










简述局部作用域,全局作用域和类作用域的异同
一个定义于某模块中的函数的全局作用域是该模块的命名空间,而不是该函数的别名被定义或调用的位置 虽然作用域是静态定义的,在使用时作用域是动态的。在任何运行时刻,总是恰好有三个作用域在使用中(即恰好有三个名字空间是直接可访问的):最内层的作用域,最先被搜索,包含局部名字;中层的作用域,其次被搜索,包含当前模块的全局名字;最外层的作用域最后被搜索,包含内置名字。 一般情况下,局部作用域引用当前函数的局部名字,其中局部是源程序文本意义上来看的。在函数外部,局部作用域与全局作用域使用相同的名字空间:模块的名字空间。类定义在局部作用域中又增加了另一个名字空间。 一定要注意作用域是按照源程序中的文本位置确定的:模块中定义的函数的全局作用域是模块的名字空间,不管这个函数是从哪里调用或者以什么名字调用的。另一方面,对名字的搜索却是在程序运行中动态进行的,不过,Python语言的定义也在演变,将来可能发展到静态名字解析,在“编译”时,所以不要依赖于动态名字解析!(实际上,局部名字已经是静态确定的了)。 类作用域包括类定义作用域和类实现作用域. 类的成员具有类作用域. 私有成员和受保护成员只能被类内部的成员函数访问, 公有成员是类提供给外部的接口, 可以在类外部被访问. 这种技术实现了信息的隐藏和封装.
4. 全局变量、局部变量和作用域 请点评
1、一个函数中定义的变量不能被另一个函数使用。例如print_time中的hour和minute在main函数中没有定义,不能使用,同样main函数中的局部变量也不能被print_time函数使用。如果这样定义:
void print_time(int hour, int minute) { printf("%d:%d\n", hour, minute); } int main(void) { int hour = 23, minute = 59; print_time(hour, minute); return 0; }
main函数中定义了局部变量hour,print_time函数中也有参数hour,虽然它们名称相同,但仍然是两个不同的变量,代表不同的存储单元。main函数的局部变量minute和print_time函数的参数minute也是如此。
2、每次调用函数时局部变量都表示不同的存储空间。局部变量在每次函数调用时分配存储空间,在每次函数返回时释放存储空间,例如调用print_time(23, 59)时分配hour和minute两个变量的存储空间,在里面分别存上23和59,函数返回时释放它们的存储空间,下次再调用print_time(12, 20)时又分配hour和minute的存储空间,在里面分别存上12和20。
例 3.5. 全局变量
#include <stdio.h>int hour = 23, minute = 59;void print_time(void){ printf("%d:%d in print_time\n", hour, minute);}int main(void){ print_time(); printf("%d:%d in main\n", hour, minute); return 0;}
正因为全局变量在任何函数中都可以访问,所以在程序运行过程中全局变量被读写的顺序从源代码中是看不出来的,源代码的书写顺序并不能反映函数的调用顺序。程序出现了Bug往往就是因为在某个不起眼的地方对全局变量的读写顺序不正确,如果代码规模很大,这种错误是很难找到的。而对局部变量的访问不仅局限在一个函数内部,而且局限在一次函数调用之中,从函数的源代码很容易看出访问的先后顺序是怎样的,所以比较容易找到Bug。因此,虽然全局变量用起来很方便,但一定要慎用,能用函数传参代替的就不要用全局变量。
如果全局变量和局部变量重名了会怎么样呢?如果上面的例子改为:
则第一次调用print_time打印的是全局变量的值,第二次直接调用printf打印的则是main函数局部变量的值。在C语言中每个标识符都有特定的作用域,全局变量是定义在所有函数体之外的标识符,它的作用域从定义的位置开始直到源文件结束,而main函数局部变量的作用域仅限于main函数之中。如上图所示,设想整个源文件是一张大纸,也就是全局变量的作用域,而main函数是盖在这张大纸上的一张小纸,也就是main函数局部变量的作用域。在小纸上用到标识符hour和minute时应该参考小纸上的定义,因为大纸(全局变量的作用域)被盖住了,如果在小纸上用到某个标识符却没有找到它的定义,那么再去翻看下面的大纸上有没有定义,例如上图中的变量x。
到目前为止我们在初始化一个变量时都是用常量做Initializer,其实也可以用表达式做Initializer,但要注意一点:局部变量可以用类型相符的任意表达式来初始化,而全局变量只能用常量表达式(Constant Expression)初始化。例如,全局变量pi这样初始化是合法的:
double pi = 3.14 + 0.0016;
但这样初始化是不合法的:
double pi = acos(-1.0);
然而局部变量这样初始化却是可以的。程序开始运行时要用适当的值来初始化全局变量,所以初始值必须保存在编译生成的可执行文件中,因此初始值在编译时就要计算出来,然而上面第二种Initializer的值必须在程序运行时调用acos函数才能得到,所以不能用来初始化全局变量。请注意区分编译时和运行时这两个概念。为了简化编译器的实现,C语言从语法上规定全局变量只能用常量表达式来初始化,因此下面这种全局变量初始化是不合法的:
int minute = 360; int hour = minute / 60;
虽然在编译时计算出hour的初始值是可能的,但是minute / 60不是常量表达式,不符合语法规定,所以编译器不必想办法去算这个初始值。
如果全局变量在定义时不初始化则初始值是0,如果局部变量在定义时不初始化则初始值是不确定的。所以,局部变量在使用之前一定要先赋值,如果基于一个不确定的值做后续计算肯定会引入Bug。
如何证明“局部变量的存储空间在每次函数调用时分配,在函数返回时释放”?当我们想要确认某些语法规则时,可以查教材,也可以查C99,但最快捷的办法就是编个小程序验证一下:
例 3.7. 验证局部变量存储空间的分配和释放
#include <stdio.h>void foo(void){ int i; printf("%d\n", i); i = 777;}int main(void){ foo(); foo(); return 0;}
第一次调用foo函数,分配变量i的存储空间,然后打印i的值,由于i未初始化,打印的应该是一个不确定的值,然后把i赋值为777,函数返回,释放i的存储空间。第二次调用foo函数,分配变量i的存储空间,然后打印i的值,由于i未初始化,如果打印的又是一个不确定的值,就证明了“局部变量的存储空间在每次函数调用时分配,在函数返回时释放”。分析完了,我们运行程序看看是不是像我们分析的这样:
134518128 777
结果出乎意料,第二次调用打印的i值正是第一次调用末尾赋给i的值777。有一种初学者是这样,原本就没有把这条语法规则记牢,或者对自己的记忆力没信心,看到这个结果就会想:哦那肯定是我记错了,改过来记吧,应该是“函数中的局部变量具有一直存在的固定的存储空间,每次函数调用时使用它,返回时也不释放,再次调用函数时它应该还能保持上次的值”。还有一种初学者是怀疑论者或不可知论者,看到这个结果就会想:教材上明明说“局部变量的存储空间在每次函数调用时分配,在函数返回时释放”,那一定是教材写错了,教材也是人写的,是人写的就难免出错,哦,连C99也这么写的啊,C99也是人写的,也难免出错,或者C99也许没错,但是反正运行结果就是错了,计算机这东西真靠不住,太容易受电磁干扰和宇宙射线影响了,我的程序写得再正确也有可能被干扰得不能正确运行。
这是初学者最常见的两种心态。不从客观事实和逻辑推理出发分析问题的真正原因,而仅凭主观臆断胡乱给问题定性,“说你有罪你就有罪”。先不要胡乱怀疑,我们再做一次实验,在两次foo函数调用之间插一个别的函数调用,结果就大不相同了:
int main(void) { foo(); printf("hello\n"); foo(); return 0; }
结果是:
134518200 hello 0
这一回,第二次调用foo打印的i值又不是777了而是0,“局部变量的存储空间在每次函数调用时分配,在函数返回时释放”这个结论似乎对了,但另一个结论又不对了:全局变量不初始化才是0啊,不是说“局部变量不初始化则初值不确定”吗?
关键的一点是,我说“初值不确定”,有没有说这个不确定值不能是0?有没有说这个不确定值不能是上次调用赋的值?在这里“不确定”的准确含义是:每次调用这个函数时局部变量的初值可能不一样,运行环境不同,函数的调用次序不同,都会影响到局部变量的初值。在运用逻辑推理时一定要注意,不要把必要条件(Necessary Condition)当充分条件(Sufficient Condition),这一点在Debug时尤其重要,看到错误现象不要轻易断定原因是什么,一定要考虑再三,找出它的真正原因。例如,不要看到第二次调用打印777就下结论“函数中的局部变量具有一直存在的固定的存储空间,每次函数调用时使用它,返回时也不释放,再次调用函数时它应该还能保持上次的值”,这个结论倒是能推出777这个结果,但反过来由777这个结果却不能推出这样的结论。所以说777这个结果是该结论的必要条件,但不是充分条件。也不要看到第二次调用打印0就断定“局部变量未初始化则初值为0”,0这个结果是该结论的必要条件,但也不是充分条件。至于为什么会有这些现象,为什么这个不确定的值刚好是777,或者刚好是0,等学到例 19.1 “研究函数的调用过程”就能解释这些现象了。
从第 2 节 “自定义函数”介绍的语法规则可以看出,非定义的函数声明也可以写在局部作用域中,例如:
int main(void) { void print_time(int, int); print_time(23, 59); return 0; }
这样声明的标识符print_time具有局部作用域,只在main函数中是有效的函数名,出了main函数就不存在print_time这个标识符了。
写非定义的函数声明时参数可以只写类型而不起名,例如上面代码中的void print_time(int, int);,只要告诉编译器参数类型是什么,编译器就能为print_time(23, 59)函数调用生成正确的指令。另外注意,虽然在一个函数体中可以声明另一个函数,但不能定义另一个函数,C语言不允许嵌套定义函数[5]。
1.C++变量根据定义的位置的不同的生命周期,具有不同的作用域,作用域可分为6种:
全局作用域,局部作用域,语句作用域,类作用域,命名空间作用域和文件作用域。
从作用域看:
1>全局变量具有全局作用域。全局变量只需在一个源文件中定义,就可以作用于所有的源文件。当然,其他不包含全局变量定义的源文件需要用extern 关键字再次声明这个全局变量。
2>静态局部变量具有局部作用域,它只被初始化一次,自从第一次被初始化直到程序运行结束都一直存在,它和全局变量的区别在于全局变量对所有的函数都是可见的,而静态局部变量只对定义自己的函数体始终可见。
3>局部变量也只有局部作用域,它是自动对象(auto),它在程序运行期间不是一直存在,而是只在函数执行期间存在,函数的一次调用执行结束后,变量被撤销,其所占用的内存也被收回。
4>静态全局变量也具有全局作用域,它与全局变量的区别在于如果程序包含多个文件的话,它作用于定义它的文件里,不能作用到其它文件里,即被static关键字修饰过的变量具有文件作用域。这样即使两个不同的源文件都定义了相同名字的静态全局变量,它们也是不同的变量。
2.从分配内存空间看:
1>全局变量,静态局部变量,静态全局变量都在静态存储区分配空间,而局部变量在栈里分配空间
2>全局变量本身就是静态存储方式, 静态全局变量当然也是静态存储方式。这两者在存储方式上并无不同。这两者的区别虽在于非静态全局变量的作用域是整个源程序,当一个源程序由多个源文件组成时,非静态的全局变量在各个源文件中都是有效的。而静态全局变量则限制了其作用域,即只在定义该变量的源文件内有效,在同一源程序的其它源文件中不能使用它。由于静态全局变量的作用域局限于一个源文件内,只能为该源文件内的函数公用,因此可以避免在其它源文件中引起错误。
1)静态变量会被放在程序的静态数据存储区(全局可见)中,这样可以在下一次调用的时候还可以保持原来的赋值。这一点是它与堆栈变量和堆变量的区别。
2)变量用static告知编译器,自己仅仅在变量的作用范围内可见。这一点是它与全局变量的区别。
从以上分析可以看出, 把局部变量改变为静态变量后是改变了它的存储方式即改变了它的生存期。把全局变量改变为静态变量后是改变了它的作用域,限制了它的使用范围。因此static 这个说明符在不同的地方所起的作用是不同的。应予以注意。
Tips:
A.若全局变量仅在单个C文件中访问,则可以将这个变量修改为静态全局变量,以降低模块间的耦合度;
B.若全局变量仅由单个函数访问,则可以将这个变量改为该函数的静态局部变量,以降低模块间的耦合度;
C.设计和使用访问动态全局变量、静态全局变量、静态局部变量的函数时,需要考虑重入问题,因为他们都放在静态数据存储区,全局可见;
D.如果我们需要一个可重入的函数,那么,我们一定要避免函数中使用static变量(这样的函数被称为:带“内部存储器”功能的的函数)
E.函数中必须要使用static变量情况:比如当某函数的返回值为指针类型时,则必须是static的局部变量的地址作为返回值,若为auto类型,则返回为错指针。
一.前言
1.编译器优化介绍:
由于内存访问速度远不及CPU处理速度,为提高机器整体性能,在硬件上引入硬件高速缓存Cache,加速对内存的访问。另外在现代CPU中指令的执行并不一定严格按照顺序执行,没有相关性的指令可以乱序执行,以充分利用CPU的指令流水线,提高执行速度。以上是硬件级别的优化。再看软件一级的优化:一种是在编写代码时由程序员优化,另一种是由编译器进行优化。编译器优化常用的方法有:将内存变量缓存到寄存器;调整指令顺序充分利用CPU指令流水线,常见的是重新排序读写指令。对常规内存进行优化的时候,这些优化是透明的,而且效率很好。由编译器优化或者硬件重新排序引起的问题的解决办法是在从硬件(或者其他处理器)的角度看必须以特定顺序执行的操作之间设置内存屏障(memory barrier),linux 提供了一个宏解决编译器的执行顺序问题。
void Barrier(void)
这个函数通知编译器插入一个内存屏障,但对硬件无效,编译后的代码会把当前CPU寄存器中的所有修改过的数值存入内存,需要这些数据的时候再重新从内存中读出。
2.volatile总是与优化有关,编译器有一种技术叫做数据流分析,分析程序中的变量在哪里赋值、在哪里使用、在哪里失效,分析结果可以用于常量合并,常量传播等优化,进一步可以消除一些代码。但有时这些优化不是程序所需要的,这时可以用volatile关键字禁止做这些优化。
二.volatile详解:
1.volatile的本意是“易变的” 因为访问寄存器要比访问内存单元快的多,所以编译器一般都会作减少存取内存的优化,但有可能会读脏数据。当要求使用volatile声明变量值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。精确地说就是,遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问;如果不使用valatile,则编译器将对所声明的语句进行优化。(简洁的说就是:volatile关键词影响编译器编译的结果,用volatile声明的变量表示该变量随时可能发生变化,与该变量有关的运算,不要进行编译优化,以免出错)
2.看两个事例:
1>告诉compiler不能做任何优化
比如要往某一地址送两指令:
int *ip =...; //设备地址
*ip = 1; //第一个指令
*ip = 2; //第二个指令
以上程序compiler可能做优化而成:
int *ip = ...;
*ip = 2;
结果第一个指令丢失。如果用volatile, compiler就不允许做任何的优化,从而保证程序的原意:
volatile int *ip = ...;
*ip = 1;
*ip = 2;
即使你要compiler做优化,它也不会把两次付值语句间化为一。它只能做其它的优化。
2>用volatile定义的变量会在程序外被改变,每次都必须从内存中读取,而不能重复使用放在cache或寄存器中的备份。
例如:
volatile char a;
a=0;
while(!a){
//do some things;
}
doother();
如果没有 volatiledoother()不会被执行
3.下面是使用volatile变量的几个场景:
1>中断服务程序中修改的供其它程序检测的变量需要加volatile;
例如:
static int i=0;
int main(void)
{
...
while (1){
if (i) dosomething();
}
}
/* Interrupt service routine. */
void ISR_2(void)
{
i=1;
}
程序的本意是希望ISR_2中断产生时,在main函数中调用dosomething函数,但是,由于编译器判断在main函数里面没有修改过i,因此可能只执行一次对从i到某寄存器的读操作,然后每次if判断都只使用这个寄存器里面的“i副本”,导致dosomething永远也不会被调用。如果将变量加上volatile修饰,则编译器保证对此变量的读写操作都不会被优化(肯定执行)。此例中i也应该如此说明。
2>多任务环境下各任务间共享的标志应该加volatile
3>存储器映射的硬件寄存器通常也要加voliate,因为每次对它的读写都可能有不同意义。
例如:
假设要对一个设备进行初始化,此设备的某一个寄存器为0xff800000。
int *output = (unsigned int *)0xff800000;//定义一个IO端口;
int init(void)
{
int i;
for(i=0;i< 10;i++){
*output = i;
}
}
经过编译器优化后,编译器认为前面循环半天都是废话,对最后的结果毫无影响,因为最终只是将output这个指针赋值为9,所以编译器最后给你编译编译的代码结果相当于:
int init(void)
{
*output = 9;
}
如果你对此外部设备进行初始化的过程是必须是像上面代码一样顺序的对其赋值,显然优化过程并不能达到目的。反之如果你不是对此端口反复写操作,而是反复读操作,其结果是一样的,编译器在优化后,也许你的代码对此地址的读操作只做了一次。然而从代码角度看是没有任何问题的。这时候就该使用volatile通知编译器这个变量是一个不稳定的,在遇到此变量时候不要优化。
例如:
volatile int *output=(volatile unsigned int *)0xff800000;//定义一个I/O端口
另外,以上这几种情况经常还要同时考虑数据的完整性(相互关联的几个标志读了一半被打断了重写),在1中可以通过关中断来实现,2中禁止任务调度,3中则只能依靠硬件的良好设计。
4.几个问题
1)一个参数既可以是const还可以是volatile吗?
可以的,例如只读的状态寄存器。它是volatile因为它可能被意想不到地改变。它是const因为程序不应该试图去修改它。
2) 一个指针可以是volatile 吗?
可以,当一个中服务子程序修该一个指向一个buffer的指针时。
5.volatile的本质:
1> 编译器的优化
在本次线程内, 当读取一个变量时,为提高存取速度,编译器优化时有时会先把变量读取到一个寄存器中;以后,再取变量值时,就直接从寄存器中取值;当变量值在本线程里改变时,会同时把变量的新值copy到该寄存器中,以便保持一致。
当变量在因别的线程等而改变了值,该寄存器的值不会相应改变,从而造成应用程序读取的值和实际的变量值不一致。
当该寄存器在因别的线程等而改变了值,原变量的值不会改变,从而造成应用程序读取的值和实际的变量值不一致。
2>volatile应该解释为“直接存取原始内存地址”比较合适,“易变的”这种解释简直有点误导人。
6.下面的函数有什么错误:
int square(volatile int *ptr)
{
return *ptr * *ptr;
}
该程序的目的是用来返指针*ptr指向值的平方,但是,由于*ptr指向一个volatile型参数,编译器将产生类似下面的代码:
int square(volatile int *ptr)
{
int a,b;
a = *ptr;
b = *ptr;
return a * b;
}
由于*ptr的值可能被意想不到地该变,因此a和b可能是不同的。结果,这段代码可能返不是你所期望的平方值!正确的代码如下:
long square(volatile int *ptr)
{
int a;
a = *ptr;
return a * a;
}
注意:频繁地使用volatile很可能会增加代码尺寸和降低性能,因此要合理的使用volatile。
1.先看程序:
#include<stdio.h>
char *returnStr()
{
char *p = “tigerjibo”;
return p;
}
int main()
{
char*str;
str =returnStr();
//str[0]=’T’;则会引起错误,不能修改只读数据段中的内容
printf(“%s\n”,str);
return0;
}
来分析下该程序。
(1)char *p = “tigerjibo”。系统在栈上分配四个字节的空间存放p的数值。“tigerjibo”是字符常量,存放在只读数据段内。指向完后,系统把”tigerjibo”的地址赋值给p。
(2)函数用return 把p的数值返回。该数值指向只读数据段(该数据段内的数据是静态的不会改变)。退出子函数后,系统把p的数值销毁。但是p的数值已经通过return 返回。且只读数据段中的内容不会被修改和回收(其输于静态区域)
(3)在主程序中把该地址又给了str。因此str指向了“tigerjbo”。
(4)该程序虽然能运行,担又一个缺点,就是在程序中不能修改字符常常量中的数值。如果修改会引起段错误。
2.先看程序
#include<stdio.h>
char *returnStr()
{
char p[]=”tigerjibo”;
return p;
}
int main()
{
char *str;
str =returStr();
printf(“%s\n”,str);
}
编译该程序后,系统会提示如下警告:
function returns address of local variable
(函数返回一个可变地址)
分析该错误:
1>”tigerjibo”是一个字符常量,存放在只读数据段中,是不能被修改的。
2>char p[],是一个局部变量,当函数被调用时,在栈上开辟一个空间来存放数组P的内容。
3>char p[]=”tigerjibo”,该语句是把”tigerjibo”的值赋值给数值P,存放在数组p地址处。而不是把”tigerjibo”的地址赋值给数组p。因此,“tigerjibo”此时在系统中有一处备份,一个在只读数据段中(不能修改,内容也不会被回收),一个在栈上存储(可以修改起内容,但函数退出后,其栈上存储的内容也会被回收)。
4>因此,当return p,返回了数组的首地址,但是当函数退出后,其栈上的内容也将被丢弃,局部变量的内存也被清空了,因此该数组首地址处的内容是一个可变的值。
3.先看一个程序:
#include<stdio.h>
char *returnStr()
{
static char p[]=”tigerjibo”;
return p;
}
int main()
{
char *str;
str =returnStr();
str[0]=’T’;
printf(“%s\n”,str);
}
此程序运行正确。
分析如下:
1>”tigerjibo”是一个字符常量,存放在只读数据段中,是不能被修改的。
2>static char p[],是一个静态局部变量,在读写数据段中开辟一个空间给p用来存放其数值。
3>static char p[]=”tigerjibo”,该语句是把”tigerjibo”的值赋值给数值P,存放在数组p地址处。而不是把”tigerjibo”的地址赋值给数组p。因此,“tigerjibo”此时在系统中有一处备份,一个在只读数据段中(不能修改,内容也不会被回收),一个在读写数据段中存储(可以修改其内容,当函数退出后,因其在读写数据段中存储,起内容不会被丢弃)。
4>因此,当return p,返回了数组的首地址,但是当函数退出后,虽然栈上的内容都清除了,但是p地址是读写数据段中的地址,其上的内容不会被回收。
4.先看一个程序:
#include<stdio.h>
#include<string.h>
#include<strdlib.h>
void getmemory(char *p)
{
p = (char *)malloc(100);
}
int main()
{
char *str=NULL;
getmemory(str);
strcpy(str,”helloworld”);
printf(“%s\n”,str);
}
编译后错误:
段错误
分析:在主程序中,str地址为空。在函数传递中将str的地址传给了子函数中的指针p(是拷贝了一份),然后在字函数中给p在堆上申请了一个100字节的空间,并把首地址赋值给p。但是函数传递中,p值改变不会影响到主函数中str的值。因此,str的地址仍为空。在strcpy中引用空指针会出现段错误。
十五章 存储类型、作用域、可见性和生存期
上一章我们讲了“程序的文件结构”。主要涉及到一个问题,即:A文件中定义的某个变量,如果在B文件也能使用它。其间我们学到一个新关键字:extern,它用来声明一个变量,并且指明这是一个“外来的”的变量。如果你对我说的这些感到陌生,那么你先复习一下上一章。
这一章,我们正是要从extern说起。
15.1 存储类型
存储类型分“外部存储”和“静态存储”两种。
15.1.1 外部存储
外部存储类型使用 extern 关键字表示。
上一章我们其实一直在用外部存储类型的变量。
一个全局变量或函数,如果你需要在其它源文件中可以共用到,那么你必须将它声明为“外部存储类型”。这其实就是上一章我们所讲的内容。这里再举个例子,简要复述一次。
在A.cpp 文件中,有一个全局变量 a,和一个函数: func();
//A.cpp 文件:
...
int a;
void func()
{
...
}
...
我们希望在B.cpp 或更多其它文件可以使用到变量a和函数func(),必须在“合适的位置”声明二者:
//B.cpp 文件:
...
extern int a; //a 由另一源文件(A.cpp)定义
extern void func(); //func 由另一源文件(A.cpp)定义
a = 100;
func();
...
这里例子中,“合适的位置”是在B.cpp文件里。其它合适的位置,比如在头文件里的例子,请复习上一章。
另外一点需要得强调一次:函数的定义默认就是外部的,所以上面 func()之前的extern也可以省略。
在使用extern 声明全局变量或函数时,一定要注意:所声明的变量或函数必须在,且仅在一个源文件中实现定义。
如果你的程序声明了一个外部变量,但却没有在任何源文件中定义它,程序将可以通编译,但无法链接通过。下面是该错误类型的一个例子,大家请打开CB,将下面代码写入完整的一个控制台工程。
错误一、只有声明,没有定义:
1、用CB新建一个空白控制台工程,CB将自动生成Unit1.cpp。加入以下黑体部分:
extern void func2();
int main(int argc, char* argv[])
{
func2();
return 0;
}
2、新建一个单元文件(菜单:New | Unit):Unit2.cpp。在Unit2.cpp后面加入:
extern int a; //a 由另一源文件(A.cpp)定义
extern void func(); //func 由另一源文件(A.cpp)定义
void func2()
{
a = 100;
func();
}
现在按Ctrl + F9,将出现以下错误:
 [Linker Error] 表明这是一个“链接”错误。两个错误分别是说变量a和函数func()没有定义。
(你可能奇怪为什么错误消息里,变量'a'的名字变成了'_a'?这是编译器遵循某些标准,在编译结果上对变量名做了一些改变,我们不必理会)
请大家想一想,并试一试,如何解决这两个链接错误。
错误二、有声明,但重复定义
1、用CB新建一个空白控制台工程,CB将自动生成Unit1.cpp。加入以下黑体部分:
extern void func2();
int a; // <--全局变量a在此定义了一次
void func() // <--函数func()在此定义了一次
{
a = 20;
}
int main(int argc, char* argv[])
{
func2();
return 0;
}
2、和错误一的第2步完全一样:
extern int a; //a 由另一源文件(A.cpp)定义
extern void func(); //func 由另一源文件(A.cpp)定义
void func2()
{
a = 100;
func();
}
3、再新建一个单元文件:Unit3.cpp,在文件后加入:
int a; // <--全局变量a在此又定义了一次
void func() // <--函数func()在此又定义了一次
{
a = 20;
}
现在编译这个含有三个单元文件的工程。这回答的是一个链接“警告/Warning”:
[Linker Error] 表明这是一个“链接”错误。两个错误分别是说变量a和函数func()没有定义。
(你可能奇怪为什么错误消息里,变量'a'的名字变成了'_a'?这是编译器遵循某些标准,在编译结果上对变量名做了一些改变,我们不必理会)
请大家想一想,并试一试,如何解决这两个链接错误。
错误二、有声明,但重复定义
1、用CB新建一个空白控制台工程,CB将自动生成Unit1.cpp。加入以下黑体部分:
extern void func2();
int a; // <--全局变量a在此定义了一次
void func() // <--函数func()在此定义了一次
{
a = 20;
}
int main(int argc, char* argv[])
{
func2();
return 0;
}
2、和错误一的第2步完全一样:
extern int a; //a 由另一源文件(A.cpp)定义
extern void func(); //func 由另一源文件(A.cpp)定义
void func2()
{
a = 100;
func();
}
3、再新建一个单元文件:Unit3.cpp,在文件后加入:
int a; // <--全局变量a在此又定义了一次
void func() // <--函数func()在此又定义了一次
{
a = 20;
}
现在编译这个含有三个单元文件的工程。这回答的是一个链接“警告/Warning”:
 警告很长,无非是说全局变量 'a' 在两个模块内重复定义。 对了,func()函数我们不是也重复定义了吗?为什么没有得到警告?这是因为CB对重复定义的函数,将只取其一,然后自动抛弃所有重复项。下面的操作可以看到这一结果。
既然是错误类型只是“警告”,那就是说我们可以硬下心肠不管,继续运行。我们现在来看看,两个func()函数,CB到底用了哪一个?
这里需要在运行前,在两个func()的函数定义处,都设置断点:
第一个断点:在Unit1.cpp 文件里:
警告很长,无非是说全局变量 'a' 在两个模块内重复定义。 对了,func()函数我们不是也重复定义了吗?为什么没有得到警告?这是因为CB对重复定义的函数,将只取其一,然后自动抛弃所有重复项。下面的操作可以看到这一结果。
既然是错误类型只是“警告”,那就是说我们可以硬下心肠不管,继续运行。我们现在来看看,两个func()函数,CB到底用了哪一个?
