



一、引言
在现代分布式系统架构中,一个常见的场景是:电商平台的用户在“黑色星期五”凌晨准时提交订单,系统需要在极短时间内完成库存扣减、订单创建、支付处理、物流通知、积分计算、推荐系统更新等十多个步骤。如果采用传统的同步调用方式,任何一个服务的延迟或故障都可能导致整个下单流程失败,用户体验将受到严重影响。
这就是消息队列技术要解决的核心问题。消息队列(Message Queue) 作为分布式系统中的“中枢神经系统”,通过在生产者和消费者之间引入一个缓冲层,实现了系统间通信的革命性转变。从早期的企业级消息中间件IBM MQ、Tibco,到现代开源解决方案RabbitMQ、Kafka,再到云服务商提供的托管服务(AWS SQS、Azure Service Bus),消息队列技术已经演进成为构建弹性、可扩展、高可用系统的基石。
对于开发者而言,理解并掌握消息队列技术不仅是解决特定问题的工具,更是构建现代化、松耦合架构的必备思维。无论是在系统设计面试中,还是在实际的微服务架构实践中,消息队列相关的知识都已成为区分初级与高级工程师的重要标尺。本文将深入探讨消息队列的三大核心价值——解耦、异步、削峰,并通过对比RabbitMQ与Kafka这两大主流技术,帮助你构建完整的消息队列知识体系。
二、核心概念:消息队列如何重塑系统架构
2.1 从紧耦合到松耦合:架构范式的演进
为了更好地理解消息队列的价值,让我们先看一个典型的电商系统订单处理流程的演变:
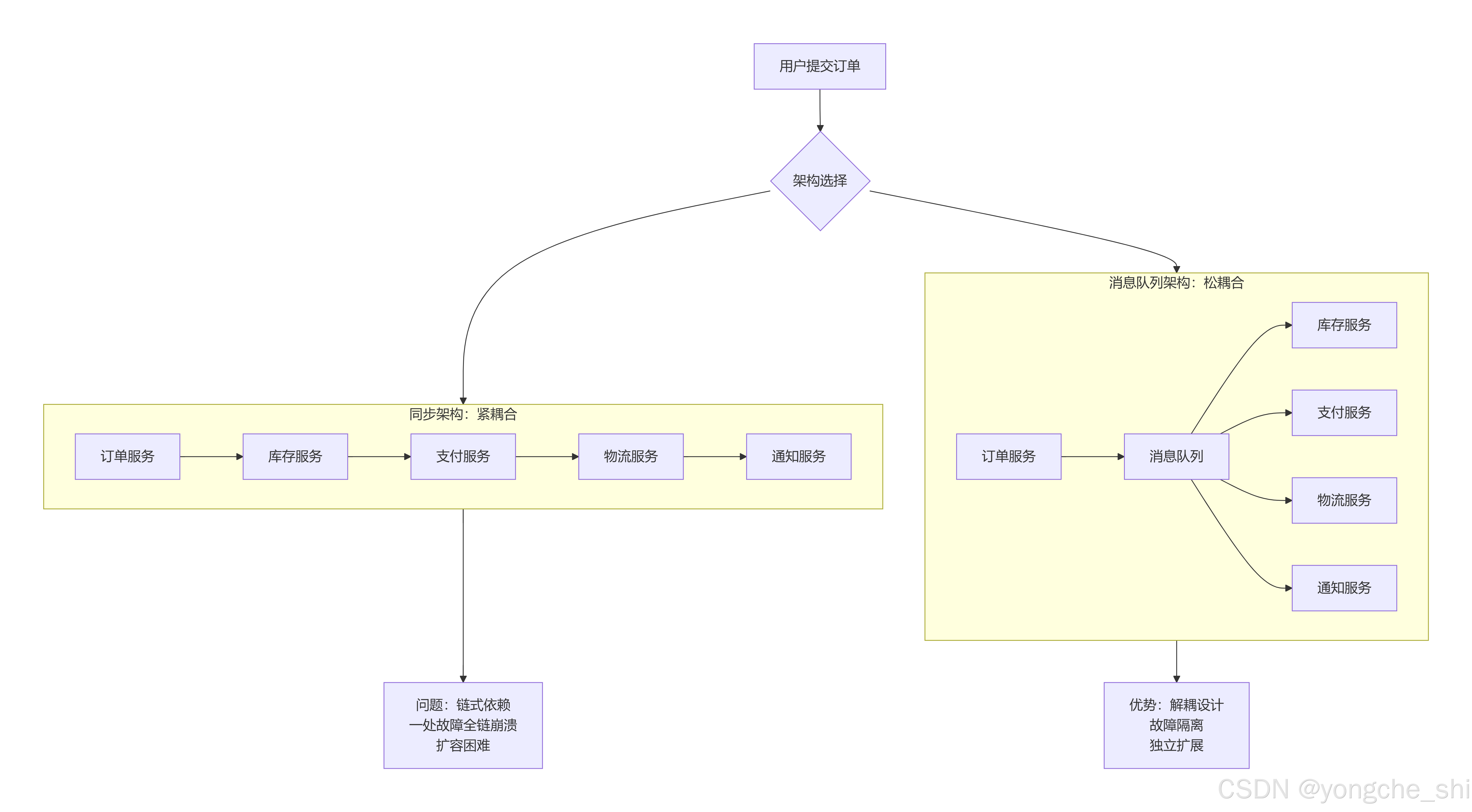
同步调用架构的问题:
-
链式故障传播:如果库存服务响应慢,整个订单流程都会阻塞
-
服务间强依赖:每个服务都需要知道下游服务的地址和接口
-
扩展困难:需要同时扩展所有相关服务,无法针对热点服务单独扩容
-
技术栈绑定:所有服务必须使用兼容的通信协议和技术栈
消息队列架构的优势:
-
故障隔离:单个服务故障不影响其他服务
-
异步处理:生产者发送消息后即可返回,无需等待消费者处理
-
弹性扩展:可以根据负载独立扩展生产者或消费者
-
技术异构:不同服务可以使用不同的技术栈,只需遵循消息格式协议
2.2 消息队列的三大核心价值
2.2.1 解耦(Decoupling)
解耦是消息队列最根本的价值。它打破了服务间的直接依赖关系,将“服务调用”转变为“事件通知”。
# 紧耦合的同步调用方式(问题示例)
class OrderService:
def create_order(self, order_data):
# 1. 调用库存服务
inventory_response = requests.post(
"http://inventory-service/lock",
json={"product_id": order_data.product_id, "quantity": order_data.quantity},
timeout=5
)
if not inventory_response.ok:
raise Exception("库存锁定失败")
# 2. 调用支付服务
payment_response = requests.post(
"http://payment-service/charge",
json={"user_id": order_data.user_id, "amount": order_data.amount},
timeout=10
)
if not payment_response.ok:
# 需要回滚库存
requests.post("http://inventory-service/unlock", json={...})
raise Exception("支付失败")
# 3. 调用物流服务
shipping_response = requests.post(
"http://shipping-service/create",
json={"order_id": order_data.id, "address": order_data.address},
timeout=8
)
# ...更多调用
return {"status": "success"}
# 松耦合的消息队列方式(解决方案)
class DecoupledOrderService:
def __init__(self, message_producer):
self.producer = message_producer
def create_order(self, order_data):
# 1. 本地事务中创建订单记录
order = self.save_order_to_db(order_data)
# 2. 发布订单创建事件(非阻塞)
event = {
"event_type": "ORDER_CREATED",
"order_id": order.id,
"user_id": order.user_id,
"product_id": order.product_id,
"quantity": order.quantity,
"amount": order.amount,
"timestamp": datetime.now().isoformat()
}
self.producer.publish("order.events", event)
# 3. 立即返回,无需等待下游处理
return {"status": "processing", "order_id": order.id}
解耦带来的架构优势:
-
独立演进:服务可以独立升级、重构,只要保持消息格式兼容
-
故障隔离:库存服务宕机不影响订单创建,用户仍可下单
-
技术多样性:库存服务可以用Java,通知服务可以用Python,通过消息格式统一通信
2.2.2 异步(Asynchronous)
异步处理允许生产者发送消息后立即返回,而不必等待消费者处理完成。这种“发后即忘”(Fire-and-Forget)模式显著提升了系统的响应速度。
# 同步处理 vs 异步处理的性能对比
import time
from concurrent.futures import ThreadPoolExecutor
def sync_processing():
"""同步处理:总时间 = 所有步骤时间之和"""
start = time.time()
# 模拟多个处理步骤
time.sleep(0.1) # 步骤1:验证数据
time.sleep(0.3) # 步骤2:处理业务逻辑
time.sleep(0.2) # 步骤3:发送通知
time.sleep(0.4) # 步骤4:更新分析系统
total_time = time.time() - start
return total_time # 约1.0秒
def async_processing():
"""异步处理:总时间 ≈ 最慢步骤的时间(如果并行)"""
start = time.time()
with ThreadPoolExecutor(max_workers=4) as executor:
# 并行执行所有步骤
futures = [
executor.submit(time.sleep, 0.1), # 步骤1
executor.submit(time.sleep, 0.3), # 步骤2
executor.submit(time.sleep, 0.2), # 步骤3
executor.submit(time.sleep, 0.4), # 步骤4
]
# 等待所有步骤完成
for future in futures:
future.result()
total_time = time.time() - start
return total_time # 约0.4秒(最慢的步骤4)
# 在消息队列架构中,异步处理的优势更加明显
# 生产者只需发送消息(通常<10ms),用户即可获得响应
# 消费者在后台按照自己的节奏处理消息
异步处理的典型应用场景:
-
用户注册流程:注册成功后,立即返回,后台异步发送欢迎邮件、初始化用户资料等
-
数据处理流水线:上传文件后立即返回,后台进行格式转换、分析、归档等处理
-
实时通知系统:用户操作后立即返回,通知通过消息队列分发给多个子系统
2.2.3 削峰(Traffic Shaping)
削峰填谷是消息队列应对突发流量的核心能力。当系统遇到流量高峰时,消息队列作为缓冲区,平滑流量冲击,保护后端系统。
# 流量削峰的直观示例
import matplotlib.pyplot as plt
import numpy as np
# 模拟24小时的请求流量
hours = np.arange(0, 24, 0.1)
# 典型模式:白天高,夜间低,加上随机突发
baseline = 1000 + 800 * np.sin((hours - 9) * np.pi / 12) # 白天高峰
spikes = np.random.poisson(5, len(hours)) * 200 # 随机突发
requests = baseline + spikes
# 无削峰的系统直接处理所有请求
system_capacity = 1500 # 系统最大处理能力
overflow = np.maximum(0, requests - system_capacity)
# 有削峰的消息队列缓冲
queue_buffer = 5000 # 消息队列缓冲能力
queue_accumulation = np.zeros_like(requests)
processed = np.zeros_like(requests)
for i in range(len(requests)):
if i == 0:
queue_accumulation[i] = max(0, requests[i] - system_capacity)
processed[i] = min(requests[i], system_capacity)
else:
# 队列中积累的消息
queue_from_previous = queue_accumulation[i-1]
# 本次可处理的消息(系统容量)
can_process = min(queue_from_previous + requests[i], system_capacity)
processed[i] = can_process
# 队列中剩余的消息
queue_accumulation[i] = max(0, queue_from_previous + requests[i] - system_capacity)
# 可视化对比
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes[0, 0].plot(hours, requests, label='原始请求流量')
axes[0, 0].axhline(y=system_capacity, color='r', linestyle='--', label='系统容量')
