




开发目的
解决漏洞扫描器的痛点
第一就是扫描量太大,对一个站点扫描了大量的无用 POC,浪费时间
指纹识别后还需要根据对应的指纹去进行 payload 扫描,非常的麻烦
开发思路
我们的思路分为大体分为指纹+POC+扫描
所以思路大概从这几个方面入手
首先就是 POC,我们得寻找一直在更新的 POC,而且是实时更新的,因为自己写的话有点太费时间了
但是这 POC 的决定是根据我们扫描器来的,因为世面上已经有许多不错的扫描器了,目前打算使用的是 nuclei 扫描器
https://github.com/projectdiscovery/nuclei
Nuclei 是一种现代、高性能的漏洞扫描程序,它利用基于 YAML 的简单模板。它使您能够设计自定义漏洞检测场景,以模拟真实世界的条件,从而实现零误报。
目前也在不断维护更新,当然还有 Xray,Goby 等工具也是不错的选择
然后回到指纹识别技术,这个需要大量的指纹样本,但是世面上的各种工具已经可以做得很好了
指纹识别
这里就的学习一下指纹识别的技术
首先我们需要知道收集指纹目前大概有哪些方法
指纹识别方式
特定文件
比如举一个例子,我们通常是如何判断一个框架是 thinkphp 呢?
我们随便找几个 thinkphp 的网站
特征就是它的图标是非常明显的
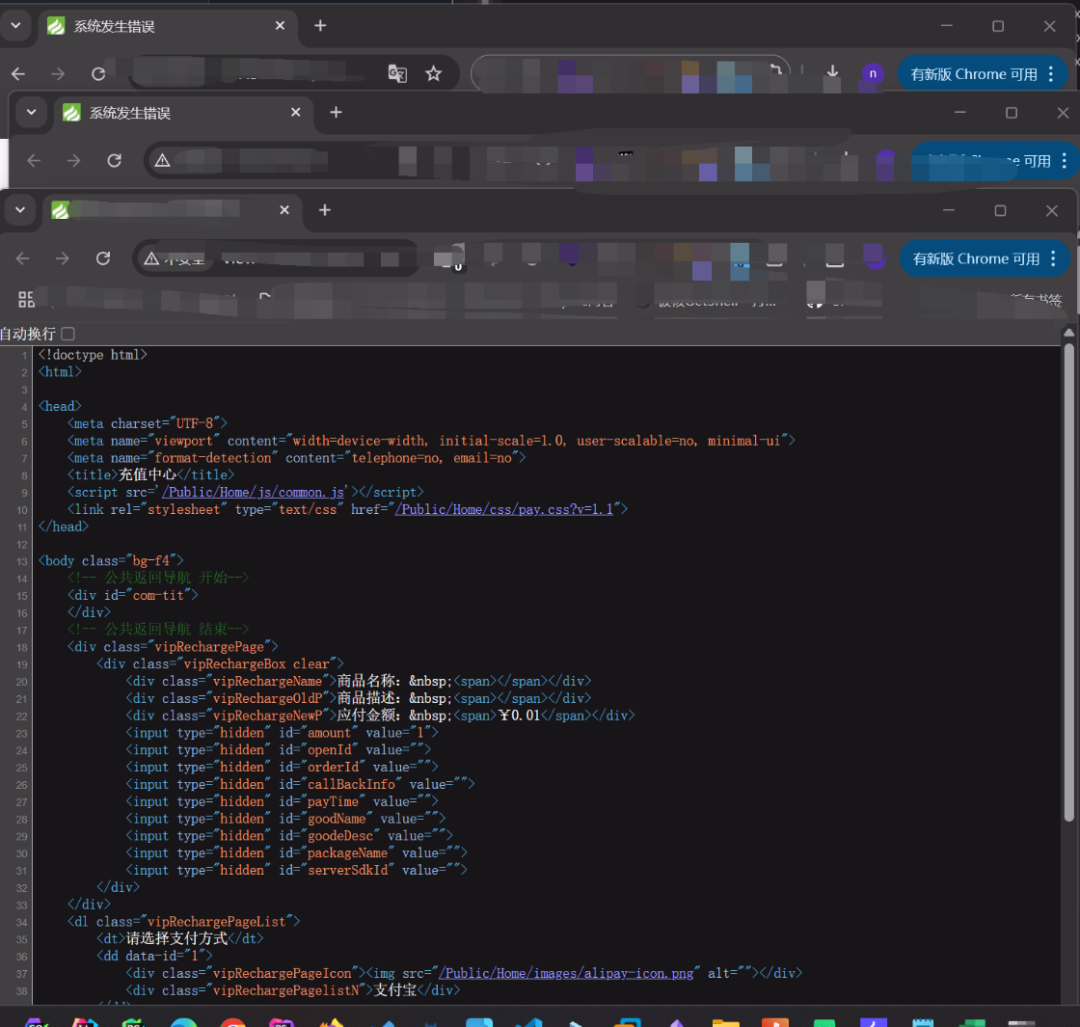
可以看到图标都是一样的,目前 fofa 和 hunter 已经有这种查找的方法了,一般都是把我们的图标换算为我们的 hash 值
这个就是我们的 favicon.ico 图标
一般网站是通过在路径后加入 favicon.ico 比如
http://xxxxxx/favicon.ico
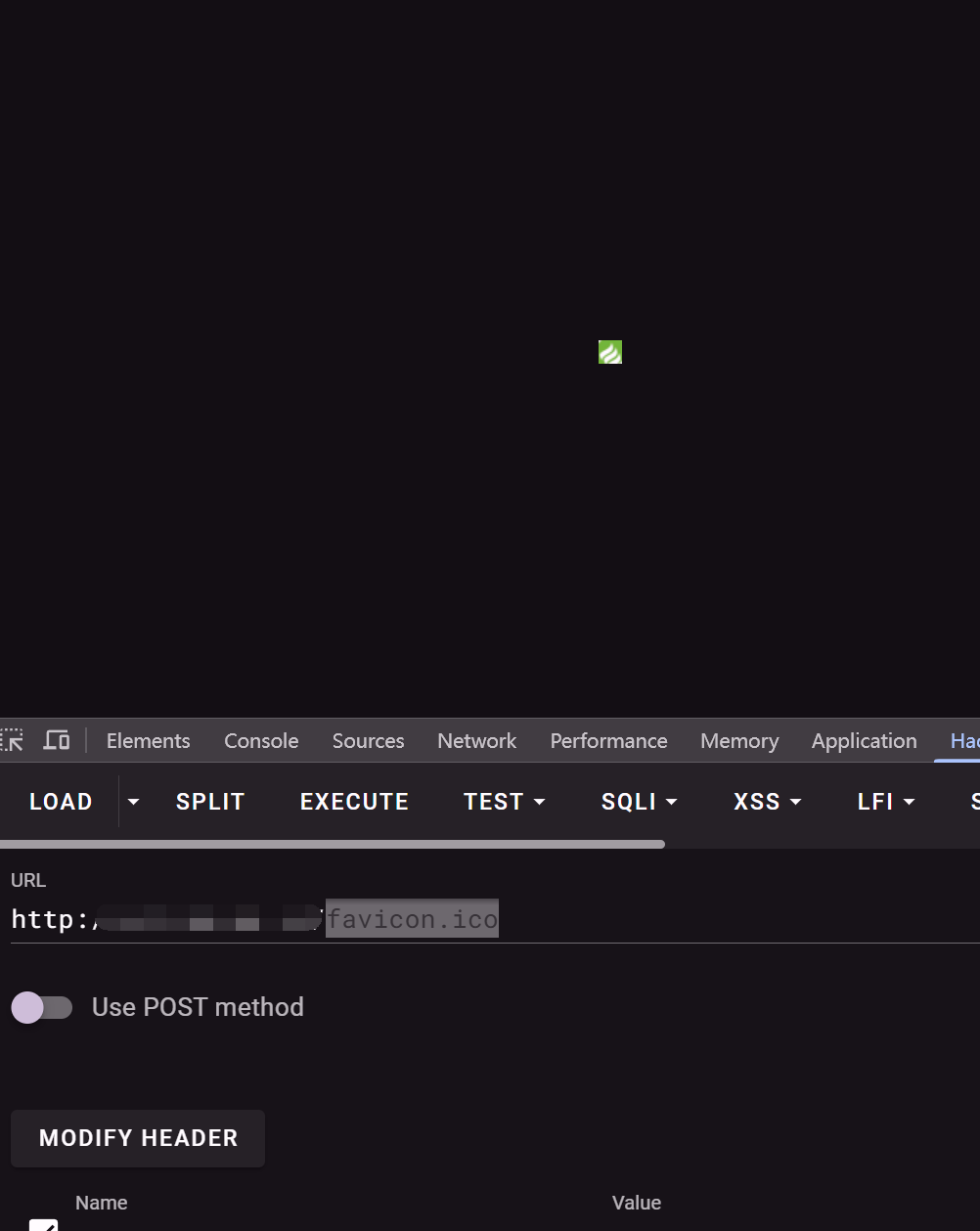
然后就能获取这个图标了,而在 fofa 中可以直接拖动查询了,可以直接算出 hash 值

比如 thinkphp 的
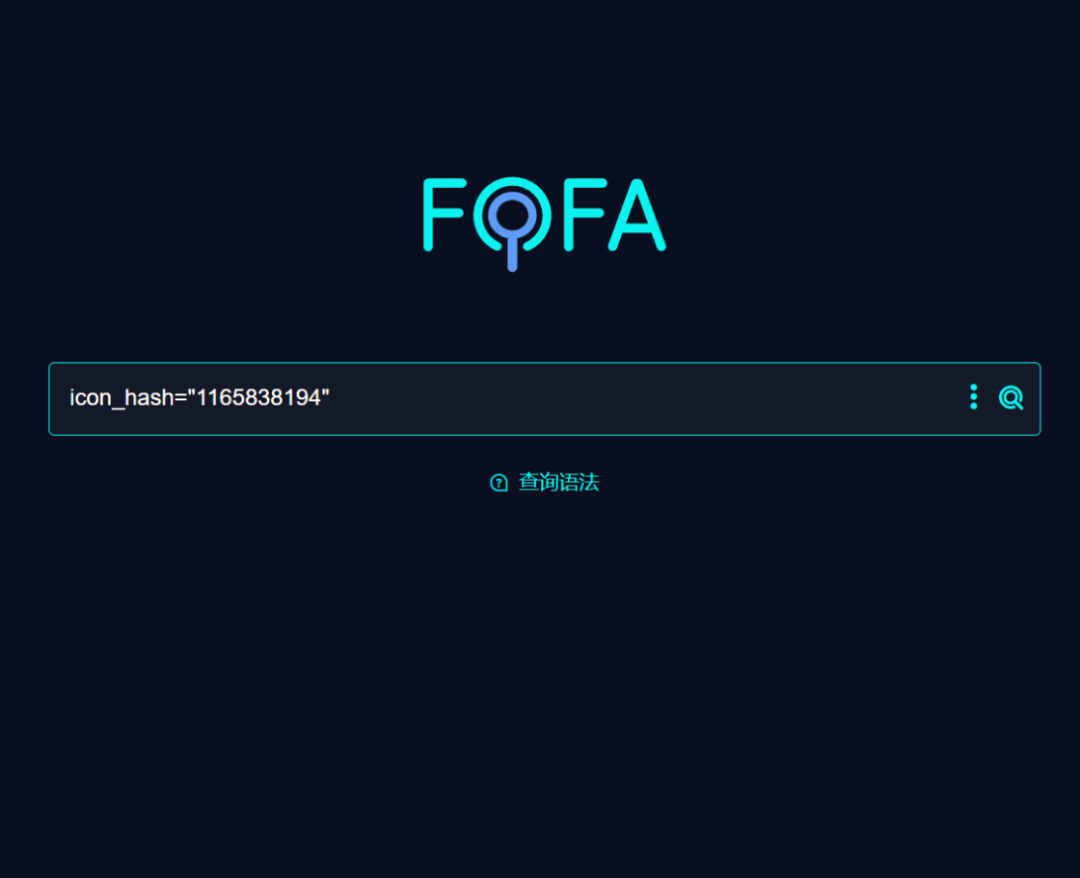
然后再次查询
