒,而话语B的持续时间为5秒,则两个说话人混合的持续时间为10秒。因此,该混合语的重叠率为50%。图4显示了两个说话人混合数据库中两个说话人混合在评价集的训练集、开发集和测试语句上的重叠百分比。两种说话人混合语的平均时长为8.5秒。
Since in both clean and two-speaker mixed datasets, the speakers in the evaluation set were different from the training and development sets, the evaluation set was used to evaluate the speaker verification performance. The interference speaker used to generate the test mixtures are not used as the enrollment in the speaker verification trials involving these test mixtures. The details are described in Section 3.3.
由于在干净和两个说话人混合数据集中,评价集中的说话人与训练集和开发集中的说话人不同,因此使用评价集来评价说话人验证性能。用于产生测试混合物的干扰扬声器不用作涉及这些测试混合物的说话人验证试验的登记。详情见第3.3节。
3.2. Target Speaker Extraction Network Setup
A short-time Fourier transform (STFT) was used with a win- dow length of 32ms and a shift of 16ms to obtain the magni- tude features from both of the input mixture for mask estima- tion network and input target speech for auxiliary network. The normalized square root hamming window was applied.
采用短时傅立叶变换(STFT),获得了32 ms的WEN -DOW长度和16ms的移位,以获得来自掩蔽估计网络的输入混合和辅助网络的输入目标语音的宏特征。应用归一化平方根hamming窗。
The learning rate started from 0.0005 and scaled down by 0.7 when the training loss increased on the development set. The minibatch size was set to 16. The network was trained with minimum 30 epochs and stopped when the relative loss reduction was lower than 0.01. The Adam algorithm [27] was used to optimize the network.
学习率从0.0005开始,当开发集上的训练损失增加时,学习率降低了0.7。小批量大小设置为16。该网络至少经过30个阶段的训练,当相对损失率小于0.01时停止。Adam算法[27]被用来优化网络。
The aforementioned magnitude extraction configuration and network training scheme were kept same in both SBF- MTSAL and SBF-MTSAL-Concat methods. The extracted magnitude were reconstructed into time-domain signal with phase of the mixture. Then the time-domain signal was used as input to the speaker verification system.
上述震级提取结构和网络训练方案在SBF-MTSAL和SBF-MTSAL-Concat方法中保持不变。将提取的幅度与混合信号的相位一起重构为时域信号。然后将时域信号作为说话人识别系统的输入。
For SBF-MTSAL, the auxiliary network was composed of
对于SBF MTSAL,辅助网络由
2 feed-forward relu hidden layers with 512 hidden nodes and a linear layer with 30 hidden nodes. The adaptation weights were obtained by averaging these 30 dimensional outputs over all the frames. The mask estimation network used a BLSTM with 512 cells in each forward and backward direction. The following adaptation layer had 30 sub-layers. Each sub-layer had 512 nodes with 1024 dimensional inputs from the outputs of the previous BLSTM. The 30 dimensional weights from the auxiliary network were used to weight these sub-layers, respec- tively. Then the activation of the adaptation layer was summed over all the sub-layers. Another 2 feed-forward relu hidden lay- ers with 512 nodes were appended. The mask layer had 129 nodes to predict the mask for the target speaker.
2个具有512个隐藏节点的前馈relu隐藏层和一个具有30个隐藏节点的线性层。通过在所有帧上平均这些30维输出,获得自适应权重。掩模估计网络使用了在每个正向和反向方向上都有512个单元的BLSTM。下面的适配层有30个子层。每个子层有512个节点,1024维输入来自前一个BLSTM的输出。从辅助网络的30维权重被用来加权这些子层,尊重。然后,在所有子层上对适应层的激活进行求和。另外添加了2个具有512个节点的前向relu隐藏层。掩模层有129个节点来预测目标说话人的掩模。
For SBF-MTSAL-Concat, the auxiliary had a BLSTM with 256 cells in each forward and backward direction, a feed- forward relu hidden layer with 256 nodes and a linear layer with 30 nodes. The output of the linear layer was averaged over all frames to obtain a 30 dimensional speaker embedding contain- ing target speaker characteristics. The speaker embedding was repeatedly concatenated with the activation of the BLSTM layer in the mask estimation network. The BLSTM had 512 cells in each forward and backward direction. Then the concatenated outputs were fed to a feed-forward relu hidden layer, a BLSTM layer and another feed-forward relu hidden layer. The BLSTM had 512 cells and the relu layers had 512 nodes. The mask layer had 129 nodes.