这里需要在运行前,在两个func()的函数定义处,都设置断点:
第一个断点:在Unit1.cpp 文件里:
 第二个断点:在Unit3.cpp 文件里:
第二个断点:在Unit3.cpp 文件里:
 然后按F9,运行,我们看到断点停在 Unit1.cpp中的 func()定义上:
然后按F9,运行,我们看到断点停在 Unit1.cpp中的 func()定义上:
 而另一处:Unit3.cpp 里的断点,变“黄”(无效断点)了:
而另一处:Unit3.cpp 里的断点,变“黄”(无效断点)了:
 之所以成为无效断点,有两种原因:
其一是某些代码,比如单纯的变量声明:int a; 或如宏定义等,这些代码在编译后成为程序的初始化部分,无需运行。
其二是某些无用,或可优化的代码中编译过程被丢弃。
这里正是第二种情况。
尽管变量或函数重复定义似乎并不造成“致命”错误,但我们同样需要严加注意,消除所有这类错误。请大家对本例进行改错。
之所以成为无效断点,有两种原因:
其一是某些代码,比如单纯的变量声明:int a; 或如宏定义等,这些代码在编译后成为程序的初始化部分,无需运行。
其二是某些无用,或可优化的代码中编译过程被丢弃。
这里正是第二种情况。
尽管变量或函数重复定义似乎并不造成“致命”错误,但我们同样需要严加注意,消除所有这类错误。请大家对本例进行改错。
15.1.2 静态存储类型
静态存储类型使用 static 关键字表示。
static 关键限定其所修饰的全局变量或函数只能在当前源文件中使用。
反过来说,如果我们确定某个全局变量仅仅是在当前源文件中使用,我们可以限定它为静态存储类型。
static 的使用格式 :
static 变量定义或函数定义
如:
static int a;
static void func();
举一个例子,下面的代码可以正确编译、运行:
Unit1.cpp 文件:
...
extern int a;
int main(int argc, char* argv[])
{
a = 100;
return 0;
}
Unit2.cpp 文件:
...
int a;
说明:在Unit1.cpp 文件中用到了外部变量:a, a在Unit2.cpp文件内定义。
现在,我们要限定 Unit2.cpp 里的变量 a 只能在 Unit2.cpp 内可以使用:
Unit2.cpp 文件:
...
static int a;
我们为 a 的定义加了一个修饰:static。现在再编译,编译器提示一个链接错误,我们在本章前面说过的:“变量 a 没有定义”:
 静态函数的例子类似:
Unit1.cpp 文件:
...
void func();
int main(int argc, char* argv[])
{
func();
return 0;
}
Unit2.cpp 文件:
int i;
static void func()
{
i = 100;
}
按Ctrl+F9,得到以下链接错误:
静态函数的例子类似:
Unit1.cpp 文件:
...
void func();
int main(int argc, char* argv[])
{
func();
return 0;
}
Unit2.cpp 文件:
int i;
static void func()
{
i = 100;
}
按Ctrl+F9,得到以下链接错误:
 又是两个制造错误例子,不要偷懒,务必亲手制造出这两个错误,并且再改正后,才继续看下面的课程。千万不要仅满足于“看得懂”就不动手。那样绝对不可能学会编程。
static 还有一种用法,称为函数局部静态变量,作用和这里的“全局静态”关系不大,我们在后面的“生存期”中会讲到。
由于静态变量或静态函数只在当前文件(定义它的文件)中有效,所以我们完全可以在多个文件中,定义两个或多个同名的静态变量或函数。
比如在A文件和B文件中分别定义两个静态变量a:
A文件中:
static int a;
B文件中:
static int a;
这两个变量完全独立,之间没有任何关系,占用各自的内存地址。你在A文件中改a的值,不会影响B文件中那个a的值。
又是两个制造错误例子,不要偷懒,务必亲手制造出这两个错误,并且再改正后,才继续看下面的课程。千万不要仅满足于“看得懂”就不动手。那样绝对不可能学会编程。
static 还有一种用法,称为函数局部静态变量,作用和这里的“全局静态”关系不大,我们在后面的“生存期”中会讲到。
由于静态变量或静态函数只在当前文件(定义它的文件)中有效,所以我们完全可以在多个文件中,定义两个或多个同名的静态变量或函数。
比如在A文件和B文件中分别定义两个静态变量a:
A文件中:
static int a;
B文件中:
static int a;
这两个变量完全独立,之间没有任何关系,占用各自的内存地址。你在A文件中改a的值,不会影响B文件中那个a的值。
15.2 作用域和可见性
作用域和可见性可以说是对一个问题的两种角度的思考。
“域”,就是范围;而“作用”,应理解为“起作用”,也可称为“有效”。所以作用域就是讲一个变量或函数在代码中起作用的范围,或者说,一个变量或函数的“有效范围”。打个比方,就像枪发出的子弹,有一定的射程,出了这个射程,就是出了子弹的“有效”范围,这颗子弹就失去了作用。
代码中的变量或函数,有的可以在整个程序中的所有范围内起作用,这称为“全局”的变量或函数。而有的只能在一定的范围内起作用,称为“局部”变量。
15.2.1 局部作用域
我们在 5.1.3 “如何为变量命名”这一小节中讲到: “不能在同一作用范围内有同名变量”。因此,下面的代码是错误的:
...
int a; //第一次定义a
int b;
b = 2*a;
int a; //错误:又定义了一次a
...
那么,在什么情况下,变量属于不同的作用范围呢?我们这里说的是第一种:一对{}括起来的代码范围,属于一个局部作用域。如果这个局部作用域包含更小的子作用域,那么子作用域的具有较高的优先级。在一个局部作用域内,变量或函数从其声明或定义的位置开始,一直作用到该作用域结束为止。
例一:变量只在其作用域内有效
void func()
{
int a;
a = 100;
cout << a << endl; //输出a的值
}
int main(int argc, char* argv[])
{
cout << a << endl; // <-- 错误: 变量a未定义
return 0;
}
说明:在函数 func()中,我们定义了变量a,但这个变量的“作用域”在 } 之前停止。所以,出了花括号以后,变量a就不存在了。请看图示:
 结论:在局部作用域内定义的变量,其有效范围从它定义的行开始,一直到该局部作用域结束。
在局部作用域内定义的变量,称为“局部变量”。
上例中的局部作用域是一个函数。其它什么地方我们还能用到{}呢?很多,所有使用到复合语句的地方,比如:
//if 语句
if( i> j)
{
int a;
... ...
}
上面的a是一个局部变量,处在的if语句所带的那对 {} 之内。
//for 语句:
for(int i=0;i<100;i++)
{
int a;
... ...
}
上面的a也是一个局部变量。处在for语句带的{}之内。
for 语句涉及局部作用域时,有一点需要特别注意:上面代码中,变量 i 的作用域是什么?
根据最新的 ANSI C++ 规定,在for的初始语句中声明的变量,其作用范围是从它定义的位置开始,一直到for所带语句的作用域结束。而原来老的标准是出了for语句仍然有效,直到for语句外层的局部作用域结束。请看对比:
假设有一for语句,它的外层是一个函数。新老标准规定的不同作用域对比如下:
结论:在局部作用域内定义的变量,其有效范围从它定义的行开始,一直到该局部作用域结束。
在局部作用域内定义的变量,称为“局部变量”。
上例中的局部作用域是一个函数。其它什么地方我们还能用到{}呢?很多,所有使用到复合语句的地方,比如:
//if 语句
if( i> j)
{
int a;
... ...
}
上面的a是一个局部变量,处在的if语句所带的那对 {} 之内。
//for 语句:
for(int i=0;i<100;i++)
{
int a;
... ...
}
上面的a也是一个局部变量。处在for语句带的{}之内。
for 语句涉及局部作用域时,有一点需要特别注意:上面代码中,变量 i 的作用域是什么?
根据最新的 ANSI C++ 规定,在for的初始语句中声明的变量,其作用范围是从它定义的位置开始,一直到for所带语句的作用域结束。而原来老的标准是出了for语句仍然有效,直到for语句外层的局部作用域结束。请看对比:
假设有一for语句,它的外层是一个函数。新老标准规定的不同作用域对比如下:
 如果按照旧标准,下面的代码将有错,但对新标准,则是正确的,请大家考虑为什么:
void func()
{
for(int i=0;i<9;i++)
{
cout << i << endl;
}
for(int i=9;i>0;i--) //<-- 在这一行,旧标准的编译器将报错,为什么?
{
cout << i << endl;
}
}
Borland C++ Builder 对新旧标准都可支持,只需通过工程中的编译设置来设置采用何种标准。默认总是采用新标准。记住:如果你在代码中偶尔有需要旧标准要求的效果,你只需把代码码写成这样:
int i;
for(i=0;i<9;i++)
{
...
}
这时候,i的作用域就将从其定义行开始,一直越过整个for语句。
其它还有不少能用到复合语句(一对{}所括起的语句组)的流程控制语句,如do..while等。请复习以前相关课程。
其实,就算没有流程控制语句,我们也可以根据需要,在代码中直接加上一对{},人为地制造一个“局部作用域”。比如在某个函数中:
void func()
{
int a = 100;
cout << a << endl;
{
int a = 200;
cout << a << endl;
}
cout << a << endl;
}
代码中红色部分即是我们制造的一个局部作用域。执行该函数,将有如下输出:
100
200
100
你能理解吗?
如果按照旧标准,下面的代码将有错,但对新标准,则是正确的,请大家考虑为什么:
void func()
{
for(int i=0;i<9;i++)
{
cout << i << endl;
}
for(int i=9;i>0;i--) //<-- 在这一行,旧标准的编译器将报错,为什么?
{
cout << i << endl;
}
}
Borland C++ Builder 对新旧标准都可支持,只需通过工程中的编译设置来设置采用何种标准。默认总是采用新标准。记住:如果你在代码中偶尔有需要旧标准要求的效果,你只需把代码码写成这样:
int i;
for(i=0;i<9;i++)
{
...
}
这时候,i的作用域就将从其定义行开始,一直越过整个for语句。
其它还有不少能用到复合语句(一对{}所括起的语句组)的流程控制语句,如do..while等。请复习以前相关课程。
其实,就算没有流程控制语句,我们也可以根据需要,在代码中直接加上一对{},人为地制造一个“局部作用域”。比如在某个函数中:
void func()
{
int a = 100;
cout << a << endl;
{
int a = 200;
cout << a << endl;
}
cout << a << endl;
}
代码中红色部分即是我们制造的一个局部作用域。执行该函数,将有如下输出:
100
200
100
你能理解吗?
15.2.2 全局作用域 和 域操作符
如果一个变量声明或定义不在任何局部作用域之内,该变量称为全局变量。同样,一个函数声明不处于任何局部作用域内,则该函数是全局函数。
一个全局变量从它声明或定义的行起,将一起直接作用到源文件的结束。
请看下例:
//设有文件 Unit1.cpp,内定义一个全局变量:
int a = 100;
void func()
{
cout << a << endl;
}
输出:
100
我们今天还要学习到一个新的操作符,域操作符 “::”。域操作符也称“名字空间操作符”,由于我们还没学到“名字空间”,所以这里重点在于它在全局作用域上的使用方法。
:: 域操作符,它要求编译器将其所修饰的变量或函数看成全局的。反过来说,当编译器遇到一个使用::修饰的变量或函数时,编译器仅从全局的范围内查找该变量的定义。
下面讲到作用域的嵌套时,你可以进一步理解全局作用域如何起作用,同时,下例也是我们实例演示如何使用域作用符::的好地方。
15.2.3 作用域嵌套及可见性
例二:嵌套的两个作用域
在例一的基础上,我增加一个全局变量:
int a = 0; //<-- 全局变量,并且初始化为0
void func()
{
int a;
a = 100;
cout << a << endl; //输出a的值
}
int main(int argc, char* argv[])
{
cout << a << endl; //输出a的值
}
我们在 5.1.3 “如何为变量命名”这一小节中讲到: “不能在同一作用范围内有同名变量”。 上面的代码中,定义了两个a,但并不违反这一规则。因为二者处于不同的作用范围内。下图标明了两个a的不同作用范围:
 从图示中看到:两个变量a:1个为全局变量,一个为局部变量。前者的作用域包含了后者的作用域。这称为作用域的嵌套。
如果在多层的作用域里,有变量同名,那么内层的变量起作用,而外层的同名变量暂时失去作用。比如在上例中,当代码执行到①处时,所输出的是函数 func()内的a。而代码②处,输出的是全局变量a。
这就引出一个“可见性”这个词,当内层的变量和外层的变量同名时,在内层里,外层的变量暂时地失去了可见性。
不过,如果外层是全局作用域,那么我们可以使用::操作符来让它在内层有同名变量的情况下,仍然可见。
int a = 0;
void func()
{
int a;
a = 100;
cout << a << endl; //输出内层的a;
cout << ::a << endl; //输出全局的a。
}
从图示中看到:两个变量a:1个为全局变量,一个为局部变量。前者的作用域包含了后者的作用域。这称为作用域的嵌套。
如果在多层的作用域里,有变量同名,那么内层的变量起作用,而外层的同名变量暂时失去作用。比如在上例中,当代码执行到①处时,所输出的是函数 func()内的a。而代码②处,输出的是全局变量a。
这就引出一个“可见性”这个词,当内层的变量和外层的变量同名时,在内层里,外层的变量暂时地失去了可见性。
不过,如果外层是全局作用域,那么我们可以使用::操作符来让它在内层有同名变量的情况下,仍然可见。
int a = 0;
void func()
{
int a;
a = 100;
cout << a << endl; //输出内层的a;
cout << ::a << endl; //输出全局的a。
}
最后请大家把本节中讲到例子,都在CB上实例际演练一下。
15.3 生存期
一个变量为什么有会不同的作用域?其中一种最常见的原因就是它有一定的生存期。什么叫生存期?就像人一样,在活着的时候,可以“起作用”,死了以后,就不存在了,一了百了。
那么,在什么情况下一个变量是“活”着,又在什么情况下它是“死”了,或“不存在”了呢?
大家知道,变量是要占用内存的。比哪一个int类型的变量占用4个字节的内存,或一个char类型的变量占用1个字节的内存。如果这个变量还占用着内存,那么我们就认为它是“活着”,即,它存在着。而一个变量释放了它所占用的内存,我们就认为它“死了”,“不存在”了。
有哪个同学能告诉我,在我们的教程中,我这是第几次讲到“变量和内存”的关系?呵,我也记不得了。不管怎样,这里又是一次——我们必须从整体上讲一讲:一个程序在内存中如何存放?
15.3.1 程序的内存分区
先从程序上看“生”和“死”。
用CB编译出一个可执行文件(.exe),它被存放在磁盘上。当它没有运行时,我们认为它是“死”的。而当我们双击它,让它“跑”起来时,我们认为它是“活”的,有了“生命”。等我们关闭它,或它自行运行结束,它又回到了“死”的状态下。在这个过程里。
程序运行时,它会从操作系统那里分得一块内存。然后程序就会把这些内存(严格讲是内存的地址)进行划分,哪里到哪里用来作什么。这有点像我们从老板那里领来2000大洋,其中1000无要交月租,500元做生活费……真惨。
那么,程序有哪些需要入占用内存呢?
首先,代码需要一个空间来存放。因此,到手的内存首先要分出一块放代码的地方,称为代码区。剩下的是数据。根据不同需要,存放数据有区域有三种:数据区,栈区,堆区。为什么存放数据的内存需要分成三个区域?这个我先不说,先来说说数据(变量等)被放入不同的区内,将遇上什么样不同的命运。
第一、放入数据区的数据。
生存期:这些数据的命运最好。它们拥有和程序一样长的生存期。程序运行时,它们就被分配了内存,然后就死死占着,直到程序结束。
谁负责生死:这些数据如何产生,如何释放,都是程序自动完成的,我们程序员不用去费心为产生或释放这些变量写代码。
占用内存的大小:这些数据都必须有已知,且固定的大小,比如一个int变量,大小是4个字节,一个char类型,大小是1个字节。为什么必须这样?因为如果这个数据可以占用的大小是未定的,那么,程序就不可能为自动分配内存。
初始化:就是这个变量最开始的值是什么?放在数据区里的数据,可以是程序员用代码初始化,比如:
int a = 100;
这样,a的值按你意思去办,并初始化为100;但如果你没有写初始的代码,如:
int a;
那么,数据区内的数据将被初始化为全是0。
第二、放入堆区的数据。
生存期:堆内的数据什么时候“生(分配内存)”,什么时候“死(释放内存)”,由程序员决定。
谁负责生死:当然就是程序员了。C++里,有专门的函数或操作符来为堆里的变量分配或释放内存。程序员通过写这些代码来在需要时,让某个堆里的变量“生”,不需要时,让它“死”。
占用内存的大小:堆里的数据占用的内存可以是固定的,也可以是可变的。这就是C,C++里最强大也最难学的内容:“指针”所要做事。
初始化:由程序员完成。如果程序员不给它初始值,则它的值是未定的。
由于程序员掌握着堆区内的数据的“生死大权”,并且决定着该数据占用多少内存。所以在写程序时,必须特别注意这些数据。一不小心就会出错。比如一个数据还没有分配内存呢,你就要使用它,就会出错。更常见的是,一个数据,你为它分配了内存,可是却始终没有为替它释放内存,那样就会造成“内存泄漏”。就算你的程序都退出了,这个数据依然可能“阴魂不散”地占用着内存。
第三、放入栈区的数据。
生存期:对比前面的两种,数据区里数据具有永久的生存期,而堆里的数据的生存期算是“临时”的。需要了,程序员写代码产生;不需要了,又由程序员写代码释放。在程序员,临时才需要变量非常多,如果每个变量都由程序员来负责产生、释放,那程序员岂不很累?并且很危险(万一忘了释放哪个大块头的家伙....)。所以,必须有一种机制可以让程序自已来产生和释放某些临时变量。所以,放入堆区的数据是只有程序员才能决定的何时需要,何时不需的临时数据,而栈区数据则是编译器就能决定是否需要的临时数据。 当然,要想让编译器能知道数据什么时候需要,什么时候不需要,就必须做一种约定。这正是我们现在讲的“生存期”的语法内容。
谁负责生死:程序(和数据区的一样)。
占用内存的大小:固定大小(和数据区的一样)。
初始化:由程序员完成。如果程序员不给它初始值,则它的值是未定的(和堆区的一样)。
下面是三个区加上代码区的分布示意图:
 现在,我们也比较好回答前面的问题:“为什么存放数据的内存需要分成三个区域”?原因正在于程序所要用到的数据具有不同的生存期要求,所以编译器把它们分别放到不同空间,好方便实现要求。
生存期和作用域的关系是:如果一个变量已经没有了生存期,那么自然它也就没了有作用域。但反过来,如果一个变量出了它的作用域,它并不一定就失去了生存期。典型的如函数内的静态数据,下面会讲到。
现在,我们也比较好回答前面的问题:“为什么存放数据的内存需要分成三个区域”?原因正在于程序所要用到的数据具有不同的生存期要求,所以编译器把它们分别放到不同空间,好方便实现要求。
生存期和作用域的关系是:如果一个变量已经没有了生存期,那么自然它也就没了有作用域。但反过来,如果一个变量出了它的作用域,它并不一定就失去了生存期。典型的如函数内的静态数据,下面会讲到。
15.3.2 动态生存期
就是放在“堆区”的数据。这些数据是在程序运行到某一处时,由程序员写的代码动态产生;后面又由程序员写的代码进行释放。我们现在还没有学习如何为变量(指针变量)分配和释放的内存的知识。
15.3.3 局部生存期
这里的局部和前面讲“局部作用域”一致,都是指“一对{}括起来的代码范围”。
请看下面代码,并思考问题:
//从前,有一个函数……
void func()
{
//函数内,有一个局部变量……
int a;
cout << a << endl;
a = 100;
}
//看清楚了,上面输出 a 的值的语句, 位于给a赋值之前!
//然后,下面的代码是两次调用这个函数:
...
func();
func();
...
第一次调用,我们知道屏幕肯定是要输出一个莫名其妙的数,因未初始化的局部变量,其值是不定的。我们以前讲变量时,就做过实例。现在,这里的变量a被输出后,我们让赋于它100。再接下来,我们又调用了一次函数func();请问这回输出的值,是100呢?或者仍然是莫名其妙的数?
大家打开CB,把这个例子做做。注意,动手生成一个空白的控制台工程后,调用func()的那两行代码,要放到主函数main()内,形如:
……
int main(int argc, char* argv[])
{
func();
func();
……
}
正确答案应该是:“仍然是莫名其妙的数”。尽管在第一次调用时func()时,局部变量最后被赋值为100;但很可惜,出了函数这个作用域,a 立即就死掉了……第二次再调用函数func()时,那个像个a投胎转世的婴儿,一切又重新开始……它又是一个没有被赋值的的变量了。
请大家把本例中的变量a改为全局变量,并且在函数func()的定义之前定义。再试一试。
15.3.4 静态生存期
就是放在“数据区”里的数据。程序一运行时,它们就开始存在;程序结束后,它们自动消亡。
这里讲的“静态”,和前面的“静态存储类型”不是一个意思。(老师,我忘了什么叫“静态存储类型”?呵,这有可能,本章的内容互相都有些关联和相似,大家多看几遍本章,最主要是课程让你动手的地儿,你就动手做,正所谓“该出手时就出手手……”)。
“静态存储类型”是指:一个全局变量,它被加上static之后,就只能在本文件内使用,别的文件不能通过加extern的声明来使用它。
“静态生存期“是指:一个变量,它仅仅产生和消亡一次(即在程序运行时产生,在程序退时消亡),而不像“动态生存期”或“局部生存期”那样可以生生死死,不断“投胎转世”。
下面的代码演示了“静态生存期”和“局部生存期”变量的不同。请你看完以后,回答问题。
#include <iostream.h>
//定义,声明一个全局变量:
int a;
//声明一个函数,定义在后面
void func();
int main(int argc, char* argv[])
{
int b = 100;
a = 10;
cout << a << end;
cout << b << end;
//调用函数func:
func();
}
//func()的定义:
void func()
{
cout << a << endl;
cout << b << endl;
}
哪里有错呢?请大家想想,试试。
15.3.5 局部静态变量
//从前,有一个函数……
void func()
{
//函数内,有一个局部变量……
int a;
cout << a << endl;
a = 100;
}
//调用两次:
func();
func();
同样是这个例子,我们只是要把 int a 之前加上一个 static 关键字:
void func()
{
//函数内,有一个局部静态变量……
static int a;
cout << a << endl;
a = 100;
}
...
func();
func();
...
我们要问的也是同样一个问题:第二次调用 func()后,输出的 a 值是多少?
这回答案是:输出的值是100。
这就是局部静态变量的特殊之处:尽管出了函数的作用域之后,变量已经不可见,并且也失去了作用。但是,它仍然存在着!并且保留着它最后的值。因此,它也是静态生存期。它也只在程序结束之后,才失去生存期。
上面讲的是局部静态变量“死”的问题,它也只“死”一次,对应地,显然它也只能“生”一次。
void func()
{
static int a = 30; //在定义时,同时初始化该局部静态变量为30。
cout << a << endl;
a = 100;
}
...
func();
func();
...
这回要问的是第一次调用func()时,输出的是什么?第二次呢?
答案:第一次输出30,第二次输出100,以后若有第三次,第四次,也是输出100。这就是说,初始化:static int = 30;这一句,仅被执行一次!
好,假如代码是这样子呢?
void func()
{
static int a;
a = 30; //改成不是在定义时同时初始化
cout << a << endl;
a = 100;
}
...
func();
func();
...
请回答我,这回,两次调用func()分别输出什么?
有关内存的堆、栈内容,最近我曾在CSDN上做过回答。大家如有兴趣,不妨去看看。(别忘了,我叫“nanyu”)。要学习编程,CSDN是不错的地方。大家有空常去(最好注册个ID)。我因为太忙,去不了几次。
15.4 对前15章的一点小结
一般教材用6或7章的内容,我们扩展成15章。大家可能嫌我讲得太慢。这我承认。哎,我的事情太多了。特别是最近这一段时间,先是笔者得了肾结石,剧痛了一夜最后住入医院,接着是我的宝宝发高烧,我在医院里守了一宿,未料到我的爱人接着也 得上医院……可恨的是电信局里不知哪个家伙一时兴起,来个什么“改线”,改来改去也不知改错了什么,我的ASDL就一断数天……幸好我天天打电话免费(不,是倒贴电话费 啊)为他们培训什么叫ADSL。(其实我也不懂,不过我总得旁敲侧击地暗示他们,“你们是不是动了什么啊?好好想想?再想想?”,哎,总的来说,他们的客户服务态度还是很好的……)。
不管怎样,在此我向所有付费报名的学员致歉。
这15章的内容,属于C,C++的基础知识,其中有些更是基础中基础。从第16章(数组)开始,就开始中级或高级的内容了。这些新的内容都有一个特点:都和内存地址有着千丝万缕的关系。所以大家有时间抓紧把前面的都复习中,其中犹其是要把我讲到的,有关“变量和内存”关系,全部重新消化一遍。
明天就是冬至了。圣诞节即到,在此我向大家问个节日快乐,并感谢早早给我发来贺卡的几位同学。
更重要的是春节即将到来,但愿我们能在春节前学完C++。然后一起向更为精彩的 Windows编程世界出发。
前面几节主要对Linux的外在体系结构做了一些介绍,在这一节里,将分析一下Linux的内部结构,初略可以将这个内部体系划分为三层:Hardware => Kernel Space => User Space
 1. 为什么要划分为内核空间和用户空间?
1. 为什么要划分为内核空间和用户空间?
Linux Kernel是操作系统的核心,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。
对于Kernel这么一个高安全级别的东西,显然是不容许其它的应用程序随便调用或访问的,所以需要对Kernel提供一定的保护机制,这个保护机制用来告诉那些应用程序,你只可以访问某些许可的资源,不许可的资源是拒绝被访问的,于是就把Kernel和上层的应用程序抽像的隔离开,分别称之为Kernel Space和User Space。
2. 用户空间的程序如何对内核空间进行访问?
上面说到用户态和内核态是两个隔离的空间,虽然从逻辑上被抽像的隔离,但无可避免的是,总是会有那么一些用户空间需要访问内核空间的资源,怎么办呢?
从上图结构中可以看出,Kernel Space层从下至上包括:
Arch:对应Kernel里arch目录,含有诸如x86, ia64, arm, s390等体系结构的支持;
Device Driver:对应Kernel里drivers目录,含有block, char, net, usb等不同硬件驱动的支持;
在Arch和Driver之上,是对内存,进程,文件系统,网络协议栈等的支持;
最上一层是System Call Interface,系统调用接口,正如其名,这层就是用户空间与内核空间的桥梁,用户空间的应用程序通过System Call这个统一入口来访问系统中的硬件资源,通过此接口,所有的资源访问都是在内核的控制下执行,以免导致对用户程序对系统资源的越权访问,从而保障了系统的安全和稳定。
3. glibc库的作用
在用户空间一层,可以看到有glibc库的存在,这里之所以把它单独列出来强调,是因为一般用户空间的程序不会直接调用内核的System Call去访问系统资源,而是由glibc这样的库间接去调用System Call,换言之,glibc对Kernel的System Call做了一层封装。
4. Kernel的C库与glibc的C库
之前强调过,Kernel是相对独立的存在,不依赖于任何用户空间的程序或库,而大家都知道Kernel除了少量的汇编代码,大多数都是由C语言编写,glibc库属于用户空间,没有glibc库的支持,Kernel又是如何去处理C语言相关的代码呢?