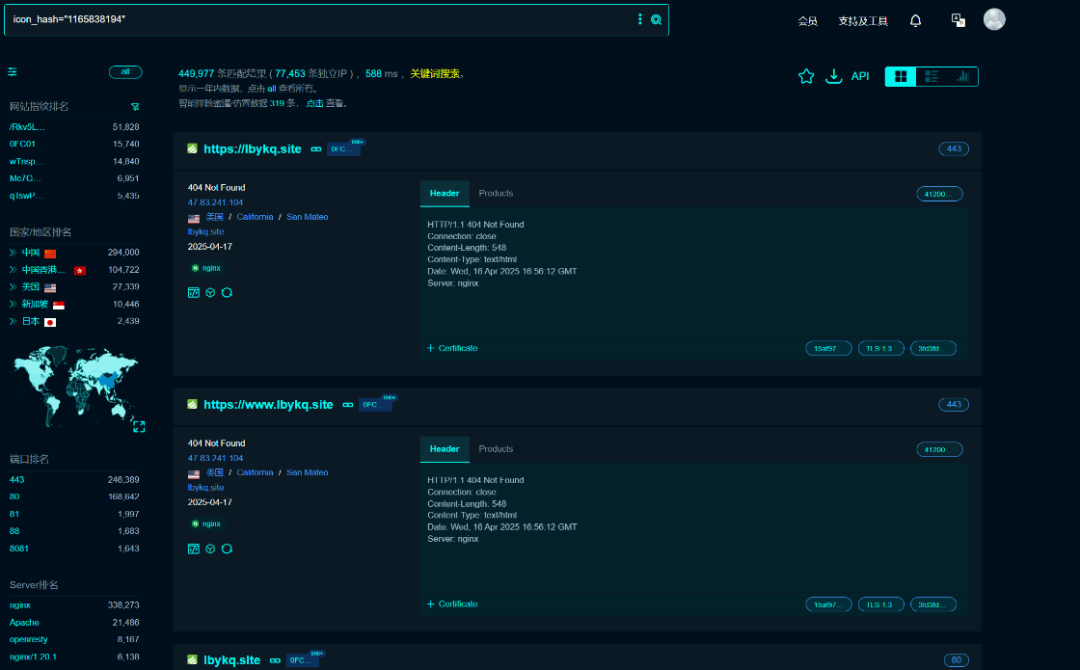
全是 tp 的网站
参考https://github.com/TideSec/TideFinger/blob/master/Web%E6%8C%87%E7%BA%B9%E8%AF%86%E5%88%AB%E6%8A%80%E6%9C%AF%E7%A0%94%E7%A9%B6%E4%B8%8E%E4%BC%98%E5%8C%96%E5%AE%9E%E7%8E%B0.md
当然除了我们的 ico 文件,还有其他很多的文件
一些网站的特定图片文件、js 文件、CSS 等静态文件,如 favicon.ico、css、logo.ico、js 等文件一般不会修改,通过爬虫对这些文件进行抓取并比对 md5 值,如果和规则库中的 Md5 一致则说明是同一 CMS。这种方式速度比较快,误报率相对低一些,但也不排除有些二次开发的 CMS 会修改这些文件。
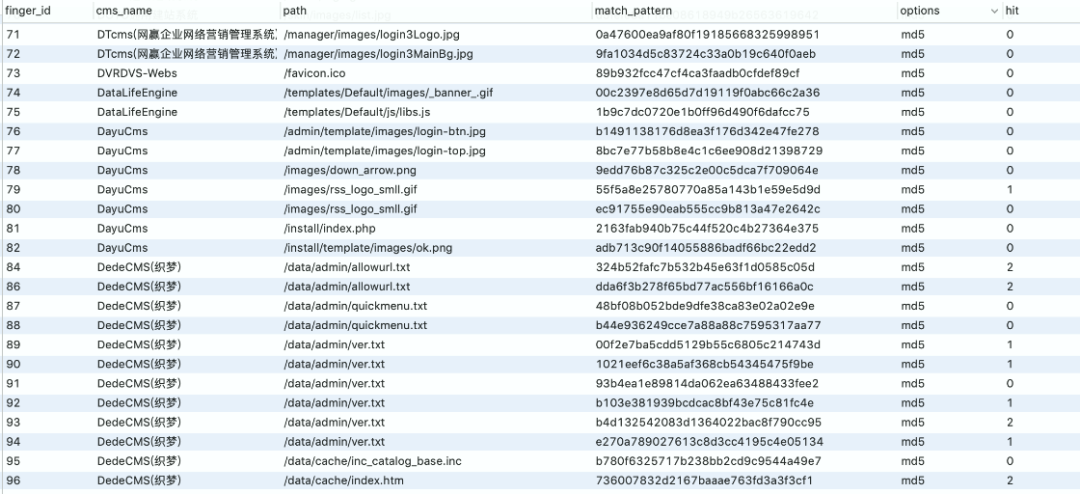