对于SBF MTSAR-CONTAT,辅助器具有BLSTM,每个前馈和反向方向上有256个单元,前馈Relu隐藏层具有256个节点,并且具有30个节点的线性层。线性层的输出在所有帧上平均,得到包含目标说话人特征的30维说话人嵌入。在掩模估计网络中,说话人嵌入与BLSTM层的激活反复连接。BLSTM在每个向前和向后方向上都有512个细胞。然后将连接的输出馈送到一个前向relu隐藏层、一个BLSTM层和另一个前向relu隐藏层。BLSTM有512个单元,relu层有512个节点。屏蔽层有129个节点。
3.3. Speaker Verification (SV) System
In the evaluation set of the two-speaker mixed dataset, we have 3000 target trials and 48,000 non-target trials for the SV eval- uation. In the evaluation trials, each enrollment utterance con- tained a contiguous speech segment from a single speaker and test utterance contained the overlapped speech from two speak- ers. We called this evaluation set as Mixture evaluation set. Moreover, to show the upper bound of target speaker extrac- tion on SV, we also generated corresponding Clean evaluation set2 with 51,000 trials from WSJ0 corpus according to the target speaker information of mixture set.
在双说话人混合数据集的评估集中,我们有3000个目标测试和48000个非目标测试用于SV评估。在评价实验中,每个被试话语都包含一个来自单个说话人的相邻语段,而测试话语则包含两个说话人的重叠语段。我们称此评估集为混合评估集。此外,为了显示SV上目标说话人提取的上界,我们还根据混合集的目标说话人信息,从WSJ0语料库中生成了相应的干净评价集2(2,The SV evaluation trials and keys for clean and mixture evaluation sets are available at: https://github.com/xuchenglin28/ speaker_extraction),测试次数为51000次。
The training and development sets of clean dataset, called as Clean(training&dev), were used for training UBM, total vari- ability matrix, LDA, and PLDA models. Because this paper di- rectly used the extracted target speaker’s speech for SV, it would cause the mismatch between extracted speech and clean speech. To solve this mismatched problem, we pooled 2,791 extracted speech from the development set of the simulated two-speaker mixed dataset and clean training set to train SV system. We called this training set as Clean(training)+Ext1 set. For further investigating the effectiveness of using extracted speech to train SV system, we also pooled all 5,000 extracted speech of the development set in two-speaker mixed dataset and the training set of clean dataset to train SV system. This pooling dataset was called as Clean(training)+Ext2 set. Section 4 will show the performance by using different training and evaluation set.
clean数据集的训练和开发集称为clean(training&dev),用于训练UBM、总变异矩阵、LDA和PLDA模型。由于本文直接将提取出的目标说话人语音用于SV,会造成提取语音与干净语音的不匹配。为了解决这一不匹配问题,我们将2791个从模拟双说话人混合数据集和干净训练集的开发集中提取的语音合并到SV系统中进行训练。我们称这个训练集为Clean(训练)+Ext1集。为了进一步研究提取语音训练SV系统的有效性,我们还将开发集的5000个提取语音集中在两个说话人混合数据集和干净数据集的训练集中训练SV系统。这个池数据集被称为Clean(training)+Ext2集。第4节将通过使用不同的培训和评估集来展示绩效。
The features of SV system were based on 19 MFCCs to- gether with energy plus their 1st- and 2nd-derivatives extracted from the speech regions, followed by cepstral mean normaliza- tion [28] with a window size of 3 seconds. A 60-dimensional acoustic vector is extracted every 10ms, using a Hamming win-dowing of 25ms. An energy based voice activity detection method is used to remove silence frames. The system was based on a gender-independent UBM with 512 mixtures. The training set described in the previous paragraph was used for estimating the UBM and total variability matrix with 400 total factors. The same data set was used for estimating the LDA and Gaussian PLDA models with 150 latent variables.
