










22年2月来自TX Austin和Facebook (Meta)的论文“DexVIP: Learning Dexterous Grasping with Human Hand Pose Priors from Video”。
灵巧的多指机械手具有强大的动作空间,但它们与人手的形态相似性具有加速机器人学习的巨大潜力。DexVIP,是一种从野外 YouTube 视频中的人与目标交互中学习灵巧机器人抓取的方法。通过从人与目标交互视频中整理抓取图像并在使用深度强化学习学习抓取时对智体的手部姿势施加先验来实现这一点。一个关键的算法优势是,学习的策略能够利用自由形式的野外视觉数据。因此,它可以轻松扩展到新目标,并且它避开了在实验室中收集人类演示的标准做法——这是一种更昂贵且间接的获取人类专业知识的方法。通过使用 30-DoF 模拟机械手对 27 个目标进行实验,证明 DexVIP 与缺乏手部姿势先验或依赖专门的遥控设备获得人体演示的现有方法相比具有优势,而且训练速度更快。
如图所示:主要思想是观察人们在现实世界中使用目标时的手势,以便建立 3D 手势先验,机器人可能会在功能性抓取过程中尝试匹配该先验。没有采用特殊目的的演示(例如,在实验室桌面录制视频),而是转向野外互联网视频作为视觉先验的来源。该方法使用计算机视觉技术自动从视频帧中提取人类手势。然后,定义一个深度强化学习模型,该模型通过奖励来增强抓取成功奖励,奖励目标接触时类似人类的手势,同时还倾向于在基于图像的模型预测的affordance区域周围抓取目标。简而言之,通过观看人们使用各种目标进行日常活动的视频,智体学习如何使用自己的多指手有效地接近目标,同时还可以加速训练。

