




建立虚拟机,安装和配置 Ubuntu Server版本操作系统,安装JDK,Hadoop,Spark,Bottle,实现对 E_Commerce_Data数据可视化流程和对iris数据集机器学习。
实验设备和所需资源
PC计算机,配置Win10操作系统, VirtualBox
PUTTY
Ubuntu Server 16.04
jdk-8u162-linux-x64.tar.gz
hadoop-3.1.3.tar.gz
spark-2.4.0-bin-without-hadoop.tgz
E_Commerce_Data.csv
数据预处理和分析代码
iris数据集
说明:
1.PUTTY,Ubuntu ,jdk, hadoop,spark,iris数据集可从网络资源中自己查找下载使用。
2.E_Commerce_Data数据集和数据预处理和分析代码可访问林子雨老师的基于零售交易数据的Spark数据处理与分析资源网址如下:https://dblab.xmu.edu.cn/blog/2652/
3.PUTTY的使用方法可访问我的另一篇文章:https://blog.csdn.net/you1234me/article/details/149281735?spm=1001.2014.3001.5501
实验内容
一、建立虚拟机
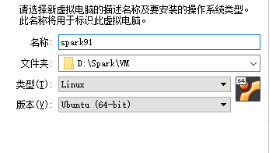
CPU:2核

RAM:4000+学号后2位 MB

硬盘:40.学号后2位 GB
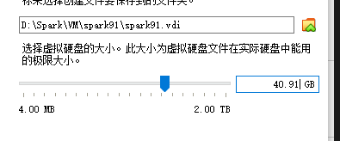
网络:默认网络
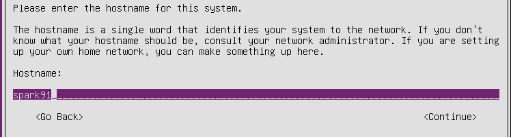
二、安装操作系统
操作系统:Ubuntu Server 16.04
HOSTNAME:spark学号后2位
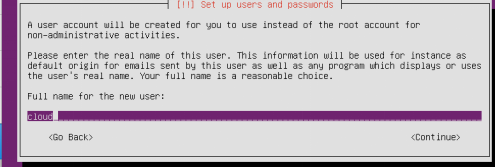
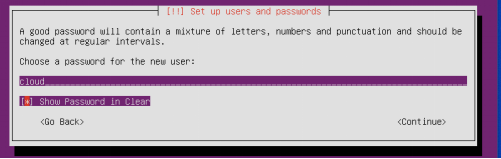
安装时设置用户名和密码都是:cloud
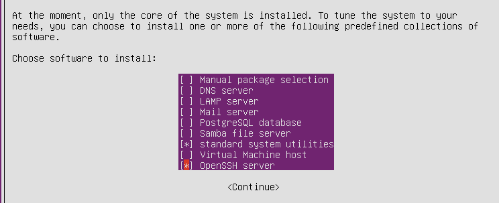
注意选择安装OpenSSH Server
三、配置操作系统
运行python3 --version查看python版本
python3 --version

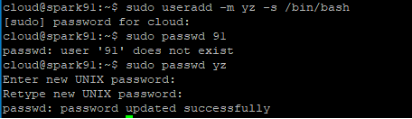
创建大数据操作用户,用户名为你的姓名各字的首字母,密码是你的学号后2位,例abc,密码12
sudo useradd -m yz -s /bin/bash
sudo passwd yz
为 hadoop 用户增加管理员权限:
sudo adduser yz sudo

使用新用户重新登录!

配置无密码登录:
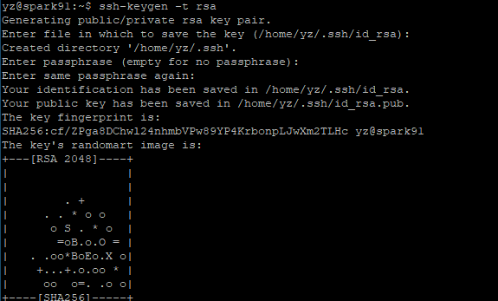
ssh-keygen -t rsa #输入该命令后需要多按几个回车
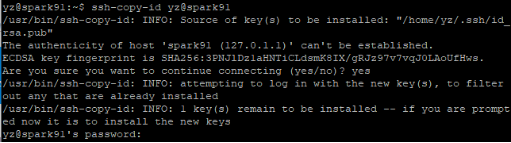
ssh-copy-id yz@spark91