SV系统的特征是基于19个MFCCs来获取能量加上从语音区域提取的1阶和2阶导数,然后是倒谱平均归一化[28],窗口大小为3秒。采用25ms的Hamming-win-dowing算法,每10ms提取一个60维的声矢量,采用基于能量的语音活动检测方法去除静音帧。该系统是基于一个性别无关的UBM与512混合物。前一段描述的训练集用于估算具有400个总因子的UBM和总变异矩阵。用同样的数据集估计了含有150个潜在变量的LDA和Gaussian-PLDA模型。
- ExperimentalResults
To investigate the effect of overlapped test speech on SV, we perform the SV experiments on both mixture and clean eval- uation set described in Section 3.3. System 1 of Table 1 is the baseline system of SV with clean training data on mixture test set. System 10 of table 1 shows the upper bound perfor- mance (also called as ideal performance) of SE-SV for over- lapped multi-talker SV. Comparison between System 1 and 10 of Table 1 shows that the performance of SV system seriously degrades when the test speech is the overlapped multi-talker speech.
为了研究重叠测试语音对SV的影响,我们在第3.3节描述的混合和干净评估集上进行了SV实验。表1的系统1是SV的基线系统,在混合测试集上有干净的训练数据。表1的系统10显示了超重叠多通话器SV的SE-SV的上界性能(也称为理想性能)。表1中系统1和系统10的比较表明,当测试语音为重叠多人语音时,SV系统的性能严重下降。

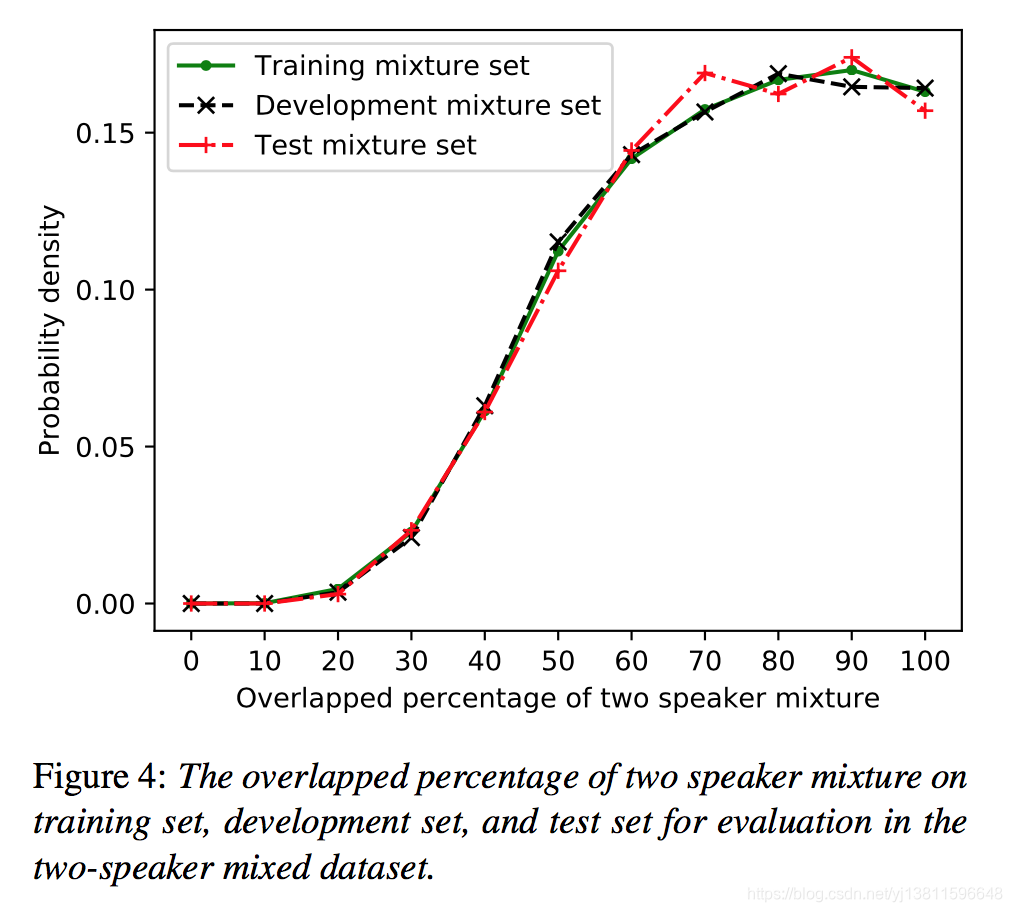
Table 1 presents the performances of SV systems with and without target speaker extraction. System 1 of Table 1 is the baseline results of overlapped multi-talker SV. Systems 4 to 6 and Systems 7 to 9 of Table 1 show the performances of SE-SV with SBF-MTSAL and SBF-MTSAL-Concat on multi- talker SV. The comparison of performances among Systems 1 to 9 suggests the following findings: (1) SE-SV significantly im- prove the performance of multi-talker SV, specifically, the per- formance of multi-talker SV after applying SE-SV with SBF- MTSAL-Concat can obtain around 64.4%, 27.7%, 18.1% rel- ative reduction over the baseline in terms of EER, DCF08, and DCF10, respectively; (2) SE-SV with SBF-MTSAL-Concat outperforms SE-SV with SBF-MTSAL in terms of both EER and DCFs; (3) pooling the clean training set and extracted speech data is effective to alleviate the effect caused by mis- match problem between clean and extrated speech; (4) more extracted speeches for SV training could further improve the performance of SE-SV on multi-talker SV; (5) comparing Sys- tem 2 with 5, and 8, we observe that most of improvement on the overlapped multi-talker SV is attributed to SE-SV. The same conclusion could be made by comparing System 3, 6, and 9.