在Kernel的目录结构中,有lib这么一个目录,此目录里含有kernel自己的C库,比如字符串处理相关函数封装在string.c文件中,比如排序相关的代码封闭在sort.c文件中,调用的时候使用:
#include <linux/string.h>
#include <linux/sort.h>
而对于用空间glibc库的调用则是:
#include <string.h>
#include <memcopy.h>
内核空间与用户空间
做驱动算来快6年了,今天突然看到一个问题:你自己是怎么样理解内核空间和用户空间的?乍一看到这问题,说实话,自己头脑有点空白的感觉。
很奇怪的感觉,因为在我脑海里潜意识我对这个问题应该还是很清楚的,内核驱动,用户程序,系统调用什么的,信手拈来,就是画模块图都是一上来就画一条粗横线,上面是user space,下面是kernel space。但是自己仔细一想想,却发现自己真还说不清楚什么是内核空间和用户空间,自己其实只知道系统有内核空间和系统空间的概念。赶紧google了一下,把我的理解记录如下:
首先,这个概念的由来,我认为跟CPU的发展有很大关系,在目前CPU的保护模式下,系统需要对其赖以运行的资料进行保护,为了保证操作系统内核资料,我们把内存空间进行划分,一部分为操作系统内核运行的空间,另一部分是应用程序运行的空间,所谓空间就是内存的地址。因此内核空间和用户空间的概念就出现了。在386以前的CPU实模式下,操作系统内核与用户程序的内存空间是不做区分的,也就不存在内核空间和用户空间的说法了。
其次,CPU的保护模式的一个重大特点,也就是硬件直接支持的内存访问模式,虚拟地址空间到物理地址空间的映射。这种工作模式与内核空间用户空间在技术上的相辅相成,也是促成内存空间划分的原因。 内核空间,顾名思义就是内核的运行空间,用户空间也就是用户程序的运行空间,操作系统为了保护自己不被普通程序的破坏,对内核空间进行了一些定义,比如访问权限,换入换出,优先级等等。也就是说内核空间只允许内核访问,用户程序如果要访问内核空间就需要经过内核的审核。内核空间的页表是常驻内存的,不会虚拟内存管理模块换出到磁盘上。内核空间的程序一旦出错,系统会立即死机——系统拒绝继续运行。而用户程序则没有这么多些特权。
再次,内核空间和用户空间都是指虚拟空间,也就是虚拟地址。目前32位系统总共有4G的虚拟地址空间,在Linux系统中,4G虚拟地址空间的最高1G地址被分配给内核使用,是为内核空间,且为内核独享,而低地址的3G空间为用户程序所共享,也就是每个用户程序都有3G的虚拟地址空间。Windows的地址空间怎么分配的,我还不知道呢,惭愧!
内存对齐的规则以及作用
首先由一个程序引入话题:
1 //环境:vc6 + windows sp2
2 //程序1
3 #include <iostream>
4
5 using namespace std;
6
7 struct st1
8 {
9 char a ;
10 int b ;
11 short c ;
12 };
13
14 struct st2
15 {
16 short c ;
17 char a ;
18 int b ;
19 };
20
21 int main()
22 {
23 cout<<"sizeof(st1) is "<<sizeof(st1)<<endl;
24 cout<<"sizeof(st2) is "<<sizeof(st2)<<endl;
25 return 0 ;
26 }
27
程序的输出结果为:
sizeof(st1) is 12
sizeof(st2) is 8
问题出来了,这两个一样的结构体,为什么sizeof的时候大小不一样呢?
本文的主要目的就是解释明白这一问题。
内存对齐,正是因为内存对齐的影响,导致结果不同。
对于大多数的程序员来说,内存对齐基本上是透明的,这是编译器该干的活,编译器为程序中的每个数据单元安排在合适的位置上,从而导致了相同的变量,不同声明顺序的结构体大小的不同。
那么编译器为什么要进行内存对齐呢?程序1中结构体按常理来理解sizeof(st1)和sizeof(st2)结果都应该是7,4(int) + 2(short) + 1(char) = 7 。经过内存对齐后,结构体的空间反而增大了。
在解释内存对齐的作用前,先来看下内存对齐的规则:
1、 对于结构的各个成员,第一个成员位于偏移为0的位置,以后每个数据成员的偏移量必须是min(#pragma pack()指定的数,这个数据成员的自身长度) 的倍数。
2、 在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行。
#pragma pack(n) 表示设置为n字节对齐。 VC6默认8字节对齐
以程序1为例解释对齐的规则 :
St1 :char占一个字节,起始偏移为0 ,int 占4个字节,min(#pragma pack()指定的数,这个数据成员的自身长度) = 4(VC6默认8字节对齐),所以int按4字节对齐,起始偏移必须为4的倍数,所以起始偏移为4,在char后编译器会添加3个字节的额外字节,不存放任意数据。short占2个字节,按2字节对齐,起始偏移为8,正好是2的倍数,无须添加额外字节。到此规则1的数据成员对齐结束,此时的内存状态为:
oxxx|oooo|oo
0123 4567 89 (地址)
(x表示额外添加的字节)
共占10个字节。还要继续进行结构本身的对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行,st1结构中最大数据成员长度为int,占4字节,而默认的#pragma pack 指定的值为8,所以结果本身按照4字节对齐,结构总大小必须为4的倍数,需添加2个额外字节使结构的总大小为12 。此时的内存状态为:
oxxx|oooo|ooxx
0123 4567 89ab (地址)
到此内存对齐结束。St1占用了12个字节而非7个字节。
St2 的对齐方法和st1相同,读者可自己完成。
内存对齐的主要作用是:
1、 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2、 性能原因:经过内存对齐后,CPU的内存访问速度大大提升。具体原因稍后解释。
图一:

这是普通程序员心目中的内存印象,由一个个的字节组成,而CPU并不是这么看待的。
图二:

CPU把内存当成是一块一块的,块的大小可以是2,4,8,16字节大小,因此CPU在读取内存时是一块一块进行读取的。块大小成为memory access granularity(粒度) 本人把它翻译为“内存读取粒度” 。
假设CPU要读取一个int型4字节大小的数据到寄存器中,分两种情况讨论:
1、数据从0字节开始
2、数据从1字节开始
再次假设内存读取粒度为4。
图三:
 当该数据是从0字节开始时,很CPU只需读取内存一次即可把这4字节的数据完全读取到寄存器中。
当该数据是从1字节开始时,问题变的有些复杂,此时该int型数据不是位于内存读取边界上,这就是一类内存未对齐的数据。
图四:
当该数据是从0字节开始时,很CPU只需读取内存一次即可把这4字节的数据完全读取到寄存器中。
当该数据是从1字节开始时,问题变的有些复杂,此时该int型数据不是位于内存读取边界上,这就是一类内存未对齐的数据。
图四:
 此时CPU先访问一次内存,读取0—3字节的数据进寄存器,并再次读取4—5字节的数据进寄存器,接着把0字节和6,7,8字节的数据剔除,最后合并1,2,3,4字节的数据进寄存器。对一个内存未对齐的数据进行了这么多额外的操作,大大降低了CPU性能。
这还属于乐观情况了,上文提到内存对齐的作用之一为平台的移植原因,因为以上操作只有有部分CPU肯干,其他一部分CPU遇到未对齐边界就直接罢工了。
此时CPU先访问一次内存,读取0—3字节的数据进寄存器,并再次读取4—5字节的数据进寄存器,接着把0字节和6,7,8字节的数据剔除,最后合并1,2,3,4字节的数据进寄存器。对一个内存未对齐的数据进行了这么多额外的操作,大大降低了CPU性能。
这还属于乐观情况了,上文提到内存对齐的作用之一为平台的移植原因,因为以上操作只有有部分CPU肯干,其他一部分CPU遇到未对齐边界就直接罢工了。
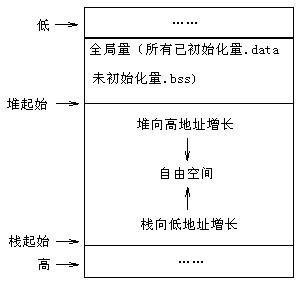
堆和栈的区别
最近太过执着于一些底层概念,《堆和栈的区别》这篇经典的博文已经被转载过N次,但还是转到这里,以方便日后查阅。谨对原创表示感谢!
一、预备知识—程序的内存分配
一个由C/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 由编译器自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
2、堆区(heap) —从堆上分配,亦称动态内存分配。程序在运行的时候用malloc 或new 申请任意多少的内存,程序员自己负责在何时用free 或delete 释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多。一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
3、全局区(静态区)(static)—,从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static 变量。全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域,程序结束后有系统释放。
4、文字常量区—常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区—存放函数体的二进制代码。
示例程序 (这是一个前辈写的,非常详细 )
[cpp] view plaincopyprint?
- // main.cpp
- int a = 0; // 全局初始化区
- char *p1; // 全局未初始化区
- int main()
- {
- int b; // 栈
- char s[] = "abc"; // 栈
- char *p2; // 栈
- char *p3 = "123456"; // 123456/0在常量区,p3在栈上。
- static int c =0; // 全局(静态)初始化区
- p1 = (char *)malloc(10);
- p2 = (char *)malloc(20);
- // 分配得来得和字节的区域就在堆区。
- strcpy(p1, "123456"); // 123456/0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
- return 0;
- }
二、堆和栈的理论知识
2.1申请方式
stack: 由系统自动分配。 例如,声明在函数中一个局部变量int b;系统自动在栈中为b开辟空间。
heap: 需要程序员自己申请,并指明大小,在c中malloc函数,如p1 = (char *)malloc(10);
在C++中用new运算符,如p2 = (char *)malloc(10); 但是注意p1、p2本身是在栈中的。
2.2 申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
2.3申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
2.4申请效率的比较:
栈由系统自动分配,速度较快。但程序员是无法控制的。
堆是由malloc/new 分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,它不是在堆,也不是在栈,是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
2.5堆和栈中的存储内容
栈: 在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
2.6存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;而bbbbbbbbbbb是在编译时就确定的;但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
比如:
[cpp] view plaincopyprint?
- int main()
- {
- char a = 1;
- char c[] = "1234567890";
- char *p ="1234567890";
- a = c[1];
- a = p[1];
- return 0;
- }
对应的汇编代码
10: a = c[1];
00401067 8A 4D F1 mov cl,byte ptr [ebp-0Fh]
0040106A 88 4D FC mov byte ptr [ebp-4],cl
11: a = p[1];
0040106D 8B 55 EC mov edx,dword ptr [ebp-14h]
00401070 8A 42 01 mov al,byte ptr [edx+1]
00401073 88 45 FC mov byte ptr [ebp-4],al
第一种在读取时直接就把字符串中的元素读到寄存器cl中,而第二种则要先把指针值读到edx中,在根据edx读取字符,显然慢了。
2.7小结:
堆和栈的区别可以用如下的比喻来看出:使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
而我们常说的“堆栈”是数据结构中的概念,是一种允许在其一端进行插入或删除的线性表,其基本操作是push入栈和pop出栈。
heap:是由malloc之类函数分配的空间所在地。地址是由低向高增长的。
stack:是自动分配变量,以及函数调用的时候所使用的一些空间。地址是由高向低减少的。
 1.变量的数据类型和存储类型
在C语言中,每一个变量都有两个属性:数据类型和存储类型。数据类型即常说的字符型、整型、浮点型;存储类型则指变量在内存中的存储方式,它决定了变量的作用域和生存期。
变量的存储类型有以下四种:auto(自动)、register(寄存器)、extern(外部)和static(静态)。其中auto和register用于声明内部变量,auto变量是存储在栈中的,register变量是存储在寄存器中的。static用于声明内部变量或外部变量,extern用于声明外部变量,它们是存储在静态存储区的。
变量声明的一般形式:<存储类型> <数据类型> <变量名列表>
当声明变量时未指定存储类型,则内部变量的存储类型默认为auto型,外部变量的存储类型默认为extern型。
外部变量有两种声明方式:定义性声明和引用性声明。
定义性声明是为了创建变量,即需为变量分配内存。引用性声明是为了建立变量与内存单元之间的关系,表示要引用的变量已在程序源文件中其他地方进行过定义性声明。定义性声明只能放在函数外部,而引用性声明可放在函数外部,也可放在函数内部。
[cpp] view plaincopyprint?
1.变量的数据类型和存储类型
在C语言中,每一个变量都有两个属性:数据类型和存储类型。数据类型即常说的字符型、整型、浮点型;存储类型则指变量在内存中的存储方式,它决定了变量的作用域和生存期。
变量的存储类型有以下四种:auto(自动)、register(寄存器)、extern(外部)和static(静态)。其中auto和register用于声明内部变量,auto变量是存储在栈中的,register变量是存储在寄存器中的。static用于声明内部变量或外部变量,extern用于声明外部变量,它们是存储在静态存储区的。
变量声明的一般形式:<存储类型> <数据类型> <变量名列表>
当声明变量时未指定存储类型,则内部变量的存储类型默认为auto型,外部变量的存储类型默认为extern型。
外部变量有两种声明方式:定义性声明和引用性声明。
定义性声明是为了创建变量,即需为变量分配内存。引用性声明是为了建立变量与内存单元之间的关系,表示要引用的变量已在程序源文件中其他地方进行过定义性声明。定义性声明只能放在函数外部,而引用性声明可放在函数外部,也可放在函数内部。
[cpp] view plaincopyprint?
- extern int b;//引用性声明,也可放在函数fun中
- void fun()
- {
- printf("d%",b);//输出
- }
- extern int b=5;//定义性声明,可以省略关键字extern
2.变量的作用域
变量的作用域是指一个范围,是从代码空间的角度考虑问题,它决定了变量的可见性,说明
变量在程序的哪个区域可用,即程序中哪些行代码可以使用变量。作用域有三种:局部作用域、全局作用域、文件作用域,相对应于局部变量(local variable)、全局变量和静态变量(global variable)。
(1)局部变量
大部分变量具有局部作用域,它们声明在函数(包括main函数)内部,因此局部变量又称为内部变量。在语句块内部声明的变量仅在该语句块内部有效,也属于局部变量。局部变量的作用域开始于变量被声明的位置,并在标志该函数或块结束的右花括号处结束。函数的形参也具有局部作用域。
[cpp] view plaincopyprint?
- #include <iostream>
- using namespace std;
-
- int main()
- {
- int x = 0;
- {
- int x=1;
- cout << x << endl;
- {
- cout << x << endl;
- int x = 2; // "x = 1" lost its scope here covered by "x = 2"
- cout << x << endl; // x = 2
- // local variable "x = 2" lost its scope here
- }
- cout << x << endl; // x = 1
- // local variable "x = 1" lost its scope here
- }
- cout << x << endl;
- // local variable "x = 0" lost its scope here
- return 0;
- }
(2) 全局变量及extern关键字
以下是MSDN对C/C++中extern关键字的解释:
The extern Storage-Class Specifier(C)
A variable declared with the extern storage-class specifier is a reference to a variable with the same name defined at the external level in any of the source files of the program. The internal extern declaration is used to make the external-level variable definition visible within the block. Unless otherwise declared at the external level, a variable declared with the extern keyword is visible only in the block in which it is declared.
The extern Storage-Class Specifier(C++)
The extern keyword declares a variable or function and specifies that it has external linkage (its name is visible from files other than the one in which it's defined). When modifying a variable, extern specifies that the variable has static duration (it is allocated when the program begins and deallocated when the program ends). The variable or function may be defined in another source file, or later in the same file. Declarations of variables and functions at file scope are external by default.
全局变量声明在函数的外部,因此又称外部变量,其作用域一般从变量声明的位置起,在程序源文件结束处结束。全局变量作用范围最广,甚至可以作用于组成该程序的所有源文件。当将多个独立编译的源文件链接成一个程序时,在某个文件中声明的全局变量或函数,在其他相链接的文件中也可以使用它们,但是必须做extern引用性声明。
关键字extern为声明但不定义一个对象提供了一种方法。实际上,它类似于函数声明,承诺了该对象会在其他地方被定义:或者在此文本文件中的其他地方,或者在程序的其他文本文件中。
如果一个函数要被其他文件中函数使用,定义时加extern关键字,在没有加extern和static关键字时,一般有的编译器会默认是extern类型的,因此你在其他文件中可以调用此函数。因此,extern一般主要用来做引用性声明。
但是,有些编译器以及在一些大型项目里,使用时一般的会将函数的定义放在源文件中不加extern,而将函数的声明放在头文件中,并且显式的声明成extern类型,需要使用此函数的源文件只要包含此头文件即可。
在使用extern 声明全局变量或函数时,一定要注意:所声明的变量或函数必须在且仅在一个源文件中实现定义。如果你的程序声明了一个外部变量,但却没有在任何源文件中定义它,程序将可以通编译,但无法链接通过:因为extern声明不会引起内存被分配!
在线程存在的情况下,必须做特殊的编码,以便同步各个线程对于全局对象的读和写操作。
另外,extern也可用来进行链接指定。C++中的extern "C"声明是为了实现C++与C及其它语言的混合编程,其中被extern "C"修饰的变量和函数是按照C语言方式编译和链接的。
如果C++调用一个C语言编写的.DLL时,当包括.DLL的头文件或声明接口函数时,应加extern "C" { }。
In C++, when used with a string, extern specifies that the linkage conventions of another language are being used for the declarator(s). C functions and data can be accessed only if they are previously declared as having C linkage. However, they must be defined in a separately compiled translation unit.
Microsoft C++ supports the strings "C" and "C++" in the string-literal field. All of the standard include files use the extern "C" syntax to allow the run-time library functions to be used in C++ programs.
例如,在C++工程中要包含C语言头文件,则一般这样:
extern "C" { #include <stdio.h> }
示例工程testExtern包含三个文件:C.c、CPP.cpp和testExtern.cpp。
[cpp] view plaincopyprint?
- // C.c
- #include <stdio.h>
-
- int intC = 2010;
-
- void funC()
- {
- printf("funC()/n");
- }
- // CPP.cpp
- #include <stdio.h>
-
- extern int global;
-
- /*extern*/ int intCPP = 2011;
- /*extern*/ const char* str = "defined outside";
- /*extern*/ int intArray[3] = {2012, 2013, 2014};
-
- static int staticIntCPP = 2015;
-
- void funCPP()
- {
- printf("funCPP() - localStatic : %d, globalExtern : %d/n", staticIntCPP, global);
- }
- // testExtern.cpp
- #include <stdio.h>
-
- /*extern*/ int global = 2016;
-
- extern "C" void funC(); // C.c中实现
- /*extern*/ void funCPP(); // CPP.cpp中实现,函数的声明默认在前面添加了extern:因为此处只声明,肯定在其他地方实现的。
-
- // 以下代码按C方式编译链接
- extern "C" void funC1()
- {
- printf("funC1()/n");
- }
-
- extern "C"
- {
- void funC2()
- {
- printf("funC2()/n");
- }
- }
-
- extern "C" void funC3(); // 本文件中其他地方(或外部文件)实现,按照C方式编译链接
- /*extern*/ void fun(); // 本文件中其他地方(或外部文件)实现
-
- extern "C" int intC; // C linkage specification in C++ must be at global scope
-
- int main()
- {
- printf("intC = %d/n", intC);
-
- extern int intCPP; // 或者放在main之前。如果去掉extern就变成了main()内部定义的局部变量!
- printf("intCPP = %d/n", intCPP);
-
- extern const char* str; // 或者放在main之前。
- printf("str = %s/n", str);
-
- extern int intArray[];
- for (int i = 0; i < 3; i++)
- {
- printf("intArray[i] = %d/n", intArray[i]);
- }
-
- // extern int staticIntCPP; // error LNK2001
- // printf("staticIntCPP = %d/n", staticIntCPP);
-
- funC();
- funCPP();
-
- funC1();
- funC2();
- funC3();
- fun();
-
- return 0;
- }
-
- void funC3()
- {
- printf("funC3()/n");
- }
-
- void fun()
- {
- printf("fun()/n");
- }
(3) 静态变量及static关键字
文件作用域是指在函数外部声明的变量只在当前文件范围内(包括该文件内所有定义的函数)可用,但不能被其他文件中的函数访问。一般在具有文件作用域的变量或函数的声明前加上static修饰符。
static静态变量可以是全局变量,也可以是局部变量,但都具有全局的生存周期,即生命周期从程序启动到程序结束时才终止。
[cpp] view plaincopyprint?
- #include <stdio.h>
- void fun()
- {
- static int a=5;//静态变量a是局部变量,但具有全局的生存期
- a++;
- printf("a=%d/n",a);
- }
- int main()
- {
- int i;
- for(i=0;i<2;i++)
- fun();
- getchar();
- return 0;
- }
输出结果为:
a=6
a=7
static操作符后面生命的变量其生命周期是全局的,而且其定义语句即static int a=5;只运行一次,因此之后再调用fun()时,该语句不运行。所以f的值保留上次计算所得,因此是6,7.
以下initWinsock例程中借助局部静态变量_haveInitializedWinsock保证Winsock只初始化一次。
[cpp] view plaincopyprint?
- int initWinsock(void)
- {
- static int _haveInitializedWinsock = 0;
- WORD WinsockVer1 = MAKEWORD(1, 1);
- WORD WinsockVer2 = MAKEWORD(2, 2);
- WSADATA wsadata;
-
- if (!_haveInitializedWinsock)
- {
- if (WSAStartup(WinsockVer1, &wsadata) && WSAStartup(WinsockVer2, &wsadata))
- {
- return 0; /* error in initialization */
- }
- if ((wsadata.wVersion != WinsockVer1)
- && (wsadata.wVersion != WinsockVer2))
- {
- WSACleanup();
- return 0; /* desired Winsock version was not available */
- }
- _haveInitializedWinsock = 1;
- }
-
- return 1;
- }
同一个源程序文件中的函数之间是可以互相调用的,不同源程序文件中的函数之间也是可以互相调用的,根据需要我们也可以指定函数不能被其他文件调用。根据函数能否被其他源程序文件调用,将函数分为内部函数和外部函数。
如果一个函数只能被本文件中其他函数所调用,它称为内部函数。在定义内部函数时,在函数名和函数类型的前面加static。
内部函数又称静态函数。使用内部函数,可以使函数只局限于所在文件,如果在不同的文件中有同名的内部函数,互不干扰。
通常把只能由同一文件使用的函数和外部变量放在一个文件中,在它们前面都冠以static使之局部化,其他文件不能引用。
由于静态变量或静态函数只在当前文件(定义它的文件)中有效,所以我们完全可以在多个文件中,定义两个或多个同名的静态变量或函数。这样当将多个独立编译的源文件链接成一个程序时,static修饰符避免一个文件中的外部变量由于与其他文件中的变量同名而发生冲突。
比如在A文件和B文件中分别定义两个静态变量a:
A文件中:static int a;
B文件中:static int a;
这两个变量完全独立,之间没有任何关系,占用各自的内存地址。你在A文件中改a的值,不会影响B文件中那个a的值。
B/S 通信简述
整个计算机网络的实现体现为协议的实现, TCP/IP 协议是 Internet 的核心协议, HTTP 协议是比 TCP 更高层次的应用层协议。
HTTP ( HyperText Transfer Protocol ,超文本传输协议)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 的初衷是为了提供一种发布和接收 HTML 页面的方法。
浏览器( Web Browser )负责与服务器建立连接,下载网页(包括资源文件及 JS 脚本文件)到本地,并最终渲染出页面。 JS 脚本文件运行在客户端,负责客户端一些行为响应或预处理,例如提交表单前的数据校验、鼠标事件处理等交互。由此可见,浏览器( Browser)一方面充当了 C/S 通信架构中 C 角色 ,另一方面它是 HTML/JavaScript 的解析渲染引擎( Analyze Render Engine )。
在浏览器地址栏敲入 “http://www.baidu.com/ ” ,按下回车键,浏览器中呈现出百度首页。这样一种情景我们再熟悉不过,本文通过 wireshark 抓取这一过程的 TCP/IP 数据包,结合 TCP 协议分析 HTTP 通信的基本流程。
MTU 和 MSS
本文用到的抓包工具为 wireshark ,它的前身是赫赫有名的 Ethereal 。 wireshark 以太网帧的封包格式为:
Frame = Ethernet Header + IP Header + TCP Header + TCP Segment Data
( 1 ) Ethernet Header = 14 Byte = Dst Physical Address ( 6 Byte ) + Src Physical Address ( 6 Byte ) + Type ( 2 Byte ),以太网帧头以下称之为数据帧 。
( 2 ) IP Header = 20 Byte ( without options field ),数据在 IP 层称为 Datagram ,分片称为 Fragment 。
( 3 ) TCP Header = 20 Byte ( without options field ),数据在 TCP 层称为 Stream ,分段称为 Segment ( UDP 中称为 Message ) 。
( 4 ) 54 个字节后为 TCP 数据负载部分( Data Portion ),即应用层用户数据。
Ethernet Header 以下的 IP 数据报最大传输单位为 MTU ( Maximum Transmission Unit , Effect of short board ),对于大多数使用以太网的局域网来说, MTU=1500 。
TCP 数据包每次能够传输的最大数据分段为 MSS ,为了达到最佳的传输效能,在建立 TCP 连接时双方协商 MSS 值,双方提供的 MSS 值的最小值为这次连接的最大 MSS 值。 MSS 往往基于 MTU 计算出来,通常 MSS=MTU-sizeof(IP Header)-sizeof(TCP Header)=1500-20-20=1460 。
这样,数据经过本地 TCP 层分段后,交给本地 IP 层,在本地 IP 层就不需要分片了。但是在下一跳路由( Next Hop )的邻居路由器上可能发生 IP 分片!因为路由器的网卡的 MTU 可能小于需要转发的 IP 数据报的大小。这时候,在路由器上可能发生两种情况:
( 1 ) . 如果源发送端设置了这个 IP 数据包可以分片( May Fragment , DF=0 ),路由器将 IP 数据报分片后转发。
( 2 ) . 如果源发送端设置了这个 IP 数据报不可以分片( Don’t Fragment , DF=1 ),路由器将 IP 数据报丢弃,并发送 ICMP 分片错误消息给源发送端。
关于 MTU 的探测,参考《 Path MTU discovery 》。我们 可以通过基于 ICMP 协议的 ping 命令来探测从本机出发到目标机器上路由上的 MTU ,详见下文。
TCP 和 UDP
在基于传输层( TCP/UDP )的应用开发中,为了最后的程序优化,应避免端到端的任何一个节点上出现 IP 分片。 TCP 的 MSS 协商机制加上序列号确认机制,基本上能够保证数据的可靠传输。
UDP 协议在 IP 协议的基础上,只增加了传输层的端口( Source Port+Destination Port )、 UDP 数据包长( Length = Header+Data )以及检验和( Checksum )。因此,基于 UDP 开发应用程序时,数据包需要结合 IP 分片情况考虑。对于以太局域网,往往取 UDP 数据包长 Length<=MTU-sizeof(IP Header)=1480 ,故 UDP 数据负载量小于或等于 1472 ( Length-UDP Header );对于公网, ipv4 最小 MTU 为 576 , UDP 数据负载量小于或等于 536 。
“ 向外” NAT 在内网和公网之间提供了一个“ 不对称” 桥的映射。“ 向外” NAT 在默认情况下只允许向外的 session 穿越 NAT :从外向内的的数据包都会被丢弃掉,除非 NAT 设备事先已经定义了这些从外向内的数据包是已存在的内网 session 的一部分。对于一方在 LAN ,一方在 WAN 的 UDP 通信,鉴于 UDP 通信不事先建立虚拟链路, NAT 后面的 LAN 通信方需先发送消息给 WAN 通信方以洞穿 NAT ,然后才可以进行双向通信,这即是常提到的 “UDP 打洞( Hole Punching ) ” 问题。
TCP 连接百度过程解析
下文对百度的完整抓包建立在不使用 缓存的基础上。如若主机存有百度站点的 cookie 和脱机缓存( Offline Cache ),则不会再请求地址栏图标 favicon.ico ;请求 /js/bdsug.js?v=1.0.3.0 可能回应 “HTTP/1.1 304 Not Modified” 。可在浏览器打开百度首页后,Ctrl+F5强制刷新,不使用缓存,也可参考《 浏览器清除缓存方法 》。
以下为访问百度过程, wireshark 抓包数据。对于直接通过 Ethernet 联网的机器, Wireshark Capture Filter 为 host www.baidu.com ;对于通过 PPP over Ethernet ( PPPoE )联网的机器, Wireshark Capture Filter 为 pppoes and hostwww.baidu.com 。以下抓包示例 直接通过 Ethernet 联网访问百度的过程。可点击图片超链接下载pcap文件,使用wireshark软件查看。
为方便起见,以下将客户端(浏览器)简称为 C ,将服务器(百度)简称为 S 。
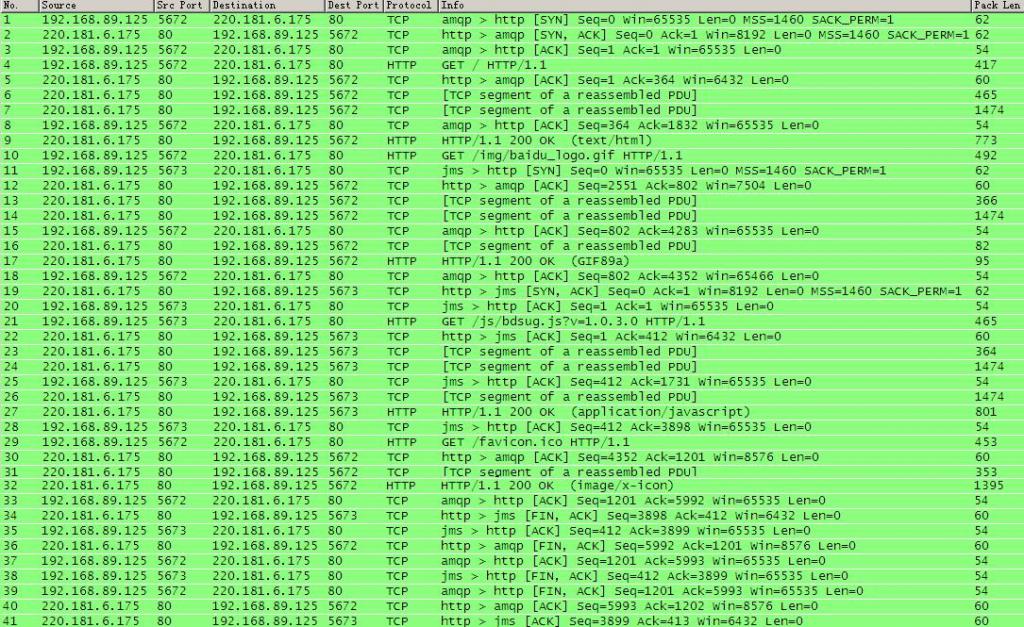 1 . TCP 三次握手建立连接
“http://” 标识 WWW 访问协议为 HTTP ,根据规则,只有底层协议建立连接之后才能进行更高层协议的连接。在浏览器地址栏输入地址后按下回车键的瞬间, C 建立与 S (机器名为 www.baidu.com , DNS 解析出来的 IP 为 220.181.6.175 )的 TCP 80 连接( HTTP 默认使用 TCP 80 端口)。
以下为三次握手建立 TCP 连接的数据包( Packet1-Packet3 )。
1 192.168.89.125:5672 → 220.181.6.175:80 TCP( 协议 ) 62( 以太网 帧长 )
amqp > http [SYN] Seq=0 Win=65535 Len=0 MSS=1460 SACK_PERM =1
2 220.181.6.175:80 → 192.168.89.125:5672 TCP 62