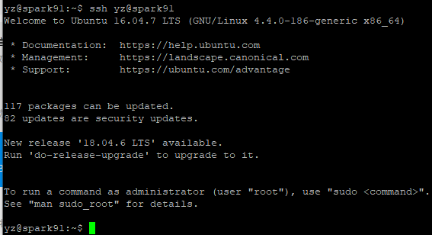
测试:ssh yz@spark91
ssh yz@spark91
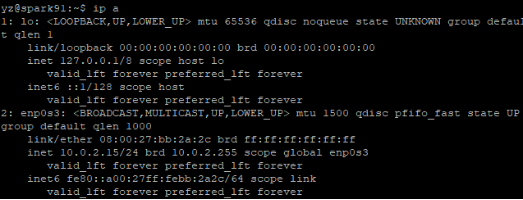
使用ip a和ip r查看当前DHCP方式获得的IP地址
ip a
ip r

修改IP地址为静态配置,使用原DHCP网段,最后一段IP地址为100+你的学号后2位
cd /etc
cd network
ls
sudo cp interfaces interfaces.bak
sudo vi interfaces

address:10.0.2.191
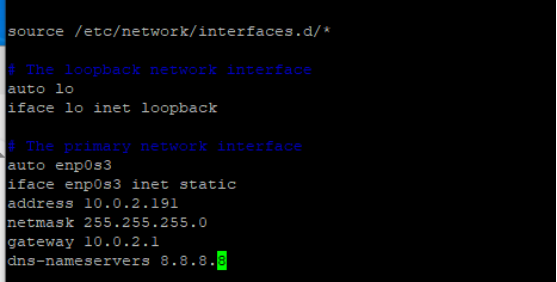
sudo /etc/init.d/networking restart #重启网络查看是否修改成功
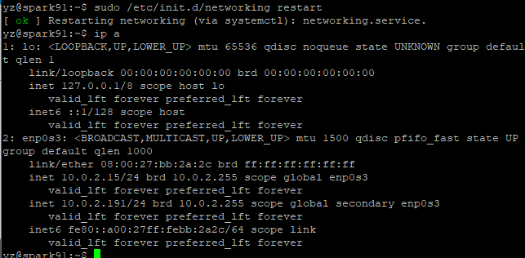
四、安装JDK
sudo mkdir /usr/lib/jvm #创建jdk安装目录
使用pscp把jdk-8u162-linux-x64.tar.gz从windows传输到ubuntu的用户主目录中

在ubuntu中解压jdk
ls /usr/lib/jvm 可以看到新目录jdk1.8.0_162
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm

设置环境变量:
vim ~/.bashrc
在文件开头写入下面变量
export JAVA_HOME=/usr/lib/jvm/jdk1.6.0_162
export JRE_HOME=$(JAVA_HOME)/jre
export CLASSPATH=.*${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
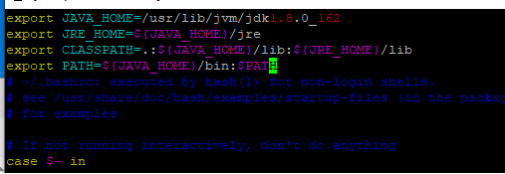
保存退出后执行 source ~/.bashrc , 运行 java -version 验证
source ~/.bashrc
java -version
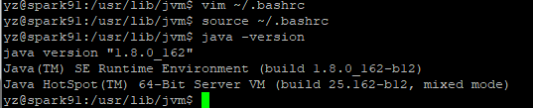
五、安装配置Hadoop3.1.3
把hadoop-3.1.3.tar.gz上传到ubuntu中