表1给出了有无目标说话人提取的SV系统的性能。表1的系统1是重叠多通话器SV的基线结果。表1的系统4至6和系统7至9显示了在多对讲机SV上使用SBF-MTSAL和SBF-MTSAL Concat的SE-SV的性能。系统1与系统9的性能比较表明:(1)SE-SV显著改善了多话机SV的性能,特别是将SE-SV应用于SBF-MTSAL Concat后,多话机SV的性能比基线平均降低了64.4%,27.7%,18.1%,DCF08和DCF10;(2)在EER和DCF方面,带SBF MTSAL Concat的SE-SV均优于带SBF MTSAL的SE-SV;(3)将干净的训练集和提取的语音数据集中在一起,可以有效地缓解干净语音和提取的语音不匹配的影响;(4) 通过对系统2、系统5和系统8的比较,发现重叠多人语音的提高主要归因于多人语音的增强。通过比较系统3、系统6和系统9,可以得出同样的结论。
This paper also investigates the performance of oracle speaker diarization on multi-talker SV. To this end, we first ap- ply the energy-based VAD on the clean speech that makes up the mixture speech, then generate the diarization labels for the mixture speech according to the VAD labels of clean speech. Because WSJ0 speech data is very clean and energy-based VAD could works very well on it, we consider these diarization labels as oracle diarization labels. With the oracle speaker diarization, the average percentage of removed non-target speech frames in the mixture speeches is around 24%. System 13 in Table 1 shows the performance of multi-talker SV system with the ora- cle speaker diarization, which also means the best performance achieved by speaker diarization for multi-talker SV. The com- parison of performance among System 1, 9, and 13 suggests that our proposed SE-SV method significantly outperforms speaker diarization in the overlapped multi-talker scenarios.
本文还研究了在多通话器SV上oracle说话人二值化的性能。为此,我们首先对构成混合语音的干净语音进行基于能量的VAD处理,然后根据干净语音的VAD标签生成混合语音的二值化标签。由于WSJ0语音数据是非常干净的,基于能量的VAD可以在其上很好地工作,我们将这些二值化标签看作oracle二值化标签。在甲骨文说话人二值化的情况下,混合语音中去除非目标语音帧的平均百分比约为24%。表1中的系统13显示了使用单声道扬声器二次化的多扬声器SV系统的性能,这也意味着对于多扬声器SV,通过扬声器二次化实现的最佳性能。系统1、系统9和系统13的性能比较表明,我们提出的SE-SV方法在重叠多人场景中明显优于说话人二值化。
In Table 1, we also observe that the performance of System 11 and 12 with Clean+Ext training data slightly drops when comparing with System 10. This is expected as we include the mismatched data during training.