http > amqp [SYN, ACK] Seq=0 Ack=1 Win=8192 Len=0 MSS=1460 SACK_PERM=1
3 192.168.89.125:5672 → 220.181.6.175:80 TCP 54
amqp > http [ACK] Seq=1 Ack=1 Win=65535 Len=0
三次握手建立 TCP 连接的流程如下:
C(Browser) S(www.baidu.com)
1. CLOSED LISTEN
2. SYN-SENT → <SEQ=0><CTL=SYN> → SYN-RECEIVED
3. ESTABLISHED ← <SEQ=0><ACK=1><CTL=SYN,ACK> ← SYN-RECEIVED
4. ESTABLISHED → <SEQ=1><ACK=1><CTL=ACK> → ESTABLISHED
3-Way Handshake for Connection Synchronization
三次握手的 socket 层执行逻辑
S 调用 socket 的 listen 函数进入监听状态; C 调用 connect 函数连接 S : [SYN] , S 调用 accept 函数接受 C 的连接并发起与 C 方向上的连接: [SYN,ACK] 。 C 发送 [ACK] 完成三次握手, connect 函数返回; S 收到 C 发送的 [ACK] 后, accept 函数返回。
关于 Seq 和 Ack
Seq 即 Sequence Number , 为源端 ( source ) 的发送序列号 ; Ack 即 Acknowledgment Number , 为目的端 ( destination ) 的接收确认序列号 。在 Wireshark Display Filter 中,可使用 tcp.seq 或 tcp.ack 过滤。
在 Packet1 中, C:5672 向 S:80 发送 SYN 握手包, Seq=0(relative sequence number) ;在 Packet2 中 , S:80 向 C:5672 发送 ACK 握手回应包, Ack=1(relative sequence number) ,同时发送 SYN 握手包, Seq=0(relative sequence number) ;在 Packet3 中, C:5672 向 S:80 发送 ACK 握手回应包, Seq=1 , Ack=1 。
至此, Seq=1 为 C 的 Initial Sequence Number ( ISN ),后期某一时刻的 Seq=ISN+ 累计发送量 (cumulative sent) ; Ack=1 为 C 的 Initial Acknowledge Number ( IAN ),后期某一时刻的 Ack=IAN+ 累计接收量 (cumulative received) 。对于 S 而言, Seq 和 Ack 情同此理。
2 . TCP 获取网站数据流程
连接建立后,下一步发送( “GET / HTTP/1.1” )请求( Request ) HTML 页面,这里 “/” 表示 S 的默认首页, “GET” 为 HTTP Request Method ; “/” 为 Request-URI ,这里为相对地址; HTTP/1.1 表示使用的 HTTP 协议版本号为 1.1 。
以下为 HTTP GET 请求数据包( Packet4 )。
4 192.168.89.125:5672 → 220.181.6.175:80 HTTP 417
GET / HTTP/1.1
HTTP GET 报文长 =417-54=363 个字节,其中 Next sequence number: 364(relative sequence number) 表示,若 在规定的时间内收到S 响应 Ack=364 ,表明该报文发送成功,可以发送下一个报文( Seq=364 );否则重传(TCP Retransmitssion )。序列号确认机制是 TCP 可靠性传输的保障。
S ( http )收到 HTTP GET 报文(共 363 个字节),向 C ( amqp )发送 TCP 确认报文 ( Packet5 )。
5 220.181.6.175:80 → 192.168.89.125:5672 TCP 60
http > amqp [ACK] Seq=1 Ack=364 Win=6432 Len=0
这里 Seq=1, 为 S 的 ISN ,意为已发送过 SYN 。 Packet2 中, Ack=1 为 S 的 IAN 。这里的 Ack-IAN=364-1=363 表示 S 已经从 C 接收到 363 个字节,即 HTTP GET 报文。同时,Ack=364也是S期待C发送的下一个TCP报文序列号(上面分析的 Next sequence number) 。
接下来, S 向 C 发送 Http Response ,根据 HTTP 协议,先发响应头( Response Header ),再发百度首页 HTML 文件。
Http Response Header 报文 ( Packet6 ) 如下 。
6 220.181.6.175:80 → 192.168.89.125:5672 TCP 465
其部分内容如下:
======================================
HTTP/1.1 200 OK
……
Content-Length: 2139
Content-Type: text/html;charset=gb2312
Content-Encoding: gzip
======================================
S 响应 C 的 “GET / HTTP/1.1” 请求,先发送带 [PSH ] 标识的 411 个字节的 Http Response Header ( Packet 6 )。
TCP 头部 [PSH] 标识置位,敦促 C 将缓存的数据推送给应用程序,即先处理 Http Response Header ,实际上是一种 “ 截流 ” 通知。相应 C 的 socket 调用 send 时 在 IPPROTO_TCP 选项级别设置 TCP_NODELAY 为 TRUE 禁用 Nagle 算法可以 “ 保留发送边界 ” ,以防粘连。
尽管握手协商的 MSS 为 1460 ,但服务器或者代理平衡服务器,每次发送过来的 TCP 数据最多只有 1420 个字节 。 可以使用 ping -f -l size target_name 命令向指定目标 target_name 发送指定字节量的 ICMP 报文,其中 -l size 指定发送缓冲区的大小; -f则表示在 IP 数据报中设置不分片( Don’t Fragment ),这样便可探测出到目标路径上的 MTU 。
执行“ ping -f -l 1452 www.baidu.com ”的结果如下:
220.181.6.18 的 Ping 统计信息 :
数据包 : 已发送 = 4 ,已接收 = 4 ,丢失 = 0 (0% 丢失 )
执行“ ping -f -l 1453 www.baidu.com ”的结果如下:
需要拆分数据包但是设置 DF 。
220.181.6.18 的 Ping 统计信息 :
数据包 : 已发送 = 4 ,已接收 = 0 ,丢失 = 4 (100% 丢失 )
从以上 ping 结果可知,在不分片时,从本机出发到百度的路由上能通过的最大数据量为 1452 ,由此推算出 MTU{local,baidu}=sizeof(IP Header)+ sizeof(ICMP Header)+sizeof(ICMP Data Portion)=20+8+1452=1480 。
S 调用 socket 的 send 函数发送 2139 个字节的 Http Response Content ( Packet 7 、 Packet 9 ),在 TCP 层将分解为两段( segment )后再发出去。
7 220.181.6.175:80 → 192.168.89.125:5672 TCP 1474
[TCP segment of a reassembled PDU]
由 “Content-Length: 2139” 可知, HTML 文件还有 2139-(1474-54)=719 个字节。但此时, C 已经发送了确认报文 ( Packet8 ) 。
8 192.168.89.125:5672 → 220.181.6.175:80 TCP 54
amqp > http [ACK] Seq=364 Ack=1832 Win=65535 Len=0
Seq-ISN=364-1=363 ,表示 C 已经发出了 363 个字节,上边已经收到了 S 的确认。 Ack-IAN=1832-1=(465-54)+(1474-54) ,表示 C 至此已经接收到 S 发来的 1831 个字节。
接下来, C 收到 HTML 文件剩余的 719 个字节,报文 ( Packet9 )如下。
9 220.181.6.175:80 → 192.168.89.125:5672 HTTP 773
HTTP/1.1 200 OK
至此, C 收到 S 发送过来的全部 HTTP 响应报文,即百度首页 HTML 内容 (text/html) 。
Packet6 、 Packet7 和 Packet9 的 ACK 都是 364 ,这是因为这三个segment都是针对 Packet4 的 TCP 响应。S将百度首页HTML文件(一个完整的HTTP报文)按照MSS分段提交给TCP层。 在 Wireshark 中可以看到 Packet9 的报文中有以下 reassemble 信息:
[Reassembled TCP segments (2555 bytes): #6(411),#7(1420),#9(719)]
[Frame: 6, payload: 0-410(411 bytes)]
[Frame: 7, payload: 411-1830(1420 bytes)]
[Frame: 9, payload: 1831-2549(719 bytes)]
C ( amqp )接收到百度首页的 HTML 文件后,开始解析渲染。在解析过程中,发现页面中含有百度的 logo 资源 baidu_logo.gif ,并且需要 bdsug.js 脚本。
<img src=" http://www.baidu.com/img/baidu_logo.gif " width="270" height="129" usemap="#mp">
{d.write('<script src=http://www.baidu.com/js/bdsug.js?v=1.0.3.0><//script>')}
于是上面那个连接( C:5672 )继续向 S 请求 logo 图标资源,报文( Packet10 )如下。
10 192.168.89.125:5672 → 220.181.6.175:80 HTTP 492
GET /img/baidu_logo.gif HTTP/1.1
与此同时, C ( jms )新建一个连接( TCP 5 673 )向 S 请求 js 脚本文件。 报文( Packet11 )如下。
11 192.168.89.125:5673 → 220.181.6.175:80 TCP 62
jms > http [SYN] Seq=0 Win=65535 Len=0 MSS=1460 SACK_PERM=1
( Packet12 ) Packet13 、 Packet14 、 Packet16 和 Packet17 为对 Packet10 的 TCP 响应(它们的 Ack=802 ), 在逻辑上它们是一个完整的 TCP 报文。其 Http Response Content 为图片文件 baidu_logo.gif 。我们在 Wireshark 中可以看到Packet17 的报文中有以下 reassemble 信息:
[Reassembled TCP segments (1801 bytes): #13(312),#14(1420),#16(28) ,#17(41)]
[Frame: 13, payload: 0-311(312 bytes)]
[Frame: 14, payload: 312-1731(1420 bytes)]
[Frame: 16, payload: 1732-1759(28 bytes)]
[Frame: 17, payload: 1760-1800(41 bytes)]
Packet11-Packet19-Packet20 完成新连接的三次握手。然后, C ( jms )发送 “ GET /js/bdsug.js?v=1.0.3.0 HTTP/1.1 ” 报文( Packet21 ),以获取 bdsug.js 脚本文件。
21 192.168.89.125:5673 → 220.181.6.175:80 HTTP 465
GET /js/bdsug.js?v=1.0.3.0 HTTP/1.1
( Packet22 ) Packet23 、 Packet24 、 Packet26 和 Packet27 为对 Packet21 的 TCP 响应(它们的 Ack=412 ), 在逻辑上它们是一个完整的 TCP 报文。其 Http Response Content 为脚本文件 bdsug.js 。我们在 Wireshark 中可以看到 Packet27 的报文中有以下 reassemble 信息:
[Reassembled TCP segments (3897 bytes): #23(310),#24(1420),#26(1420) ,#27(747)]
[Frame: 23, payload: 0-309(310 bytes)]
[Frame: 24, payload: 310-1729(1420 bytes)]
[Frame: 26, payload: 1730-3149(1420 bytes)]
[Frame: 27, payload: 3150-3896(747 bytes)]
通常,浏览器会自动的搜索网站的根目录,只要它发现了 favicon.ico 这个文件,就把它下载下来作为网站地址栏图标。于是, C ( amqp )还将发起 “ GET /favicon.ico HTTP/1.1 ” 请求 网站地址栏图标,见报文 Packet29 。
3 . TCP 四次挥手关闭连接
经 Packet28 确认收到了完整的 japplication/javascript 文件后,链路 1 (本地端口 5673 )使命结束, S 关闭该链路,进入四次挥手关闭双向连接。
( Packet30 ) Packet31 和 Packet32 为对 Packet29 的 TCP 响应(它们的 Ack=1201 )。 经 Packet33 确认收到了完整的 image/x-icon 文件后,链路 2 (本地端口 5672 )使命结束, S 关闭该链路,进入四次挥手关闭双向连接。
为什么握手是三次,而挥手是四次呢?这是因为握手时,服务器往往在答应建立连接时,也建立与客户端的连接,即所谓的双向连接。所以,在 Packet2 中,服务器将 ACK 和 SYN 打包发出。挥手,即关闭连接,往往只是表明挥手方不再发送数据(无数据可发),而接收通道依然有效(依然可以接受数据)。当对方也挥手时,则表明对方也无数据可发了,此时双向连接真正关闭。
1 . TCP 三次握手建立连接
“http://” 标识 WWW 访问协议为 HTTP ,根据规则,只有底层协议建立连接之后才能进行更高层协议的连接。在浏览器地址栏输入地址后按下回车键的瞬间, C 建立与 S (机器名为 www.baidu.com , DNS 解析出来的 IP 为 220.181.6.175 )的 TCP 80 连接( HTTP 默认使用 TCP 80 端口)。
以下为三次握手建立 TCP 连接的数据包( Packet1-Packet3 )。
1 192.168.89.125:5672 → 220.181.6.175:80 TCP( 协议 ) 62( 以太网 帧长 )
amqp > http [SYN] Seq=0 Win=65535 Len=0 MSS=1460 SACK_PERM =1
2 220.181.6.175:80 → 192.168.89.125:5672 TCP 62
http > amqp [SYN, ACK] Seq=0 Ack=1 Win=8192 Len=0 MSS=1460 SACK_PERM=1
3 192.168.89.125:5672 → 220.181.6.175:80 TCP 54
amqp > http [ACK] Seq=1 Ack=1 Win=65535 Len=0
三次握手建立 TCP 连接的流程如下:
C(Browser) S(www.baidu.com)
1. CLOSED LISTEN
2. SYN-SENT → <SEQ=0><CTL=SYN> → SYN-RECEIVED
3. ESTABLISHED ← <SEQ=0><ACK=1><CTL=SYN,ACK> ← SYN-RECEIVED
4. ESTABLISHED → <SEQ=1><ACK=1><CTL=ACK> → ESTABLISHED
3-Way Handshake for Connection Synchronization
三次握手的 socket 层执行逻辑
S 调用 socket 的 listen 函数进入监听状态; C 调用 connect 函数连接 S : [SYN] , S 调用 accept 函数接受 C 的连接并发起与 C 方向上的连接: [SYN,ACK] 。 C 发送 [ACK] 完成三次握手, connect 函数返回; S 收到 C 发送的 [ACK] 后, accept 函数返回。
关于 Seq 和 Ack
Seq 即 Sequence Number , 为源端 ( source ) 的发送序列号 ; Ack 即 Acknowledgment Number , 为目的端 ( destination ) 的接收确认序列号 。在 Wireshark Display Filter 中,可使用 tcp.seq 或 tcp.ack 过滤。
在 Packet1 中, C:5672 向 S:80 发送 SYN 握手包, Seq=0(relative sequence number) ;在 Packet2 中 , S:80 向 C:5672 发送 ACK 握手回应包, Ack=1(relative sequence number) ,同时发送 SYN 握手包, Seq=0(relative sequence number) ;在 Packet3 中, C:5672 向 S:80 发送 ACK 握手回应包, Seq=1 , Ack=1 。
至此, Seq=1 为 C 的 Initial Sequence Number ( ISN ),后期某一时刻的 Seq=ISN+ 累计发送量 (cumulative sent) ; Ack=1 为 C 的 Initial Acknowledge Number ( IAN ),后期某一时刻的 Ack=IAN+ 累计接收量 (cumulative received) 。对于 S 而言, Seq 和 Ack 情同此理。
2 . TCP 获取网站数据流程
连接建立后,下一步发送( “GET / HTTP/1.1” )请求( Request ) HTML 页面,这里 “/” 表示 S 的默认首页, “GET” 为 HTTP Request Method ; “/” 为 Request-URI ,这里为相对地址; HTTP/1.1 表示使用的 HTTP 协议版本号为 1.1 。
以下为 HTTP GET 请求数据包( Packet4 )。
4 192.168.89.125:5672 → 220.181.6.175:80 HTTP 417
GET / HTTP/1.1
HTTP GET 报文长 =417-54=363 个字节,其中 Next sequence number: 364(relative sequence number) 表示,若 在规定的时间内收到S 响应 Ack=364 ,表明该报文发送成功,可以发送下一个报文( Seq=364 );否则重传(TCP Retransmitssion )。序列号确认机制是 TCP 可靠性传输的保障。
S ( http )收到 HTTP GET 报文(共 363 个字节),向 C ( amqp )发送 TCP 确认报文 ( Packet5 )。
5 220.181.6.175:80 → 192.168.89.125:5672 TCP 60
http > amqp [ACK] Seq=1 Ack=364 Win=6432 Len=0
这里 Seq=1, 为 S 的 ISN ,意为已发送过 SYN 。 Packet2 中, Ack=1 为 S 的 IAN 。这里的 Ack-IAN=364-1=363 表示 S 已经从 C 接收到 363 个字节,即 HTTP GET 报文。同时,Ack=364也是S期待C发送的下一个TCP报文序列号(上面分析的 Next sequence number) 。
接下来, S 向 C 发送 Http Response ,根据 HTTP 协议,先发响应头( Response Header ),再发百度首页 HTML 文件。
Http Response Header 报文 ( Packet6 ) 如下 。
6 220.181.6.175:80 → 192.168.89.125:5672 TCP 465
其部分内容如下:
======================================
HTTP/1.1 200 OK
……
Content-Length: 2139
Content-Type: text/html;charset=gb2312
Content-Encoding: gzip
======================================
S 响应 C 的 “GET / HTTP/1.1” 请求,先发送带 [PSH ] 标识的 411 个字节的 Http Response Header ( Packet 6 )。
TCP 头部 [PSH] 标识置位,敦促 C 将缓存的数据推送给应用程序,即先处理 Http Response Header ,实际上是一种 “ 截流 ” 通知。相应 C 的 socket 调用 send 时 在 IPPROTO_TCP 选项级别设置 TCP_NODELAY 为 TRUE 禁用 Nagle 算法可以 “ 保留发送边界 ” ,以防粘连。
尽管握手协商的 MSS 为 1460 ,但服务器或者代理平衡服务器,每次发送过来的 TCP 数据最多只有 1420 个字节 。 可以使用 ping -f -l size target_name 命令向指定目标 target_name 发送指定字节量的 ICMP 报文,其中 -l size 指定发送缓冲区的大小; -f则表示在 IP 数据报中设置不分片( Don’t Fragment ),这样便可探测出到目标路径上的 MTU 。
执行“ ping -f -l 1452 www.baidu.com ”的结果如下:
220.181.6.18 的 Ping 统计信息 :
数据包 : 已发送 = 4 ,已接收 = 4 ,丢失 = 0 (0% 丢失 )
执行“ ping -f -l 1453 www.baidu.com ”的结果如下:
需要拆分数据包但是设置 DF 。
220.181.6.18 的 Ping 统计信息 :
数据包 : 已发送 = 4 ,已接收 = 0 ,丢失 = 4 (100% 丢失 )
从以上 ping 结果可知,在不分片时,从本机出发到百度的路由上能通过的最大数据量为 1452 ,由此推算出 MTU{local,baidu}=sizeof(IP Header)+ sizeof(ICMP Header)+sizeof(ICMP Data Portion)=20+8+1452=1480 。
S 调用 socket 的 send 函数发送 2139 个字节的 Http Response Content ( Packet 7 、 Packet 9 ),在 TCP 层将分解为两段( segment )后再发出去。
7 220.181.6.175:80 → 192.168.89.125:5672 TCP 1474
[TCP segment of a reassembled PDU]
由 “Content-Length: 2139” 可知, HTML 文件还有 2139-(1474-54)=719 个字节。但此时, C 已经发送了确认报文 ( Packet8 ) 。
8 192.168.89.125:5672 → 220.181.6.175:80 TCP 54
amqp > http [ACK] Seq=364 Ack=1832 Win=65535 Len=0
Seq-ISN=364-1=363 ,表示 C 已经发出了 363 个字节,上边已经收到了 S 的确认。 Ack-IAN=1832-1=(465-54)+(1474-54) ,表示 C 至此已经接收到 S 发来的 1831 个字节。
接下来, C 收到 HTML 文件剩余的 719 个字节,报文 ( Packet9 )如下。
9 220.181.6.175:80 → 192.168.89.125:5672 HTTP 773
HTTP/1.1 200 OK
至此, C 收到 S 发送过来的全部 HTTP 响应报文,即百度首页 HTML 内容 (text/html) 。
Packet6 、 Packet7 和 Packet9 的 ACK 都是 364 ,这是因为这三个segment都是针对 Packet4 的 TCP 响应。S将百度首页HTML文件(一个完整的HTTP报文)按照MSS分段提交给TCP层。 在 Wireshark 中可以看到 Packet9 的报文中有以下 reassemble 信息:
[Reassembled TCP segments (2555 bytes): #6(411),#7(1420),#9(719)]
[Frame: 6, payload: 0-410(411 bytes)]
[Frame: 7, payload: 411-1830(1420 bytes)]
[Frame: 9, payload: 1831-2549(719 bytes)]
C ( amqp )接收到百度首页的 HTML 文件后,开始解析渲染。在解析过程中,发现页面中含有百度的 logo 资源 baidu_logo.gif ,并且需要 bdsug.js 脚本。
<img src=" http://www.baidu.com/img/baidu_logo.gif " width="270" height="129" usemap="#mp">
{d.write('<script src=http://www.baidu.com/js/bdsug.js?v=1.0.3.0><//script>')}
于是上面那个连接( C:5672 )继续向 S 请求 logo 图标资源,报文( Packet10 )如下。
10 192.168.89.125:5672 → 220.181.6.175:80 HTTP 492
GET /img/baidu_logo.gif HTTP/1.1
与此同时, C ( jms )新建一个连接( TCP 5 673 )向 S 请求 js 脚本文件。 报文( Packet11 )如下。
11 192.168.89.125:5673 → 220.181.6.175:80 TCP 62
jms > http [SYN] Seq=0 Win=65535 Len=0 MSS=1460 SACK_PERM=1
( Packet12 ) Packet13 、 Packet14 、 Packet16 和 Packet17 为对 Packet10 的 TCP 响应(它们的 Ack=802 ), 在逻辑上它们是一个完整的 TCP 报文。其 Http Response Content 为图片文件 baidu_logo.gif 。我们在 Wireshark 中可以看到Packet17 的报文中有以下 reassemble 信息:
[Reassembled TCP segments (1801 bytes): #13(312),#14(1420),#16(28) ,#17(41)]
[Frame: 13, payload: 0-311(312 bytes)]
[Frame: 14, payload: 312-1731(1420 bytes)]
[Frame: 16, payload: 1732-1759(28 bytes)]
[Frame: 17, payload: 1760-1800(41 bytes)]
Packet11-Packet19-Packet20 完成新连接的三次握手。然后, C ( jms )发送 “ GET /js/bdsug.js?v=1.0.3.0 HTTP/1.1 ” 报文( Packet21 ),以获取 bdsug.js 脚本文件。
21 192.168.89.125:5673 → 220.181.6.175:80 HTTP 465
GET /js/bdsug.js?v=1.0.3.0 HTTP/1.1
( Packet22 ) Packet23 、 Packet24 、 Packet26 和 Packet27 为对 Packet21 的 TCP 响应(它们的 Ack=412 ), 在逻辑上它们是一个完整的 TCP 报文。其 Http Response Content 为脚本文件 bdsug.js 。我们在 Wireshark 中可以看到 Packet27 的报文中有以下 reassemble 信息:
[Reassembled TCP segments (3897 bytes): #23(310),#24(1420),#26(1420) ,#27(747)]
[Frame: 23, payload: 0-309(310 bytes)]
[Frame: 24, payload: 310-1729(1420 bytes)]
[Frame: 26, payload: 1730-3149(1420 bytes)]
[Frame: 27, payload: 3150-3896(747 bytes)]
通常,浏览器会自动的搜索网站的根目录,只要它发现了 favicon.ico 这个文件,就把它下载下来作为网站地址栏图标。于是, C ( amqp )还将发起 “ GET /favicon.ico HTTP/1.1 ” 请求 网站地址栏图标,见报文 Packet29 。
3 . TCP 四次挥手关闭连接
经 Packet28 确认收到了完整的 japplication/javascript 文件后,链路 1 (本地端口 5673 )使命结束, S 关闭该链路,进入四次挥手关闭双向连接。
( Packet30 ) Packet31 和 Packet32 为对 Packet29 的 TCP 响应(它们的 Ack=1201 )。 经 Packet33 确认收到了完整的 image/x-icon 文件后,链路 2 (本地端口 5672 )使命结束, S 关闭该链路,进入四次挥手关闭双向连接。
为什么握手是三次,而挥手是四次呢?这是因为握手时,服务器往往在答应建立连接时,也建立与客户端的连接,即所谓的双向连接。所以,在 Packet2 中,服务器将 ACK 和 SYN 打包发出。挥手,即关闭连接,往往只是表明挥手方不再发送数据(无数据可发),而接收通道依然有效(依然可以接受数据)。当对方也挥手时,则表明对方也无数据可发了,此时双向连接真正关闭。
1 .计算机网络的体系结构
计算机网络是一个非常复杂的系统,将整个网络的传输功能进行分层设计的网络结构层次模型及各层协议的集合称为计算机网络的体系结构。为了解决异构互联及通信问题, 20 世纪 70 年代后期国际标准化组织( ISO )制定了 OSI ( Open System Interconnect )开放式系统互联参考模型。该模型采用了三级抽象,即体系结构、服务定义和协议规格说明,是一种标准化的理论参考模型。
开放式互联网( Internet )发展的第一阶段是从单个网络 ARPANET 向互联网发展的过程,以 1983 年 TCP/IP 协议成为 ARPANET 上的标准协议为里程碑。 TCP/IP 是事实上的国际标准。
2 . TCP/IP 参考模型
TCP/IP ,全称为 Transfer Controln Protocol/Internet Protocol ,即传输控制 / 网际协议,它并不单只 TCP 和 IP 这两个协议,而是用于计算机通信的一组协议,我们通常称之为 TCP/IP 协议族。
TCP/IP 是四层的体系结构:应用层、运输层、网际层和网络接口层。但最下面的网络接口层并没有具体内容。因此往往采取折中的办法,即综合 OSI 和 TCP/IP 的优点,采用一种只有五层协议的体系结构,如图 1 所示。
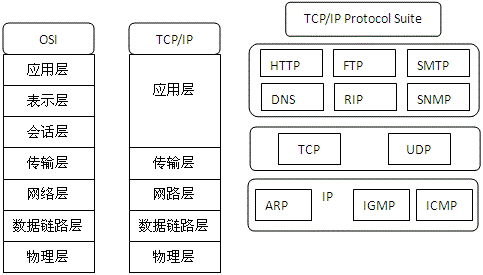 图 1 OSI 体系结构与 TCP/IP 体系结构的关系
2.1 .物理层( Physical Layer )
物理层把比特流传送到物理媒体。电气信号(或光信号)在物理媒体中传播,比特流从发送端物理层传送到接收端物理层。物理层接收到比特流,上交给数据链路层。主机的网卡、 RJ45 以太网接口、网线等硬件设备均属于物理层范畴。
2.2 .数据链路层( Data Link Layer )
数据链路层也称为网络接口层,它的功能是将网络层提交的数据报( IP Datagram )封装成(以太网)帧后提交给物理层,或从物理链路上接收到的数据帧中萃取数据报提交给网络层。
对于一个给定的(物理)连接来说,链路层协议主要实现在网络适配器中,即我们常说的网卡( NIC , Network Interface Card )。传输节点的网络层把 IP 数据报传递到适配器,由适配器将此数据报封装到链路层的帧中,然后把这个帧传输到物理层通信链路。
现在一般都是以太网卡,上面跑的是以太网驱动。 DSL 通信中的 PPPoE 即 Point to Point Protocol over Ethernet ,其层级同网络层。
2.3 .网络层( Network Layer )
Internet 的网络层通过一系列的路由器在源地址和目的地址之间传输数据包,它依赖于底层链路层的服务。由于该层的主要协议是 IP 协议,因而也可简称为 IP 层。它是 TCP/IP 协议栈中最重要的一层,主要功能是可以把源主机上的分片( Fragment )发送到互联网中的任何一台目标主机上。
网络层包含了子网操作,它是懂得网络拓扑结构(网络中机器的物理配置,带宽的限制等)的最高层,也是内网通信的最高层。涉及到 ARP 协议, ICMP 协议, RIP 、 OSPF 、 BGP 等路由协议和路由器设备。
2.4 .传输层( Transport Layer )
我们通常所说的两台主机之间的通信其实是两台主机上对应应用程序之间的通信,传输层提供的就是应用程序之间的通信,也叫端到端( host-to-host end-to-end )的通信。在 TCP/IP 协议族中传输层包含点对点( Peer to Peer )的传输协议:一个是 TCP (传输控制协议);另一个是 UDP (用户数据报协议)。
TCP 是一个可靠的面向连接的协议,它允许源于一个机器的字节流( byte stream )被无错误地传输到 Internet 上的任何机器。 UDP 是一个不可靠无连接的协议,它是为那些不需要 TCP 的序列号管理和流控制而想自己提供这些功能的应用程序设计的。
2.5 .应用层( Application Layer )
应用层是指建立在传输层之上,直接面向用户,向用户提供特定的、常用的应用程序。如远程登录服务( tcp/telnet )、超文本传输协议( tcp/http )、文件传输协议( tcp/ftp )、实时流媒体协议( tcp/rtsp );动态主机设置协议( udp/dhcp)、简单文件传输协议( udp/tftp )、实时传输协议( udp/rtp )等。
鉴于 TCP 和 UDP 协议各自的特性,有些应用综合使用两种协议。例如 DNS 在某些情况下使用 TCP (发送和接收域名数据库),但使用 UDP 传送有关单个主机的信息; RTSP/RTP/RTCP 使用 TCP 实现流点播控制,使用 UDP 实现数据传输及控制。
3 . TCP/IP 协议模块
TCP/IP 协议模块关系如图 2 所示。
图 1 OSI 体系结构与 TCP/IP 体系结构的关系
2.1 .物理层( Physical Layer )
物理层把比特流传送到物理媒体。电气信号(或光信号)在物理媒体中传播,比特流从发送端物理层传送到接收端物理层。物理层接收到比特流,上交给数据链路层。主机的网卡、 RJ45 以太网接口、网线等硬件设备均属于物理层范畴。
2.2 .数据链路层( Data Link Layer )
数据链路层也称为网络接口层,它的功能是将网络层提交的数据报( IP Datagram )封装成(以太网)帧后提交给物理层,或从物理链路上接收到的数据帧中萃取数据报提交给网络层。
对于一个给定的(物理)连接来说,链路层协议主要实现在网络适配器中,即我们常说的网卡( NIC , Network Interface Card )。传输节点的网络层把 IP 数据报传递到适配器,由适配器将此数据报封装到链路层的帧中,然后把这个帧传输到物理层通信链路。
现在一般都是以太网卡,上面跑的是以太网驱动。 DSL 通信中的 PPPoE 即 Point to Point Protocol over Ethernet ,其层级同网络层。
2.3 .网络层( Network Layer )
Internet 的网络层通过一系列的路由器在源地址和目的地址之间传输数据包,它依赖于底层链路层的服务。由于该层的主要协议是 IP 协议,因而也可简称为 IP 层。它是 TCP/IP 协议栈中最重要的一层,主要功能是可以把源主机上的分片( Fragment )发送到互联网中的任何一台目标主机上。
网络层包含了子网操作,它是懂得网络拓扑结构(网络中机器的物理配置,带宽的限制等)的最高层,也是内网通信的最高层。涉及到 ARP 协议, ICMP 协议, RIP 、 OSPF 、 BGP 等路由协议和路由器设备。
2.4 .传输层( Transport Layer )
我们通常所说的两台主机之间的通信其实是两台主机上对应应用程序之间的通信,传输层提供的就是应用程序之间的通信,也叫端到端( host-to-host end-to-end )的通信。在 TCP/IP 协议族中传输层包含点对点( Peer to Peer )的传输协议:一个是 TCP (传输控制协议);另一个是 UDP (用户数据报协议)。
TCP 是一个可靠的面向连接的协议,它允许源于一个机器的字节流( byte stream )被无错误地传输到 Internet 上的任何机器。 UDP 是一个不可靠无连接的协议,它是为那些不需要 TCP 的序列号管理和流控制而想自己提供这些功能的应用程序设计的。
2.5 .应用层( Application Layer )
应用层是指建立在传输层之上,直接面向用户,向用户提供特定的、常用的应用程序。如远程登录服务( tcp/telnet )、超文本传输协议( tcp/http )、文件传输协议( tcp/ftp )、实时流媒体协议( tcp/rtsp );动态主机设置协议( udp/dhcp)、简单文件传输协议( udp/tftp )、实时传输协议( udp/rtp )等。