axes[0, 0].fill_between(hours, system_capacity, requests, where=(requests>system_capacity), alpha=0.3, color='red')
axes[0, 0].set_title('无削峰:系统过载区域')
axes[0, 0].set_xlabel('时间(小时)')
axes[0, 0].set_ylabel('请求数/小时')
axes[0, 0].legend()
axes[0, 0].grid(True)
axes[0, 1].plot(hours, processed, label='实际处理请求', color='green')
axes[0, 1].plot(hours, requests, label='原始请求', alpha=0.5)
axes[0, 1].axhline(y=system_capacity, color='r', linestyle='--', label='系统容量')
axes[0, 1].set_title('有削峰:平滑处理')
axes[0, 1].set_xlabel('时间(小时)')
axes[0, 1].set_ylabel('请求数/小时')
axes[0, 1].legend()
axes[0, 1].grid(True)
axes[1, 0].plot(hours, overflow, label='被拒绝的请求', color='red')
axes[1, 0].set_title('无削峰:请求丢失情况')
axes[1, 0].set_xlabel('时间(小时)')
axes[1, 0].set_ylabel('丢失请求数')
axes[1, 0].legend()
axes[1, 0].grid(True)
axes[1, 1].plot(hours, queue_accumulation, label='队列积压', color='orange')
axes[1, 1].axhline(y=queue_buffer, color='r', linestyle='--', label='队列容量')
axes[1, 1].set_title('消息队列积压情况')
axes[1, 1].set_xlabel('时间(小时)')
axes[1, 1].set_ylabel('积压消息数')
axes[1, 1].legend()
axes[1, 1].grid(True)
plt.tight_layout()
plt.show()
削峰的核心机制:
-
缓冲池:消息队列作为临时存储,吸收突发流量
-
可控的消费速率:消费者按照自身处理能力拉取消息,避免过载
-
优先级队列:重要消息优先处理,保证关键业务不受影响
-
死信队列:处理失败的消息转入特殊队列,避免阻塞正常流程
2.3 RabbitMQ vs Kafka:两种不同的设计哲学
虽然RabbitMQ和Kafka都是消息队列,但它们的设计目标和适用场景有显著差异:
| 维度 | RabbitMQ | ApacheKafka |
|---|---|---|
| 设计目标 | 企业级消息代理,可靠的消息传递 高吞吐量分布式流处理平台 | |
| 数据模型 | 队列(Queue)模型,消息被消费后删除 | 日志(Log)模型,消息持久化可重放 |
| 消息消费 | 基于推送(Push),消费者被动接收 | 基于拉取(Pull),消费者主动获取 |
| 消息存储 | 内存为主,可持久化到磁盘 | 磁盘顺序写入,高吞吐持久化 |
| 吞吐量 | 万级到十万级 QPS | 十万级到百万级 QPS |
| 典型场景 | 任务分发、RPC、工作队列 | 日志收集、流处理、事件溯源 |
| 消息顺序 | 队列内保证顺序(单个消费者) | 分区内保 |
| 协议支持 | AMQP、STOMP、MQTT等 | 自定义二进制协议 |
三、基础构建:RabbitMQ与Kafka的核心机制
3.1 RabbitMQ:基于AMQP的企业级消息代理
3.1.1 AMQP模型与核心概念
RabbitMQ实现了AMQP(Advanced Message Queuing Protocol)协议,其核心架构基于生产者、消费者、交换机和队列的交互:
RabbitMQ核心组件详解:
- 连接(Connection)与信道(Channel):
import pika
# 创建到RabbitMQ服务器的连接
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host='localhost',
port=5672,
credentials=pika.PlainCredentials('guest', 'guest')
)
)
# 创建信道(TCP连接内的轻量级逻辑连接)
channel = connection.channel()
# 声明一个队列(幂等操作,如果队列已存在则不影响)
channel.queue_declare(
queue='order_queue',
durable=True, # 队列持久化
exclusive=False, # 非独占队列
auto_delete=False, # 不自动删除
arguments={
'x-max-length': 10000, # 队列最大长度
'x-message-ttl': 3600000, # 消息存活时间(毫秒)
}
)
- 交换机类型与路由:
# 1. Direct Exchange - 直接交换机(精确匹配)
channel.exchange_declare(
exchange='order_direct',
exchange_type='direct',
durable=True
)
channel.queue_bind(
queue='order_queue',
exchange='order_direct',
routing_key='order.created' # 精确匹配此路由键
)
# 2. Topic Exchange - 主题交换机(模式匹配)
channel.exchange_declare(
exchange='order_topic',
exchange_type='topic',
durable=True
)
channel.queue_bind(
queue='order_queue',
exchange='order_topic',
routing_key='order.*' # 匹配 order.created, order.paid 等
)
# 3. Fanout Exchange - 扇形交换机(广播)
channel.exchange_declare(
exchange='order_fanout',
exchange_type='fanout',
durable=True
)
# Fanout交换机会忽略routing_key,广播到所有绑定的队列
# 4. Headers Exchange - 头部交换机(属性匹配)
channel.exchange_declare(
exchange='order_headers',
exchange_type='headers',
durable=True
)
channel.queue_bind(
queue='order_queue',
exchange='order_headers',
arguments={
'x-match': 'all', # 所有头部必须匹配(或'any'表示任意匹配)
'type': 'order',
'format': 'json'
}
)
3.1.2 消息发布与消费
# 生产者:发布消息
def publish_order_event(channel, order_data):
"""发布订单创建事件"""
message = json.dumps({
'event_type': 'ORDER_CREATED',
'order_id': order_data['id'],
'user_id': order_data['user_id'],
'total_amount': order_data['amount'],
'timestamp': datetime.now().isoformat()
})
channel.basic_publish(
exchange='order_direct',
routing_key='order.created',
body=message,
properties=pika.BasicProperties(
delivery_mode=2, # 持久化消息
content_type='application/json',
content_encoding='utf-8',
headers={
'source': 'order_service',
'version': '1.0'
}
)
)
print(f"订单事件已发布: {order_data['id']}")
# 消费者:处理消息
def process_order(channel, method, properties, body):
"""处理订单消息"""
try:
message = json.loads(body.decode('utf-8'))
# 业务处理逻辑
order_id = message['order_id']
print(f"开始处理订单: {order_id}")
# 模拟业务处理
process_inventory(order_id)
process_payment(order_id)
process_shipping(order_id)
# 确认消息已成功处理
channel.basic_ack(delivery_tag=method.delivery_tag)
print(f"订单处理完成: {order_id}")
except Exception as e:
print(f"订单处理失败: {e}")
# 拒绝消息,可以设置requeue=True重新入队
channel.basic_nack(
delivery_tag=method.delivery_tag,
requeue=False # 不重新入队,避免死循环
)
# 可以将失败消息发送到死信队列
send_to_dead_letter(channel, body, properties, str(e))
def start_order_consumer():
"""启动订单消费者"""
connection = create_rabbitmq_connection()
channel = connection.channel()
# 设置服务质量(QoS),限制未确认消息数量
channel.basic_qos(prefetch_count=10)
# 开始消费消息
channel.basic_consume(
queue='order_queue',
on_message_callback=process_order,
auto_ack=False # 手动确认模式
)
print('订单消费者已启动,等待消息...')
