







 本文介绍了一种基于Flask的应用程序中管理博客文章的方法,包括数据库模型的设计、表单处理流程、用户权限验证及文章分页显示等功能。通过创建User和Post模型,实现了文章的提交、展示和分页导航,提高了用户体验。
本文介绍了一种基于Flask的应用程序中管理博客文章的方法,包括数据库模型的设计、表单处理流程、用户权限验证及文章分页显示等功能。通过创建User和Post模型,实现了文章的提交、展示和分页导航,提高了用户体验。
提交和显示博客文章
为支持博客文章,我们需要创建一个新的数据库模型,如下所示:
# app/models.py
class User(UserMixin, db.Model):
# ...
posts = db.relationship('post', backref='author', lazy='dynamic')
class Post(db.Model):
__tablename__ = 'posts'
id = db.Column(db.Integer, primary_key=True)
body = db.Column(db.Text)
timestamp = db.Column(db.DateTime, index=True, default=datetime.utcnow)
author_id = db.Column(db.Integer, db.ForeignKey('users.id'))
博客文章包含正文,时间戳以及和User模型之间的一对多关系,body字段的定义类型是db.Text,所以不限制长度
在程序的首页要显示一个表单,以便让用户写博客,这个表单很简单,只包括一个多行文本输入框,用于输入博客文章的内容,另外还有一个提交按钮,表单定义如下:
# app/main/forms.py
class PostForm(Form):
body = TextAreaField("What's on your mind?, validators=[Required()]")
submit = SubmitField('Submit')
index()视图函数处理这个表单并把以前发布的博客文章列表传给模板,如下:
@main.route('/', methods=['GET', 'POST'])
def index():
form = PostForm()
if current_user.can(Permission.WRITE_ARTICLES) and \
form.validators_on_submit():
post = Post(body=form.body.data,
author=current_user._get_current_object())
db.session.add(post)
return redirect(url_for('.index'))
posts = Post.query.order_by(Post.timestamp.desc()).all()
return render_template('index.html', form=form, posts=posts)
这个视图函数把表单和完整的博客文章列表传给模板,文章列表按照时间戳进行降序排列, 博客文章表单采取惯常处理方式,如果提交的数据能通过验证就创建一个新Post实例,在发布新文章之前,要检查当前用户是否有写文章的权限
需要一提的是,新文章对象的author属性值为表达式current_user._get_current_object(),变量current_user由flask-login提供,和所有上下文变量一样,也是通过线程内的代理对象实现,但实际上却是一个轻度包装,包含真正的用户对象,数据库需要真正的用户对象,因此要调用_get_current_object()方法
这个表单显示在index.html模板中欢迎消息的下方,其后是博客文章列表,在这个博客文章列表中,我们首次尝试创建博客文章的时间轴,按照时间顺序由新到旧列出了数据库中所有的博客文章,对模板所做的改动如下:
# app/templates/index.html
#...
<ul class='posts'>
{% for post in posts %}
<li class = 'post'>
<div class='post-thumbnail'>
<a href="{{ url_for('.user', username=post.author.username) }}">
<img class='img-rounded profile-thumbnail' src="{{ post.author.gravatar(size=40) }}"></a>
</div>
<div class='post-date'>{{ moment(post.timestamp).fromnow() }}</div>
<div class='post-author'>