鉴于 TCP 和 UDP 协议各自的特性,有些应用综合使用两种协议。例如 DNS 在某些情况下使用 TCP (发送和接收域名数据库),但使用 UDP 传送有关单个主机的信息; RTSP/RTP/RTCP 使用 TCP 实现流点播控制,使用 UDP 实现数据传输及控制。
3 . TCP/IP 协议模块
TCP/IP 协议模块关系如图 2 所示。
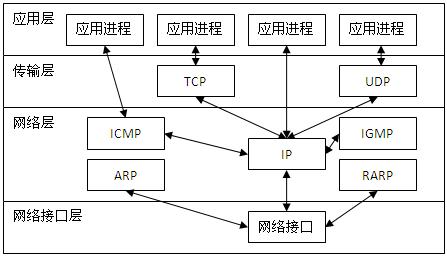 图 2 TCP/IP 协议模块关系
TCP/IP 协议分为四层结构,这四层结构中有两个重要的边界:一个是将操作系统与应用程序分开的边界,另一个是将高层互联网地址与低层物理网卡地址分开的边界,如图 2-3 所示。
图 2 TCP/IP 协议模块关系
TCP/IP 协议分为四层结构,这四层结构中有两个重要的边界:一个是将操作系统与应用程序分开的边界,另一个是将高层互联网地址与低层物理网卡地址分开的边界,如图 2-3 所示。
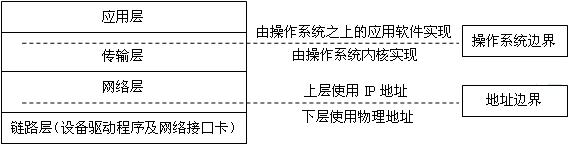 图 3 TCP/IP 协议模型的两个边界
3.1 .操作系统边界
操作系统边界的上面是应用层,应用层处理的是用户应用程序(用户进程)的细节问题,提供面向用户的服务。
3.2 .地址边界
地址边界的上层为网络层,网络层用于对不同的网络进行互联,连接在一起的所有网络为了能互相寻址,要使用统一的互联网地址( IP 地址)。
4 .基于 TCP/IP 架构的网络通信模型
如图 4 所示的 TCP/IP 协议通信模型,这个模型尽管是由分析主机 A 和主机 B 通信而来的,但该模型是一个一般的模型,也适合于网络中其他主机之间的通信描述。
该模型中,主机 A 和主机 1 组成了端到端( Endpoint to Endpoint )的系统。
图 3 TCP/IP 协议模型的两个边界
3.1 .操作系统边界
操作系统边界的上面是应用层,应用层处理的是用户应用程序(用户进程)的细节问题,提供面向用户的服务。
3.2 .地址边界
地址边界的上层为网络层,网络层用于对不同的网络进行互联,连接在一起的所有网络为了能互相寻址,要使用统一的互联网地址( IP 地址)。
4 .基于 TCP/IP 架构的网络通信模型
如图 4 所示的 TCP/IP 协议通信模型,这个模型尽管是由分析主机 A 和主机 B 通信而来的,但该模型是一个一般的模型,也适合于网络中其他主机之间的通信描述。
该模型中,主机 A 和主机 1 组成了端到端( Endpoint to Endpoint )的系统。
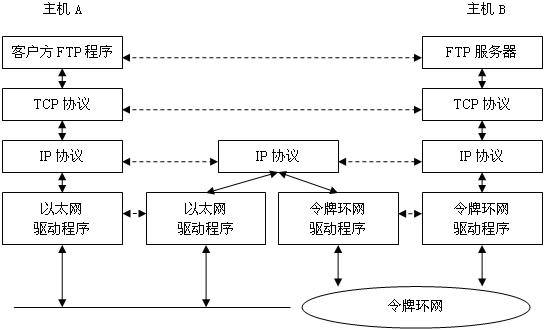 图 4 TCP/IP 协议的通信模型
图 4 TCP/IP 协议的通信模型
多线程级别的并行计算
写多线程应用程序最困难的地方在于如何使各线程的工作协调进行。Windows提供的用于线程间通信的各种机制是很容易掌握的,可是要把它们应用到工作中完成既定的功能时就会遇到这样、那样的困难。
对于常见的“生产者-消费者”模型,只要采取合理同步措施实现数据交换的统一性即可。这类模型中的多线程往往任务独立,主要两类线程,一类写线程(生产者),一类读线程(消费者)。但在实际应用中,多核机器往往需要使用多线程来协作处理一项大规模的计算任务,这涉及到并行计算的概念和多核编程技术。
如何让多个处理器(多个线程)协作完成一项大规模的任务,涉及到任务的分解和调度。因此,多核编程技术的关键问题在于如何将计算均匀分摊到各个CPU核上。并行(Parallel)计算,即空间复用多个处理器,属于线程级别上的协作。
关于多线程协作,参阅王艳平著《Windows程序设计》第3章《Win32程序的执行单元》中的CRapidFinder例程。该例程演示了如何使用多线程协助完成文件搜索任务。
多进程协助完成任务—分布式计算的滥觞
分布式计算则是进程级别上的协作,它是一种把需要进行大量计算的工程数据分割成小块,由多台计算机分别计算,在上传运算结果后再统一合并得出数据结论的技术。
现代大规模CG视觉特效的渲染系统有很多渲染节点组成,采用领先的分布式渲染技术,系统将自动确定网络中可用的渲染节点和资源,同时将将任务分解到相应渲染节点,自动负载平衡功能可以优化工作流程中每个渲染节点的使用效率。
从《后天》到《2012》,再到《阿凡达》,这些大电影,其数以PB计艰苦卓绝的渲染工作无不依赖于现代分布式集群工作站的协同作战。
线程的池化管理
通常情况下,内存的分配和释放通常都是mallloc和free显式进行的。对同一块内存的多次释放通常会导致页面错误,而一直不释放又导致内存泄露,并且使系统性能大大下降。
频繁地创建和销毁内存资源是很耗时间的,因为创建一个对象要获取内存资源或者其它更多资源。malloc/free操纵的是进程堆内存,C/C++运行库不允许两个线程同时从内存堆中分配内存,这种多线程同步操作也是相当耗时的。
对于共享资源,有一个很著名的设计模式:资源池(Resource Pool)。该模式正是为了解决资源的频繁分配和释放所造成的问题。如何利用已有对象来服务就是一个需要解决的关键问题,其实这就是一些“池化资源”技术产生的原因。数据库连接池、内存池等正是基于这一思想而产生的。
对于单核PC,多线程微观串行;对于多处理器系统,使用多线程技术可以充分发挥硬件的优势。理论上,安装了N核CPU的PC,在某一时刻,系统底层所能并发执行的线程个数为N。然而,线程的数量并不是多多益善。首先,线程这种内核资源的创建和销毁本身就很耗系统资源;其次,频繁的线程上下文切换也会耗费较多的CPU时钟周期。借鉴数据库连接池和内存池的池化管理思想,对于线程也可以实行池化管理。
在讨论WinSock的五种I/O模型中,选择模型(select、WSAAsyncSelcet、WSAEventSelect)基于消息轮询或事件等待,对于多用户并发响应往往为每个客户连接创建一个I/O伺服线程。这种单连接单线程的处理方式,对于中小型服务器较为通用,但对大规模多用户的服务器的高并发需求无能为力。完成端口模型本质上利用了Win32重叠I/O机制,底层利用完成端口队列对象来管理一个线程池。关于线程池规模,根据经验为每个处理器创建2个线程,即工作线程数为CPU数的两倍,因为并不是每个线程都是可调度的。参考《深度探索I/O完成端口》、《WinSock完成端口I/O模型》。
一个大规模高并发的服务器对于资源的管理至关重要,因此往往同时使用数据库连接池、内存池和线程池,对关键资源实行池化管理。
一般一个简单线程池至少包含下列组成部分。
线程池管理器(ThreadPoolManager):用于创建并管理线程池
工作线程(WorkThread):线程池中线程
任务接口(Task):每个任务必须实现的接口,以供工作线程调度任务的执行。
任务队列:用于存放没有处理的任务。提供一种缓冲机制。
基于IOCP使用资源池化技术实现高性能的服务器,参阅王艳平、张越著《Windows网络与通信程序设计》第4章《IOCP与可伸缩网络程序》中的CIOCPServer例程。下图为CIOCPServer的系统结构图。
 CIOCPServer系统结构图
赋值操作符
赋值操作符即“=”。赋值操作符为二元操作数,其操作目的是将右操作数的值复制给左操作数。由于左值涉及到写操作,因此左值必须为非const量,而右值在赋值操作中只涉及读操作,因此一般为const量。
赋值操作符通常返回左操作数的引用,这样就不需要创建和撤销运算结果的临时副本。
C/C++编译器支持对内置类型(例如整形int和浮点型double)的赋值运算。
字符数组(字符串)的赋值
对于const变量进行赋值是非法的,例如数组名为不可修改的左值。
char cstr1[6] = "cstr1";
char cstr2[6] = "cstr2";
cstr1 = cstr2; // error C2106: '=' : left operand must be l-value
对于内置类型数组的赋值需要逐个元素进行赋值。对于以上C字符串类型,<string.h>中定义了标准库函数char* strcpy(char *dst, const char *src);用于字符串的赋值。其实现如下:
// strcat.c
char * __cdecl strcpy(char * dst, const char * src)
{
char * cp = dst;
while( *cp++ = *src++ ); /* Copy src over dst */
return( dst );
}
对于非内置类型,如自定义的复数类型complex,我们必须重载赋值操作符“=”,使其支持complex对象之间的赋值。
// complex
_Myt& operator=(const _Myt& _Right)
{ // assign other complex
this->_Val[0] = _Right.real();
this->_Val[1] = _Right.imag();
return (*this);
}
C++标准库string类型封装了C字符串类型的操作,它重载了赋值操作符,但其内部实现同strcpy,也是逐个字符进行(迭代)赋值。
例解CString::operator =
MFC中的字符串处理类CString中对赋值操作符“=”做了多个版本的重载,这样CStirng不仅支持同类对象的赋值,还支持将字符类型(TCHAR)、以及C字符串类型(LPCTSTR、unsigned char*)赋值给CString对象。
// AFX.H
class CString
{
public:
// ……
// ref-counted copy from another CString
const CString& operator=(const CString& stringSrc);
// set string content to single character
const CString& operator=(TCHAR ch);
#ifdef _UNICODE
const CString& operator=(char ch);
#endif
// copy string content from ANSI string (converts to TCHAR)
const CString& operator=(LPCSTR lpsz);
// copy string content from UNICODE string (converts to TCHAR)
const CString& operator=(LPCWSTR lpsz);
// copy string content from unsigned chars
const CString& operator=(const unsigned char* psz);
// ……
}
上述返回值的类型为const CString&,即返回指向const CString对象的引用,返回被赋值对象的引用(return *this;),而加const修饰则说明不允许对返回值进行写操作。
CString afxstr1 = "afxstr1";
CString afxstr2 = "afxstr2";
CString afxStr3 = afxstr2 = afxstr1; // afxStr3 = (afxstr2 = afxstr1);
(afxStr3 = afxstr2) = afxstr1; // error
上述代码中afxstr2 = afxstr1调用const CString& CString::operator=(const CString& stringSrc) 将afxstr1的值赋给afxstr2(AssignCopy)。形如CString::operator=(&afxstr2, afxstr1),其中第一个参数为具体CString对象的this指针。注意CString afxStr3 = afxstr2中的“=”赋值运算符将隐式创建对象,调用构造函数CString::CString(const CString& stringSrc)。C++中的explicit关键字用来修饰类的构造函数,以限制这种隐式转换构造。
(afxStr3 = afxstr2) = afxstr1;试图对赋值操作返回值进行二次赋值是不允许的,因为赋值操作返回值受const限定,不可再作为赋值运算的左值。
类的赋值牵涉到深拷贝和浅拷贝问题,牵涉到拷贝构造函数。CString中的引用计数CStringData::nRefs用来实现在线拷贝(浅拷贝),从而提高内存管理和操作的效率。
CString afxstr1 = "afxstr1"; // CString::CString(LPCTSTR lpsz);
CString afxstr2 = "afxstr2"; // CString::CString(LPCTSTR lpsz);
CString afxstr3 = afxstr1; // CString::CString(const CString& stringSrc)
afxstr3 = afxstr2; // const CString& CString::operator=(const CString& stringSrc)
上述代码中afxstr3 = afxstr2;只是简单的做afxstr3.m_pchData = afxstr2..m_pchData;的指针赋值操作,即just copy references around。
算术操作符
+、-、*、/、%是常用的运算操作符,其用法为expr1+expr2、expr1-expr2、expr1*expr2、expr1/expr2、expr1%expr2。它们皆为二元操作符,即它们作用于两个操作数,其中expr1为左操作数,expr2为右操作数。运算结果为同类操作数(对象),一般使用赋值操作符对运算结果进行接收,形如res= expr1+expr2。
“+=、-=、*=、/=、%=”等为复合赋值运算符,它表示把右边的表达式加到左边的操作数的当前值上,因此左操作数又充当了运算结果的接收者。其调用形式与赋值操作符相同,如expr1+=expr2,实际操作为expr1=expr1+expr2。鉴于左操作数既做操作数又做返回值接收器,因此复合赋值运算符通常也返回左操作数的引用。
C/C++编译器支持对内置类型(例如整形int和浮点型double)的算术运算。
// <1>基本内置类型
int n1 = 2010;
int n2 = 2;
int n3 = n1+n2; // OK. n3 is the sum of n1 and n2.
字符串的+连接操作
我们使用+运算符企图连接两个字符串是错误的,因为C/C++编译器对于字符串类型(char[])没有提供内置的衔接操作。因此,我们必须重载“+”运算符实现期望的操作。<string.h>中定义了标准库函数char* strcat(char *dst, const char *src);用于字符串的连接。
// strcat.c
char * __cdecl strcat (char * dst, const char * src)
{
char * cp = dst;
while( *cp )
cp++; /* find end of dst */
while( *cp++ = *src++ ) ; /* Copy src to end of dst */
return( dst ); /* return dst */
}
// <2>(字符)数组类型
char cstr1[6] = "cstr1";
char cstr2[6] = "cstr2";
char cstr3[12] = {0};
cstr3 = cstr1+cstr2; // error C2110: cannot add two pointers
strcat(cstr3, cstr1);
strcat(cstr3, cstr2);
C++标准库string类型重载了“+、+=”操作符,但其内部实现同strcat。
例解CString::operator +(=)
MFC中的字符串处理类CString中对赋值操作符“+、+=”做了多个版本的重载,这样CStirng不仅支持同类对象的连接,还支持将字符类型(TCHAR)、以及C字符串类型(LPCTSTR)连接到CString对象上。
// AFX.H
class CString
{
public:
// ……
// concatenate from another CString
const CString& operator+=(const CString& string);
// concatenate a single character
const CString& operator+=(TCHAR ch);
#ifdef _UNICODE
// concatenate an ANSI character after converting it to TCHAR
const CString& operator+=(char ch);
#endif
// concatenate a UNICODE character after converting it to TCHAR
const CString& operator+=(LPCTSTR lpsz);
friend CString AFXAPI operator+(const CString& string1, const CString& string2)
{
// STRCOR.CPP
CString s; // temporary object for concat result
s.ConcatCopy(string1.GetData()->nDataLength, string1.m_pchData,
string2.GetData()->nDataLength, string2.m_pchData);
return s;
}
friend CString AFXAPI operator+(const CString& string, TCHAR ch);
friend CString AFXAPI operator+(TCHAR ch, const CString& string);
#ifdef _UNICODE
friend CString AFXAPI operator+(const CString& string, char ch);
friend CString AFXAPI operator+(char ch, const CString& string);
#endif
friend CString AFXAPI operator+(const CString& string, LPCTSTR lpsz);
friend CString AFXAPI operator+(LPCTSTR lpsz, const CString& string);
// ……
}
由于operator+是对两个CString相关的对象的连接操作,不属单对象操作,因此它们应是全局函数(AFXAPI),被设置为CString的友元成员(函数)。而CString对象作为操作数不涉及写访问,因此一般定义const常量;而为避免副本带来的内存开销,一般传入引用,即const CString& string。当然,对于内置类型TCHAR作为操作数,一般不考虑副本内存开销的问题。
CString afxstr1 = "afxstr1";
CString afxstr2 = "afxstr2";
CString afxstr3 = afxstr1+afxstr2;
上述代码中afxstr3 = afxstr1+afxstr2;调用CString operator+(const CString& string1, const CString& string2),即operator+(afxstr1, afxstr2),“afxstr3 =”将存放afxstr1+afxstr2结果的临时对象s拷贝给afxstr3。
另外,可参考MFC中CPoint、CSize和CRect之间的运算操作。
下标操作符
可以从容器中检索单个元素的容器类一般会定义下标操作符,即 operator[]。C/C++编译器定义了对内置类型数组的下标访问。标准库的类 string 和 vector 均定义了下标操作符。
定义下标操作符比较复杂的地方在于,它在用作赋值的左右操作符数时都应该能表现正常。下标操作符出现在左边,必须生成左值,可以指定引用作为返回类型而得到左值。只要下标操作符返回引用,就可用作赋值的任意一方。
下标操作符必须定义为类成员函数,一般需要定义两个版本:一个为非 const 成员并返回引用,另一个为 const 成员并返回 const 引用。
例解一:CString::operator[]
MFC封装的是对C字符串的操作,因此提供了operator[],以对内部字符缓冲区((LPTSTR m_pchData)做char[]索引访问(读和写)。
class CString
{
public:
// ……
// return single character at zero-based index
TCHAR operator[](int nIndex) const { return m_pchData[nIndex]; }
// ……
}
例解二:CArray::operator[]
MFC中的数组集合类CArray 对operator[]的重载为普通的数组索引访问。
// AFXTEMPL.H
template<class TYPE, class ARG_TYPE>
class CArray : public CObject
{
public:
// ……
// overloaded operator helpers
TYPE operator[](int nIndex) const { return GetAt(nIndex); }
TYPE& operator[](int nIndex) { return ElementAt(nIndex); }
// ……
}
注意上述CArray::operator[]两个版本的区别在于第一个版本后面的const修饰传递给该函数的this指针,即const对象调用operator[]的第一个版本(传入const CArray* const this指针),非const对象调用operator[]的第二个版本(传入CArray*const this指针)。
如果只定义了第一个版本,没有定义第二个版本,非const对象调用operator[]实际上对传入的非const指针进行了const隐式转换。
例解三:CMap::operator[]
字典映射类CMap对operator[]的重载是哈希查找。实现由key查找value的“索引”访问,同时又可对索引返回值进行赋值(形如map[key] = value,先Get后Set)。
template<class KEY, class ARG_KEY, class VALUE, class ARG_VALUE>
class CMap : public CObject
{
// ……
// Lookup and add if not there
VALUE& operator[](ARG_KEY key);
// ……
}
类型转换符
在对内置类型进行二元运算时,如果两个操作数类型不一致,编译器会进行隐式转换。
int n = 0;
n = 3.541 + 3; // warning C4244: '=' : conversion from 'const double' to 'int', possible loss of data
以上代码n = 3.541 + 3在编译时检查到该表达式需进行类型转换,将给出double向int截断转换的精度损失警告,其在运行期等效于n = (int)((double)3.541+(double)3);这个是编译器对内置类型的自动隐式转换支持。
例解一:CString::operator LPCTSTR
我们在对字符串进行处理的时候,难免会遭遇char*(char[])与string或CString的混合处理问题。例如我们可能需要将char字符数组(C字符串)拷贝给CString对象,或将CString对象的值拷贝到char字符数组(C字符串)中。
char cstr[16] = "c string";
CString afxstr = "CString";
strcpy(cstr, afxstr); // right
printf("afxstr = %s", afxstr); // right
strcpy(afxstr, cstr); // error
strcpy((char*)(LPCTSTR)afxstr, cstr); // right
afxstr = cstr; // invoke const CString& CString::operator=(&afxstr, LPCSTR lpsz);
代码strcpy(cstr, afxstr)和printf("afxstr = %s", afxstr)运行时,将试图对CString对象afxstr做向const char*的转换(const char*)(afxstr)以满足形参二的预期类型。在非UNICODE环境下,const *char即LPCTSTR,因此这里将调用CString提供的LPCTSTR转换符,形如CString::operator LPCTSTR(&afxstr),其中&afxstr即为对象的this指针,返回CString对象afxstr内部指向缓冲区的常量指针:this->m_pchData。
代码strcpy(afxstr, cstr);是错误的,因为对CString对象的引用无法直接对其数据区(LPTSTR m_pchData;)进行写访问的,不存在这种转换支持。但若我们对afxstr进行强制char*去cosnt转换(C++中的const_cast) ,即strcpy((char*)(LPCTSTR)afxstr, cstr);编译运行都正确。但一般不提倡这么做,获取CString内部指向缓冲区的非常量指针(LPTSTR m_pchData;)的安全做法是调用CString的GetBuffer()方法。
实际上,CString类重载的operator=赋值运算符,具体为const CString& operator=(LPCSTR lpsz)支持将char字符数组(C字符串)直接对CString对象进行赋值,直接afxstr = cstr;即可。
// AFX.H
class CString
{
public:
// ……
// return pointer to const string
operator LPCTSTR() const { return m_pchData; }
// get pointer to modifiable buffer at least as long as nMinBufLength
LPTSTR GetBuffer(int nMinBufLength);
// ……
}
例解二:CTypeSimpleList::operator TYPE
MFC线程局部存储中使用到的简单模板链表CTypedSimpleList中TYPE()操作符,使得链表支持直接引用对象,以返回链表首节点。
// AFXTLS_.H
template<class TYPE>
class CTypedSimpleList : public CSimpleList
{
public:
// ……
operator TYPE()
{ return (TYPE)CSimpleList::GetHead(); }
};
下列代码片段演示了CTypedSimpleList的使用。
MyThreadData* pData;
CTypedSimpleList<MyThreadData*> list;
list.Construct(offsetof(MyThreadData, pNext));
// 向链表中添加成员
for(int i=0; i<10; i++)
{
pData = new MyThreadData;
pData->nSomeData = i;
list.AddHead(pData);
}
// ………… // 使用链表中的数据
// 遍历整个链表,释放MyThreadData对象占用的空间
pData = list; // 调用了成员函数 operator TYPE(),相当于“pData = list.GetHead();”语句
while(pData != NULL)
{
// ……
}
上面代码中,pData = list;赋值语句中,左值为数据类型,右值为链表类型,对右值进行隐式类型转换才能实现赋值:pData = (MyThreadData*)(list);编译时检查有无此转换支持(即检查CTypedSimpleList 是否存在TYPE()转换符操作支持)。其中MyThreadData*即TYPE,因此运行期调用CTypedSimpleList的operator TYPE()转换符,即CTypedSimpleList::TYPE(&list)àlist.GetHead(),返回链表的首节点。
例解三:CWnd::operator HWND; CAsyncSocket::operator SOCKET; …
MFC中封装某种内核对象的类一般都支持对其内核对象做类型转换,典型的如CWndàHWND。
class CWnd : public CCmdTarget
{
// ……
// Attributes
public:
HWND m_hWnd; // must be first data member
operator HWND() const;
// ……
}
CWnd只不过封装了窗口对象HWND的操作,因此在调用需要HWND参数的API时,也可直接传入CWnd对象。
类似的还有CAsyncSocketàSOCKET。
class CAsyncSocket : public CObject
{
// ……
// Attributes
public:
SOCKET m_hSocket;
operator SOCKET() const;
// ……
}
关系操作符
关系操作符主要指同类对象的值大小比较,包括等于(==)、大于(>)、小于(<)等。关系操作符与算术操作符一样都是二元操作符,不过关系操作符返回的是布尔值。
字符'/0'和'0'的区别
字符’0’对应的ASCII码为十六进制30;而’/0’即为ASCII码中的0,其对应字符空字符NUL。
char c = '/0';çèchar c = 0 // NUL
char c = '0';çèchar c = 48;
最典型如memset函数:void *memset( void *buffer, int ch, size_t count );
将一段长为count字节的内存块初始化为ASCII码值0,字符为NUL:
memset(pBuffer, '/0', sizeof(pBuffer) );çèmemset(pBuffer, 0, sizeof(pBuffer) );
字符串
字符串常量是双引号括起的任意字符序列。
例如:"Hello World","Fantasy","Please enter your full name:",……
C语言没有专门定义字符串数据类型(如其他语言中的string) ,所谓的字符串,只是对字符数组的一种特殊应用而已,它用以'/0'结尾的字符数组来表示一个逻辑意义上的字符串。
在字符串常量中,显然不能直接写双引号,因为这将被认为是字符串的结束。转义序列在字符串常量中要包含双引号,需要用“/"”表示。如:"Hello /"Accp/""
与字符数组不同的是:在存完字符串常量的所有字符之后,还要另存一个空字符'/0'作为结束的标志,空字符是ASCII码值为0的字符,C语言中用'/0'标识字符串的结束,所以也称为结束符。如果在程序里写了字符串:char hello[]="HELLO"或{"HELLO"};虽然只有5个字符,在内存中却需要占用6个字节存储,其中'/0'表示空字符。存储情况如:
CIOCPServer系统结构图
赋值操作符
赋值操作符即“=”。赋值操作符为二元操作数,其操作目的是将右操作数的值复制给左操作数。由于左值涉及到写操作,因此左值必须为非const量,而右值在赋值操作中只涉及读操作,因此一般为const量。
赋值操作符通常返回左操作数的引用,这样就不需要创建和撤销运算结果的临时副本。
C/C++编译器支持对内置类型(例如整形int和浮点型double)的赋值运算。
字符数组(字符串)的赋值
对于const变量进行赋值是非法的,例如数组名为不可修改的左值。
char cstr1[6] = "cstr1";
char cstr2[6] = "cstr2";
cstr1 = cstr2; // error C2106: '=' : left operand must be l-value
对于内置类型数组的赋值需要逐个元素进行赋值。对于以上C字符串类型,<string.h>中定义了标准库函数char* strcpy(char *dst, const char *src);用于字符串的赋值。其实现如下:
// strcat.c
char * __cdecl strcpy(char * dst, const char * src)
{
char * cp = dst;
while( *cp++ = *src++ ); /* Copy src over dst */
return( dst );
}
对于非内置类型,如自定义的复数类型complex,我们必须重载赋值操作符“=”,使其支持complex对象之间的赋值。
// complex
_Myt& operator=(const _Myt& _Right)
{ // assign other complex
this->_Val[0] = _Right.real();
this->_Val[1] = _Right.imag();
return (*this);
}
C++标准库string类型封装了C字符串类型的操作,它重载了赋值操作符,但其内部实现同strcpy,也是逐个字符进行(迭代)赋值。
例解CString::operator =
MFC中的字符串处理类CString中对赋值操作符“=”做了多个版本的重载,这样CStirng不仅支持同类对象的赋值,还支持将字符类型(TCHAR)、以及C字符串类型(LPCTSTR、unsigned char*)赋值给CString对象。
// AFX.H
class CString
{
public:
// ……
// ref-counted copy from another CString
const CString& operator=(const CString& stringSrc);
// set string content to single character
const CString& operator=(TCHAR ch);
#ifdef _UNICODE
const CString& operator=(char ch);
#endif
// copy string content from ANSI string (converts to TCHAR)
const CString& operator=(LPCSTR lpsz);
// copy string content from UNICODE string (converts to TCHAR)
const CString& operator=(LPCWSTR lpsz);
// copy string content from unsigned chars
const CString& operator=(const unsigned char* psz);
// ……
}
上述返回值的类型为const CString&,即返回指向const CString对象的引用,返回被赋值对象的引用(return *this;),而加const修饰则说明不允许对返回值进行写操作。
CString afxstr1 = "afxstr1";
CString afxstr2 = "afxstr2";
CString afxStr3 = afxstr2 = afxstr1; // afxStr3 = (afxstr2 = afxstr1);
(afxStr3 = afxstr2) = afxstr1; // error
上述代码中afxstr2 = afxstr1调用const CString& CString::operator=(const CString& stringSrc) 将afxstr1的值赋给afxstr2(AssignCopy)。形如CString::operator=(&afxstr2, afxstr1),其中第一个参数为具体CString对象的this指针。注意CString afxStr3 = afxstr2中的“=”赋值运算符将隐式创建对象,调用构造函数CString::CString(const CString& stringSrc)。C++中的explicit关键字用来修饰类的构造函数,以限制这种隐式转换构造。
(afxStr3 = afxstr2) = afxstr1;试图对赋值操作返回值进行二次赋值是不允许的,因为赋值操作返回值受const限定,不可再作为赋值运算的左值。
类的赋值牵涉到深拷贝和浅拷贝问题,牵涉到拷贝构造函数。CString中的引用计数CStringData::nRefs用来实现在线拷贝(浅拷贝),从而提高内存管理和操作的效率。
CString afxstr1 = "afxstr1"; // CString::CString(LPCTSTR lpsz);
CString afxstr2 = "afxstr2"; // CString::CString(LPCTSTR lpsz);
CString afxstr3 = afxstr1; // CString::CString(const CString& stringSrc)
afxstr3 = afxstr2; // const CString& CString::operator=(const CString& stringSrc)
上述代码中afxstr3 = afxstr2;只是简单的做afxstr3.m_pchData = afxstr2..m_pchData;的指针赋值操作,即just copy references around。
算术操作符
+、-、*、/、%是常用的运算操作符,其用法为expr1+expr2、expr1-expr2、expr1*expr2、expr1/expr2、expr1%expr2。它们皆为二元操作符,即它们作用于两个操作数,其中expr1为左操作数,expr2为右操作数。运算结果为同类操作数(对象),一般使用赋值操作符对运算结果进行接收,形如res= expr1+expr2。
“+=、-=、*=、/=、%=”等为复合赋值运算符,它表示把右边的表达式加到左边的操作数的当前值上,因此左操作数又充当了运算结果的接收者。其调用形式与赋值操作符相同,如expr1+=expr2,实际操作为expr1=expr1+expr2。鉴于左操作数既做操作数又做返回值接收器,因此复合赋值运算符通常也返回左操作数的引用。
C/C++编译器支持对内置类型(例如整形int和浮点型double)的算术运算。
// <1>基本内置类型
int n1 = 2010;
int n2 = 2;
int n3 = n1+n2; // OK. n3 is the sum of n1 and n2.