channel.start_consuming()
3.1.3 高级特性:死信队列与延迟消息
# 死信队列配置
def setup_dead_letter_queue(channel):
"""设置死信队列处理失败消息"""
# 1. 创建死信交换机
channel.exchange_declare(
exchange='dlx_exchange',
exchange_type='direct',
durable=True
)
# 2. 创建死信队列
channel.queue_declare(
queue='dead_letter_queue',
durable=True,
arguments={
'x-queue-mode': 'lazy' # 惰性队列,消息直接存磁盘
}
)
channel.queue_bind(
queue='dead_letter_queue',
exchange='dlx_exchange',
routing_key='dead_letter'
)
# 3. 主队列绑定死信交换机
channel.queue_declare(
queue='order_queue',
durable=True,
arguments={
'x-dead-letter-exchange': 'dlx_exchange', # 死信交换机
'x-dead-letter-routing-key': 'dead_letter', # 死信路由键
'x-max-length': 10000, # 队列最大长度
'x-message-ttl': 3600000, # 消息过期时间(1小时)
'x-overflow': 'reject-publish' # 队列满时拒绝新消息
}
)
# 延迟消息(通过插件或死信队列实现)
def send_delayed_message(channel, message, delay_ms):
"""发送延迟消息"""
# 使用RabbitMQ延迟消息插件
channel.queue_declare(
queue='delayed_queue',
durable=True,
arguments={
'x-delayed-type': 'direct',
'x-delayed-message': True
}
)
channel.exchange_declare(
exchange='delayed_exchange',
exchange_type='x-delayed-message',
durable=True,
arguments={'x-delayed-type': 'direct'}
)
channel.queue_bind(
queue='delayed_queue',
exchange='delayed_exchange',
routing_key='delayed'
)
# 发送延迟消息
channel.basic_publish(
exchange='delayed_exchange',
routing_key='delayed',
body=message,
properties=pika.BasicProperties(
headers={'x-delay': delay_ms} # 延迟毫秒数
)
)
3.2 Apache Kafka:高吞吐分布式流平台
3.2.1 Kafka核心架构
Kafka采用发布-订阅模型,其核心概念包括主题(Topic)、分区(Partition)、生产者(Producer)、消费者(Consumer)和消费者组(Consumer Group):
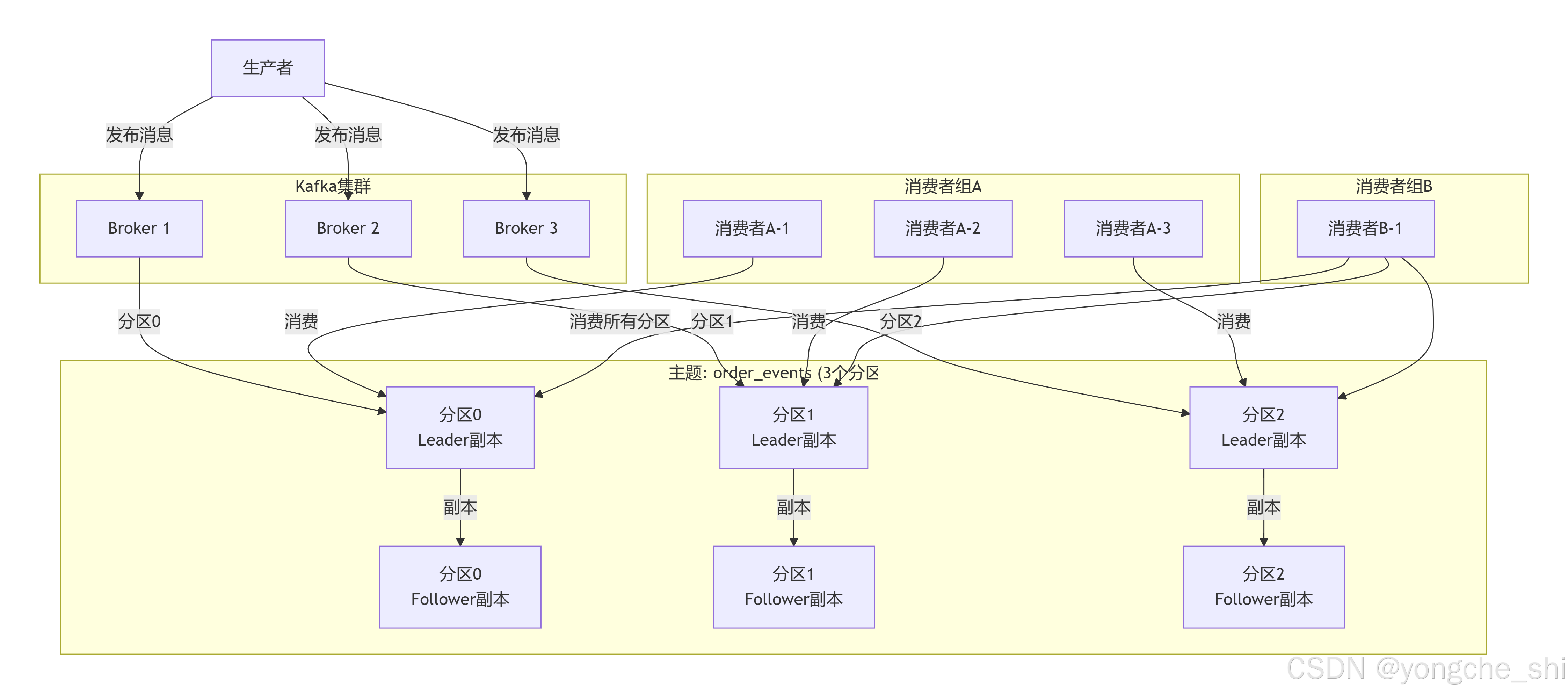
3.2.2 Kafka生产者与消费者
# 生产者配置与发送
from kafka import KafkaProducer
from kafka.errors import KafkaError
import json
def create_kafka_producer():
"""创建Kafka生产者"""
producer = KafkaProducer(
bootstrap_servers=['localhost:9092', 'localhost:9093', 'localhost:9094'],
client_id='order-service-producer',
# 序列化配置
key_serializer=lambda k: k.encode('utf-8') if k else None,
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
# 可靠性配置
acks='all', # 等待所有副本确认
retries=3, # 失败重试次数
max_in_flight_requests_per_connection=1, # 保证分区内消息顺序
# 性能配置
compression_type='snappy', # 压缩算法
batch_size=16384, # 批量发送大小
linger_ms=5, # 批量发送等待时间
# 高级配置
enable_idempotence=True, # 启用幂等生产者
transaction_id='order-service-tx' # 事务ID
)
return producer
def send_order_event(producer, order_data):
"""发送订单事件到Kafka"""
# 根据订单ID选择分区(确保同一订单的消息进入同一分区)
partition_key = str(order_data['user_id'] % 10) # 假设有10个分区
future = producer.send(
topic='order_events',
key=partition_key,
value={
'event_type': 'ORDER_CREATED',
'order_id': order_data['id'],
'user_id': order_data['user_id'],
'total_amount': order_data['amount'],
'items': order_data['items'],
'timestamp': datetime.now().isoformat()
},
headers=[('source', b'order_service'), ('version', b'1.0')]
)
# 异步回调处理
def on_send_success(record_metadata):
print(f"消息发送成功: topic={record_metadata.topic}, "
f"partition={record_metadata.partition}, "
f"offset={record_metadata.offset}")
def on_send_error(exc):
print(f"消息发送失败: {exc}")
# 可以在这里实现重试逻辑
future.add_callback(on_send_success)
future.add_errback(on_send_error)
return future
# 消费者配置与处理
from kafka import KafkaConsumer
from kafka.coordinator.assignors.range import RangePartitionAssignor
from kafka.coordinator.assignors.roundrobin import RoundRobinPartitionAssignor
def create_kafka_consumer(group_id):
"""创建Kafka消费者"""
consumer = KafkaConsumer(
'order_events',
group_id=group_id, # 消费者组ID
bootstrap_servers=['localhost:9092', 'localhost:9093', 'localhost:9094'],
# 反序列化配置
key_deserializer=lambda k: k.decode('utf-8') if k else None,
value_deserializer=lambda v: json.loads(v.decode('utf-8')),
# 消费位置配置
auto_offset_reset='latest', # 如果没有偏移量,从最新开始
enable_auto_commit=False, # 手动提交偏移量
# 会话与心跳配置
session_timeout_ms=30000, # 会话超时时间
heartbeat_interval_ms=3000, # 心跳间隔
# 分区分配策略
partition_assignment_strategy=[
RoundRobinPartitionAssignor, # 轮询分配
RangePartitionAssignor # 范围分配
],
# 消费配置
max_poll_records=500, # 每次拉取最大记录数
max_poll_interval_ms=300000, # 最大拉取间隔(5分钟)
fetch_max_wait_ms=500, # 拉取等待时间
fetch_min_bytes=1, # 最小拉取字节数
fetch_max_bytes=52428800, # 最大拉取字节数(50MB)
)
return consumer
def process_order_events(consumer):
"""处理订单事件"""
try:
while True:
# 拉取消息
message_batch = consumer.poll(timeout_ms=1000, max_records=500)
for topic_partition, messages in message_batch.items():
print(f"处理分区: {topic_partition}")
for message in messages:
try:
# 处理消息
event = message.value
process_single_order(event)
except Exception as e:
print(f"消息处理失败: {e}")
# 可以记录失败,但继续处理其他消息
log_failed_message(message, str(e))
# 提交这个分区的偏移量
consumer.commit({topic_partition: messages[-1].offset + 1})
except KeyboardInterrupt:
print("消费者停止")
finally:
consumer.close()
def process_single_order(event):
"""处理单个订单事件"""
event_type = event['event_type']
if event_type == 'ORDER_CREATED':
print(f"处理订单创建: {event['order_id']}")
# 库存扣减
deduct_inventory(event['items'])
