









23年11月来自Nvidia、加州USC和斯坦福的论文"A Language Agent for Autonomous Driving“。
人性化驾驶是自动驾驶的终极目标。传统的方法将自动驾驶作为一种感知-预测-规划框架,但它们的系统没有利用人类固有的推理能力和经验知识。本文提出一个当前流水线的基本范式转变,利用大语言模型(LLM)作为一种认知智体,将类人智能集成到自动驾驶系统中。其方法称为Agent Driver,引入一个可通过函数调用访问的通用工具库、用于决策的常识和经验知识的认知记忆,以及一个能够进行思维链(CoT)推理、任务规划、运动规划和自我反思的推理机,这样改变了传统的自动驾驶流水线。在LLM的支持下,Agent Driver具有直观的常识和强大的推理能力,从而实现了更细致、更人性化的自动驾驶方法。该方法还表现出了优越的可解释性和少样本学习能力。
其和传统方法的直观比较图如下所示:在LLM之上,引入了一个多功能工具库,该库通过动态函数调用与神经模块接口,以较少的冗余简化感知。此外,提出一种可配置的认知记忆,它明确地存储常识和驾驶经验,为系统注入人类经验知识。此外,提出了一个推理引擎,该引擎处理感知结果和记忆数据,模拟类人的决策。推理引擎执行思维链推理,识别关键目标和事件,执行任务规划导出高级驾驶规划,执行运动规划生成驾驶轨迹,执行自我反思以确保规划轨迹的安全。这些组成部分由LLM协调,最终形成拟人的驾驶过程。

Agent-Driver的总体架构如图所示。该方法将感官数据作为输入,并引入神经模块来处理这些感官数据,并提取有关检测、预测、占用和地图的环境信息。在神经模块之上,提出了一个工具库,其中设计了一组函数来进一步抽象神经输出并返回基于文本的消息。对于每个驾驶场景,LLM通过调用工具库中的特定功能来选择性地激活所需的神经模块,确保以较少的冗余度收集必要的环境信息。在收集到必要的环境信息后,LLM利用这些数据作为查询,在认知记忆中搜索相关的交通法规和最相似的过去驾驶体验。最后,检索的交通规则和驾驶经验,以及以前收集的环境信息,用作基于LLM推理引擎的输入。推理引擎根据输入进行多轮推理,最终设计出安全舒适的驾驶轨迹。