字符串的+连接操作
我们使用+运算符企图连接两个字符串是错误的,因为C/C++编译器对于字符串类型(char[])没有提供内置的衔接操作。因此,我们必须重载“+”运算符实现期望的操作。<string.h>中定义了标准库函数char* strcat(char *dst, const char *src);用于字符串的连接。
// strcat.c
char * __cdecl strcat (char * dst, const char * src)
{
char * cp = dst;
while( *cp )
cp++; /* find end of dst */
while( *cp++ = *src++ ) ; /* Copy src to end of dst */
return( dst ); /* return dst */
}
// <2>(字符)数组类型
char cstr1[6] = "cstr1";
char cstr2[6] = "cstr2";
char cstr3[12] = {0};
cstr3 = cstr1+cstr2; // error C2110: cannot add two pointers
strcat(cstr3, cstr1);
strcat(cstr3, cstr2);
C++标准库string类型重载了“+、+=”操作符,但其内部实现同strcat。
例解CString::operator +(=)
MFC中的字符串处理类CString中对赋值操作符“+、+=”做了多个版本的重载,这样CStirng不仅支持同类对象的连接,还支持将字符类型(TCHAR)、以及C字符串类型(LPCTSTR)连接到CString对象上。
// AFX.H
class CString
{
public:
// ……
// concatenate from another CString
const CString& operator+=(const CString& string);
// concatenate a single character
const CString& operator+=(TCHAR ch);
#ifdef _UNICODE
// concatenate an ANSI character after converting it to TCHAR
const CString& operator+=(char ch);
#endif
// concatenate a UNICODE character after converting it to TCHAR
const CString& operator+=(LPCTSTR lpsz);
friend CString AFXAPI operator+(const CString& string1, const CString& string2)
{
// STRCOR.CPP
CString s; // temporary object for concat result
s.ConcatCopy(string1.GetData()->nDataLength, string1.m_pchData,
string2.GetData()->nDataLength, string2.m_pchData);
return s;
}
friend CString AFXAPI operator+(const CString& string, TCHAR ch);
friend CString AFXAPI operator+(TCHAR ch, const CString& string);
#ifdef _UNICODE
friend CString AFXAPI operator+(const CString& string, char ch);
friend CString AFXAPI operator+(char ch, const CString& string);
#endif
friend CString AFXAPI operator+(const CString& string, LPCTSTR lpsz);
friend CString AFXAPI operator+(LPCTSTR lpsz, const CString& string);
// ……
}
由于operator+是对两个CString相关的对象的连接操作,不属单对象操作,因此它们应是全局函数(AFXAPI),被设置为CString的友元成员(函数)。而CString对象作为操作数不涉及写访问,因此一般定义const常量;而为避免副本带来的内存开销,一般传入引用,即const CString& string。当然,对于内置类型TCHAR作为操作数,一般不考虑副本内存开销的问题。
CString afxstr1 = "afxstr1";
CString afxstr2 = "afxstr2";
CString afxstr3 = afxstr1+afxstr2;
上述代码中afxstr3 = afxstr1+afxstr2;调用CString operator+(const CString& string1, const CString& string2),即operator+(afxstr1, afxstr2),“afxstr3 =”将存放afxstr1+afxstr2结果的临时对象s拷贝给afxstr3。
另外,可参考MFC中CPoint、CSize和CRect之间的运算操作。
下标操作符
可以从容器中检索单个元素的容器类一般会定义下标操作符,即 operator[]。C/C++编译器定义了对内置类型数组的下标访问。标准库的类 string 和 vector 均定义了下标操作符。
定义下标操作符比较复杂的地方在于,它在用作赋值的左右操作符数时都应该能表现正常。下标操作符出现在左边,必须生成左值,可以指定引用作为返回类型而得到左值。只要下标操作符返回引用,就可用作赋值的任意一方。
下标操作符必须定义为类成员函数,一般需要定义两个版本:一个为非 const 成员并返回引用,另一个为 const 成员并返回 const 引用。
例解一:CString::operator[]
MFC封装的是对C字符串的操作,因此提供了operator[],以对内部字符缓冲区((LPTSTR m_pchData)做char[]索引访问(读和写)。
class CString
{
public:
// ……
// return single character at zero-based index
TCHAR operator[](int nIndex) const { return m_pchData[nIndex]; }
// ……
}
例解二:CArray::operator[]
MFC中的数组集合类CArray 对operator[]的重载为普通的数组索引访问。
// AFXTEMPL.H
template<class TYPE, class ARG_TYPE>
class CArray : public CObject
{
public:
// ……
// overloaded operator helpers
TYPE operator[](int nIndex) const { return GetAt(nIndex); }
TYPE& operator[](int nIndex) { return ElementAt(nIndex); }
// ……
}
注意上述CArray::operator[]两个版本的区别在于第一个版本后面的const修饰传递给该函数的this指针,即const对象调用operator[]的第一个版本(传入const CArray* const this指针),非const对象调用operator[]的第二个版本(传入CArray*const this指针)。
如果只定义了第一个版本,没有定义第二个版本,非const对象调用operator[]实际上对传入的非const指针进行了const隐式转换。
例解三:CMap::operator[]
字典映射类CMap对operator[]的重载是哈希查找。实现由key查找value的“索引”访问,同时又可对索引返回值进行赋值(形如map[key] = value,先Get后Set)。
template<class KEY, class ARG_KEY, class VALUE, class ARG_VALUE>
class CMap : public CObject
{
// ……
// Lookup and add if not there
VALUE& operator[](ARG_KEY key);
// ……
}
类型转换符
在对内置类型进行二元运算时,如果两个操作数类型不一致,编译器会进行隐式转换。
int n = 0;
n = 3.541 + 3; // warning C4244: '=' : conversion from 'const double' to 'int', possible loss of data
以上代码n = 3.541 + 3在编译时检查到该表达式需进行类型转换,将给出double向int截断转换的精度损失警告,其在运行期等效于n = (int)((double)3.541+(double)3);这个是编译器对内置类型的自动隐式转换支持。
例解一:CString::operator LPCTSTR
我们在对字符串进行处理的时候,难免会遭遇char*(char[])与string或CString的混合处理问题。例如我们可能需要将char字符数组(C字符串)拷贝给CString对象,或将CString对象的值拷贝到char字符数组(C字符串)中。
char cstr[16] = "c string";
CString afxstr = "CString";
strcpy(cstr, afxstr); // right
printf("afxstr = %s", afxstr); // right
strcpy(afxstr, cstr); // error
strcpy((char*)(LPCTSTR)afxstr, cstr); // right
afxstr = cstr; // invoke const CString& CString::operator=(&afxstr, LPCSTR lpsz);
代码strcpy(cstr, afxstr)和printf("afxstr = %s", afxstr)运行时,将试图对CString对象afxstr做向const char*的转换(const char*)(afxstr)以满足形参二的预期类型。在非UNICODE环境下,const *char即LPCTSTR,因此这里将调用CString提供的LPCTSTR转换符,形如CString::operator LPCTSTR(&afxstr),其中&afxstr即为对象的this指针,返回CString对象afxstr内部指向缓冲区的常量指针:this->m_pchData。
代码strcpy(afxstr, cstr);是错误的,因为对CString对象的引用无法直接对其数据区(LPTSTR m_pchData;)进行写访问的,不存在这种转换支持。但若我们对afxstr进行强制char*去cosnt转换(C++中的const_cast) ,即strcpy((char*)(LPCTSTR)afxstr, cstr);编译运行都正确。但一般不提倡这么做,获取CString内部指向缓冲区的非常量指针(LPTSTR m_pchData;)的安全做法是调用CString的GetBuffer()方法。
实际上,CString类重载的operator=赋值运算符,具体为const CString& operator=(LPCSTR lpsz)支持将char字符数组(C字符串)直接对CString对象进行赋值,直接afxstr = cstr;即可。
// AFX.H
class CString
{
public:
// ……
// return pointer to const string
operator LPCTSTR() const { return m_pchData; }
// get pointer to modifiable buffer at least as long as nMinBufLength
LPTSTR GetBuffer(int nMinBufLength);
// ……
}
例解二:CTypeSimpleList::operator TYPE
MFC线程局部存储中使用到的简单模板链表CTypedSimpleList中TYPE()操作符,使得链表支持直接引用对象,以返回链表首节点。
// AFXTLS_.H
template<class TYPE>
class CTypedSimpleList : public CSimpleList
{
public:
// ……
operator TYPE()
{ return (TYPE)CSimpleList::GetHead(); }
};
下列代码片段演示了CTypedSimpleList的使用。
MyThreadData* pData;
CTypedSimpleList<MyThreadData*> list;
list.Construct(offsetof(MyThreadData, pNext));
// 向链表中添加成员
for(int i=0; i<10; i++)
{
pData = new MyThreadData;
pData->nSomeData = i;
list.AddHead(pData);
}
// ………… // 使用链表中的数据
// 遍历整个链表,释放MyThreadData对象占用的空间
pData = list; // 调用了成员函数 operator TYPE(),相当于“pData = list.GetHead();”语句
while(pData != NULL)
{
// ……
}
上面代码中,pData = list;赋值语句中,左值为数据类型,右值为链表类型,对右值进行隐式类型转换才能实现赋值:pData = (MyThreadData*)(list);编译时检查有无此转换支持(即检查CTypedSimpleList 是否存在TYPE()转换符操作支持)。其中MyThreadData*即TYPE,因此运行期调用CTypedSimpleList的operator TYPE()转换符,即CTypedSimpleList::TYPE(&list)àlist.GetHead(),返回链表的首节点。
例解三:CWnd::operator HWND; CAsyncSocket::operator SOCKET; …
MFC中封装某种内核对象的类一般都支持对其内核对象做类型转换,典型的如CWndàHWND。
class CWnd : public CCmdTarget
{
// ……
// Attributes
public:
HWND m_hWnd; // must be first data member
operator HWND() const;
// ……
}
CWnd只不过封装了窗口对象HWND的操作,因此在调用需要HWND参数的API时,也可直接传入CWnd对象。
类似的还有CAsyncSocketàSOCKET。
class CAsyncSocket : public CObject
{
// ……
// Attributes
public:
SOCKET m_hSocket;
operator SOCKET() const;
// ……
}
关系操作符
关系操作符主要指同类对象的值大小比较,包括等于(==)、大于(>)、小于(<)等。关系操作符与算术操作符一样都是二元操作符,不过关系操作符返回的是布尔值。
字符'/0'和'0'的区别
字符’0’对应的ASCII码为十六进制30;而’/0’即为ASCII码中的0,其对应字符空字符NUL。
char c = '/0';çèchar c = 0 // NUL
char c = '0';çèchar c = 48;
最典型如memset函数:void *memset( void *buffer, int ch, size_t count );
将一段长为count字节的内存块初始化为ASCII码值0,字符为NUL:
memset(pBuffer, '/0', sizeof(pBuffer) );çèmemset(pBuffer, 0, sizeof(pBuffer) );
字符串
字符串常量是双引号括起的任意字符序列。
例如:"Hello World","Fantasy","Please enter your full name:",……
C语言没有专门定义字符串数据类型(如其他语言中的string) ,所谓的字符串,只是对字符数组的一种特殊应用而已,它用以'/0'结尾的字符数组来表示一个逻辑意义上的字符串。
在字符串常量中,显然不能直接写双引号,因为这将被认为是字符串的结束。转义序列在字符串常量中要包含双引号,需要用“/"”表示。如:"Hello /"Accp/""
与字符数组不同的是:在存完字符串常量的所有字符之后,还要另存一个空字符'/0'作为结束的标志,空字符是ASCII码值为0的字符,C语言中用'/0'标识字符串的结束,所以也称为结束符。如果在程序里写了字符串:char hello[]="HELLO"或{"HELLO"};虽然只有5个字符,在内存中却需要占用6个字节存储,其中'/0'表示空字符。存储情况如:
H
E
L
L
O
/0
5005
5006
5007
5008
5009
500A
而字符数组char hello[]={'H','E','L','L','O'};的长度和大小则为5.
根据字符串存储形式的规定,只要在数组里顺序存入所需字符,随后存一个空字符,这个字符数组里的数据就有了字符串的表现形式,这个数组也就可以当作字符串使用了。分析char str[]="abc";因为定义的是一个字符数组,所以就相当于定义了一些空间来存放"abc",而又因为字符数组就是把字符一个一个地存放的,所以编译器把这个语句解析为char str[3] = {'a','b','c'};根据上面的总结,所以char str[]="abc";的最终结果是char str[4] = {'a','b','c','/0'};即char str[] = {'a','b','c','/0'}<==> char str[]="abc"
值得注意的是只有在程序中对字符串进行处理时,才考虑字符串结束标志的问题。考虑字符数组char a[4]={'B','O','Y','/0'};a数组中存放的是字符串“BOY”。如果执行语句a[1]= '/0';后,a数组的内容为'B','/0','Y','/0'。此时系统认为a数组中存放了一个字符串“B”,printf("a=%s/n",a);输出的结果是a=B; printf("length a=%d/n",strlen(a))输出的结果是length a=1, 而printf("sizeof a=%d/n",sizeof(a));输出结果为4.不要认为数组中只有'B'和'/0'了,只不过按系统对字符串的处理方式来看就是这样的。
char s3[10]="HELLO";//s3是编译期大小已经固定的数组
int a=strlen(s3); //a=5;//strlen()在运行起确定
int b=sizeof(s3); //b=10;//sizeof()在编译期确定
sizeof(s)
strlen(s)
char *s="HELLO";
4
5
char s[]="HELLO";
6
5
char s[10]="HELLO";
10
5
注意printf("hello is %s/n",hello);和cout<<hello;以及头文件<string.h>中的库函数只能操作以'/0'结尾的字符串,故对char hello[]={'H','E','L','L','O'};操作无效。
以下为四种hello字符串的定义:
char hello1[]="HELLO";
char hello2[]={"HELLO"}; //等同于hello1
char hello3[]={'H','E','L','L','O','/0'};//等价于hello1
char *hello4="HELLO";//区别:hello1是字符数组,hello4是字符指针。
用strlen函数测试hello1, hello2, hello3, hello4的结果均为5,因为不计末尾结束符’/0’。常用hello1或hello4来定义字符串。
字符串与指针
C语言中许多字符串的操作都由指向字符数组的指针及指针的运算来实现的。因为对字符串来说一般都是严格顺序存取,使用指针可以打破这种存取方式,使字符串的处理更加灵活。
以下代码利用指针简洁的实现了字符串拷贝函数:
void strcpy(s,t)//copy t to s
char *s,*t;
{
while(*s++=*t++);
}
解析:*s++=*t++,先赋值*s=*t,然后指针后移t++,s++,当遇到*t= '/0'时,则拷贝操作完成。
char *pChar;
char *text = "hello";
pChar = new char[strlen(text) + 1]; // 注意这里考虑终止字符!
cout << strcpy(pChar, text) << endl; // 不能用pChar = text;
cout << (strcmp(pChar, text) == 0) << endl; // 不能用pChar == text;
字符串常量
当一个字符串常量出现于表达式中时,它的值是个指针常量。编译器把这些指定字符的一份拷贝存储在内存的某个位置,并存储一个指向第一个字符的指针。
"xyz"+1;//这个表达式计算“指针值加上”的值,返回一个指针,指向字符串中的第二个字符'y'
*"xyz";//返回第一个字符'x'
"xyz"[2];//返回第三个字符'z'
*("xyz"+4);//偏移量超过了这个字符串的范围,返回一个不可预测的字符
那什么使用会用到上述表达式呢?我们考虑把二进制转换为字符并把它们打印出来。
remainder = value % 16;//value对求余保存到remainder中
if(remainder < 10)//0~9
putchar(remainder + '0');
else10~15
putchar(remainder - 10 + 'A');
下面的代码用一种不同的方法解决这个问题:
putchar("0123456789ABCDEF"[value % 16]);
1.指针的初始化
指针变量的零值是“空”(记为NULL)。在<stdio.h>中#define NULL 0,尽管NULL 的值与0 相同,但是两者意义不同。假设指针变量的名字为p,它与零值比较的标准if 语句如下:
if (p == NULL) // p 与NULL 显式比较,强调p 是指针变量。
当我们试图析取(dereference)一个空指针NULL时,例如int *p = NULL;当我们试图cout<<*p;析取p时,将会出现内存读错误。因为0x00000000为进程私有地址,是不允许访问的,因此将会弹出应用程序错误:“0x********”指令引用的“0x00000000”内存。该内存不能“read”。
如果定义指针时把它初始化为NULL,我们的代码就能用if(ptr==NULL)来判断它是不是有效的指针。
因此,建议定义指针后将其初始化为NULL或指向合法内存。
典型错误:char *dest; char *src = "Fantasy"; strcpy(dest, src);
2.检查一个指针是否有效
malloc returns a void pointer to the allocated space, or NULL if there is insufficient memory available.
If there is insufficient memory for the allocation request, by default operator new returns NULL.
用malloc 或new 申请内存之后,应该用if(p==NULL)检查指针值是否为NULL,防止使用指针值为NULL 的内存。如果指针p 是函数的参数,那么在函数的入口处用assert(p!=NULL)进行检查。
3.野指针
1)、指针变量在定义后如果没有初始化是野指针,其值不为NULL,指向一个随机地址。故在使用*析取(dereference)之前,应确保指针指向合法的地址。
2)、delete某个指针后,指针所指向的变量(对象)被释放(生命周期结束),但是该指针变为野指针。
4.delete干掉了什么
一般用new运算符动态分配出来的堆内存,需要我们配对调用delete来显式回收内存,以防内存泄漏。但delete只是把指针所指的内存给释放掉,并没有把指针本身干掉。下面的测试中发现指针pn3被delete以后其地址仍然不变(非NULL),只是该地址对应的内存是垃圾,pn3成了“野指针”。如果此时不把pn3设置为NULL,会让人误以为pn3是个合法的指针。
如果程序比较长,我们有时记不住pn3所指的内存是否已经被释放,在继续使用pn3之前,通常会用语句if (pn3!= NULL)进行防错处理。很遗憾,此时if 语句起不到防错作用,因为即便pn3不是NULL 指针,它也不指向合法的内存块。因此,建议在delete释放了内存之后,应立即将指针赋值为NULL,防止产生“野指针”。
另外,在实际程序中,可能不止在一个模块中操作new申请的内存块,我们可能会将new返回的指针作为参数传递给另一个函数模块处理,以享指针直接操作内存之快捷。但是一定要把握这个指针的生命周期,看哪里不用了就适时delete结束其生命。
通常我们会在析构函数中使用delete,在本对象被析构之前先把对象里使用new实例化的一些对象析构,防止内存泻漏。如果在程序中显式调用delete pClass来清除对象,则delete会去调用被pClass所指向对象的析构函数来释放内存。编译器对普通自动对象将调用其析构函数,但是对于new出来的pClass,则必须显式调用delete将其删除。
5.测试代码
//testPointer.cpp
#include <iostream>
using namespace std;
int main()
{
int *pn1;
cout << "代码:int *pn1;" << endl;
cout << "&pn1 = " << &pn1 << endl;
cout << "pn1 = " << pn1;
// pn1不知所指,可能乱指一气,故下面一句可能有输出
// cout << "*pn1 = " << *pn1 << endl << endl;
pn1 = NULL;
cout << "代码:pn1 = NULL;" << endl;
cout << "pn1 = " << pn1 << endl;
// 若cout << *pn1 试图访问内存0x00000000(NULL)将抛出异常
// 因为内存0x00000000已经被用户进程使用,处于私有保护状态,不能读
int n1 = 5;
pn1 = &n1; // 指针pn1指向n1
cout << "代码:int n1 = " << n1 << ";" << "pn1 = &n1;" << endl;
cout << "&pn1 = " << &pn1 << endl;
cout << "pn1 = " << pn1 << endl;
cout << "*pn1 = " << *pn1 << endl ;//
int n2 = 10;
pn1 = &n2; // 指针pn1另有所指
cout << "代码:int n2 = " << n2 << ";" << "pn1 = &n2;" << endl;
cout << "&pn1 = " << &pn1 << endl;
cout << "pn1 = " << pn1 << endl;
cout << "*pn1 = " << *pn1 << endl;//
// 不能调用delete pn1;因为pn1已经指向了栈里分配的n2
int *pn2 = new int; // int *pn2这个指针变量4 byte是在栈里分配的,
// new int这个4 byte是堆里分配的
cout << "代码:int *pn2 = new int;" << endl;
cout << "&pn2 = " << &pn2 << endl;
cout << "pn2 = " << pn2 << endl;
// 内存分配虽然成功,但是尚未初始化就引用它,以下输出为随机数或记忆数
cout << "*pn2 = " << *pn2 << endl ;
pn2 = &n2; // 指针pn2指向n2
cout << "代码:int n2 = " << n2 << ";" << "pn2 = &n2;" << endl;
cout << "&pn2 = " << &pn2 << endl;
cout << "pn2 = " << pn2 << endl;
cout << "*pn2 = " << *pn2 << endl;
// 不能调用delete pn2;因为此时pn2已经指向栈里分配的n2
// 所以堆上分配的那4 byte内存泄漏了!
int *pn3 = new int; //
*pn3 = 10;
cout << "代码:int *pn3 = new int;*pn3 = " << *pn3 << endl;
cout << "&pn3 = " << &pn3 << endl;
cout << "pn3 = " << pn3 << endl;
cout << "*pn3 = " << *pn3 << endl;
delete pn3; //
cout << "代码:delete pn3;" << endl;
cout << "&pn3 = " << &pn3 << endl;
cout << "pn3 = " << pn3 << endl; // 释放了内存却继续使用它
cout << "*pn3 = " << *pn3 << endl; //
pn3 = NULL; //
cout << "代码:pn3 = NULL;" << endl;
cout << pn3 << endl;
return0;
}
运行结果:
代码:int *pn1;
&pn1 = 0012FF7C //整形指针变量pn1(栈向低地址增长)
pn1 = CCCCCCCC
代码:pn1 = NULL;
pn1 = 00000000
代码:int n1 = 5;pn1 = &n1;
pn1 = 0012FF78 //整形变量n1
*pn1 = 5
代码:int n2 = 10;pn1 = &n2;
pn1 = 0012FF74//整形变量n2
*pn1 = 10
代码:int *pn2 = new int;
&pn2 = 0012FF70//整形指针变量pn2
pn2 = 003724E8//(堆向高地址增长)
*pn2 = -842150451
代码:int n2 = 10;pn2 = &n2;
pn2 = 0012FF74
*pn2 = 10
代码:int *pn3 = new int;*pn3 = 10
&pn3 = 0012FF6C//整形指针变量pn3
pn3 = 00372520
*pn3 = 10
代码:delete pn3;
pn3 = 00372520
*pn3 = -572662307
代码:pn3 = NULL;
00000000
1.变量的数据类型和存储类型
在C语言中,每一个变量都有两个属性:数据类型和存储类型。数据类型即常说的字符型、整型、浮点型;存储类型则指变量在内存中的存储方式,它决定了变量的作用域和生存期。
变量的存储类型有以下四种:auto(自动)、register(寄存器)、extern(外部)和static(静态)。其中auto和register用于声明内部变量,auto变量是存储在栈中的,register变量是存储在寄存器中的。static用于声明内部变量或外部变量,extern用于声明外部变量,它们是存储在静态存储区的。
变量声明的一般形式:<存储类型> <数据类型> <变量名列表>
当声明变量时未指定存储类型,则内部变量的存储类型默认为auto型,外部变量的存储类型默认为extern型。
外部变量有两种声明方式:定义性声明和引用性声明。
定义性声明是为了创建变量,即需为变量分配内存。引用性声明是为了建立变量与内存单元之间的关系,表示要引用的变量已在程序源文件中其他地方进行过定义性声明。定义性声明只能放在函数外部,而引用性声明可放在函数外部,也可放在函数内部。
[cpp] view plaincopyprint?