<a href="{{url_for('.user', username=post.author.username) }}">
{{ post.author.username }}
</a>
</div>
<div class='post-body'>{{ post.body }}
</div>
</li>
{% endfor %}
</ul>
如果用户所属角色没有WRITE_ARTICLES权限,则经User.can()方法检查后,不会显示博客文章表单,博客文章列表通过HTML无序列表实现,并指定了一个CSS类,从而让格式更精美,页面左侧会显示作者的小头像,头像和作者用户名都渲染成链接形式,可链接到用户资料页面,所用的CSS样式都存储在程序static文件夹里的style.css文件中
在资料页中显示博客文章
我们可以将用户资料页改进一下,在上面显示该用户发布的博客文章列表,下例为获取文章列表:
# app/main/views.py
@main.route('/user/<username>')
def user(username):
user = User.query.filter_by(username=username).first()
if user is None:
abort(404)
posts = user.posts.order_by(Post.timestamp.desc()).all()
return render_template('user.html', user=user, posts=posts)
用户发布的博客文章列表通过User.posts关系获取,User.posts返回的是查询对象,因此可在其上调用过滤器,例如order_by()
和index.html模板一样,user.html模板也要使用一个HTML<ul>元素渲染博客文章,不建议维护两个完全相同的HTML片段副本,这种情况使用Jinja2提供的include()指令就非常有用,user.html模板包含了其他文件中定义的列表:
# app/templates/user.html
<h3>Posts by {{user.username }}</h3>
{% include '_posts.html' %}为了完成这种新的模板组织方式,index.html模板中的<ul>元素需要移到新模板_posts.html中,并替换成另一个include()指令,需要注意的是,_posts.html模板名的下划线前缀不是必须使用的,这只是一种习惯用法,以区分独立模板和局部模板
分页显示长博客文章列表
随着网络的发展,博客文章的数量会不断增多,如果要在首页和资料页显示全部文章,浏览速度会变慢且不符合实际需求,在web浏览器中,内容多的网页需要花费更多的时间生成,下载和渲染,所以网页内容变多会降低用户体验的质量,这一问题的解决方法是分页显示数据,进行片段式渲染
创建虚拟博客文章数据
若想实现博客文章分页,我们需要一个包含大量数据的测试数据库,手动添加数据库记录浪费时间而且很麻烦,所以最好能使用自动化方案,有多个Python包可用于生成虚拟信息,其中功能相对完善的是ForgeryPy,安装如下:
(env) PS D:\flasky> pip install forgerypy严格来说,ForgeryPy并不是这个程序的依赖,因为他只在开发过程中使用,为了区分生产环境的依赖和开发环境的依赖,我们可以把文件requirements.txt换成requirements文件夹,它们分别保存不同环境中的依赖,在这个新建的文件夹中,我们可以创建一个dev.txt文件,列出开发过程中所需的依赖,在创建一个prod.txt文件,列出生产环境所需的依赖,由于两个环境所需的依赖大部分是相同的,因此可以创建一个common.txt文件,在dev.txt和prod.txt中使用-r参数导入,dev.txt文件的内容如下:
-r common.txt
ForgeryPy==0.1下例展示了添加到User模型和Post模型中的类方法,用来生成虚拟数据
class User(UserMixin, db.Model):
#...
@staticmethod
def generate_fake(count=100):
from sqlalchemy.exc import IntegrityError
from random import seed
import forgery_py
seef()
for i in range(count):
u = User(email=forgery_py.internet.email_address(),
username=forgery_py.internet.user_name(True),
password=forgery_py.lorem_ipsum.word(),
confirmed=True,
name=forgery_py.name_name(),