# 其他处理...
elif event_type == 'ORDER_PAID':
print(f"处理订单支付: {event['order_id']}")
# 更新订单状态
update_order_status(event['order_id'], 'PAID')
# 触发物流
trigger_shipping(event['order_id'])
elif event_type == 'ORDER_SHIPPED':
print(f"处理订单发货: {event['order_id']}")
# 发送通知
send_notification(event['user_id'], '您的订单已发货')
3.2.3 Kafka流处理与连接器
# 使用Kafka Streams进行流处理
from kafka import KafkaStreams
def create_order_processing_stream():
"""创建订单处理流应用"""
# 流处理拓扑
builder = KafkaStreamsBuilder()
# 1. 从订单主题创建流
order_stream = builder.stream(
'order_events',
consumed=Consumed.with(Serdes.String(), OrderSerde())
)
# 2. 过滤出已支付的订单
paid_orders = order_stream.filter(
lambda key, order: order.status == 'PAID'
)
# 3. 按用户分组并统计消费金额
user_spending = paid_orders \
.group_by(
lambda key, order: order.user_id, # 按用户ID分组
grouped=Grouped.with(Serdes.String(), OrderSerde())
) \
.aggregate(
lambda: 0.0, # 初始值
lambda user_id, order, total: total + order.amount, # 累加器
materialized=Materialized.as('user-spending-store')
.with_key_serde(Serdes.String())
.with_value_serde(Serdes.Float())
)
# 4. 将结果输出到新主题
user_spending.to_stream() \
.map(lambda key, value: (key, str(value))) \
.to('user_spending_summary',
produced=Produced.with(Serdes.String(), Serdes.String()))
# 构建并启动流应用
streams = KafkaStreams(builder.build(), {
'application.id': 'order-processing-app',
'bootstrap.servers': 'localhost:9092',
'default.key.serde': Serdes.String(),
'default.value.serde': Serdes.String(),
'processing.guarantee': 'exactly_once_v2' # 精确一次语义
})
streams.start()
return streams
# Kafka连接器示例
def setup_debezium_connector():
"""设置Debezium MySQL连接器,捕获数据库变更"""
connector_config = {
"name": "order-db-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "mysql-host",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"database.server.name": "order-db",
"database.include.list": "order_db",
"table.include.list": "order_db.orders,order_db.order_items",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "dbhistory.order",
"include.schema.changes": "true",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false"
}
}
# 通过REST API注册连接器
response = requests.post(
'http://localhost:8083/connectors',
json=connector_config,
headers={'Content-Type': 'application/json'}
)
if response.status_code == 201:
print("连接器创建成功")
else:
print(f"连接器创建失败: {response.text}")
四、进阶设计:生产环境中的消息队列实践
4.1 高可用性与故障恢复
4.1.1 RabbitMQ集群与镜像队列
# RabbitMQ集群配置
def setup_rabbitmq_cluster():
"""配置RabbitMQ高可用集群"""
# 集群节点配置
nodes = [
{'host': 'rabbitmq-node1', 'port': 5672, 'node_name': 'rabbit@node1'},
{'host': 'rabbitmq-node2', 'port': 5672, 'node_name': 'rabbit@node2'},
{'host': 'rabbitmq-node3', 'port': 5672, 'node_name': 'rabbit@node3'}
]
# 创建镜像队列策略
policy = {
'pattern': '^order', # 匹配以order开头的队列
'definition': {
'ha-mode': 'exactly', # 高可用模式
'ha-params': 2, # 副本数量
'ha-sync-mode': 'automatic', # 自动同步
'ha-promote-on-shutdown': 'always', # 关机时提升副本
'ha-promote-on-failure': 'always' # 故障时提升副本
},
'apply-to': 'queues'
}
# 在实际环境中,可以通过RabbitMQ Management API或CLI设置策略
# rabbitmqctl set_policy ha-order "^order" '{"ha-mode":"exactly","ha-params":2}'
# 客户端连接多个节点(故障转移)
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host=nodes[0]['host'],
port=nodes[0]['port'],
connection_attempts=3,
retry_delay=5,
socket_timeout=10
)
)
# 或者使用负载均衡器地址
lb_connection = pika.BlockingConnection(
pika.ConnectionParameters(
host='rabbitmq-lb.example.com',
port=5672,
heartbeat=600,
blocked_connection_timeout=300
)
)
return connection
4.1.2 Kafka多副本与ISR机制
# Kafka主题多副本配置
def create_high_availability_topic(admin_client):
"""创建高可用的Kafka主题"""
topic_config = {
'num_partitions': 6, # 分区数
'replication_factor': 3, # 副本因子
'configs': {
'min.insync.replicas': 2, # 最小同步副本数
'unclean.leader.election.enable': 'false', # 禁用不干净领导者选举
'retention.ms': '604800000', # 保留7天
'segment.bytes': '1073741824', # 段大小1GB
'compression.type': 'snappy', # 压缩类型
'max.message.bytes': '10485760', # 最大消息大小10MB
}
}
# 创建主题
future = admin_client.create_topics([
new_topic(
name='order_events_ha',
num_partitions=topic_config['num_partitions'],
replication_factor=topic_config['replication_factor'],
topic_configs=topic_config['configs']
)
])
# 等待创建完成
for topic, f in future.items():
try:
f.result() # 等待结果
print(f"主题 {topic} 创建成功")
except Exception as e:
print(f"主题 {topic} 创建失败: {e}")
# 监控ISR(In-Sync Replicas)状态
def monitor_isr_health(admin_client):
"""监控分区ISR健康状态"""
# 获取主题描述
topic_description = admin_client.describe_topics(['order_events_ha'])
for topic, description in topic_description.items():
print(f"主题: {topic}")
for partition in description.partitions.values():
isr_count = len(partition.isr) # 同步副本数
replicas_count = len(partition.replicas) # 总副本数
status = "健康"
if isr_count < replicas_count:
status = "警告:有副本不同步"
if isr_count < 2: # 假设min.insync.replicas=2
status = "危险:同步副本不足"
print(f" 分区 {partition.partition}: "
f"Leader={partition.leader}, "
f"ISR={isr_count}/{replicas_count}, "
f"状态={status}")
4.2 消息语义与顺序保证
4.2.1 消息传递语义
# 实现不同消息语义的发送者
class MessageProducer:
"""支持不同消息语义的生产者"""
def __init__(self, broker_type='kafka'):
self.broker_type = broker_type
def send_at_most_once(self, topic, message):
"""最多一次语义:可能丢失消息,但不会重复"""
if self.broker_type == 'kafka':
producer = KafkaProducer(
bootstrap_servers='localhost:9092',
acks=0, # 不等待确认
retries=0 # 不重试
)
else: # RabbitMQ
# 使用非持久化消息,不启用确认
pass
producer.send(topic, message)
def send_at_least_once(self, topic, message, message_id):
"""至少一次语义:可能重复,但不会丢失"""
if self.broker_type == 'kafka':
producer = KafkaProducer(
bootstrap_servers='localhost:9092',
acks='all', # 等待所有副本确认
retries=3,
enable_idempotence=False # 不启用幂等
)
else: # RabbitMQ
# 使用持久化消息和发布者确认
pass
# 需要消费者实现幂等性
future = producer.send(topic, key=message_id, value=message)
future.get(timeout=10) # 等待发送完成
def send_exactly_once(self, topic, message, transaction_id=None):
"""精确一次语义:既不会丢失也不会重复"""
if self.broker_type == 'kafka':
producer = KafkaProducer(
bootstrap_servers='localhost:9092',
acks='all',
retries=3,
enable_idempotence=True, # 启用幂等生产者
transactional_id=transaction_id or 'default-tx'
)
# 开始事务
producer.init_transactions()
producer.begin_transaction()
try:
future = producer.send(topic, value=message)
future.get(timeout=10)
# 提交事务
producer.commit_transaction()
except Exception as e:
producer.abort_transaction()
raise e
else: # RabbitMQ
# RabbitMQ本身不支持事务消息,需结合数据库事务
# 使用事务通道或发布者确认
pass
4.2.2 消息顺序保证
# 保证消息顺序的处理模式
class OrderEventProcessor:
"""保证订单事件顺序处理的消费者"""
def __init__(self, broker_type='kafka'):
self.broker_type = broker_type
self.order_processors = {} # 按订单ID分组处理
def process_with_order_guarantee(self, topic):
"""保证同一订单的消息顺序处理"""
if self.broker_type == 'kafka':
# Kafka:同一分区内消息有序
consumer = KafkaConsumer(
topic,
group_id='order-processor-group',
bootstrap_servers='localhost:9092',
max_poll_records=100,
enable_auto_commit=False
)
# 按订单ID分配分区(生产者需确保同一订单ID进入同一分区)
# 分区内顺序消费自然保证同一订单消息的顺序
for message in consumer:
order_id = self.extract_order_id(message)
# 串行处理同一订单的消息
if order_id in self.order_processors:
# 如果该订单正在处理,等待完成
self.order_processors[order_id].join()
# 创建新线程处理这个订单的消息
processor = threading.Thread(
target=self.process_order_messages,
args=(order_id, [message])
)
self.order_processors[order_id] = processor
processor.start()
# 提交偏移量
consumer.commit()
else: # RabbitMQ
# RabbitMQ:单个队列内消息有序,但多个消费者会破坏顺序
# 解决方案:为每个订单创建独立队列,或使用单个消费者
connection = pika.BlockingConnection(
pika.ConnectionParameters('localhost')
)
channel = connection.channel()
# 使用单个消费者保证顺序
channel.basic_qos(prefetch_count=1) # 一次只处理一个消息
def callback(ch, method, properties, body):
order_id = self.extract_order_id_from_body(body)
self.process_single_order(order_id, body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(
queue='order_events',
on_message_callback=callback
)
channel.start_consuming()
def extract_order_id(self, message):
"""从消息中提取订单ID"""
if self.broker_type == 'kafka':
return message.key.decode('utf-8')
else:
data = json.loads(message.value.decode('utf-8'))
return data.get('order_id')
4.3 监控、告警与运维
4.3.1 关键监控指标
# 消息队列监控指标收集
class MessageQueueMonitor:
"""消息队列监控类"""
def __init__(self, broker_type='kafka'):
self.broker_type = broker_type
self.metrics = {}
def collect_metrics(self):
"""收集关键监控指标"""
if self.broker_type == 'kafka':
return self.collect_kafka_metrics()
else:
return self.collect_rabbitmq_metrics()
def collect_kafka_metrics(self):
"""收集Kafka监控指标"""
metrics = {
'吞吐量': {
'messages_in_per_sec': self.get_messages_in_rate(),
'bytes_in_per_sec': self.get_bytes_in_rate(),
'bytes_out_per_sec': self.get_bytes_out_rate(),
},
'延迟': {
'request_queue_time_ms': self.get_request_queue_time(),
'local_time_ms': self.get_local_time(),
'response_queue_time_ms': self.get_response_queue_time(),
'response_send_time_ms': self.get_response_send_time(),
'total_time_ms': self.get_total_request_time(),
},
'消费者滞后': {
'consumer_lag': self.get_consumer_lag(),
'records_lag_max': self.get_max_records_lag(),
},
'副本状态': {
'under_replicated_partitions': self.get_under_replicated_count(),
'isr_shrinks_per_sec': self.get_isr_shrink_rate(),
'isr_expands_per_sec': self.get_isr_expand_rate(),
},
'请求处理': {
'produce_requests_per_sec': self.get_produce_request_rate(),
'fetch_requests_per_sec': self.get_fetch_request_rate(),
}
}
# 添加分区级别指标
metrics['partitions'] = self.get_partition_metrics()
return metrics
def collect_rabbitmq_metrics(self):
"""收集RabbitMQ监控指标"""
import requests
# 通过Management API获取指标
response = requests.get(
'http://localhost:15672/api/overview',
auth=('guest', 'guest')
)
overview = response.json()
metrics = {
'队列状态': {
'total_queues': overview.get('object_totals', {}).get('queues', 0),
'total_messages': overview.get('queue_totals', {}).get('messages', 0),
'messages_ready': overview.get('queue_totals', {}).get('messages_ready', 0),
'messages_unacked': overview.get('queue_totals', {}).get('messages_unacknowledged', 0),
},
'消息速率': {
'publish_details': overview.get('message_stats', {}).get('publish_details', {}).get('rate', 0),
'ack_details': overview.get('message_stats', {}).get('ack_details', {}).get('rate', 0),
'deliver_get_details': overview.get('message_stats', {}).get('deliver_get_details', {}).get('rate', 0),
'redelivered_details': overview.get('message_stats', {}).get('redelivered_details', {}).get('rate', 0),
},
'节点状态': [],
'连接状态': {
'total_connections': overview.get('object_totals', {}).get('connections', 0),
'total_channels': overview.get('object_totals', {}).get('channels', 0),
}
}
# 获取节点详情
nodes_response = requests.get(
'http://localhost:15672/api/nodes',
auth=('guest', 'guest')
)
metrics['节点状态'] = nodes_response.json()
return metrics
def setup_alerts(self):
"""设置告警规则"""
alerts = [
{
'name': '高消费者滞后',
'condition': 'consumer_lag > 10000',
'severity': 'warning',
'action': 'notify_slack:#alerts'
},
{
'name': '队列消息积压',
'condition': 'messages_ready > 50000',
'severity': 'critical',
'action': 'scale_consumers +2'
},
{
'name': '副本不同步',
'condition': 'under_replicated_partitions > 0',
'severity': 'critical',
'action': 'notify_pagerduty'
},
{
'name': '高请求延迟',
'condition': 'total_time_ms > 1000',
'severity': 'warning',
'action': 'notify_email:team@example.com'
}
]
return alerts
4.3.2 容量规划与性能调优
# 容量规划与性能优化
class QueueCapacityPlanner:
"""消息队列容量规划器"""
def calculate_requirements(self, business_metrics):
"""
根据业务指标计算消息队列需求
Args:
business_metrics: {
'peak_requests_per_second': 10000,
'average_message_size_bytes': 1024,
'retention_days': 7,
'replication_factor': 3,
'availability_target': 0.999 # 99.9%
}
"""
peak_rps = business_metrics['peak_requests_per_second']
avg_msg_size = business_metrics['average_message_size_bytes']
retention_days = business_metrics['retention_days']
replication = business_metrics['replication_factor']
# 计算存储需求
daily_messages = peak_rps * 3600 * 24 # 每日消息数(按峰值估算)
daily_storage = daily_messages * avg_msg_size * replication # 每日存储(含副本)
total_storage = daily_storage * retention_days # 总存储需求
# 计算吞吐需求
peak_throughput = peak_rps * avg_msg_size # 峰值吞吐量(字节/秒)
# 计算分区/队列数量(经验法则)
partitions_needed = max(3, peak_rps // 1000) # 每分区约1000 QPS
requirements = {
'storage': {
'daily_gb': daily_storage / (1024**3),
'total_gb': total_storage / (1024**3),
'retention_days': retention_days
},
'throughput': {
'peak_messages_per_second': peak_rps,
'peak_bytes_per_second': peak_throughput,
'average_bytes_per_second': peak_throughput * 0.3 # 假设平均是峰值的30%
},
'scaling': {
'partitions_or_queues': partitions_needed,
'consumers_needed': partitions_needed * 2, # 每个分区2个消费者用于容灾
'replication_factor': replication
},
'hardware_recommendation': self.get_hardware_recommendation(
peak_rps, total_storage
)
}
return requirements
def get_hardware_recommendation(self, peak_rps, total_storage_gb):
"""获取硬件推荐配置"""
if peak_rps < 1000:
return {
'node_count': 3,
'cpu_per_node': 4,
'memory_gb_per_node': 16,
'disk_type': 'SSD',
'disk_gb_per_node': max(100, total_storage_gb // 3 * 2) # 留50%余量
}
elif peak_rps < 10000:
return {
'node_count': 5,
'cpu_per_node': 8,
'memory_gb_per_node': 32,
'disk_type': 'NVMe SSD',
'disk_gb_per_node': max(500, total_storage_gb // 5 * 2)
}
else:
return {
'node_count': 7,
'cpu_per_node': 16,
'memory_gb_per_node': 64,
'disk_type': 'NVMe SSD',
'disk_gb_per_node': max(1000, total_storage_gb // 7 * 2)
}
def performance_tuning_guide(self, broker_type):
"""性能调优指南"""
if broker_type == 'kafka':
return {
'producer_tuning': {
'batch.size': '增大批量大小(如 16384-65536)',
'linger.ms': '适当增加等待时间(如 5-100ms)',
'compression.type': '使用 snappy 或 lz4 压缩',
'buffer.memory': '增加缓冲区内存(如 33554432)',
'max.in.flight.requests.per.connection': '设为1以保证顺序',
},
'consumer_tuning': {
'fetch.min.bytes': '增大最小拉取字节数',
'fetch.max.wait.ms': '增加最大等待时间',
'max.partition.fetch.bytes': '增加分区拉取字节数',
'session.timeout.ms': '适当增加会话超时',
},
'broker_tuning': {
'num.io.threads': 'CPU核心数的2-3倍',
'num.network.threads': 'CPU核心数的3倍',
'log.flush.interval.messages': '10000',
'log.flush.interval.ms': '1000',
'num.replica.fetchers': '3-5',
}
}
else: # RabbitMQ
return {
'channel_tuning': {
'prefetch_count': '根据消费者能力设置(如 10-100)',