- extern int b;//引用性声明,也可放在函数fun中
- void fun()
- {
- printf("d%",b);//输出
- }
- extern int b=5;//定义性声明,可以省略关键字extern
2.变量的作用域
变量的作用域是指一个范围,是从代码空间的角度考虑问题,它决定了变量的可见性,说明
变量在程序的哪个区域可用,即程序中哪些行代码可以使用变量。作用域有三种:局部作用域、全局作用域、文件作用域,相对应于局部变量(local variable)、全局变量和静态变量(global variable)。
(1)局部变量
大部分变量具有局部作用域,它们声明在函数(包括main函数)内部,因此局部变量又称为内部变量。在语句块内部声明的变量仅在该语句块内部有效,也属于局部变量。局部变量的作用域开始于变量被声明的位置,并在标志该函数或块结束的右花括号处结束。函数的形参也具有局部作用域。
[cpp] view plaincopyprint?
- #include <iostream>
- using namespace std;
-
- int main()
- {
- int x = 0;
- {
- int x=1;
- cout << x << endl;
- {
- cout << x << endl;
- int x = 2; // "x = 1" lost its scope here covered by "x = 2"
- cout << x << endl; // x = 2
- // local variable "x = 2" lost its scope here
- }
- cout << x << endl; // x = 1
- // local variable "x = 1" lost its scope here
- }
- cout << x << endl;
- // local variable "x = 0" lost its scope here
- return 0;
- }
(2) 全局变量及extern关键字
以下是MSDN对C/C++中extern关键字的解释:
The extern Storage-Class Specifier(C)
A variable declared with the extern storage-class specifier is a reference to a variable with the same name defined at the external level in any of the source files of the program. The internal extern declaration is used to make the external-level variable definition visible within the block. Unless otherwise declared at the external level, a variable declared with the extern keyword is visible only in the block in which it is declared.
The extern Storage-Class Specifier(C++)
The extern keyword declares a variable or function and specifies that it has external linkage (its name is visible from files other than the one in which it's defined). When modifying a variable, extern specifies that the variable has static duration (it is allocated when the program begins and deallocated when the program ends). The variable or function may be defined in another source file, or later in the same file. Declarations of variables and functions at file scope are external by default.
全局变量声明在函数的外部,因此又称外部变量,其作用域一般从变量声明的位置起,在程序源文件结束处结束。全局变量作用范围最广,甚至可以作用于组成该程序的所有源文件。当将多个独立编译的源文件链接成一个程序时,在某个文件中声明的全局变量或函数,在其他相链接的文件中也可以使用它们,但是必须做extern引用性声明。
关键字extern为声明但不定义一个对象提供了一种方法。实际上,它类似于函数声明,承诺了该对象会在其他地方被定义:或者在此文本文件中的其他地方,或者在程序的其他文本文件中。
如果一个函数要被其他文件中函数使用,定义时加extern关键字,在没有加extern和static关键字时,一般有的编译器会默认是extern类型的,因此你在其他文件中可以调用此函数。因此,extern一般主要用来做引用性声明。
但是,有些编译器以及在一些大型项目里,使用时一般的会将函数的定义放在源文件中不加extern,而将函数的声明放在头文件中,并且显式的声明成extern类型,需要使用此函数的源文件只要包含此头文件即可。
在使用extern 声明全局变量或函数时,一定要注意:所声明的变量或函数必须在且仅在一个源文件中实现定义。如果你的程序声明了一个外部变量,但却没有在任何源文件中定义它,程序将可以通编译,但无法链接通过:因为extern声明不会引起内存被分配!
在线程存在的情况下,必须做特殊的编码,以便同步各个线程对于全局对象的读和写操作。
另外,extern也可用来进行链接指定。C++中的extern "C"声明是为了实现C++与C及其它语言的混合编程,其中被extern "C"修饰的变量和函数是按照C语言方式编译和链接的。
如果C++调用一个C语言编写的.DLL时,当包括.DLL的头文件或声明接口函数时,应加extern "C" { }。
In C++, when used with a string, extern specifies that the linkage conventions of another language are being used for the declarator(s). C functions and data can be accessed only if they are previously declared as having C linkage. However, they must be defined in a separately compiled translation unit.
Microsoft C++ supports the strings "C" and "C++" in the string-literal field. All of the standard include files use the extern "C" syntax to allow the run-time library functions to be used in C++ programs.
例如,在C++工程中要包含C语言头文件,则一般这样:
extern "C" { #include <stdio.h> }
示例工程testExtern包含三个文件:C.c、CPP.cpp和testExtern.cpp。
[cpp] view plaincopyprint?
- // C.c
- #include <stdio.h>
-
- int intC = 2010;
-
- void funC()
- {
- printf("funC()/n");
- }
- // CPP.cpp
- #include <stdio.h>
-
- extern int global;
-
- /*extern*/ int intCPP = 2011;
- /*extern*/ const char* str = "defined outside";
- /*extern*/ int intArray[3] = {2012, 2013, 2014};
-
- static int staticIntCPP = 2015;
-
- void funCPP()
- {
- printf("funCPP() - localStatic : %d, globalExtern : %d/n", staticIntCPP, global);
- }
- // testExtern.cpp
- #include <stdio.h>
-
- /*extern*/ int global = 2016;
-
- extern "C" void funC(); // C.c中实现
- /*extern*/ void funCPP(); // CPP.cpp中实现,函数的声明默认在前面添加了extern:因为此处只声明,肯定在其他地方实现的。
-
- // 以下代码按C方式编译链接
- extern "C" void funC1()
- {
- printf("funC1()/n");
- }
-
- extern "C"
- {
- void funC2()
- {
- printf("funC2()/n");
- }
- }
-
- extern "C" void funC3(); // 本文件中其他地方(或外部文件)实现,按照C方式编译链接
- /*extern*/ void fun(); // 本文件中其他地方(或外部文件)实现
-
- extern "C" int intC; // C linkage specification in C++ must be at global scope
-
- int main()
- {
- printf("intC = %d/n", intC);
-
- extern int intCPP; // 或者放在main之前。如果去掉extern就变成了main()内部定义的局部变量!
- printf("intCPP = %d/n", intCPP);
-
- extern const char* str; // 或者放在main之前。
- printf("str = %s/n", str);
-
- extern int intArray[];
- for (int i = 0; i < 3; i++)
- {
- printf("intArray[i] = %d/n", intArray[i]);
- }
-
- // extern int staticIntCPP; // error LNK2001
- // printf("staticIntCPP = %d/n", staticIntCPP);
-
- funC();
- funCPP();
-
- funC1();
- funC2();
- funC3();
- fun();
-
- return 0;
- }
-
- void funC3()
- {
- printf("funC3()/n");
- }
-
- void fun()
- {
- printf("fun()/n");
- }
(3) 静态变量及static关键字
文件作用域是指在函数外部声明的变量只在当前文件范围内(包括该文件内所有定义的函数)可用,但不能被其他文件中的函数访问。一般在具有文件作用域的变量或函数的声明前加上static修饰符。
static静态变量可以是全局变量,也可以是局部变量,但都具有全局的生存周期,即生命周期从程序启动到程序结束时才终止。
[cpp] view plaincopyprint?
- #include <stdio.h>
- void fun()
- {
- static int a=5;//静态变量a是局部变量,但具有全局的生存期
- a++;
- printf("a=%d/n",a);
- }
- int main()
- {
- int i;
- for(i=0;i<2;i++)
- fun();
- getchar();
- return 0;
- }
输出结果为:
a=6
a=7
static操作符后面生命的变量其生命周期是全局的,而且其定义语句即static int a=5;只运行一次,因此之后再调用fun()时,该语句不运行。所以f的值保留上次计算所得,因此是6,7.
以下initWinsock例程中借助局部静态变量_haveInitializedWinsock保证Winsock只初始化一次。
[cpp] view plaincopyprint?
- int initWinsock(void)
- {
- static int _haveInitializedWinsock = 0;
- WORD WinsockVer1 = MAKEWORD(1, 1);
- WORD WinsockVer2 = MAKEWORD(2, 2);
- WSADATA wsadata;
-
- if (!_haveInitializedWinsock)
- {
- if (WSAStartup(WinsockVer1, &wsadata) && WSAStartup(WinsockVer2, &wsadata))
- {
- return 0; /* error in initialization */
- }
- if ((wsadata.wVersion != WinsockVer1)
- && (wsadata.wVersion != WinsockVer2))
- {
- WSACleanup();
- return 0; /* desired Winsock version was not available */
- }
- _haveInitializedWinsock = 1;
- }
-
- return 1;
- }
同一个源程序文件中的函数之间是可以互相调用的,不同源程序文件中的函数之间也是可以互相调用的,根据需要我们也可以指定函数不能被其他文件调用。根据函数能否被其他源程序文件调用,将函数分为内部函数和外部函数。
如果一个函数只能被本文件中其他函数所调用,它称为内部函数。在定义内部函数时,在函数名和函数类型的前面加static。
内部函数又称静态函数。使用内部函数,可以使函数只局限于所在文件,如果在不同的文件中有同名的内部函数,互不干扰。
通常把只能由同一文件使用的函数和外部变量放在一个文件中,在它们前面都冠以static使之局部化,其他文件不能引用。
由于静态变量或静态函数只在当前文件(定义它的文件)中有效,所以我们完全可以在多个文件中,定义两个或多个同名的静态变量或函数。这样当将多个独立编译的源文件链接成一个程序时,static修饰符避免一个文件中的外部变量由于与其他文件中的变量同名而发生冲突。
比如在A文件和B文件中分别定义两个静态变量a:
A文件中:static int a;
B文件中:static int a;
这两个变量完全独立,之间没有任何关系,占用各自的内存地址。你在A文件中改a的值,不会影响B文件中那个a的值。
左值
C++语言中可以放在等号左边的变量,即具有对应的可以由用户访问的存储单元,并且能够由用户去改变其值的量。 或者说左值是代表一个内存地址值,通过这个内存地址,就可以对内存进行读写操作;这也就是为什么左值可以被赋值的原因了。 相对应的还有右值:当一个符号或者常量放在操作符右边的时候,计算机就读取他们的“右值”,也就是其代表的真实值。 比如: int ia,ib; ib=0; ia=ib; 在这里,首先定义ia,ib。然后对ib赋值,此时计算机取ib的左值,也就是这个符号代表的内存位置即内存地址值,计算机取0的右值,也就是数值0;然后给ia赋值为ib,此时取ib的右值给ia的左值; 所以说,ib的左值、右值是根据他的位置来说的; 这也算是形式语言的一个有意思之处吧。
1>数据值,存储在某个内存地址中,也称右值(rvalue),右值是被读取的值(read value),文字常量和变量都可被用于右值。
2>地址值,即存储数据值的那块内存地址,也称左值(lvalue),文字常量不能被用作左值。
左值是一个引用到对象的表达式,通过左值我们可以取出该对象的值。通过可修改的左值表达式(modifiable lvalue)我们还可以修改该对象的值。(需要说明的是,在C++中,左值还可以引用到函数,即表达式f如果引用的是函数类型,那么在C中它既不是左值也不是右值;而在C++中则是左值)。因为左值引用到某一对象,因此我们使用&对左值表达式(也只能对左值表达式和函数)取址运算时,可以获得该对象的地址(有两种左值表达式不能取址,一是具有位域( bit-field )类型,因为实现中最小寻址单位是 byte;另一个是具有register指定符,使用register修饰的变量编译器可能会优化到寄存器中)。
这个可以在代码中慢慢体会。左值:能代表一个“容器”的就是一个左值。右值: 能代表一个数值的就是一个右值。一般来说,左值都素有地址的,但是寄存器变量是没有地址的
虚拟继承与虚基类实际上是说了同一件事,只是不同的书表达不同,在这里还是推荐虚拟继承这种说法(因为有人总问虚基类是什么,这里可以解释为虚基类就是虚拟继承,一种继承的方式,有的书偏要把一个动作写成一个名词,不负责任)。虚拟继承是C++继承的一个特殊方法,用来达到特殊的目的。要达到什么目的呢?那就是避免继承机制下的二义性问题(二义性:程序产生两种或多种可能,把编译器搞的不知所措)
继承机制下的二义性一般体现在两种情况下,要介绍的虚拟继承主要解决了其中第二种情况的二义性问题,不妨把两种情况都简单说一说:
【第一种情况】:由多个基类同名成员产生的二义性
class A //定义一个类A
{
public:
A(){cout << "A called"<< endl;}
void print(){cout << "A print" <<endl;}
private:
};
class B //定义一个类 B
{
public:
B(){cout << "B called" << endl;}
void print(){cout << "B print" << endl;}
private:
};
class C :public A , public B //定义一个类C 分别继承自 A ,B
{
public:
C(){}
private:
};
int main(void)
{
C c;
c.print(); ------------------------------------------------------- mark 1
getchar();
return 0;
}
如上图和代码所示:主程序main在执行到mark1标记时产生了二义性,c对象有两个基类,编译器不知道该调用A的print() 还是B的print(),这个二义性的产生的解决办法与虚拟继承无关,需要用作用于符号来解决,即将c.print() 修改为 c.A::print();那么就调用A的print方法,也就是告诉他要调用的方法在哪个基类里。
【第二种情况】:由多个父类的共同基类产生的二义性
A是B,C的共同基类,D继承于B,C
class A
{
public:
A(){cout << "A called"<< endl;}
void print(){cout << "A print" <<endl;}
private:
};
class B : public A
{
public:
B(){cout << "B called" << endl;}
private:
};
class C : public A
{
public:
C(){cout << "C called" << endl;}
private:
};
class D:public B,public C
{
public:
D(){cout << "D called" << endl;}
private:
};
int main(void)
{
D d;
d.print();---------------------------------------------------------mark 2
getchar();
return 0;
}
如上图和代码所示:主程序main在执行到mar2标记时产生了二义性,虽然只有基类A中有print(),但是继承的路线有两条,编译器不知道从B路线向上找还是从C向上找,一样会出错,这里可以用第一种方法用到的作用于说明符号即将d.print()改为d.B::print(),告诉编译器是从B继承下来的,当然,也可以改为d.C::print()。除了这种解决方案,还有另外一种解决方案,就是:运用虚拟继承的机制。实际上造成上边的二义性的根本原因是在这种继承的特殊模式下,A这个父类分别伴随B和C产生了两个拷贝,在调用拷贝中的方法时产生了矛盾,到底是调用哪一个拷贝中的print()呢?于是,所有人都会想,要是只有一个拷贝就好了,就没有矛盾了,虚拟继承就提供了这种机制,按上面的例子,只需修改B和C对A的继承方式,即加一个关键字 virtual
class B : virtual public A
{
public:
B(){cout << "B called" << endl;}
private:
};
class C : virtual public A
{
public:
C(){cout << "C called" << endl;}
private:
};
这样就相当于说,在没有A类的拷贝时就构造一个,如果已经有了,就用已经有的那一个,这样一来,拷贝只有一份了,二义性消除了。
虚拟继承不多说了,最后在补充点关于继承的东西,实际上继承框架性的东西不多,一个访问控制,一个调用顺序,把这两个搞清楚,再把上面的弄明白,就差我下面要说的一件事了,
有的地方叫继承的支配规则:
派生类中设置了基类中同名的成员,就是说基类中的成员的名字在派生类中再次使用,则派生类中的名字就把基类的名字隐藏在其后面了,所有的调用都是对派生类成员的调用,除非用域说明符 :: 。
上例子吧:
【例一】
class A
{
public:
A(){cout << "A called"<< endl;}
void print(){cout << "A print" <<endl;}
private:
};
class B : public A
{
public:
B(){cout << "B called" << endl;}
void print(){cout << "B print" << endl;}
private:
};
int main(void)
{
B b;
b.print();
getchar();
return 0;
}
打印的肯定是"B print",那要想打印"A print"呢,只能改为b.A::print();
需要说明的是这里并不是对print的重载(根本是同一个方法嘛,与重载没关系),应该起名叫“隐藏”比较合适。
【例二】
class A
{
public:
A(){cout << "A called"<< endl;}
void print(){cout << "A print" <<endl;}
private:
};
class B : public A
{
public:
B(){cout << "B called" << endl;}
void print(int a){cout << "B print" << endl;}
private:
};
int main(void)
{
B b;
b.print();
getchar();
return 0;
}
这个例子编译一下,没通过!怎么可能呢,B的print参数不符合,不是有基类的print符合要求嘛,怎么不调用呢,原来在派生类B中,print被更改了,这里是被重载了,很多人把这叫“覆盖”,有点道理,所以A类中的print()怎么也访问不到,除非用作用域符号,怎么改呢,加个参数,加个作用域符,看你想怎么用了,再这里只想说明“覆盖”这么件事。
动态调用与静态调用
最近学习了动态调用与静态调用的一些知识。哈哈。写一些心得体会。
首先讲一下库函数。所谓的库函数,就是很多函数的集合,实现各种功能的函数集中起来供程序调用。这样就有利于共享与避免重复书写。一次写,多次用。
我们编程的时候也接触过很多include进来的库函数。还有就是自己在头文件中敲的很多自定义函数。这些函数是要编译进.exe文件中去的,像这样的要将函数编译进. exe文件中的这些函数库调用就叫做静态库。平时我们可能没什么感觉,觉得这样还行。但是当我们的程序够大的时候,会有很多很多的函数,就像编写qq程序一样,需要很多的 函数,如果都将其编译到exe文件中,无疑这个exe文件的体积会非常大。
怎样解决这个问题呢,我们就需要用到动态库啦。
所谓的动态库就是讲函数的代码都写到dll文件中去。需要用到的时候我们在加载或引用。这样也有利于程序员之间的分工。
先写一些这么编写dll程序。我们新建一个Win32 Dynamic-Link Library文件。只需要在在每个函数前面加上:extern "C" _declspec(dllexport) 这一句代码。其余跟一般函数没什么区别。例如
extern "C" _declspec(dllexport) int add(int i1,int i2)
{
return i1+i2;
}
写好了编译成dll文件就ok了。
写好dll文件了。就需要怎样去调用它。这里也有两种调用方式,就是静态调用很动态调用。注意:动态调用与静态调用只是动态库的两种调用方式。
静态调用:只需要在程序的前面声明一下:
#pragma comment(lib, "dll1.lib")
extern "C" _declspec(dllexport) int add(int i1,int i2);
然后就可以像调用普通函数一样调用了。
如果dll中函数很多的话,一般都是由dll开发者开发好.h文件,把函数的声明都写好,然后供其他人调用,只要include就好了。程序运行时会去指定目录下找相应的dll文件。如果没有找到就不能启动程序。
动态调用:比较复杂。动态调用是在程序中需要用到dll文件内的函数时才去加载该文件。
这里直接举个例子说明:
typedef int(__cdecl* FunctionAdd)(int,int); //声明相应的函数指针类型。
函数指针
HMODULE hModule; //指向dll文件的句柄。
FunctionAdd add; //指向相应函数的指针实例。
hModule = LoadLibrary("dll1.dll"); // LoadLibrary 将dll1.dll文件加载进内存中来。用句柄指向。文件目录可以任意。
If(NULL==hModule )
{
//error.
}
add =(FunctionAdd)GetProcAddress(hModule,"add"); //根据dll的句柄得到相应函数的指针。
if(NULL==add)
{
//error
}
int r = add(1,1) ; //得到指针后就可以用相应的函数啦。
Wsprintf msgbox
FreeLibrary(hModule); //释放dll句柄。
这里大概可以分这几步:1.加载dll文件,2。取得文件内相应函数的指针。3.使用函数。4.释放dll句柄。
我们可以讲我们经常用到的函数风装成dll文件。供我们以后调用。
一,c++函数的返回分为以下几种情况
1)主函数main的返回值:这里提及一点,返回0表示程序运行成功。
2)返回非引用类型:函数的返回值用于初始化在跳用函数出创建的临时对象。用函数返回值初始化临时对象与用实参初始化形参的方法是一样 的。如果返回类型不是引用,在调用函数的地方会将函数返回值复制给临时对象。且其返回值既可以是局部对象,也可以是求解表达式的结果。
3)返回引用类型:当函数返回引用类型时,没有复制返回值。相反,返回的是对象本身。
二,函数返回引用
1 ,当函数返回引用类型时,没有复制返回值。相反,返回的是对象本身。先看两示例,示例1如下:
const string &shorterString(const string &s1,const string &s2)
{
return s1.size < s2.size ? s1:s2;
}
示例2:
[cpp] view plaincopy
- ostream &operator<<(ostream &output, const AAA &aaa)
- {
- output << aaa.x << ' ' << aaa.y << ' ' << aaa.z << endl;
- return output;
- }
形参和返回类型都是指向const string对象的引用,调用函数和返回结果时,都没有复制这些string对象。
2 ,返回引用,要求在函数的参数中,包含有以引用方式或指针方式存在的,需要被返回的参数。比如:
int& abc(int a, int b, int c, int& result){
result = a + b + c;
return result;
}
这种形式也可改写为:
int& abc(int a, int b, int c, int *result){
*result = a + b + c;
return *result;
}
但是,如下的形式是不可以的:
int& abc(int a, int b, int c){
return a + b + c;
}
3,千万不要返回局部对象的引用。当函数执行完毕时,将释放分配给局部对象的存储空间。此时,对局部对象的引用就会指向不确定的内存。如:
const string &manip(const string &s)
{
string ret =s;
return ret; //wrong:returning reference to a local object
}
4,引用返回左值。返回引用的函数返回一个左值。因此这样的函数可用于任何要求使用左值的地方。示例见:c++ primer p215
5,由于返回值直接指向了一个生命期尚未结束的变量,因此,对于函数返回值(或者称为函数结果)本身的任何操作,都在实际上,是对那个变量的操作,这就是引入const类型的返回的意义。当使用了const关键字后,即意味着函数的返回值不能立即得到修改!如下代码,将无法编译通过,这就是因为返回值立即进行了++操作(相当于对变量z进行了++操作),而这对于该函数而言,是不允许的。如果去掉const,再行编译,则可以获得通过,并且打印形成z = 7的结果。
include <iostream>
include <cstdlib>
const int& abc(int a, int b, int c, int& result){
result = a + b + c;
return result;
}
int main() {
int a = 1; int b = 2; int c=3;
int z;
abc(a, b, c, z)++; //wrong: returning a const reference
cout << "z= " << z << endl;
SYSTEM("PAUSE");
return 0;
}
三,思考:
1,什么时候返回引用是正确的?而什么时候返回const引用是正确的?
返回指向函数调用前就已经存在的对象的引用是正确的。当不希望返回的对象被修改时,返回const引用是正确的。
1-什么时候会用到拷贝构造函数?
2-什么时候有必要手动写拷贝构造函数?
1-什么时候会用到拷贝构造函数?
任何你想利用一个已有的类实例给另一个类实例赋值时,这种赋值可能是显式的,也可能是隐式的
显式:classa_1=class_2;
隐式:函数的形参有用到类对象却没有用引用或传址技术时
函数的返回值是一个对象也没有应用传址技术时
2-什么时候有必要用拷贝构造函数?
上述3种情况,如果没有涉及到深拷贝问题,就没有必要自己来编写拷贝构造函数,编译器有默认的可以很完美的完成任务
关于深拷贝
如果一个类中含有指针成员变量,则在利用一个已存在对象构造新的对象时,就会面临两种选择:深拷贝和浅拷贝。
浅拷贝只是将对象间对应的指针成员变量进行简单的拷贝,即拷贝结束后新旧对象的指针指向相同的资源(指针的值是相同的);这种拷贝会导致对象的成员不可用,如下例:
class Person
{
public :
//....
char * home; //the person's home
void SetHome(char * str)
{home = str;}
~Person()
{
//...
delete [] home;
}
}
//....
char * place = new char [20];
strcpy(place,"China");
Person *A = new Person();
A->SetHome(place);
Person * B= Person(A);
delete A;
//....
此时对象A 和对象B的成员home值相同,如果A对象 destroy,则对象B的成员home指向的地址变为不可用(对象A撤销时将home指向的资源释放了)。
深拷贝是相对于浅拷贝而言的,为了避免上述情况的发生,将上例中的代码改造:对象拷贝时将指针指向的内容拷贝,代码如下:
class Person
{
public :
//....
char * home;//the person's home
void SetHome(char * str)
{home = str;}
Person & Person(const Person & per)
{
//...
if(* this == per)//copy itself
return *this;
home = new char[strlen(per.home) +1]; //alloc new memory,深拷贝的体现
strcpy(home,per.home);
return * this;
}
~Person()
{
//...
delete [] home;
}
}
深拷贝之后,新旧对象的home成员指向的内容的值相同,而其自身的值不同。这样就可避免出现其中之一destroy 之后,另一对象的home成员不可用。【以上内容为转载】
这里补充一句,当类中包含了需要深拷贝的字符指针时,需要编写拷贝构造函数和赋值函数。
最后,以前面写的string类中的拷贝构造函数来结束。
string类必须要自己定义拷贝构造函数,而不能由编译器自动生成。因为m_string为指针,拷贝对象时需要为m_string分配内存空间,即深拷贝。
String::String(const String &str) { int len = strlen(str.m_string); m_string = new char[len+1]; //深拷贝的体现 strcpy(m_string,str.m_string); }
PS:拷贝构造函数的作用以及用途,什么时候需要自定义拷贝构造函数?
在C++中,下面三种对象需要拷贝的情况。因此,拷贝构造函数将会被调用。 1). 一个对象以值传递的方式传入函数体 2). 一个对象以值传递的方式从函数返回 3). 一个对象需要通过另外一个对象进行初始化 以上的情况需要拷贝构造函数的调用。如果在前两种情况不使用拷贝构造函数的时候,就会导致一个指针指向已经被删除的内存空间。对于第三种情况来说,初始化和赋值的不同含义是构造函数调用的原因。事实上,拷贝构造函数是由普通构造函数和赋值操作赋共同实现的。描述拷贝构造函数和赋值运算符的异同的参考资料有很多。 拷贝构造函数不可以改变它所引用的对象,其原因如下:当一个对象以传递值的方式传一个函数的时候,拷贝构造函数自动的被调用来生成函数中的对象。如果一个对象是被传入自己的拷贝构造函数,它的拷贝构造函数将会被调用来拷贝这个对象这样复制才可以传入它自己的拷贝构造函数,这会导致无限循环。 除了当对象传入函数的时候被隐式调用以外,拷贝构造函数在对象被函数返回的时候也同样的被调用。换句话说,你从函数返回得到的只是对象的一份拷贝。但是同样的,拷贝构造函数被正确的调用了,你不必担心。 如果在类中没有显式的声明一个拷贝构造函数,那么,编译器会私下里为你制定一个函数来进行对象之间的位拷贝(bitwise copy)。这个隐含的拷贝构造函数简单的关联了所有的类成员。许多作者都会提及这个默认的拷贝构造函数。注意到这个隐式的拷贝构造函数和显式声明的拷贝构造函数的不同在于对于成员的关联方式。显式声明的拷贝构造函数关联的只是被实例化的类成员的缺省构造函数除非另外一个构造函数在类初始化或者在构造列表的时候被调用。 拷贝构造函数是程序更加有效率,因为它不用再构造一个对象的时候改变构造函数的参数列表。设计拷贝构造函数是一个良好的风格,即使是编译系统提供的帮助你申请内存默认拷贝构造函数。事实上,默认拷贝构造函数可以应付许多情况。
C++操作符operator的另一种用法
今天在程序员面试宝典上看到这样一道题目:
A C++ developer wants to handle a static_cast<char*>() operation for the class String shown below. Which of the following options are valid declarations that will accomplish this task?
class String
{
public:
//...