解压 sudo tar -zxf hadoop-3.1.3.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R yz ./hadoop # 修改文件权限
sudo tar -zxf hadoop-3.1.3.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R yz ./hadoop # 修改文件权限, yz是我的用户名
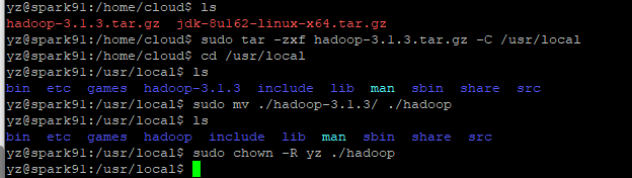
配置hadoop伪分布式集群模式:
进入Hadoop 配置文件目录 /usr/local/hadoop/etc/hadoop/
cd /usr/local/hadoop/etc/hadoop/
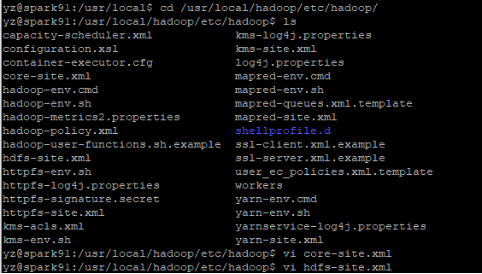
vi core-site.xml修改为:
vi core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
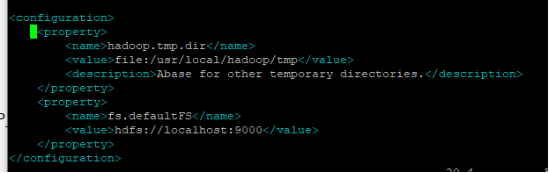
vi hdfs-site.xml修改为:
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>

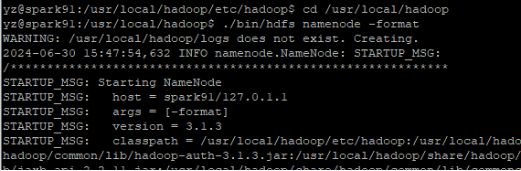
执行 NameNode 的格式化
cd /usr/local/hadoop
./bin/hdfs namenode –format
cd /usr/local/hadoop
./bin/hdfs namenode –format
开启 NameNode 和 DataNode 守护进程 ./sbin/start-dfs.sh
./sbin/start-dfs.sh

修改环境变量
vi ~/.bashrc添加export HADOOP_HOME=/usr/local/hadoop
运行 source ~/.bashrc
vi ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop
source ~/.bashrc #退出配置文件后执行

在HDFS中创建用户目录
./bin/hdfs dfs -mkdir -p /user/你的用户名
./bin/hdfs dfs -ls
./bin/hdfs dfs -mkdir -p /user/你的用户名
./bin/hdfs dfs -ls

六、安装Spark
把spark-2.4.0-bin-without-hadoop.tgz上传到ubuntu,解压

sudo tar -zxf spark-2.4.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-2.4.0-bin-without-hadoop/ ./spark
sudo chown -R yz:yz ./spark #赋予权限
sudo tar -zxf spark-2.4.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-2.4.0-bin-without-hadoop/ ./spark
sudo chown -R yz:yz ./spark #赋予权限

修改环境变量
vi ~/.bashrc增加export SPARK_HOME=/usr/local/spark
export PYSPARK_PYTHON=python3
运行source ~/.bashrc
vi ~/.bashrc
export SPARK_HOME=/usr/local/spark
export PYSPARK_PYTHON=python3
source ~/.bashrc#退出配置文件后执行

修改Spark的配置文件
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
vim ./conf/spark-env.sh
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
vim ./conf/spark-env.sh

第一行添加以下配置信息:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)

测试运行,记录计算出的pi结果
bin/run-example SparkPi
bin/run-example SparkPi

在windows用浏览器访问虚拟机的4040端口
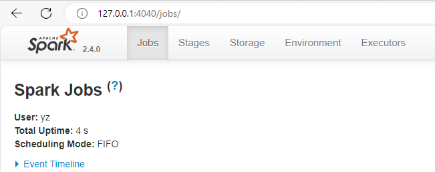
七、安装Bottle v0.12.18
执行如下命令:
sudo apt update
sudo apt-get install python3-pip
pip3 install bottle

八、数据预处理
将数据集E_Commerce_Data.csv上传至ubuntu后,复制到hdfs中
/usr/local/hadoop/bin/hdfs dfs -put E_Commerce_Data.csv /
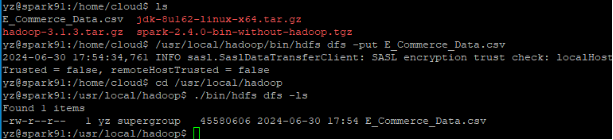
启动spark对数据进行初步探索和清洗:
cd /usr/local/spark
./bin/pyspark
以下在pyspark中操作:
1. 读取在HDFS上的文件,以csv的格式读取,得到DataFrame对象
df=spark.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load('E_Commerce_Data.csv')
2. 查看数据集的大小,记录输出记录数,注意这不包含标题行
df.count()