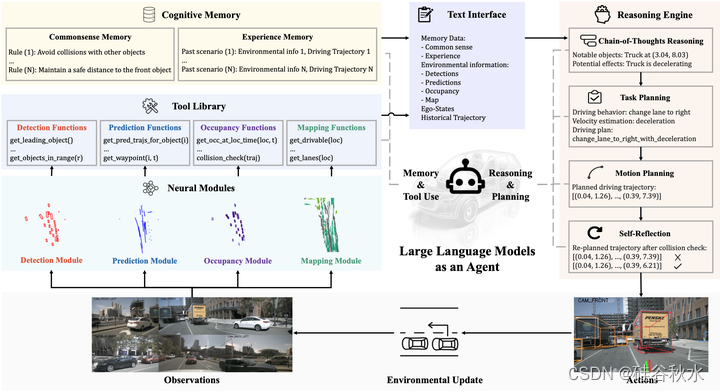
Agent Driver架构利用了工具库带来的动态感知和预测能力、来自认知记忆的人类知识以及推理引擎强大的决策能力。这种协同集成产生了一个更像人类的驾驶系统,并增强了决策能力。
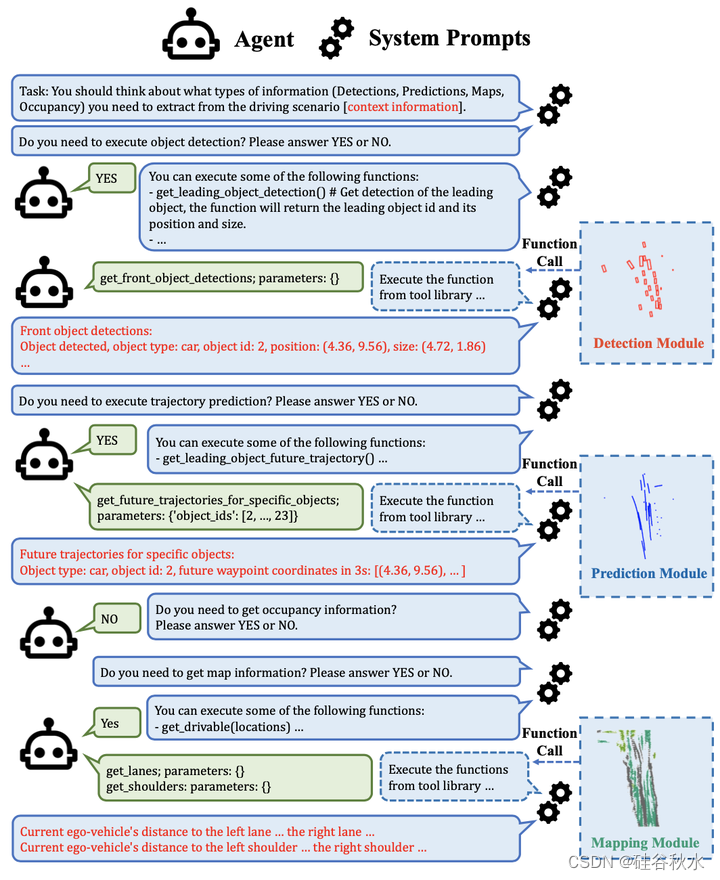
工具库的基石是四个神经模块,即检测、预测、占用和地图模块,它们处理观测数据,并分别生成检测的边框、未来轨迹、占用网格和地图。神经模块涵盖感知和预测的各种任务,并从观测中提取环境信息。然而,这些信息是高度冗余的,并且大多数信息不会影响决策过程。为了从神经模块输出中动态提取必要的信息,提出了一个工具库,其中设计了一组函数,将神经输出汇总为基于文本的消息,调用动态函数来建立信息收集过程。如图显示了该过程的示例。
如何利用交通规则和驾驶经验?该方法采用与认知记忆的互动方法。具体来说,认知记忆存储基于文本的常识和驾驶体验。对于每一种驾驶场景,利用函数调用收集环境信息作为查询,在认知记忆中搜索类似的过去经历,以帮助决策。认知记忆包含两个子记忆:常识记忆和经验记忆。
常识记忆。常识性记忆概括了驾驶员在道路上安全驾驶通常需要的基本知识,如交通法规和有关危险行为的知识。值得注意的是,常识记忆纯粹是基于文本的,并且是完全可配置的,也就是说,用户只需在记忆中写入不同类型的知识,就可以针对不同的驾驶条件定制自己的常识记忆。
经验记忆。经验记忆包含了一系列过去的驾驶场景,其中每个场景都由当时的环境信息和随后的驾驶决策组成。通过检索最相似的经历并参考其驾驶决策,系统增强了能力去做出更明智和更有弹性的驾驶决策。
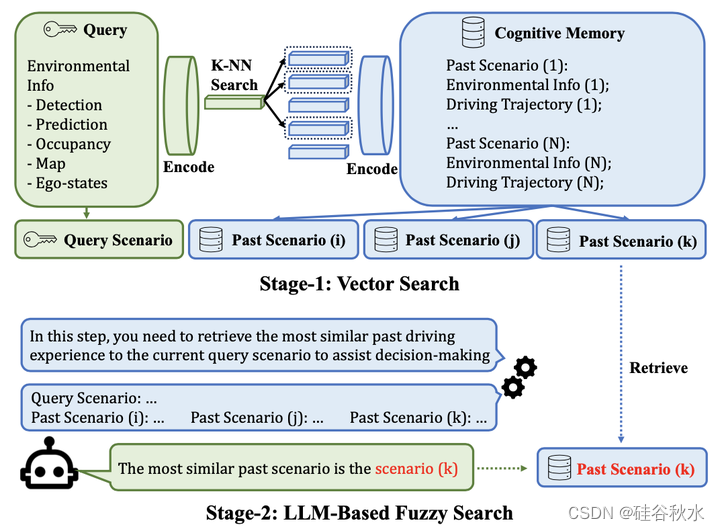
记忆搜索。如图所示,作者提出了一种两阶段搜索算法,有效地搜索经验记忆中最相似的过去驾驶场景。算法的第一阶段受到向量数据库[19,37]的启发,其中输入查询和存储器中的每个记录,编码为嵌入,然后通过嵌入空间中的K-NN搜索来检索前K个相似记录。由于驾驶场景非常多样化,基于嵌入的搜索固有地受到编码方法的限制,导致泛化能力不足。为了克服这一挑战,第二阶段结合了基于LLM的模糊搜索。