location=forgery_py.address.city(),
about_me=forgery_py.lorem_ipsum.sentence(),
member_since=forgery_py.date.date(True)
)
db.session.add(u)
try:
db.session.commit()
except IntegrityError:
db.session.rollback()
class Post(db.Model):
#...
@staticmethod
def generate_fake(count=100):
from random import seed, randint
import forgery_py
seed()
user_count = User.query.count()
for i in range(count):
u = User,query.offset(randint(0, user_count - 1)).first()
p = Post(body=forgery_py.lorem_ipsum.sentences(randint(1, 3)),
timestamp=forgery_py.data.date(True),
author=u)
db.session.add(p)
db.session.commit()
这些虚拟对象的属性由ForgeryPy的随机信息生成器生成,其中的名字、电子邮件地址、句子等属性看起来就像真的一样
用户的电子邮件地址和用户名必须是唯一的,但ForgeryPy随机生成这些信息,因此有重复的风险,如果发生了这种不太可能出现的情况,提交数据库会话时会抛出IntegrityError的、异常,这个异常的处理方式是,在继续操作之前回滚会话,在循环中生成重复内容时不会把用户写入数据库,因此生成的虚拟用户总数可能会比预期少
随机生成文章时要为每篇文章随机指定一个用户,为此,我们使用offset()查询过滤器,这个过滤器会跳过参数中指定的记录数量,通过设定一个随机的偏移值,再调用first()方法,就能每次都获得一个不同的随机用户
使用新添加的方法,我们可以在shell中轻易生成大量虚拟用户和文章:
(env) $ python manage.py shell
>>> User.generate_fake(100)
>>> Post.generate_fake(100)效果如下
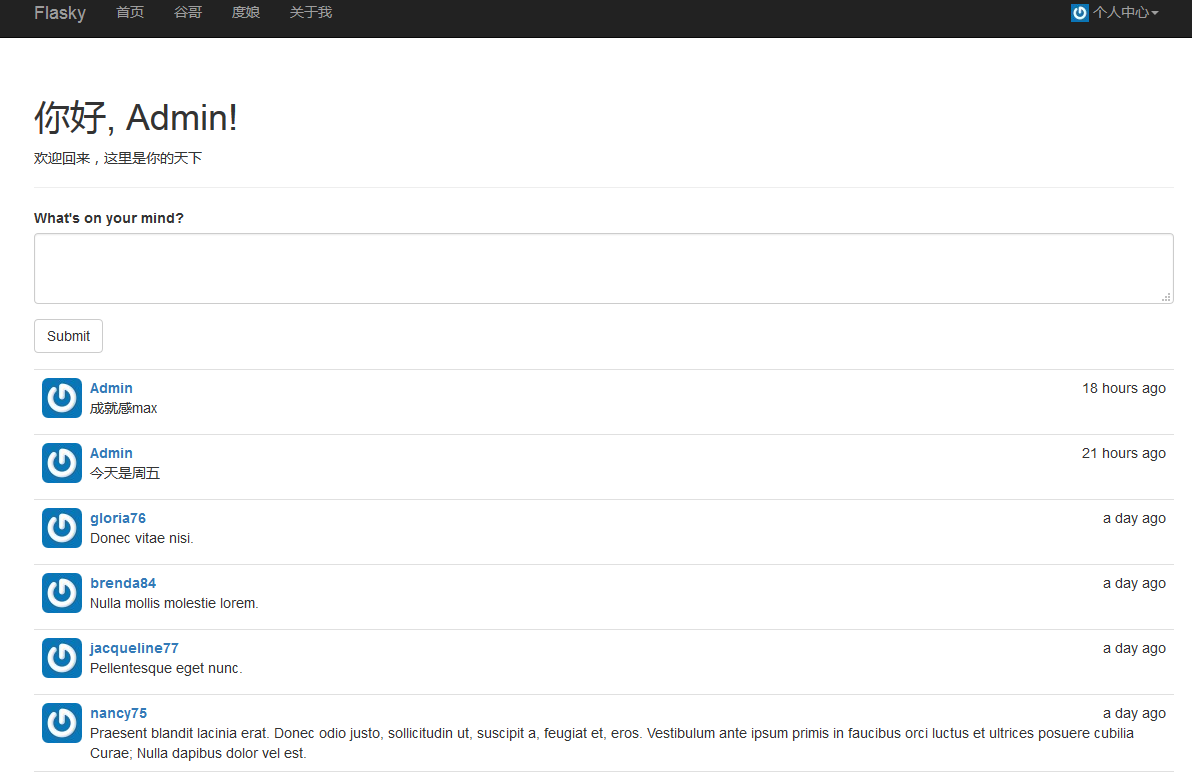
在页面中渲染数据
下面展示了为支持分页对首页路由所做的改动:
@main.route('/', methods=['GET', 'POST'])
def index():
page = request.args.get('page', 1, type=int)
pagination = Post.query.order_by(Post.timestamp.desc()).paginate(
page, per_page=current_app.config['FLASKY_POSTS_PER_PAGE'],
error_out=False)
posts = pagination.items
return render_template('index.html', form=form, posts=posts, pagination=pagination)
渲染的页数从请求的查询字符串(request.args)中获取,如果没有明确指定,则默认渲染第一页,参数type=int保证参数无法转换成整数时,返回默认值
为了显示某页中的记录,要把all()换成Flask-SQLAlchemy提供的paginate()方法,页数是paginate()方法的第一个参数,也是唯一必须的参数,可选参数per_page用来指定每页显示的记录数量,如果没有指定,则默认20个记录
另一个可选参数为error_out,当其设为True(默认值)时,如果请求的页数超出了范围,则会返回404错误,如果设为False,页数超出范围时会返回一个空列表,为了能够很便利的配置每页显示的记录数量,参数per_page的值从程序的环境变量FLASK_POSTS_PER_PAGE中读取
这样修改之后,首页中的文章列表只会显示有限数量的文章,若想看第二页中的文章,要在浏览器地址栏中的URL后加上查询字符串?page=2
添加分页导航
paginate()方法的返回值是一个Pagination类对象,这个类在Flask-SQLAlchemy中定义,这个对象包含很多属性,用于在模板中生成分页链接,因此将其作为参数传入了模板,分页对象的属性简介如下:
| 属性 | 说明 |
|---|---|
| items | 当前页面中的记录 |
| query | 分页的源查询 |
| page | 当前页数 |
| prev_num | 上一页的页数 |