'global_qos': '谨慎使用全局QoS',
},
'queue_tuning': {
'x-max-length': '设置队列最大长度',
'x-message-ttl': '设置消息TTL',
'x-overflow': 'reject-publish 或 drop-head',
'lazy_queue': '对大量消息启用惰性队列',
},
'vm_tuning': {
'vm_memory_high_watermark': '0.6-0.7',
'vm_memory_high_watermark_paging_ratio': '0.5',
'disk_free_limit': '至少保留2GB或1%空间',
}
}
五、实战:电商系统消息队列架构设计
5.1 整体架构设计
让我们设计一个完整的电商系统消息队列架构,处理从用户下单到订单完成的整个流程:
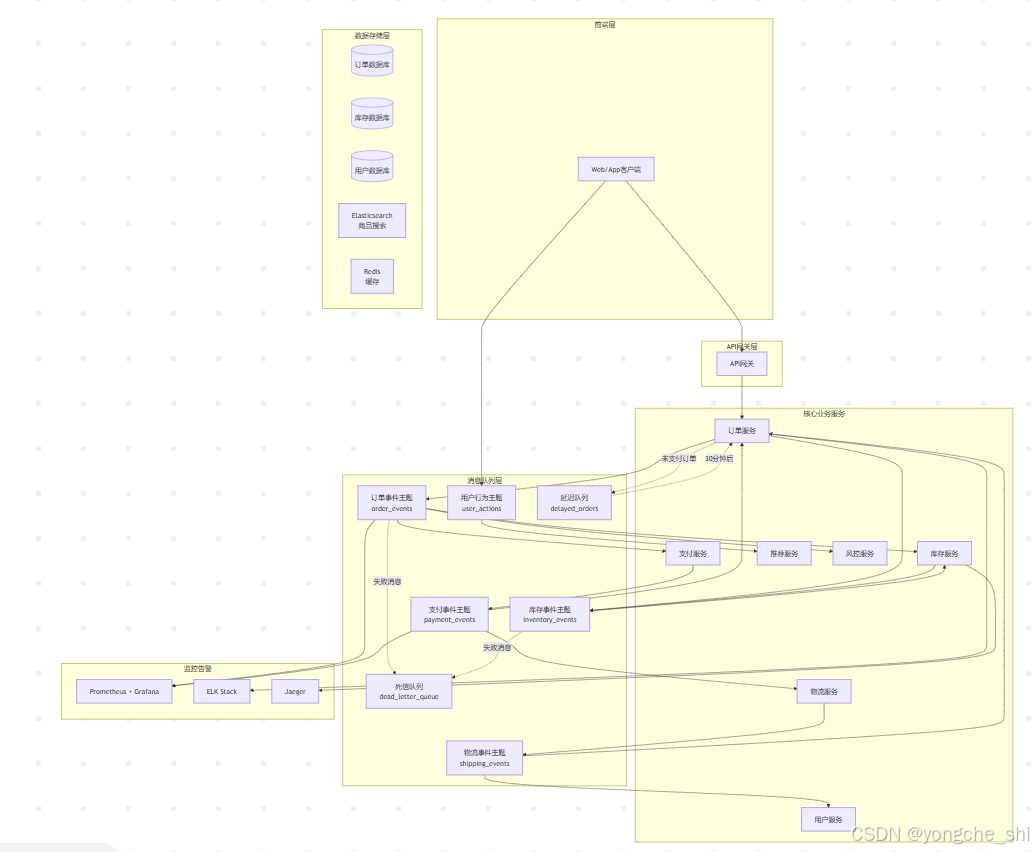
5.2 核心业务流程实现
5.2.1 订单创建流程
# order_service.py
class OrderService:
"""订单服务 - 处理订单创建全流程"""
def __init__(self):
self.kafka_producer = create_kafka_producer()
self.rabbitmq_channel = create_rabbitmq_channel()
self.db_session = create_db_session()
def create_order(self, user_id, items, shipping_address):
"""
创建订单 - 完整流程
1. 验证数据
2. 创建订单记录
3. 发送库存锁定事件
4. 发送订单创建事件
5. 返回订单ID
"""
# 1. 验证输入数据
self.validate_order_data(user_id, items, shipping_address)
# 2. 数据库事务中创建订单
with self.db_session.begin():
# 创建订单记录
order = Order(
user_id=user_id,
status='CREATED',
total_amount=self.calculate_total(items),
shipping_address=json.dumps(shipping_address)
)
self.db_session.add(order)
self.db_session.flush() # 获取order.id
# 创建订单项
for item in items:
order_item = OrderItem(
order_id=order.id,
product_id=item['product_id'],
quantity=item['quantity'],
price=item['price']
)
self.db_session.add(order_item)
# 3. 发送库存锁定事件(Kafka - 高吞吐)
inventory_event = {
'event_type': 'INVENTORY_LOCK_REQUEST',
'order_id': order.id,
'items': items,
'timestamp': datetime.now().isoformat()
}
self.kafka_producer.send(
'inventory_events',
key=str(order.id),
value=inventory_event
)
# 4. 发送订单创建事件(RabbitMQ - 可靠传递)
order_event = {
'event_type': 'ORDER_CREATED',
'order_id': order.id,
'user_id': user_id,
'total_amount': order.total_amount,
'timestamp': datetime.now().isoformat()
}
self.rabbitmq_channel.basic_publish(
exchange='order_exchange',
routing_key='order.created',
body=json.dumps(order_event),
properties=pika.BasicProperties(
delivery_mode=2,
content_type='application/json',
headers={'order_id': str(order.id)}
)
)
# 5. 发送延迟消息:30分钟后检查支付状态
self.send_delayed_payment_check(order.id, delay_minutes=30)
# 6. 发送用户行为事件(用于推荐系统)
user_action_event = {
'user_id': user_id,
'action': 'create_order',
'order_id': order.id,
'items': items,
'timestamp': datetime.now().isoformat()
}
self.kafka_producer.send(
'user_actions',
key=str(user_id),
value=user_action_event
)
return {
'order_id': order.id,
'status': 'processing',
'message': '订单已创建,正在处理中'
}
def send_delayed_payment_check(self, order_id, delay_minutes):
"""发送延迟消息检查支付状态"""
check_time = datetime.now() + timedelta(minutes=delay_minutes)
# RabbitMQ延迟队列
self.rabbitmq_channel.basic_publish(
exchange='delayed_exchange',
routing_key='payment.check',
body=json.dumps({
'order_id': order_id,
'check_time': check_time.isoformat()
}),
properties=pika.BasicProperties(
headers={'x-delay': delay_minutes * 60 * 1000}
)
)
def process_delayed_payment_check(self, order_id):
"""处理延迟支付检查"""
order = self.db_session.query(Order).get(order_id)
if order and order.status == 'CREATED':
# 订单创建30分钟后仍未支付,取消订单
order.status = 'CANCELLED'
order.cancellation_reason = 'payment_timeout'
self.db_session.commit()
# 发送订单取消事件,释放库存
self.kafka_producer.send(
'order_events',
key=str(order_id),
value={
'event_type': 'ORDER_CANCELLED',
'order_id': order_id,
'reason': 'payment_timeout',
'timestamp': datetime.now().isoformat()
}
)
5.2.2 库存服务实现
# inventory_service.py
class InventoryService:
"""库存服务 - 处理库存扣减与恢复"""
def __init__(self):
self.kafka_consumer = create_kafka_consumer('inventory-group')
self.db_session = create_db_session()
self.redis_client = create_redis_client()
def start_inventory_processor(self):
"""启动库存事件处理器"""
# 订阅库存事件主题
self.kafka_consumer.subscribe(['inventory_events', 'order_events'])
# 创建死信队列处理器
dead_letter_processor = threading.Thread(
target=self.process_dead_letter_messages
)
dead_letter_processor.start()
# 主处理循环
while True:
try:
# 拉取消息
records = self.kafka_consumer.poll(timeout_ms=1000)
for topic_partition, messages in records.items():
# 按订单ID分组处理(保证同一订单的顺序)
messages_by_order = self.group_messages_by_order(messages)
for order_id, order_messages in messages_by_order.items():
# 顺序处理同一订单的所有消息
self.process_order_messages(order_id, order_messages)
# 提交偏移量
last_offset = order_messages[-1].offset
self.kafka_consumer.commit({
topic_partition: last_offset + 1
})
except Exception as e:
print(f"库存处理异常: {e}")
self.handle_processing_error(e)
def process_order_messages(self, order_id, messages):
"""处理同一订单的所有消息"""
for message in messages:
event = json.loads(message.value.decode('utf-8'))
event_type = event['event_type']
try:
if event_type == 'INVENTORY_LOCK_REQUEST':
self.lock_inventory(
order_id,
event['items'],
message.offset
)
elif event_type == 'ORDER_CANCELLED':
self.release_inventory(
order_id,
event.get('reason')
)
elif event_type == 'ORDER_PAID':
self.confirm_inventory_deduction(order_id)
except InventoryException as e:
# 库存相关异常,记录并发送到死信队列
self.send_to_dead_letter(message, str(e))
except Exception as e:
# 其他异常,重试或记录
self.handle_unexpected_error(message, e)
def lock_inventory(self, order_id, items, message_offset):
"""锁定库存(预扣减)"""
# 使用Redis分布式锁
lock_key = f"inventory_lock:{order_id}"
with self.redis_client.lock(lock_key, timeout=10):
# 检查库存是否已处理(避免重复处理)
processed_key = f"inventory_processed:{order_id}:{message_offset}"
if self.redis_client.get(processed_key):
print(f"订单 {order_id} 的库存已处理,跳过")
return
# 数据库事务中锁定库存
with self.db_session.begin():
for item in items:
product_id = item['product_id']
quantity = item['quantity']
# 查询当前库存
inventory = self.db_session.query(Inventory).filter_by(
product_id=product_id
).with_for_update().first() # 行级锁
if not inventory:
raise InventoryException(f"产品 {product_id} 不存在")
if inventory.available < quantity:
raise InventoryException(
f"产品 {product_id} 库存不足,"
f"需求: {quantity}, 可用: {inventory.available}"
)
# 锁定库存
inventory.available -= quantity
inventory.locked += quantity
# 记录库存变更历史
history = InventoryHistory(
product_id=product_id,
order_id=order_id,
change_type='LOCK',
quantity=quantity,
previous_available=inventory.available + quantity,
new_available=inventory.available,
timestamp=datetime.now()
)
self.db_session.add(history)
# 标记为已处理
self.redis_client.setex(processed_key, 3600, '1')
print(f"订单 {order_id} 库存锁定成功")
# 发送库存锁定成功事件
self.send_inventory_locked_event(order_id)
def send_inventory_locked_event(self, order_id):
"""发送库存锁定成功事件"""
producer = create_kafka_producer()
producer.send('inventory_events', key=str(order_id), value={
'event_type': 'INVENTORY_LOCKED',
'order_id': order_id,
'timestamp': datetime.now().isoformat()
})
producer.flush()
5.2.3 支付服务实现
# payment_service.py
class PaymentService:
"""支付服务 - 处理支付与退款"""
def __init__(self):
self.rabbitmq_connection = create_rabbitmq_connection()
self.channel = self.rabbitmq_connection.channel()
self.setup_queues()
def setup_queues(self):
"""设置支付相关队列"""
# 支付请求队列
self.channel.queue_declare(
queue='payment_requests',
durable=True,
arguments={
'x-dead-letter-exchange': 'dlx_exchange',