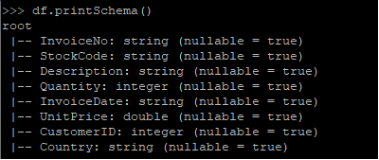
3. 打印数据集的schema,截屏字段及其类型信息。输出内容就是上文中的属性表
df.printSchema()
4. 创建临时视图data
5. 顾客编号CustomID和商品描述Description均存在部分缺失,所以进行数据清洗,过滤掉有缺失值的记录。特别地,由于CustomID为integer类型,所以该字段若为空,则在读取时被解析为0,故用df[“CustomerID”]!=0 条件过滤。
6. 查看清洗后的数据集的大小,记录输出记录数
df.createOrReplaceTempView("data")
clean=df.filter(df["CustomerID"]!=0).filter(df["Description"]!="")
clean.count()

7. 保存预处理后的数据写入HDFS。将清洗后的文件以csv的格式,写入E_Commerce_Data_Clean.csv中(实际上这是目录名,真正的文件在该目录下,文件名类似于part-00000),需要确保HDFS中不存在这个目录,否则写入时会报“already exists”错误。
clean.write.format("com.databricks.spark.csv").options(header='true',inferschema='true').save('E_Commerce_Data_Clean.csv')


九、数据分析
1. 上传相关代码

把所提供的代码复制到/usr/local/spark/code目录中
mkdir -p /usr/local/spark/code/static

2. 分析project.py程序
解读主程序实现
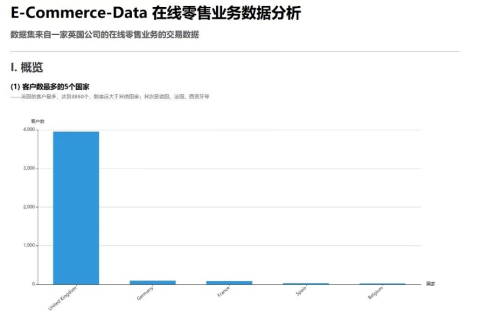
(0)顾户数最多的5个国家、
countryCustomerDF = spark.sql(
"SELECT Country, COUNT(DISTINCT CustomerID) AS countOfCustomer "
"FROM data "
"GROUP BY Country "
"ORDER BY countOfCustomer DESC "
"LIMIT 5"
)
# 显示结果
# countryCustomerDF.show()
# 返回结果(以列表形式)
return countryCustomerDF.collect()

(1)销量最高的5个国家、
def countryquantity():
countryQuantityDF = spark.sql("""
SELECT Country, SUM(Quantity) AS sumOfQuantity
FROM data
GROUP BY Country
ORDER BY sumOfQuantity DESC
LIMIT 5
""")
return countryQuantityDF.collect()

(2)销量最高的5个商品、
def countryQuantity():
countryQuantityDF = spark.sql("""
SELECT Country, SUM(Quantity) AS sumOfQuantity
FROM data
GROUP BY Country
ORDER BY sumOfQuantity DESC
LIMIT 5
""")
return countryQuantityDF.collect()

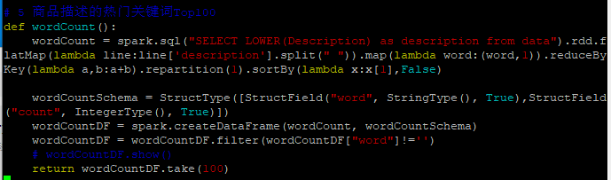
(3)商品描述的热门关键词Top100、
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
def wordCount():
# 分词并统计词频
wordCount = spark.sql("SELECT LOWER(Description) as description FROM data").rdd \
.flatMap(lambda line: line['description'].split(' ')) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b) \
.repartition(1) \
.sortBy(lambda x: x[1], False)
# 定义Schema并创建DataFrame
wordCountSchema = StructType([
StructField("word", StringType(), True),
StructField("count", IntegerType(), True)
])
wordCountDF = spark.createDataFrame(wordCount, wordCountSchema)
wordCountDF = wordCountDF.filter(wordCountDF["word"] != '')
# 返回Top100高频词
return wordCountDF.take(100)
(4)退货订单数最多的5个国家、
def countryReturnInvoice():
countryReturnInvoiceDF = spark.sql("""
SELECT
Country,
COUNT(DISTINCT InvoiceNo) AS countOfReturnInvoice
FROM
data
WHERE
InvoiceNo LIKE 'C%'
GROUP BY
Country
ORDER BY
countOfReturnInvoice DESC
LIMIT 5
""")
return countryReturnInvoiceDF.collect()