LLM的任务是根据这些记录与查询的相关性对它们进行排名。该排名基于LLM的隐含相似性评估,利用其泛化和推理能力。认知记忆使系统具备了人类知识和过去的驾驶经验。检索到的最相似的经验,加上常识和环境信息,共同构成了推理引擎的输入。文本作为一个统一的界面,弥合了神经感知结果和人类知识之间的差距,从而增强了系统的兼容性。
推理是人类的一项基本能力,对决策过程至关重要。如图所示,作者提出了一种推理引擎,将推理能力融入驾驶决策过程。推理引擎输入环境信息和记忆数据,进行多阶段推理,最终规划出安全舒适的驾驶轨迹。它由四个核心组成部分组成:思维链推理、任务规划、动作规划和自我反思。
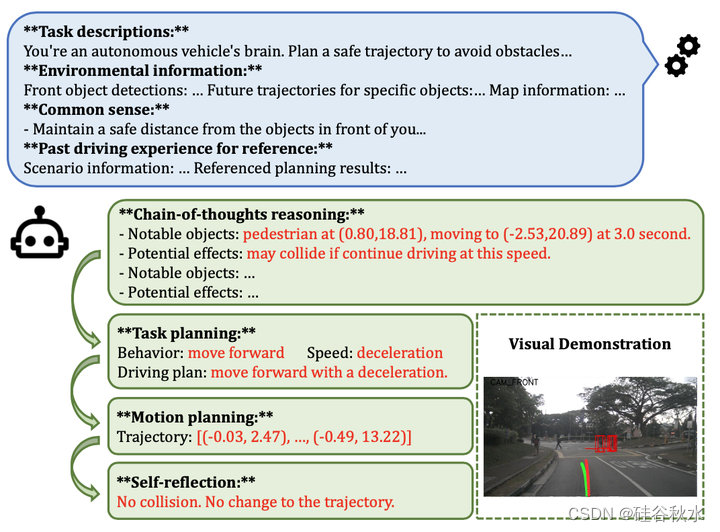
思维链推理。提出了一个思维链推理模块,指示LLM对输入的环境信息进行推理,并在文本中输出关键目标及其潜在影响的列表。为了指导这个推理过程,通过对一些人类注释示例的上下文学习来指导LLM。这种策略成功地将LLM的推理能力与自动驾驶的上下文相结合,从而提高了推理的准确性。
任务规划。高级驾驶规划为低级运动规划提供了重要指导。将高级驾驶规划定义为离散驾驶行为和速度估计的组合。例如,驾驶行为左变道和速度估计减速的组合会导致高级驾驶规划向左变道并减速。通过上下文学习指导LLM根据环境信息、记忆数据和思维链推理结果制定高级驾驶规划。所设计的高级驾驶规划表征了自车的粗略运动,并作为指导后续运动规划过程的有力前提。
运动规划。将运动规划重新表述为一个语言建模问题。具体来说,利用环境信息、记忆数据、推理结果和高级驾驶规划共同作为LLM的输入,并指示LLM对输入进行推理来生成基于文本的驾驶轨迹。通过对人类驾驶轨迹进行微调,LLM可以生成与人类驾驶模式密切相似的轨迹。最后,将基于文本的轨迹转换回用于系统执行的真实轨迹。
自我反思。提出了一种碰撞检查和优化方法。具体来说,对于来自运动规划模块的规划轨迹,首先调用工具库中的碰撞检查函数来检查其碰撞概率。如果其高于阈值,通过优化成本函数将轨迹τ细化为新轨迹。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









