










sparkStreaming的转换操作
史上最简单的spark教程
所有代码示例地址:https://github.com/Mydreamandreality/sparkResearch
(提前声明:文章由作者:张耀峰 结合自己生产中的使用经验整理,最终形成简单易懂的文章,写作不易,转载请注明)
(文章参考:Elasticsearch权威指南,Spark快速大数据分析文档,Elasticsearch官方文档,实际项目中的应用场景)
(帮到到您请点点关注,文章持续更新中!)
Git主页 https://github.com/Mydreamandreality
- Streaming的转换操作分为两种
- 无状态转换操作(stateless)
- 再无状态转换操作中,每个批次的处理数据不依赖于之前批次的数据
- 有状态转换操作(stateful)
- 有状态转换操作就是需要依赖于之前批次或者中间结果来计算当前批次的数据
- 有状态的操作包括基于滑动窗口的转换操作和追踪状态变化的转换操作
- 无状态转换操作(stateless)
详细介绍一波
无状态转换操作:
- 无状态转换操作就是转化Dstream中的每一个RDD
- 代码和我们RDD的wordcount基本是一致的,之前有专门讲解过这个,这里就不赘述了,不太懂的兄弟可以去看我的博客第二章快速运行java+spark程序
- wordCount代码案例:
/**
* Created by 張燿峰
* 无状态转换操作案例
*
* @author 孤
* @date 2019/4/12
* @Varsion 1.0
*/
public class StateLess {
private static final Pattern SPACE = Pattern.compile(" ");
static final class LogTuple implements PairFunction<String, String, Integer> {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<>(s, 1);
}
}
static final class ReduceIsKey implements Function2<Integer, Integer, Integer> {
@Override
public Integer call(Integer v1, Integer v2) {
return v1 + v2;
}
}
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setMaster("local[2]").setAppName("StateLess");
JavaStreamingContext streamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(1));
JavaReceiverInputDStream<String> inputDStream = streamingContext.socketTextStream("localhost", 8080);
JavaDStream<String> dStream = inputDStream.flatMap((FlatMapFunction<String, String>) s -> Arrays.asList(SPACE.split(s)).iterator());
JavaPairDStream<String, Integer> pairDStream = dStream.mapToPair(new LogTuple());
JavaPairDStream<String, Integer> result = pairDStream.reduceByKey(new ReduceIsKey());
result.print();
}
}
无状态转化操作 JOIN连接
代码案例
//JOIN
JavaPairDStream<String, Integer> pairDStream1 = dStream.mapToPair(new LogTuple());
JavaPairDStream<String, Integer> result1 = pairDStream.reduceByKey(new ReduceIsKey());
JavaPairDStream<String,Tuple2<Integer,Integer>> c = result.join(result);
有状态转化操作
- Dstream的有状态转换操作是跨越时间区间跟踪数据的操作
- 为了实现旧批次的数据也可以在新批次中进行计算,sparkStreaming提供了两种方式
- 滑动窗口
- 以时间阶段为滑动窗口进行操作
- updateStateBykey()
- 追踪每个键的状态变化
- 滑动窗口
有状态转化操作:滑动窗口概念以及代码案例
-
滑动窗口我们先简单的理解,它就是整合多个批次处理结果,计算整个窗口的结果
-
那么所有基于滑动窗口的操作都需要两个参数
- 窗口时长:控制每次计算最近多少批次的数据
- 滑动步长:控制多少批次间隔进行窗口计算
-
如果我们的sparkStreaming设置的是10秒的执行间隔,然后我们要创建一个最近三批次的窗口时长,那么就是窗口时长就是30秒
-
然后我们希望每两个批次计算一次窗口结果,就把滑动步长设置为20秒
首先:有状态转化操作需要开启检查点[检查点在第十八章有解释]
代码案例
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("window").setMaster("local[2]");
JavaStreamingContext streamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(10));
//检查点设置
streamingContext.checkpoint("hdfs://localhost:9300");