| next_num | 下一页的页数 |
| has_next | 如果有下一页,返回True |
| has_prev | 如果有上一页,返回True |
| pages | 查询得到的总页数 |
| per_page | 每页显示的记录数量 |
| total | 查询的返回的记录总数 |
在分页对象上还可调用以下方法:
| 方法 | 说明 |
|---|---|
| iter_pages(left_edge=2,left_current=2, | 一个迭代器,返回一个在分页导航中显示的页数列表,这个列表的最左边显示left_edge页,当前页的左边显示left_current页,当前页的右边显示right_current页,最右 |
| right_current=5,right_edge=2) | 边显示right_edge页,例如,在一个100页的列表中,当前页为第50页,使用默认配置,这个方法会返回以下页数:1、2、None、48、49、50、51、52、53、54、55、None、99、100.None表示页数之间的间隔 |
| prev() | 上一页的分页对象 |
| next() | 下一页的分页对象 |
拥有这么强大的对象和Bootstrap中的分页CSS类,我们很容易的就能在模板底部构建一个分页导航,以下是实现代码
{% macro pagination_widget(pagination, endpoint) %}
<ul class="pagination">
<li{% if not pagination.has_prev %} class="disabled"{% endif %}>
<a href="{% if pagination.has_prev %}{{ url_for(endpoint, page = pagination.page - 1, **kwargs) }}{% else %}#{% endif %}">«
</a>
</li>
{% for p in pagination.iter_pages() %}
{% if p %}
{% if p == pagination.page %}
<li class="active">
<a href="{{ url_for(endpoint, page = p, **kwargs) }}">{{ p}}</a>
</li>
{% else %}
<li>
<a href="{{ url_for(endpoint, page = p, **kwargs) }}">{{ p }}</a>
</li>
{% endif %}
{% else %}
<li class="disabled"><a href="#">…</a>
</li>
{% endif %}
{% endfor %}
<li{% if not pagination.has_next %} class="disabled"{% endif %}>
<a href="{% if pagination.has_next %}{{ url_for(endpoint, page = pagination.page + 1, **kwargs) }}{% else %}#{% endif %}">
»
</a>
</li>
</ul>
{% endmacro %}这个宏创建了一个Bootstrap分页元素,即一个由特殊样式的无序列表,其中定义了下述页面链接
- 上一页链接,如果当前页是第一页,则为这个链接加上disabled类
- 分页对象的iter_page()迭代器返回的所有页面链接,这些页面被渲染成具有明确页数的链接,页数在url_for()的参数中指定,当前显示的页面使用activeCSS类高亮显示,页数列表中的间隔使用省略号表示
- 下一页链接,如果当前页是最后一页,则会禁用这个链接
Jinja2宏的参数列表中不用加入**kwargs即可接受关键字参数,分页宏把接收到的所有关键字参数都传给了生成分页链接的url_for()方法,这种方式也可在路由中使用,例如包含一个动态部分的资料页
pagination_widget宏可放在index.html和user.html中的_posts.html模板后面:
# app/templates/index.html
#...
{% include '_posts.html' %}
{% if pagination %}
<div class="pagination">
{{ macros.pagination_widget(pagination, '.index') }}
</div>
{% endif %}效果如下:
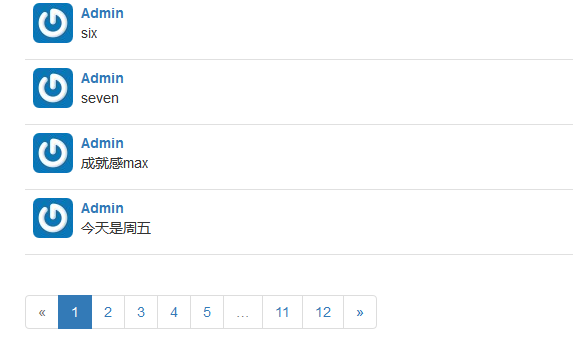

















 8918
8918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