各个国家的总销售额分布情况、月销售额随时间的变化趋势、日销量随时间的变化趋势、各国的购买订单量和退货订单量的关系、商品的平均单价与销量的关系的代码,把结果以json格式存放到static目录中。
重点解读你的学号后2位对5取余数对应的功能。
3. 运行
/usr/local/spark/code
../bin/spark-submit project.py
记录分析运行结果

十、数据可视化
- 开放对虚拟机9999端口的访问
sudo ufw allow 9999
- 运行python3 web.py
python3 web.py
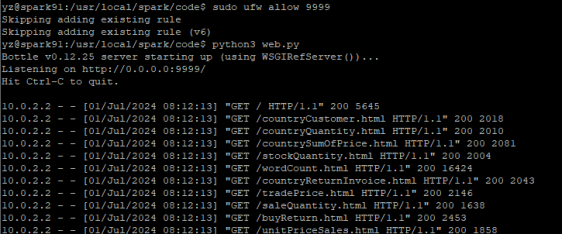
在windows浏览器中访问虚拟机的9999端口
十一、机器学习
实现对iris数据集的K-Means的聚类分析
将iris.zip上传到虚拟机:
pscp -P 10422 D:\Spark\iris.zip cloud@127.0.0.1:/home/cloud

进行解压缩包:
sudo unzip iris.zip
启动pyspark运行代码进行K-Means的聚类分析:
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler, StandardScaler
from pyspark.sql.functions import monotonically_increasing_id
from pyspark.ml.clustering import KMeans
from pyspark.sql.types import StructType, StructField, StringType, DoubleType
from pyspark.ml.feature import StandardScaler
# 假设 data_clustering 是已加载的DataFrame
assembler = VectorAssembler(inputCols=[...], outputCol="features") # 需替换为实际列名
data_assembled = assembler.transform(data_clustering)
# 特征归一化
scaler = StandardScaler(inputCol="features", outputCol="scaledFeatures", withMean=True, withStd=True)
data_scaled = scaler.fit(data_assembled).transform(data_assembled)
# 应用K-Means算法(聚类数量需指定)
from pyspark.ml.clustering import KMeans
k = 3 # 示例聚类数量
kmeans = KMeans(featuresCol="scaledFeatures", k=k)
model = kmeans.fit(data_scaled)
# 预测类别并添加索引
predictions = model.transform(data_scaled)
data = data.withColumn("index", monotonically_increasing_id())
predictions = predictions.withColumn("index", monotonically_increasing_id())
# 合并预测结果
data_with_predictions = data.join(predictions.select("index", "prediction"), "index")
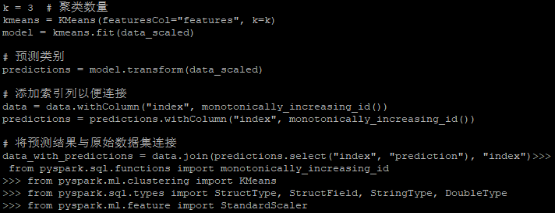
运行的聚类分析部分预测结果如下:
data_with_predictions.select("sepal_length", "sepal_width", "petal_length", "petal_width", "class", "prediction").show()
对预测结果和原始数据进行保存:
output_path = "file:///usr/local/spark/datasets/iris/predictions"
data_with_predictions.write.mode("overwrite").csv(output_path)
sc.stop()

创建spark会话,加载iris数据集:
from pyspark.sql import SparkSession
# 创建Spark会话
spark = SparkSession.builder \
.appName("IrisDataLoading") \
.getOrCreate()
# 加载数据
iris_df = spark.read.csv(
"file:///usr/local/spark/datasets/iris/iris.data",
header=False,
inferSchema=True
)

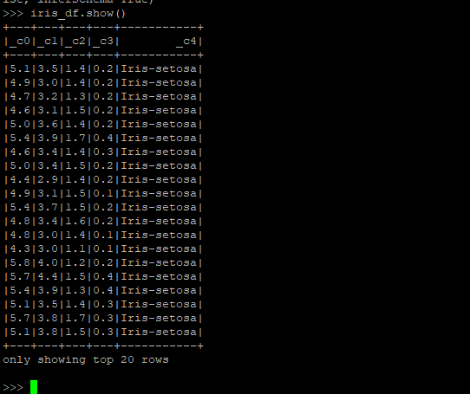
显示iris数据集:
iris_df.show()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