JavaDStream<String> dStream = streamingContext.socketTextStream("localhost", 8080);
JavaDStream<String> winDstream = dStream.window(Durations.seconds(30), Durations.seconds(20));
JavaDStream<Long> result = winDstream.count();
}
可以看到window还是很简单的
但是我们上面的代码会存在这样的问题,我画个图给大家理解下
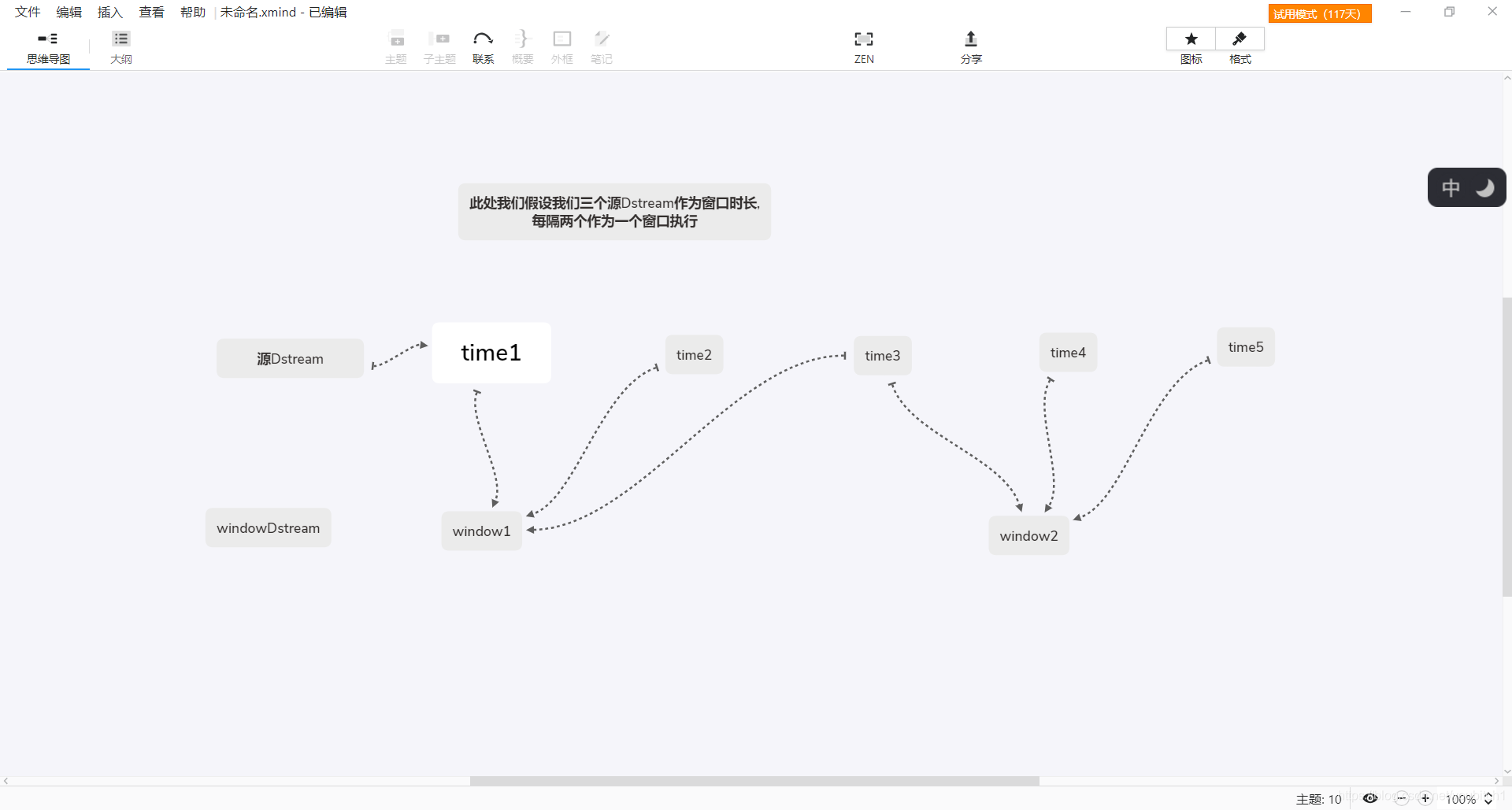
由于我们是三个dstream作为窗口时长,两个作为滑动步长,所以如图所示,两个窗口的统计部分会有重复dstream,所以spark提供了一些其他的窗口操作,让我们更高效的使用,比如:reduceByKeyAndWindow
reduceByKeyAndWindow 更高效的window操作
reduceByKeyAndWindow可以对每个窗口进行更高效的归约操作,它接收一个归约的函数,在整个窗口上执行
小科普:归约:指的是在尽可能保证数据原貌的前提下,最大限度的精简数据量
-
reduceByKeyAndWindow有一种特殊的形式,它只考虑新进入窗口的数据和离开窗口的数据.需要提供一个逆函数,说的通俗一些:我们刚才那个案例使用reduceByKeyAndWindow之后会变成这个样子
- window1 = time1+time2+time3
- window2 = window1+time4+time5 -time1-time2
-
通俗点说就是我们不需要重新获取或者计算,而是通过旧信息更新信息,这样既节省空间还节省内存
代码案例:
需求:计算每个IP地址的访问量
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
/**
* Created by 張燿峰
* reduceByKeyAndWindow的代码案例
* 计算每个IP地址的访问量
* @author 孤
* @date 2019/4/16
* @Varsion 1.0
*/
public class ReduceByKeyAndWindow {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("reduceByKeyAndWindow").setMaster("local[2]");
JavaStreamingContext streamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(10));
//检查点设置
streamingContext.checkpoint("hdfs://localhost:9300");
//数据源
JavaDStream<String> dStream = streamingContext.socketTextStream("localhost", 8080);
JavaPairDStream<String, Long> ipPairDstream = dStream.mapToPair(new GetIp());
JavaPairDStream<String, Long> result = ipPairDstream.reduceByKeyAndWindow(new AddLongs(),
new SubtractLongs(), Durations.seconds(30), Durations.seconds(10));
}
static class GetIp implements PairFunction<String, String, Long> {
@Override
public Tuple2<String, Long> call(String s) {
return new Tuple2<>(s, 1L);
}
}
/**
* 加上新进入窗口的批次元素
*/
static class AddLongs implements Function2<Long, Long, Long> {
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
}
/**
* 移除离开窗口的旧批次元素
*/
static class SubtractLongs implements Function2<Long, Long, Long> {
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 - v2;
}
}
}
除此之外,spark还提供了很多方便我们计算的函数
比如:countByWindow()或者countByValueAndWindow()
countByWindow…等等.还有很多
countByWindow()这个函数可以对每个滑动窗口的数据进行count()操作
代码案例
public static void countWindow(JavaDStream<String> javaDStream) {
JavaDStream ip = javaDStream.map((Function<String, Object>) v1 -> v1);
JavaDStream<Long> ipCount = ip.countByWindow(Durations.seconds(30), Durations.seconds(10));
JavaPairDStream<String, Long> ipAddressRequestCount = ip.countByValueAndWindow(Durations.seconds(30), Durations.seconds(10));
}
spark流处理的有状态/无状态 转化操作核心的点基本都写完啦














 863
863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