页面关键字
比如 tp 的错误页面大多数都是

我们 body 就可以包含这个关键字了
或者可以构造错误页面,根据报错信息来判断使用的 CMS 或者中间件信息,比较常见的如 tomcat 和 spring 的报错页面。
根据 response header 一般有以下几种识别方式:
请求头关键字
根据网站 response 返回头信息进行关键字匹配,这个一般是 ningx 这种
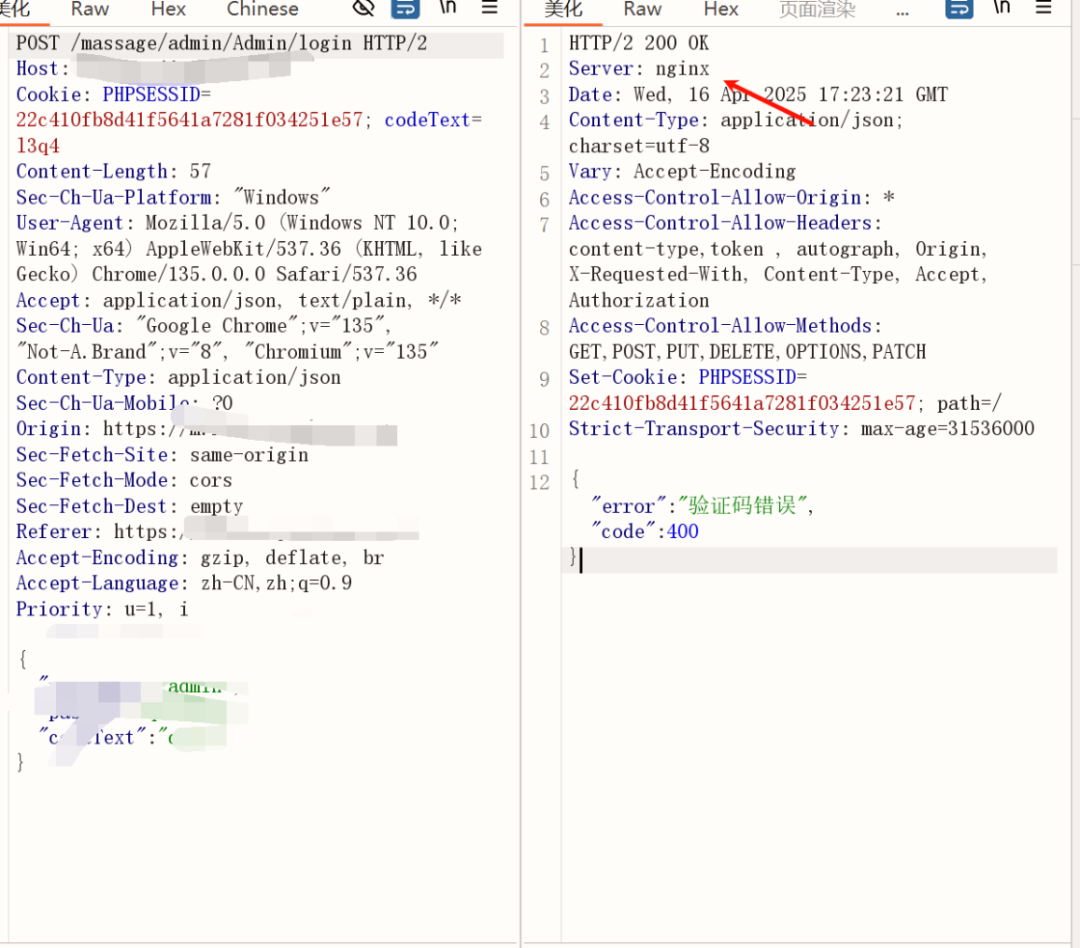
能够识别我们的服务器
URL 路径
根据总结
wordpress 默认存在 wp-includes 和 wp-admin 目录,织梦默认管理后台为 dede 目录,solr 平台可能使用/solr 目录,weblogic 可能使用 wls-wsat 目录等。
大部分还是根据我们的 body
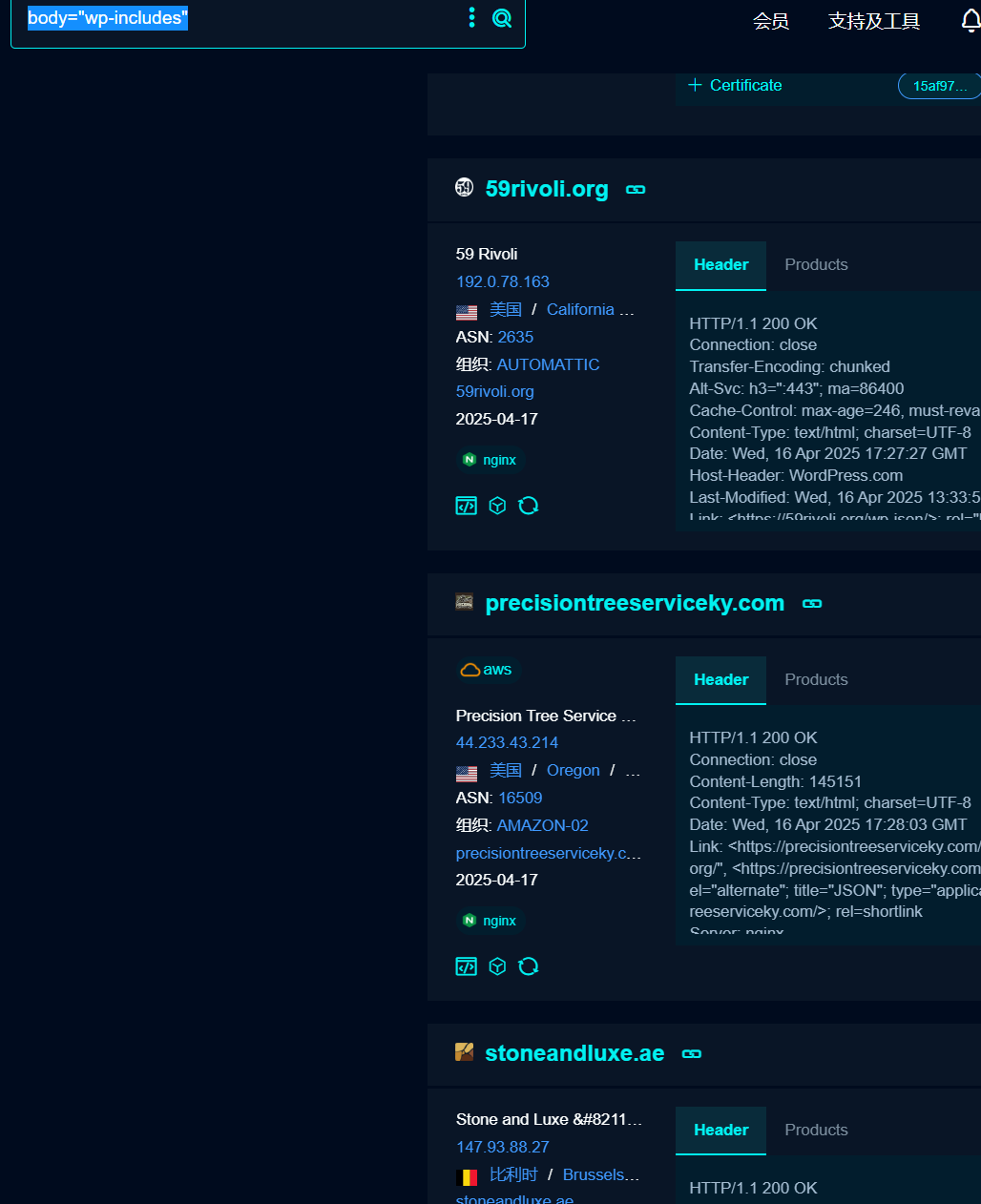
然后点一个进去
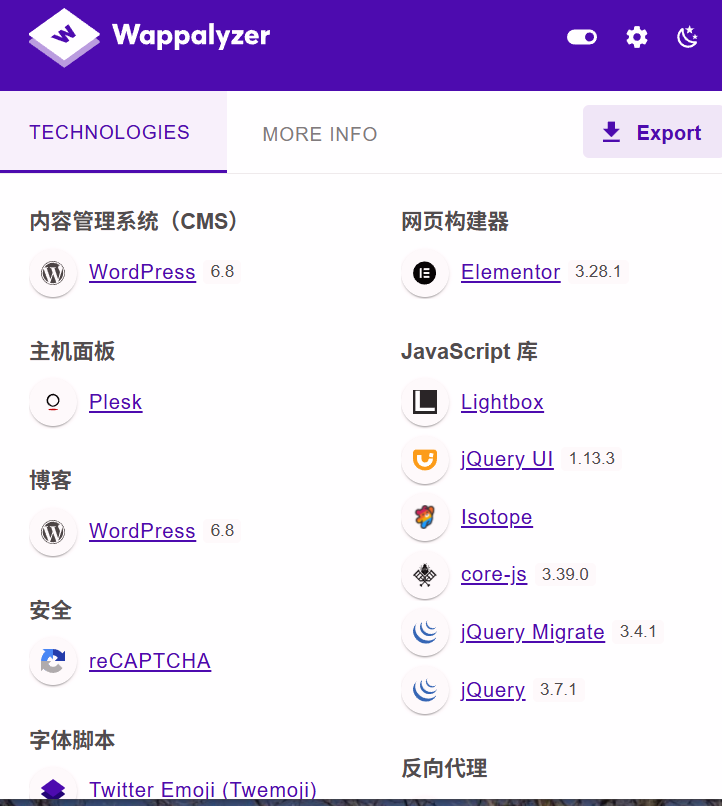