灵巧抓取任务被构造为强化学习 (RL) 问题,其中智体根据策略与环境交互以最大化指定的奖励,如图所示。在每个时间步骤 t,智体观察当前观察 o/t 并从其策略 π 中采样一个动作 a/t。然后它从环境中获得标量奖励 R/t+1 和下一个观察 o/t+1。此反馈循环持续到episode在 T 时间步骤终止。智体的目标是确定最大化预期奖励总和的最佳随机策略。
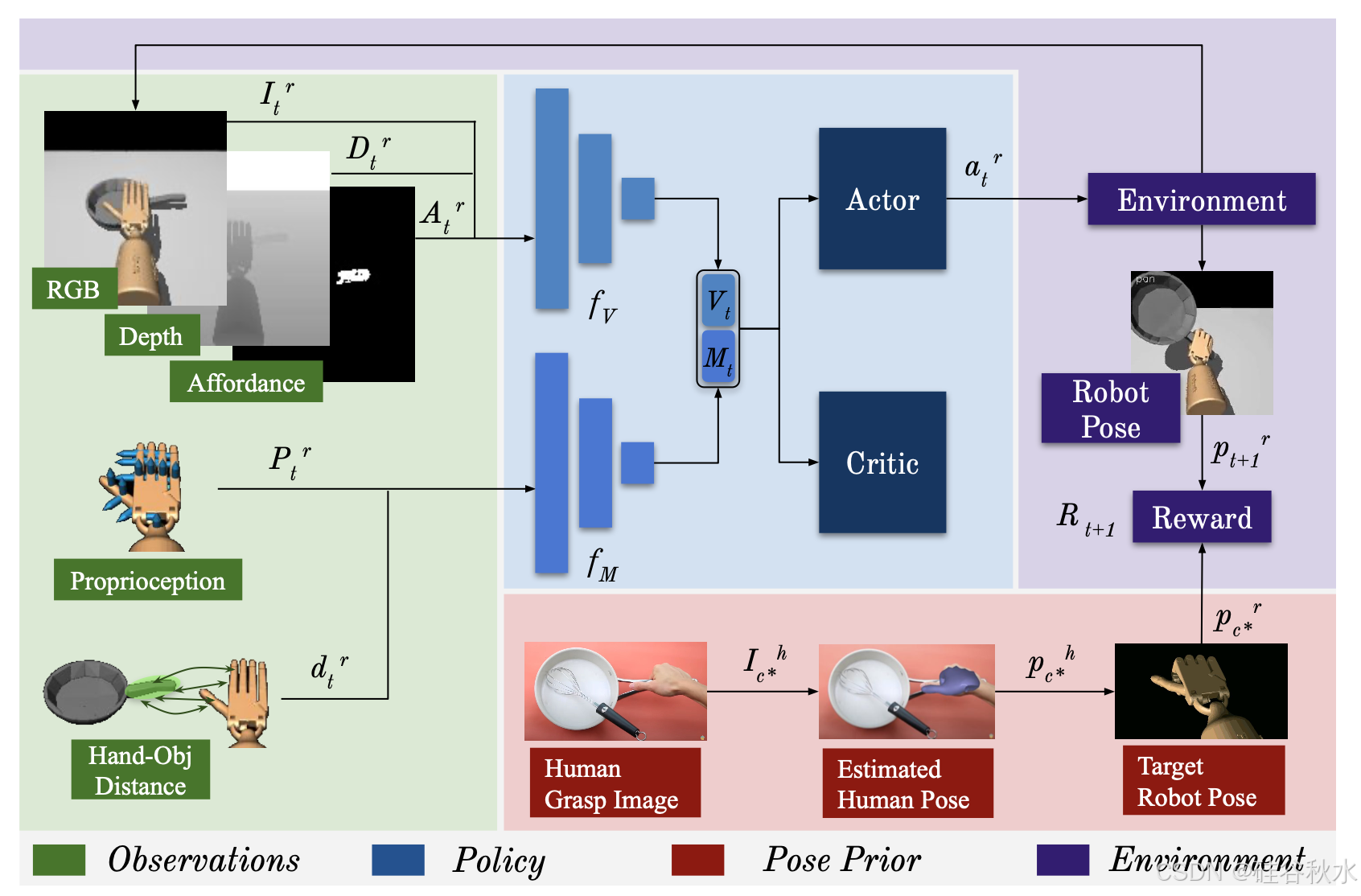
任务设置包括放置在桌面上方的机械手,感兴趣的目标放在桌子上。在每个episode开始时,采样一个目标并将其从其规范方向随机旋转。每个时间步 t 的观察 or/t(上图,绿色块)是机器人视觉和运动输入的组合。视觉流来自以自我为中心的手持式摄像机。它由场景的 RGB 图像 Ir/t 和相应的深度图 Dr/t 组成。此外,还提供了一个二进制affordance图 Ar/t,该图是使用affordance预测网络 [18] 从 Ir/0 推断出来的,以引导智体朝向目标的功能性抓握区域。电机输入是机器人本体感受 Pr/t 和手与目标接触距离 dr/t 的组合。Pr/t 由机器人关节角度或姿势 pr/t 和执行器的角速度 vr/t 组成,而 dr/t 是目标affordance区域和手上接触点之间的成对距离。后者假设一旦检测到目标的affordance区域,就会如 [18]那样在 3D 中跟踪该目标。智体还有 21 个触摸传感器 T^r,均匀分布在手掌和手指上。
在每个时间步骤 t,策略 π 处理观测值 or/t 并估计动作 a^r/t — 30 个连续关节角度值 — 这些动作应用于执行器的关节角度。考虑的机器人操纵器是 Adroit hand [51],这是一个 30 自由度位置控制的灵巧手。机器人手的形态与人手非常相似,因为有一个五指 24 自由度执行器连接到一个 6 自由度手臂。这种一致性开辟了一条令人兴奋的途径,可以将先前从人与目标交互视频中学到的抓握姿势注入其中。
采用演员-评论家(AC)模型来学习抓握策略。视觉运动观测值 or/t 分别使用两个神经网络 f/V 和 f/M 进行处理(上图,蓝色块)。具体来说,包含 {Ir/T, Dr/T , Ar/t } 的视觉输入被连接起来并馈送到三层 CNN f/V,后者对它们进行编码以获得视觉嵌入 V/t。由 {Pr/t, dr/t} 组成的运动流由两层全连接网络 f/M 处理,后者将它们编码为运动嵌入 M/t。最后,V/t 和 M/t 被连接起来并馈送到参与者-评论家(AC)网络,以分别估计每个时间步骤的策略分布 π/θ (ar/t |or/t ) 和状态值 V/θ (or/t)。得到的策略 π 输出一个 30 维单位方差高斯分布,其均值由网络推断出来;从这个分布中抽样以获得机器人的下一个动作 a^r/t 。用 PPO [52] 训练完整的 RL 网络,并使用鼓励成功抓握、触摸目标affordance区域和模仿人类手势的奖励。
机器人手模拟器在 MuJoCo [53] 中进行实验,这是一种常用于机器人研究的物理模拟器。由于无法使用真正的机械手,在模拟中进行所有实验。纯粹在模拟中训练的灵巧策略,成功迁移到现实世界 [11, 7, 6] 支持了基于模拟器的学习在当今研究中的价值。此外,进行大量实验,实验中设置了可能在现实世界中出现的噪声传感和驱动设置,以说明该策略对非理想场景的稳健性。
使用获得的 HowTo100M 抓取图像 I/h 为机器人抓取提供学习信号。为此,对于每张图像,首先推断其 3D 人手姿势 p^h。具体来说,用 FrankMocap [44] 来估计 3D 人手姿势(见图左)。FrankMocap 是一种近乎实时的方法,用于从单目视频中估计 3D 手部和身体姿势;它返回每帧中检测的手部 3D 关节角度。虽然可以在这里插入其他姿势估计方法,但在实现中使用 FrankMocap,因为它效率高且经验性能好。只保留右手检测,因为机器人是单手的。

此步骤会针对视频中发现的各种目标生成每个目标的不同手势集合。令 P © = {ph/c/1 , . . . , ph/c/n } 为与目标类别 c 相关的人类手势集合。目标类别中的手势通常非常一致,因为视频自然地描绘了人们以标准功能方式使用该目标,例如,握住锅柄会引起大多数人的相同手势。但是,某些目标会引起多模态手势分布(例如,握住刀时食指伸出或不伸出)。为了自动发现目标的“共识”姿势,接下来对每个集合 P© 应用 k-medoid 聚类。将最大类的 中值手部姿势视为共识目标手部姿势 ph/c∗,并在目标 c 的策略学习期间使用其关联的目标机器人姿势 p^r/c∗。
为了在强化学习公式中发挥视频先验的影响,加入了一个辅助奖励函数,该函数有利于机器人的姿势与视频中人类的姿势相似。这样,奖励函数不仅可以指示在哪里抓取特定目标,还可以指导智体如何有效地抓取。为了实现这一点,结合三个奖励:R/succ(当目标从桌子上拿起时为正奖励)、R/aff(表示从 [18] 获得的手部affordance接触距离的负奖励),以及最值得注意的是 R/pose,当智体的姿势 pr/t 与该目标的目标抓取姿势 p^r/c∗ 匹配时为正奖励。
所提出的方法允许通过视觉观察人类的操作视频进行模仿,但无需访问人类活动的状态-动作轨迹。因此,其监督模式比传统的遥操作或动觉教学要轻松得多。此外,由于模型可以通过获取新的训练图像来整合新目标的先验知识,因此它可以很好地扩展以添加新目标。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