在表1中,我们还观察到,与系统10相比,具有Clean+Ext训练数据的系统11和系统12的性能略有下降。这是预期的,因为我们在训练中包含了不匹配的数据。
- Conclusions and Future Works
This paper proposes SE-SV to improve the performance of SV on overlapped multi-talker speech and compares with the ora- cle speaker diarization on this task. Experimental results show that the proposed SE-SV approach could significantly improve the performance of multi-talker SV and outperform the oracle speaker diarization system. Joint training of target speaker ex- traction and speaker embedding network for SV will be studied in the future work.
为了提高SV在重叠多人语音中的性能,提出了SE-SV算法,并与传统的说话人二值化算法进行了比较。实验结果表明,提出的SE-SV方法可以显著提高多用户SV的性能,并优于oracle的说话人二值化系统。在未来的工作中将研究SV中目标说话人提取和说话人嵌入网络的联合训练。
- Acknowledgements
This work is supported by the Neuromorphic Computing Pro- gramme under the RIE2020 Advanced Manufacturing and En- gineering Programmatic Grant A1687b0033 in Singapore.
这项工作得到新加坡RIE2020先进制造和工程项目拨款A168700033下神经形态计算程序的支持。
- References
[1] X. Anguera, S. Bozonnet, N. Evans, C. Fredouille, G. Fried- land, and O. Vinyals, “Speaker diarization: A review of recent research,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 2, pp. 356–370, 2012.
[2] O. Kudashev, S. Novoselov, K. Simonchik, and A. Kozlov, “A speaker recognition system for the SITW challenge.” in Proceed- ings of Interspeech, San Francisco, California, Sep. 2016, pp. 833–837.
[3] Y. Liu, Y. Tian, L. He, and J. Liu, “Investigating various diariza- tion algorithms for speaker in the wild (SITW) speaker recog- nition challenge,” in Proceedings of Interspeech, San Francisco, California, Sep. 2016, pp. 853–857.
[4] O. Novotny, P. Matejka, O. Plchot, O. Glembek, L. Burget, and J. Cernocky, “Analysis of speaker recognition systems in realistic scenarios of the SITW 2016 challenge.” San Francisco, California, Sep. 2016.
[5] H. Ghaemmaghami, M. H. Rahman, I. Himawan, D. Dean, A. Kanagasundaram, S. Sridharan, and C. Fookes, “Speakers in the wild (SITW): The QUT speaker recognition system,” in Pro- ceedings of Interspeech, San Francisco, California, Sep. 2016, pp. 838–842.
[6] D.Snyder,D.Garcia-Romero,G.Sell,A.McCree,D.Povey,and S. Khudanpur, “Speaker recognition for multi-speaker conversa- tions using x-vectors,” in Proceedings of ICASSP, Brighton, UK, May 2019.
[7] D. Charlet, C. Barras, and J.-S. Lie ́nard, “Impact of overlapping speech detection on speaker diarization for broadcast news and debates,” in Proceedings of ICASSP, 2013, pp. 7707–7711.
[8] S. H. Yella and H. Bourlard, “Overlapping speech detection us- ing long-term conversational features for speaker diarization in meeting room conversations,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 22, no. 12, pp. 1688– 1700, 2014.
[9] J.R.Hershey,Z.Chen,J.LeRoux,andS.Watanabe,“Deepclus- tering: Discriminative embeddings for segmentation and separa- tion,” in Proceedings of ICASSP, 2016, pp. 31–35.
[10] Z. Chen, Y. Luo, and N. Mesgarani, “Deep attractor network for single-microphone speaker separation,” in Proceedings of ICASSP, 2017, pp. 246–250.
[11] M.Kolbæk,D.Yu,Z.-H.Tan,andJ.Jensen,“Multitalkerspeech separation with utterance-level permutation invariant training of deep recurrent neural networks,” IEEE/ACM Transactions on Au- dio, Speech, and Language Processing, vol. 25, no. 10, pp. 1901– 1913, 2017.