'x-dead-letter-routing-key': 'payment_dead_letter'
}
)
# 支付结果队列
self.channel.queue_declare(
queue='payment_results',
durable=True
)
# 退款队列
self.channel.queue_declare(
queue='refund_requests',
durable=True
)
# 设置QoS
self.channel.basic_qos(prefetch_count=5)
def start_payment_processor(self):
"""启动支付处理器"""
# 支付请求消费者
self.channel.basic_consume(
queue='payment_requests',
on_message_callback=self.process_payment_request,
auto_ack=False
)
# 退款请求消费者
self.channel.basic_consume(
queue='refund_requests',
on_message_callback=self.process_refund_request,
auto_ack=False
)
print("支付服务已启动,等待消息...")
self.channel.start_consuming()
def process_payment_request(self, ch, method, properties, body):
"""处理支付请求"""
try:
request = json.loads(body.decode('utf-8'))
order_id = request['order_id']
amount = request['amount']
payment_method = request['payment_method']
print(f"处理订单 {order_id} 的支付请求,金额: {amount}")
# 调用支付网关
payment_result = self.call_payment_gateway(
order_id, amount, payment_method
)
if payment_result['success']:
# 支付成功
self.handle_payment_success(order_id, payment_result)
ch.basic_ack(delivery_tag=method.delivery_tag)
# 发送支付成功事件
self.send_payment_event(
order_id,
'PAID',
payment_result['transaction_id']
)
else:
# 支付失败
self.handle_payment_failure(order_id, payment_result)
# 根据错误类型决定是否重试
if payment_result.get('retryable', False):
# 可重试错误,重新入队
ch.basic_nack(
delivery_tag=method.delivery_tag,
requeue=True
)
else:
# 不可重试错误,确认消息并记录
ch.basic_ack(delivery_tag=method.delivery_tag)
self.send_to_dead_letter(body, properties, payment_result['error'])
except Exception as e:
print(f"支付处理异常: {e}")
# 记录异常,消息重新入队(最多重试3次)
retry_count = properties.headers.get('retry_count', 0)
if retry_count < 3:
# 增加重试计数并重新入队
properties.headers['retry_count'] = retry_count + 1
ch.basic_publish(
exchange='',
routing_key='payment_requests',
body=body,
properties=properties
)
ch.basic_ack(delivery_tag=method.delivery_tag)
else:
# 超过重试次数,转入死信队列
ch.basic_nack(
delivery_tag=method.delivery_tag,
requeue=False
)
def send_payment_event(self, order_id, status, transaction_id=None):
"""发送支付事件"""
event = {
'event_type': f'ORDER_{status}',
'order_id': order_id,
'status': status,
'transaction_id': transaction_id,
'timestamp': datetime.now().isoformat()
}
# 使用Kafka发送支付事件(高吞吐,多个消费者)
producer = create_kafka_producer()
producer.send('order_events', key=str(order_id), value=event)
producer.flush()
5.3 监控与告警实现
# monitoring_service.py
class MessageQueueMonitor:
"""消息队列监控服务"""
def __init__(self):
self.prometheus_client = PrometheusClient()
self.alert_manager = AlertManager()
self.dashboards = {}
def collect_and_report_metrics(self):
"""收集并报告监控指标"""
metrics = {
'kafka': self.collect_kafka_metrics(),
'rabbitmq': self.collect_rabbitmq_metrics(),
'application': self.collect_application_metrics(),
'business': self.collect_business_metrics()
}
# 报告到Prometheus
self.report_to_prometheus(metrics)
# 检查告警条件
alerts = self.check_alerts(metrics)
# 触发告警
if alerts:
self.trigger_alerts(alerts)
# 更新Grafana仪表盘
self.update_dashboards(metrics)
return metrics
def collect_business_metrics(self):
"""收集业务指标"""
# 订单处理指标
order_metrics = {
'orders_created_total': self.get_total_orders_created(),
'orders_paid_total': self.get_total_orders_paid(),
'orders_cancelled_total': self.get_total_orders_cancelled(),
'order_creation_rate': self.get_order_creation_rate(),
'order_payment_success_rate': self.get_payment_success_rate(),
'average_order_value': self.get_average_order_value(),
'inventory_lock_success_rate': self.get_inventory_lock_success_rate(),
}
# 队列积压指标
backlog_metrics = {
'payment_queue_backlog': self.get_queue_length('payment_requests'),
'inventory_queue_backlog': self.get_consumer_lag('inventory_events'),
'order_events_backlog': self.get_consumer_lag('order_events'),
'dead_letter_queue_size': self.get_queue_length('dead_letter_queue'),
}
# 延迟指标
latency_metrics = {
'order_to_payment_latency_p95': self.get_latency_percentile(
'ORDER_CREATED', 'ORDER_PAID', 95
),
'payment_to_shipping_latency_p95': self.get_latency_percentile(
'ORDER_PAID', 'ORDER_SHIPPED', 95
),
'inventory_lock_latency_avg': self.get_average_latency(
'INVENTORY_LOCK_REQUEST', 'INVENTORY_LOCKED'
),
}
# 错误指标
error_metrics = {
'payment_failure_rate': self.get_payment_failure_rate(),
'inventory_lock_failure_rate': self.get_inventory_lock_failure_rate(),
'dead_letter_rate': self.get_dead_letter_rate(),
'message_processing_error_rate': self.get_message_processing_error_rate(),
}
return {
'orders': order_metrics,
'backlog': backlog_metrics,
'latency': latency_metrics,
'errors': error_metrics
}
def check_alerts(self, metrics):
"""检查告警条件"""
alerts = []
# 业务告警
if metrics['business']['orders']['order_creation_rate'] < 10:
alerts.append({
'name': '低订单创建率',
'severity': 'warning',
'value': metrics['business']['orders']['order_creation_rate'],
'threshold': 10,
'description': '订单创建率低于阈值'
})
if metrics['business']['errors']['payment_failure_rate'] > 0.05:
alerts.append({
'name': '高支付失败率',
'severity': 'critical',
'value': metrics['business']['errors']['payment_failure_rate'],
'threshold': 0.05,
'description': '支付失败率超过5%'
})
# 积压告警
if metrics['business']['backlog']['payment_queue_backlog'] > 1000:
alerts.append({
'name': '支付队列积压',
'severity': 'warning',
'value': metrics['business']['backlog']['payment_queue_backlog'],
'threshold': 1000,
'description': '支付队列积压超过1000'
})
# 延迟告警
if metrics['business']['latency']['order_to_payment_latency_p95'] > 300000:
alerts.append({
'name': '高订单支付延迟',
'severity': 'warning',
'value': metrics['business']['latency']['order_to_payment_latency_p95'],
'threshold': 300000,
'description': '95%订单支付延迟超过5分钟'
})
return alerts
def trigger_alerts(self, alerts):
"""触发告警"""
for alert in alerts:
# 发送到Alertmanager
self.alert_manager.send_alert(alert)
# 根据严重程度采取不同行动
if alert['severity'] == 'critical':
# 紧急告警:电话、短信、PagerDuty
self.send_urgent_notification(alert)
# 自动扩缩容
if 'payment_queue_backlog' in alert['name']:
self.scale_payment_processors(2)
elif alert['severity'] == 'warning':
# 警告:邮件、Slack
self.send_warning_notification(alert)
# 记录告警到数据库
self.log_alert(alert)
def scale_payment_processors(self, increment):
"""扩缩容支付处理器"""
current_count = self.get_current_pod_count('payment-service')
new_count = current_count + increment
# 调用Kubernetes API扩缩容
self.kubernetes_client.scale_deployment(
'payment-service',
new_count
)
print(f"支付服务从 {current_count} 扩缩到 {new_count} 个实例")
# 记录扩缩容事件
self.log_scaling_event('payment-service', current_count, new_count)
六、总结与面试准备
6.1 核心知识复盘
通过本文的系统学习,我们建立了完整的消息队列知识体系:
-
三大核心价值:深入理解了消息队列在解耦、异步、削峰方面的核心价值,以及它们如何改变系统架构设计。
-
技术选型:掌握了RabbitMQ和Kafka的设计哲学、适用场景和核心区别,能够根据业务需求做出合理的技术选型。
-
核心机制:
-
RabbitMQ的Exchange-Queue模型、四种交换机类型、消息确认机制
-
Kafka的分区-副本机制、消费者组、ISR集合、高效存储设计
-
-
生产实践:
-
高可用性设计:集群、镜像队列、多副本、故障转移
-
消息语义保证:最多一次、至少一次、精确一次
-
顺序性保证:分区键设计、单消费者模式、顺序处理逻辑
-
-
高级特性:
-
死信队列与延迟消息
-
事务消息与幂等性
-
流处理与连接器
-
监控告警与容量规划
-
-
实战经验:通过完整的电商系统案例,掌握了消息队列在真实业务场景中的架构设计、实现细节和运维实践。
6.2 高频面试题深度剖析
Q1:RabbitMQ和Kafka的主要区别是什么?如何选择?