可以看到都是我们的 wordPress 的站点
指纹识别方法
有了我们上面的识别技术,那么我们大概是如何来识别一个指纹的呢
首先使用 python 简单举一个实现
首先就是需要一个配置文件,这个配置文件就需要包含我们的大体指纹和验证方法
- name: ThinkPHP
matchers:
- type: header
rule: X-Powered-By
keyword: ThinkPHP
- type: body
keyword: "http://www.thinkphp.cn"
- type: banner
keyword: thinkphp
- type: path
path: /thinkphp/library/think/
keyword: class
- type: favicon_hash
hash: 1165838194
然后就是我们的后端处理逻辑了
import yaml
import requests
import socket
import base64
import mmh3
def get_http_response(url, path=""):
try:
full_url = url.rstrip("/") + path
return requests.get(full_url, timeout=5)
except:
return None
def get_tcp_banner(ip, port=80):
try:
with socket.create_connection((ip, port), timeout=5) as s:
banner = s.recv(1024).decode(errors="ignore")
return banner
except:
return""
def get_favicon_hash(url):
try:
res = requests.get(url.rstrip("/") + "/favicon.ico", timeout=5)
favicon = base64.encodebytes(res.content)
return mmh3.hash(favicon.decode('utf-8'))
except:
return None
def load_fingerprints(path="fingerprints.yaml"):
with open(path, "r", encoding="utf-8") as f:
return yaml.safe_load(f)
def match_fingerprint(url, ip=None):
fingerprints = load_fingerprints()
results = []
res = get_http_response(url)
banner = get_tcp_banner(ip or url.replace("http://", "").replace("https://",  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