[12] C. Xu, W. Rao, X. Xiao, E. S. Chng, and H. Li, “Single channel speech separation with constrained utterance level permutation invariant training using grid LSTM,” in Proceedings of ICASSP - Calgary, Alberta, Canada: IEEE, Apr. 2018.
[13] C.Xu,W.Rao,E.S.Chng,andH.Li,“Ashifteddeltacoefficient objective for monaural speech separation using multi-task learn- ing,” in Proceedings of Interspeech 2018, Hyderabad, India, Sep. 2018, pp. 3479–3483.
[14] K. Zˇmol ́ıkova ́, M. Delcroix, K. Kinoshita, T. Higuchi, A. Ogawa, and T. Nakatani, “Learning speaker representation for neural net- work based multichannel speaker extraction,” in 2017 IEEE Auto- matic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2017, pp. 8–15.
[15] M. Delcroix, K. Zmolikova, K. Kinoshita, A. Ogawa, and T. Nakatani, “Single channel target speaker extraction and recog- nition with speaker beam,” in Proceedings of ICASSP, 2018, pp. 5554–5558.
[16] C. Xu, W. Rao, E. S. Chng, and H. Li, “Optimization of speaker extraction neural network with magnitude and temporal spec- trum approximation loss,” in Proceedings of ICASSP 2019, arXiv preprint arXiv:1903.09952.
[17] J. Wang, J. Chen, D. Su, L. Chen, M. Yu, Y. Qian, and D. Yu, “Deep extractor network for target speaker recovery from single channel speech mixtures,” in Proceedings of Interspeech, Hyder- abad, India, Sep. 2018, pp. 307–311.
[18] Q. Wang, H. Muckenhirn, K. Wilson, P. Sridhar, Z. Wu, J. Her- shey, R. A. Saurous, R. J. Weiss, Y. Jia, and I. L. Moreno, “Voice- filter: Targeted voice separation by speaker-conditioned spectro- gram masking,” arXiv preprint arXiv:1810.04826, 2018.
[19] N. Dehak, P. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet, “Front-end factor analysis for speaker verification,” IEEE Trans. on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 788–798, May 2011.
[20] P. Kenny, “Bayesian speaker verification with heavy-tailed pri- ors,” in Proceedings of Odyssey: Speaker and Language Recogni- tion Workshop, Brno, Czech Republic, Jun. 2010.
[21] S. Prince and J. Elder, “Probabilistic linear discriminant analy- sis for inferences about identity,” in Proceedings of 11th Inter- national Conference on Computer Vision, Rio de Janeiro, Brazil, Oct. 2007, pp. 1–8.
[22] D. Garcia-Romero and C. Y. Espy-Wilson, “Analysis of i-vector length normalization in speaker recognition systems,” in Proceed- ings of Interspeech 2011, Florence, Italy, Aug. 2011, pp. 249–252.
[23] M. Delcroix, K. Kinoshita, C. Yu, A. Ogawa, T. Yoshioka, and T. Nakatani, “Context adaptive deep neural networks for fast acoustic model adaptation in noisy conditions,” in Proceedings of ICASSP, 2016, pp. 5270–5274.
[24] H.Erdogan,J.R.Hershey,S.Watanabe,andJ.LeRoux,“Phase- sensitive and recognition-boosted speech separation using deep recurrent neural networks,” in Proceedings of ICASSP, 2015, pp. 708–712.
[25] S. Furui, “Speaker-independent isolated word recognition us- ing dynamic features of speech spectrum,” IEEE Transaction on Acoustics, Speech, and Signal Processing, vol. 34, no. 1, pp. 52– 59, 1986.
[26] J. Garofolo, D. Graff, D. Paul, and D. Pallett, “CSR-I (WSJ0) Complete LDC93S6A,” Web Download. Philadelphia: Linguistic Data Consortium, 1993.
[27] D.KingmaandJ.Ba,“Adam:Amethodforstochasticoptimiza- tion,” arXiv preprint arXiv:1412.6980, 2014.
[28] B.S.Atal,“Effectivenessoflinearpredictioncharacteristicsofthe speech wave for automatic speaker identification and verification,” Journal of the Acoustical Society of America, vol. 55, no. 6, pp. 1304–1312, Jun. 1974.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