参考答案:
RabbitMQ和Kafka虽然都是消息队列,但设计目标和适用场景有本质区别:
-
设计哲学:
-
RabbitMQ是企业级消息代理,注重消息的可靠传递、灵活路由和复杂的企业集成场景
-
Kafka是分布式流处理平台,注重高吞吐、持久化存储和实时流处理
-
-
数据模型:
-
RabbitMQ:基于队列,消息被消费后删除(除非持久化)
-
Kafka:基于日志,消息持久化存储,可重复消费,支持多订阅者
-
-
吞吐量与延迟:
-
RabbitMQ:万级到十万级QPS,毫秒级延迟
-
Kafka:十万级到百万级QPS,更高的吞吐但可能有毫秒到秒级延迟
-
-
典型应用场景:
# RabbitMQ适用场景
rabbitmq_scenarios = {
'任务分发': '将任务分发给多个工作者,如邮件发送、图像处理',
'RPC调用': '实现异步RPC,如远程服务调用',
'复杂路由': '需要根据多种条件路由消息的场景',
'企业集成': '需要支持多种协议(AMQP、MQTT、STOMP)的集成',
}
# Kafka适用场景
kafka_scenarios = {
'活动流处理': '用户行为追踪、点击流分析',
'日志聚合': '收集分布式系统日志,集中处理',
'流处理': '实时数据处理、复杂事件处理',
'事件溯源': '存储所有状态变更事件,支持回放',
}
-
选择建议:
-
选择RabbitMQ:需要复杂路由、企业集成、任务队列、相对较低吞吐但需要低延迟的场景
-
选择Kafka:需要高吞吐、日志收集、流处理、事件溯源、消息重放的场景
-
混合使用:大型系统通常会同时使用两者,用Kafka处理高吞吐数据流,用RabbitMQ处理业务消息
-
Q2:如何保证消息队列的高可用性?
参考答案:
保证消息队列高可用需要多层次策略:
- RabbitMQ高可用方案:
rabbitmq_ha = {
'集群部署': '多节点组成集群,共享元数据',
'镜像队列': '队列内容在多个节点间镜像',
'负载均衡': '使用HAProxy或负载均衡器分发连接',
'持久化': '消息和队列持久化到磁盘',
'网络分区处理': '配置适当的网络分区恢复策略',
}
- Kafka高可用方案:
kafka_ha = {
'多副本机制': '每个分区有多个副本(通常3个)',
'ISR集合': '维护同步副本集合,确保数据一致性',
'控制器选举': '自动选举控制器节点管理分区和副本',
'机架感知': '副本分布在不同的机架,防止机架故障',
'监控与自愈': '监控Broker状态,自动故障转移',
}
-
客户端高可用:
-
连接多个服务器地址,自动故障转移
-
实现重试机制和断路器模式
-
消费者偏移量管理,避免重复消费或消息丢失
-
-
数据备份与恢复:
-
定期备份元数据和消息数据
-
测试灾难恢复流程
-
监控磁盘使用,设置清理策略
-
Q3:如何避免消息重复消费?如何实现幂等性?
参考答案:
消息重复是分布式系统中的常见问题,解决方案包括:
- 消息去重策略:
class MessageDeduplicator:
"""消息去重器"""
def __init__(self, storage_backend='redis'):
self.storage = self.create_storage_backend(storage_backend)
self.expire_time = 86400 # 24小时过期
def is_duplicate(self, message_id):
"""检查消息是否重复"""
key = f"message:{message_id}"
if self.storage.exists(key):
return True
# 记录消息ID,设置过期时间
self.storage.setex(key, self.expire_time, 'processed')
return False
def create_storage_backend(self, backend_type):
if backend_type == 'redis':
return redis.Redis(host='localhost', port=6379)
elif backend_type == 'database':
return DatabaseStorage()
- 幂等性设计模式:
class IdempotentOrderProcessor:
"""幂等的订单处理器"""
def process_order_payment(self, payment_message):
# 提取唯一标识
message_id = payment_message['message_id']
order_id = payment_message['order_id']
# 检查是否已处理
if self.is_payment_processed(order_id, message_id):
print(f"订单 {order_id} 支付已处理,跳过")
return
# 使用数据库事务保证原子性
with self.db_session.begin():
# 检查订单当前状态
order = self.db_session.query(Order).get(order_id)
# 只有状态为CREATED时才处理支付
if order.status == 'CREATED':
# 更新订单状态
order.status = 'PAID'
order.payment_time = datetime.now()
order.payment_transaction_id = payment_message['transaction_id']
# 记录处理历史
self.record_processing_history(order_id, message_id)
print(f"订单 {order_id} 支付处理完成")
else:
print(f"订单 {order_id} 状态为 {order.status},跳过支付处理")
-
实现层面建议:
-
在消息中包含唯一ID(如UUID)
-
消费者在处理前检查消息是否已处理
-
使用数据库唯一约束或乐观锁
-
对于金融等敏感操作,记录详细的操作日志支持对账
-
Q4:Kafka为什么能做到高吞吐?
参考答案:
Kafka的高吞吐源于其精心设计的架构:
- 顺序磁盘I/O:
# Kafka的磁盘写入优化
kafka_io_optimizations = {
'顺序写入': '日志文件只追加写入,避免磁盘随机寻址',
'页缓存': '利用操作系统页缓存,减少磁盘直接读写',
'零拷贝': '使用sendfile系统调用,减少内核态到用户态的数据拷贝',
'批量处理': '生产者批量发送,消费者批量拉取',
}
-
高效的数据结构:
-
分区日志结构,支持快速顺序读写
-
偏移量索引,支持快速定位消息
-
时间戳索引,支持按时间范围查找
-
-
生产者优化:
-
批量发送(batch.size, linger.ms)
-
压缩(snappy, lz4, gzip)
-
异步发送,生产者和Broker解耦
-
-
消费者优化:
-
基于拉取的模式,消费者控制消费速率
-
批量拉取,减少网络往返
-
消费者组,并行消费不同分区
-
-
Broker优化:
-
多分区并行处理
-
高效的网络模型(Reactor模式)
-
智能的副本同步机制
-
6.3 面试Checklist
在消息队列相关面试前,确保你能清晰阐述:
-
核心价值:能详细解释消息队列在解耦、异步、削峰方面的作用
-
技术选型:能对比RabbitMQ和Kafka的差异,并根据场景做出选择
-
架构设计:能设计高可用的消息队列架构,包括集群、副本、负载均衡
-
消息语义:理解最多一次、至少一次、精确一次的含义和实现方式
-
顺序保证:知道如何保证消息顺序,以及何时需要顺序保证
-
幂等性:能实现幂等消费,避免重复处理
-
故障处理:了解消息队列的常见故障及应对策略
-
监控运维:知道如何监控消息队列,设置合理的告警
-
性能优化:了解消息队列的性能调优方法
-
实战经验:如有,能描述真实项目中消息队列的应用场景和挑战
掌握消息队列技术不仅意味着学会使用RabbitMQ或Kafka这两个工具,更代表着你理解了现代分布式系统设计的核心思想。在微服务、事件驱动架构日益普及的今天,消息队列已成为连接服务、传递事件、保证系统弹性的关键组件。无论是面试还是实际工作中,对消息队列的深入理解都将为你打开通往高级架构师的大门。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