//declaration goes here
};
A. char* operator();
B. char* operator char*();
C. String operator char*();
D. operator char*();
E. char* operator String();
答案是D,但是百思不得其解,百度了很多资料,才发现原来operator的作用不仅仅在于运算符的重载,他还有另外一种作用:强制类型转换。
operator char*()是类型转换函数的定义,即该类型可以自动转换为char*类型。有时候经常和const在一起用,operator const char*() const.
下面看别人写的一个例子:
[cpp] view plaincopy
- /*************************Test_OperatorConvert.h*************************/
- #ifndef TEST_OPERATORCONVERT_H
- #define TEST_OPERATORCONVERT_H
-
- const int MAX_PATH2 = 256;
-
- class Test_OperatorConvert{
- public:
- Test_OperatorConvert();
- Test_OperatorConvert(char *str);
- virtual ~Test_OperatorConvert();
- char *GetStr();
- operator char*();
- private:
- char m_szTest[MAX_PATH2];
- };
- #endif
-
- /*************************Test_OperatorConvert.cpp*************************/
- #include "stdafx.h"
- #include "Test_OperatorConvert.h"
-
- #include <iostream>
- using namespace std;
-
- Test_OperatorConvert::Test_OperatorConvert()
- {
- memset(m_szTest, 0, sizeof(m_szTest));
- }
-
- Test_OperatorConvert::Test_OperatorConvert(char *str)
- {
- strcpy(m_szTest, str);
- }
-
- Test_OperatorConvert::~Test_OperatorConvert()
- {
- }
-
- // 这个函数实现的功能与operator char*()的功能一致。
- char *Test_OperatorConvert::GetStr()
- {
- return m_szTest;
- }
-
- Test_OperatorConvert::operator char*()
- {
- return m_szTest;
- }
-
- int main(int argc, char* argv[])
- {
- Test_OperatorConvert cTestInstance;
- char *pTest1 = cTestInstance; // 这里就是operator char*()发挥作用的地方,
- // 类Test_OperatorConvert 被转换成char*类型。
- char *pTest2 = cTestInstance.GetStr(); //如果没有实现operator char*(),使用这种方法也一样。
- return 0;
- }
这类似于一种隐式类型转换,实现的语法格式就是 operator type_name().
在需要char*类型的时候,就可以用Test_OperatorConvert来代替。还有一点需要注意的就是:C++中有3中函数不需要返回类型:构造函数、析构函数、类型转换函数
前两个我们都知道不允许返回任何类型,甚至void类型,也不允许出现return,最后一个也不写返回类型,但是必须返回对应类型的值,即必须有return语句。
看到一道网易有关C++高级机制的面试题目:析构函数可以抛出异常吗?为什么不能抛出异常?除了资源泄露,还有其他需考虑的因素吗?
于是在网上收集了一下资料,进行一个快速的学习。
1. 抛出异常
1.1 抛出异常(也称为抛弃异常)即检测是否产生异常,在C++中,其采用throw语句来实现,如果检测到产生异常,则抛出异常。
该语句的格式为: throw 表达式;
如果在try语句块的程序段中(包括在其中调用的函数)发现了异常,且抛弃了该异常,则这个异常就可以被try语句块后的某个catch语句所捕获并处理,捕获和处理的条件是被抛弃的异常的类型与catch语句的异常类型相匹配。由于C++使用数据类型来区分不同的异常,因此在判断异常时,throw语句中的表达式的值就没有实际意义,而表达式的类型就特别重要。
1.2 抛出异常实际是作为另一种返回值来使用的。 抛出异常的好处一是可以不干扰正常的返回值,另一个是调用者必须处理异常,而不像以前c语言返回一个整数型的错误码,调用者往往将它忽略了。
1.3 举例说明
假如说A方法掉调用-->B方法调用-->C方法。 然后在B和C方法里定义了throws Exception。A方法里定义了Try Catch。
那么调用A方法时,在执行到C方法里出现了异常,那么这个异常就会从C抛到B,再从B抛到A。在A里的try catch就会捕获这个异常,然后你就可以在catch写自己的处理代码。
那么为什么当时出现了异常不去处理呢? 因为你业务逻辑调用的是A方法,你执行了A方法,当然要在A里得到异常,然后来处理。如果在C里面就处理异常,这就破坏程序结构了。 另外,A调用了C方法,假如还接着也调用了D,E,F方法,假如他们都有可能抛出异常,你说是在A里面获得处理一次好,还是在C,D,E,F得到了异常,每个都当时处理一下的好? 当时就处理异常理论上也是可以的,而且大多数时候,到底在哪处理异常,是要根据需求和项目的具体情况的。
2. 构造函数可以抛出异常。
3. C++标准指明析构函数不能、也不应该抛出异常。
C++异常处理模型是为C++语言量身设计的,更进一步的说,它实际上也是为C++语言中面向对象而服务的。C++异常处理模型最大的特点和优势就是对C++中的面向对象提供了最强大的无缝支持。那么如果对象在运行期间出现了异常,C++异常处理模型有责任清除那些由于出现异常所导致的已经失效了的对象(也即对象超出了它原来的作用域),并释放对象原来所分配的资源, 这就是调用这些对象的析构函数来完成释放资源的任务,所以从这个意义上说,析构函数已经变成了异常处理的一部分。
上面的论述C++异常处理模型它其实是有一个前提假设——析构函数中是不应该再有异常抛出的。试想,如果对象出了异常,现在异常处理模块为了维护系统对象数据的一致性,避免资源泄漏,有责任释放这个对象的资源,调用对象的析构函数,可现在假如析构过程又再出现异常,那么请问由谁来保证这个对象的资源释放呢?而且这新出现的异常又由谁来处理呢?不要忘记前面的一个异常目前都还没有处理结束,因此这就陷入了一个矛盾之中,或者说无限的递归嵌套之中。所以C++标准就做出了这种假设,当然这种假设也是完全合理的,在对象的构造过程中,或许由于系统资源有限而致使对象需要的资源无法得到满足,从而导致异常的出现,但析构函数完全是可以做得到避免异常的发生,毕竟你是在释 放资源呀!
假如无法保证在析构函数中不发生异常,怎么办? 虽然C++标准中假定了析构函数中不应该,也不永许抛出异常的。但实际的软件系统开发中是很难保证到这一点的。所有的析构函数的执行过程完全不发生一点异常,这根本就是天方夜谭,或者说自己欺骗自己算了。而且有时候析构一个对象(释放资源)比构造一个对象还更容易发生异常,例如一个表示引用记数的句柄不小心出错, 结果导致资源重复释放而发生异常,当然这种错误大多时候是由于程序员所设计的算法在逻辑上有些小问题所导致的,但不要忘记现在的系统非常复杂,不可能保证 所有的程序员写出的程序完全没有bug。因此杜绝在析构函数中决不发生任何异常的这种保证确实是有点理想化了。
3.1 more effective c++提出两点理由(析构函数不能抛出异常的理由):
1)如果析构函数抛出异常,则异常点之后的程序不会执行,如果析构函数在异常点之后执行了某些必要的动作比如释放某些资源,则这些动作不会执行,会造成诸如资源泄漏的问题。
2)通常异常发生时,c++的机制会调用已经构造对象的析构函数来释放资源,此时若析构函数本身也抛出异常,则前一个异常尚未处理,又有新的异常,会造成程序崩溃的问题。
3.2 那么当无法保证在析构函数中不发生异常时, 该怎么办?
其实还是有很好办法来解决的。那就是把异常完全封装在析构函数内部,决不让异常抛出函数之外。这是一种非常简单,也非常有效的方法。
~ClassName()
{
try{
do_something();
}
catch(){ //这里可以什么都不做,只是保证catch块的程序抛出的异常不会被扔出析构函数之外。
}
}
3.3 析构函数中抛出异常时概括性总结
1)C++中析构函数的执行不应该抛出异常;
2)假如析构函数中抛出了异常,那么你的系统将变得非常危险,也许很长时间什么错误也不会发生;但也许你的系统有时就会莫名奇妙地崩溃而退出了,而且什么迹象也没有,崩得你满地找牙也很难发现问题究竟出现在什么地方;
3)当在某一个析构函数中会有一些可能(哪怕是一点点可能)发生异常时,那么就必须要把这种可能发生的异常完全封装在析构函数内部,决不能让它抛出函数之外(这招简直是绝杀!呵呵!);
4)一定要切记上面这几条总结,析构函数中抛出异常导致程序不明原因的崩溃是许多系统的致命内伤!
昨天有个同学让我做下面这道有关动态内存的题,做完后就写了这篇小文
#include<iostream>
using namespace std; void GetMemory(char* p,int num) { p = (char*)malloc(sizeof(char)*num); } int main() { char *str=NULL; GetMemory(str,100); strcpy(str,"hello"); cout<<str<<endl; return 0;
}
上面的程序测试后有什么效果?如何修改?
首先上面程序可以编译,但是运行时内存出错。原因是函数传递参数的方式按值传递,将指针str传递给参数时,实际上传递的是str的副本
无论你在GetMemory怎么分配内存,主函数中的str依旧是NULL,因此给NULL指针strcpy一个字符串,必然要报内存错误。
修改1:使用函数返回值
无论如何,GetMemory函数中已经申请了内存,我们只需把他返回给str即可。
#include<iostream>
using namespace std; char* GetMemory(char* p,int num) { p = (char*)malloc(sizeof(char)*num);
return p; } int main() { char *str=NULL; str = GetMemory(str,100); strcpy(str,"hello"); cout<<str<<endl; return 0;
}
修改2:使用引用
引用可以使我们直接去操作参数的本身,而非拷贝
#include<iostream>
using namespace std; void GetMemory(char* &p,int num) { p = (char*)malloc(sizeof(char)*num); } int main() { char *str=NULL; GetMemory(str,100); strcpy(str,"hello"); cout<<str<<endl; return 0;
}
修改3:使用二级指针
虽然传递的是二级指针的副本,但是副本指向的内容和原件是一样,改变副本的内 同样能改变 str
#include<iostream>
using namespace std; void GetMemory(char* *p,int num) { *p = (char*)malloc(sizeof(char)*num); } int main() { char *str=NULL; GetMemory(&str,100); strcpy(str,"hello"); cout<<str<<endl; return 0;
}
1、局部变量能否和全局变量重名?
答:能,局部会屏蔽全局。要用全局变量,需要使用"::" ;局部变量可以与全局变量同名,在函数内引用这个变量时,会用到同名的局部变量,而不会用到全局变量。对于有些编译器而言,在同一个函数内可以定义多个同名的局部变量,比如在两个循环体内都定义一个同名的局部变量,而那个局部变量的作用域就在那个循环体内。
2、如何引用一个已经定义过的全局变量?
答:extern
可以用引用头文件的方式,也可以用extern关键字,如果用引用头文件方式来引用某个在头文件中声明的全局变理,假定你将那个编写错了,那么在编译期间会报错,如果你用extern方式引用时,假定你犯了同样的错误,那么在编译期间不会报错,而在连接期间报错。
3、全局变量可不可以定义在可被多个.C文件包含的头文件中?为什么?
答:可以,在不同的C文件中以static形式来声明同名全局变量。
可以在不同的C文件中声明同名的全局变量,前提是其中只能有一个C文件中对此变量赋初值,此时连接不会出错.
4、请写出下列代码的输出内容
#include <stdio.h>
int main(void)
{
int a,b,c,d;
a=10;
b=a++;
c=++a;
d=10*a++;
printf("b,c,d:%d,%d,%d",b,c,d);
return 0;
}
答:10,12,120
5、static全局变量与普通的全局变量有什么区别?static局部变量和普通局部变量有什么区别?static函数与普通函数有什么区别?
答: 1) 全局变量(外部变量)的说明之前再冠以static 就构成了静态的全局变量。全局变量本身就是静态存储方式, 静态全局变量当然也是静态存储方式。 这两者在存储方式上并无不同。这两者的区别在于非静态全局变量的作用域是整个源程序, 当一个源程序由多个源文件组成时,非静态的全局变量在各个源文件中都是有效的。 而静态全局变量则限制了其作用域, 即只在定义该变量的源文件内有效, 在同一源程序的其它源文件中不能使用它。由于静态全局变量的作用域局限于一个源文件内,只能为该源文件内的函数公用, 因此可以避免在其它源文件中引起错误。
2) 从以上分析可以看出, 把局部变量改变为静态变量后是改变了它的存储方式即改变了它的生存期。把全局变量改变为静态变量后是改变了它的作用域,限制了它的使用范围。
3) static函数与普通函数作用域不同,仅在本文件。只在当前源文件中使用的函数应该说明为内部函数(static),内部函数应该在当前源文件中说明和定义。对于可在当前源文件以外使用的函数,应该在一个头文件中说明,要使用这些函数的源文件要包含这个头文件
综上所述:
static全局变量与普通的全局变量有什么区别:
static全局变量只初使化一次,防止在其他文件单元中被引用;全局变量可以被其他文件单元所引用
static局部变量和普通局部变量有什么区别:
static局部变量只被初始化一次,下一次依据上一次运算结果值;并且静态局部变量是存储在静态区,而局部变量存储在栈上
static函数与普通函数有什么区别:
static函数在内存中只有一份,普通函数在每个被调用中维持一份拷贝
6、程序的局部变量存在于(堆栈)中,全局变量存在于(静态区 )中,动态申请数据存在于( 堆)中。
7、设有以下说明和定义:
typedef union
{
long i;
int k[5];
char c;
} DATE;
struct data
{
int cat;
DATE cow;
double dog;
} too;
DATE max;
则语句 printf("%d",sizeof(struct data)+sizeof(max));的执行结果是:52
考点:区别struct与union.(一般假定在32位机器上)
答:DATE是一个union, 变量公用空间. 里面最大的变量类型是int[5], 占用20个字节. 所以它的大小是20. data是一个struct, 每个变量分开占用空间. 依次为int4 + DATE20 + double8 = 32. 所以结果是 20 + 32 = 52. 当然...在某些16位编辑器下, int可能是2字节,那么结果是 int2 + DATE10 + double8 = 20
8、队列和栈有什么区别?
队列先进先出,栈后进先出
9、写出下列代码的输出内容
#include <stdio.h>
int inc(int a)
{ return(++a); }
int multi(int*a,int*b,int*c)
{ return(*c=*a**b); }
typedef int(FUNC1)(int in);
typedef int(FUNC2) (int*,int*,int*);
void show(FUNC2 fun,int arg1, int*arg2)
{
FUNC1 p=&inc;//这段有误,编译通不过
int temp =p(arg1);
fun(&temp,&arg1, arg2);
printf("%dn",*arg2);
}
main()
{
int a;
show(multi,10,&a);
return 0;
}
答:110
10、请找出下面代码中的所有错误 (题目不错,值得一看)
说明:以下代码是把一个字符串倒序,如“abcd”倒序后变为“dcba”
#include"string.h"
main()
{
char*src="hello,world";
char* dest=NULL;
int len=strlen(src);
dest=(char*)malloc(len);
char* d=dest;
char* s=src[len];
while(len--!=0)
d++=s--;
printf("%s",dest);
return 0;
}
答:
方法1:一共有4个错误;
int main()
{
char* src = "hello,world";
int len = strlen(src);
char* dest = (char*)malloc(len+1);//要为分配一个空间 char* d = dest;
char* s = src+len-1; //指向最后一个字符
while( len-- != 0 )
*d++=*s--;
*d = 0; //尾部要加’\0’
free(dest); // 使用完,应当释放空间,以免造成内存汇泄露
dest = NULL; //防止产生野指针
return 0;
}
方法2: 自己给出的解法
void Reverse(char* s, int len)
{
char*p1 = s;
char*p2 = s+len-1;
char tmp;
while(p1<p2)//注意要交换
{
tmp= *p1;
*p1= *p2;
*p2= tmp;
p1++;
p2--;
}
}
11.对于一个频繁使用的短小函数,在C语言中应用什么实现,在C++中应用什么实现?
c 用宏定义,c++用inline
12.直接链接两个信令点的一组链路称作什么?
PPP点到点连接
13.接入网用的是什么接口?
V5接口
14.voip都用了那些协议?
H.323协议簇、SIP协议、Skype协议、H.248和MGCP协议
15.软件测试都有那些种类?
黑盒:针对系统功能的测试
白盒:测试函数功能,各函数接口
16.确定模块的功能和模块的接口是在软件设计的那个队段完成的?
概要设计阶段
17.
unsigned char *p1;
unsigned long *p2;
p1=(unsigned char *)0x801000;
p2=(unsigned long *)0x810000;
请问
p1+5= ;
p2+5= ;
答案:0x801005(相当于加上5位) 0x810014(相当于加上20位);
逻辑题:
18.-1,2,7,28,,126请问28和126中间那个数是什么?为什么?
第一题的答案应该是4^3-1=63
规律是n^3-1(当n为偶数0,2,4)n^3+1(当n为奇数1,3,5)
答案:63
19.用两个栈实现一个队列的功能?要求给出算法和思路!
设2个栈为A,B, 一开始均为空.
入队: 将新元素push入栈A;
出队: (1)判断栈B是否为空; (2)如果不为空,则将栈A中所有元素依次pop出并push到栈B; (3)将栈B的栈顶元素pop出;
这样实现的队列入队和出队的平摊复杂度都还是O(1), 比上面的几种方法要好。
20.在c语言库函数中将一个字符转换成整型的函数是atool()吗,这个函数的原型是什么?
函数名: atol 功 能: 把字符串转换成长整型数 用 法: long atol(const char *nptr); 程序例: #i nclude <stdlib.h> #i nclude <stdio.h> int main(void) { long l; char *str = "98765432"; l = atol(str); printf("string = %s integer = %ld\n", str, l); return(0); }
选择题:
21.Ethternet链接到Internet用到以下那个协议? D
A.HDLC; B.ARP; C.UDP; D.TCP; E.ID
22.属于网络层协议的是:( B C)
A.TCP;B.IP;C.ICMP;D.X.25
23.Windows消息调度机制是:(C)
A.指令队列;B.指令堆栈;C.消息队列;D.消息堆栈;
24. unsigned short hash(unsigned short key) { return (key>>)%256 //有误 } 请问hash(16),hash(256)的值分别是: A.1.16;B.8.32;C.4.16;D.1.32
找错题:
25.请问下面程序有什么错误? int a[60][250][1000],i,j,k; for(k=0;k<=1000;k++) for(j=0;j<250;j++) for(i=0;i<60;i++) a[i][j][k]=0;
将循环顺序变为i j k 26. #define Max_CB 500 void LmiQueryCSmd(Struct MSgCB * pmsg) { unsigned char ucCmdNum; ...... for(ucCmdNum=0;ucCmdNum<Max_CB;ucCmdNum++) { ......; }
死循环,unsigned int的取值范围是0~255,当ucCmdNum为255时,++之后又从0开始循环 27.以下是求一个数的平方的程序,请找出错误: #define SQUARE(a)((a)*(a)) int a=5; int b; b=SQUARE(a++);
答:结果与编译器相关,得到的可能不是平方值. 28. typedef unsigned char BYTE int examply_fun(BYTE gt_len; BYTE *gt_code) { BYTE *gt_buf; gt_buf=(BYTE *)MALLOC(Max_GT_Length); ...... if(gt_len>Max_GT_Length) { return GT_Length_ERROR; } ....... }
问答题:
29.IP Phone的原理是什么?
IP电话(又称IP PHONE或VoIP)是建立在IP技术上的分组化、数字化传输技术,其基本原理是:通过语音压缩算法对语音数据进行压缩编码处理,然后把这些语音数据按IP等相关协议进行打包,经过IP网络把数据包传输到接收地,再把这些语音数据包串起来,经过解码解压处理后,恢复成原来的语音信号,从而达到由IP网络传送语音的目的。
30.TCP/IP通信建立的过程怎样,端口有什么作用?
三次握手,端口确定是哪个应用程序使用该协议
31.1号信令和7号信令有什么区别,我国某前广泛使用的是那一种?
1号信令接续慢,但是稳定,可靠。
7号信令的特点是:信令速度快,具有提供大量信令的潜力,具有改变和增加信令的灵活性,便于开放新业务,在通话时可以随意处理信令,成本低。目前得到广泛应用。
32.列举5种以上的电话新业务
如“闹钟服务”、“免干扰服务”、“热线服务”、“转移呼叫”、“遇忙回叫”、“缺席用户服务”、“追查恶意呼叫”、“三方通话”、“会议电话”、“呼出限制”、“来电显示”、“虚拟网电话”等
一、预处理器(Preprocessor) 1. 用预处理指令#define 声明一个常数,用以表明1年中有多少秒(忽略闰年问题) #define SECONDS_PER_YEAR (60 * 60 * 24 * 365)UL (PS:UL必须要要加上) 考点: 1). #define 语法的基本知识(例如:不能以分号结束,括号的使用,等等) 2). 懂得预处理器将为你计算常数表达式的值,因此,直接写出你是如何计算一年中有多少秒而不是计算出实际的值,是更清晰而没有代价的。 3). 意识到这个表达式将使一个16位机的整型数溢出-因此要用到长整型符号L,告诉编译器这个常数是的长整型数。 4).表达式中用到UL(表示无符号长整型) 2. 写一个“标准”宏MIN,这个宏输入两个参数并返回较小的一个。 #define MIN(A,B) ((A) <= (B) ? (A) : (B)) 这个测试是为下面的目的而设的: 1). 标识#define在宏中应用的基本知识。这是很重要的,因为直到嵌入(inline)操作符变为标准C的一部分,宏是方便产生嵌入代码的唯一方法,对于嵌入式系统来说,为了能达到要求的性能,嵌入代码经常是必须的方法。 2). 三重条件操作符的知识。这个操作符存在C语言中的原因是它使得编译器能产生比if-then-else更优化的代码,了解这个用法是很重要的。 3). 懂得在宏中小心地把参数用括号括起来 4).讨论下面宏的副作用,例如:当你写下面的代码时会发生什么事? least = MIN(*p++, b); 二、数据声明(Data declarations) 用变量a给出下面的定义 a) 一个整型数(An integer) b) 一个指向整型数的指针(A pointer to an integer) c) 一个指向指针的的指针,它指向的指针是指向一个整型数(A pointer to a pointer to an integer) d) 一个有10个整型数的数组(An array of 10 integers) e) 一个有10个指针的数组,该指针是指向一个整型数的(An array of 10 pointers to integers) f) 一个指向有10个整型数数组的指针(A pointer to an array of 10 integers) g) 一个指向函数的指针,该函数有一个整型参数并返回一个整型数(A pointer to a function that takes an integer as an argument and returns an integer) h) 一个有10个指针的数组,该指针指向一个函数,该函数有一个整型参数并返回一个整型数( An array of ten pointers to functions that take an integer argument and return an integer )int(*a[10]) (int) 答案是: a) int a; // An integer b) int *a; // A pointer to an integer c) int **a; // A pointer to a pointer to an integer d) int a[10]; // An array of 10 integers e) int *a[10]; // An array of 10 pointers to integers f) int (*a)[10]; // A pointer to an array of 10 integers g) int (*a)(int); // A pointer to a function a that takes an integer argument and returns an integer h) int (*a[10])(int); // An array of 10 pointers to functions that take an integer argument and return an integer 三、Static 关键字static的作用是什么? 在C语言中,关键字static有三个明显的作用:(更详细的内容还要参见之前的blog) 1). 在函数体,一个被声明为静态的变量在这一函数被调用过程中维持其值不变。 2). 在模块内(但在函数体外),一个被声明为静态的变量可以被模块内所用函数访问,但不能被模块外其它函数访问。它是一个本地的全局变量。 3). 在模块内,一个被声明为静态的函数只可被这一模块内的其它函数调用。那就是,这个函数被限制在声明它的模块的本地范围内使用。 四、Const 关键字const是什么含意? 1). 合理地使用关键字const可以使编译器很自然地保护那些不希望被改变的参数,防止其被无意的代码修改。简而言之,这样可以减少bug的出现。 2). 通过给优化器一些附加的信息,使用关键字const也许能产生更紧凑的代码。 3). 关键字const的作用是为给读你代码的人传达非常有用的信息,实际上,声明一个参数为常量是为了告诉了用户这个参数的应用目的。如果你曾花很多时间清理其它人留下的垃圾,你就会很快学会感谢这点多余的信息。(当然,懂得用const的程序员很少会留下的垃圾让别人来清理的。) #include <stdio.h> using namespace std; int main(){ const char *pa;//常量指针 char const *pb; char ca = 'a'; char cb = 'b'; char * const pc = &ca;//指针常量 const char * const pd = &cb;//指向常量的指针 pa = &ca; pa = &cb; pb = &ca; pb = &cb; *pc = 'd'; printf("ca = %c\n", ca); return 0; } 经过以上测试 const char *pa; char const *pb; 上面两种定义方法一样都是 pa(pb)指向的变量的值不可改变,及*pa,*pb, 而pa,和pb本身是可变的,如: pa = &ca; //ok ×pa = 'c' //error char * const pc = &ca; pc本身是不可变的(只能在定义时初始化),但指向的变量值是可变的,如 pc = &ca; //error *pc = 'd'; //ok const char * const pd = &cb; pd本身是不可变的,且指向的变量也是不可变的(只能在定义时初始化) pd = &cb; //error *pd = 'c'; /error 通过以上总结,无论怎样定义p都是一指针 如果const在*左边,表示该指针指向的变量是不可变的 如果const在*右边,表示该指针本身是不可变得 五、Volatile 关键字volatile有什么含意 并给出三个不同的例子。 一个定义为volatile的变量是说这变量可能会被意想不到地改变,这样,编译器就不会去假设这个变量的值了。精确地说就是,优化器在用到这个变量时必须每次都小心地重新读取这个变量的值,而不是使用保存在寄存器里的备份。下面是volatile变量的几个例子: 1). 并行设备的硬件寄存器(如:状态寄存器) 2). 一个中断服务子程序中会访问到的非自动变量(Non-automatic variables) 3). 多线程应用中被几个任务共享的变量 这是区分C程序员和嵌入式系统程序员的最基本的问题。嵌入式系统程序员经常同硬件、中断、RTOS等等打交道,所用这些都要求volatile变量。不懂得volatile内容将会带来灾难。 回答以下问题: 1). 一个参数既可以是const还可以是volatile吗?解释为什么。 2). 一个指针可以是volatile 吗?解释为什么。 3). 下面的函数有什么错误: int square(volatile int *ptr) { return *ptr * *ptr; } 下面是答案: 1). 是的。一个例子是只读的状态寄存器。它是volatile因为它可能被意想不到地改变。它是const因为程序不应该试图去修改它。 2). 是的。尽管这并不很常见。一个例子是当一个中服务子程序修该一个指向一个buffer的指针时。 3). 这段代码的有个恶作剧。这段代码的目的是用来返指针*ptr指向值的平方,但是,由于*ptr指向一个volatile型参数,编译器将产生类似下面的代码: int square(volatile int *ptr) { int a,b; a = *ptr; b = *ptr; return a * b; } 由于*ptr的值可能被意想不到地该变,因此a和b可能是不同的。结果,这段代码可能返不是你所期望的平方值!正确的代码如下: long square(volatile int *ptr) { int a; a = *ptr; return a * a; } 六、位操作(Bit manipulation) 嵌入式系统总是要用户对变量或寄存器进行位操作。给定一个整型变量a,写两段代码,第一个设置a的bit 3,第二个清除a 的bit 3。在以上两个操作中,要保持其它位不变。 解答:采用#defines 和 bit masks 操作。这是一个有极高可移植性的方法,是应该被用到的方法。最佳的解决方案如下: #define BIT3 (0x1<<3) static int a; void set_bit3(void) { a |= BIT3; } void clear_bit3(void) { a &= ~BIT3;
}
PS:这里的写法与位图的实现非常相似,具体可参见(自己做的数据结构笔记C版本),a |= BIT3 表示将1左移3位,a或上00·······0100(32位)
一些人喜欢为设置和清除值而定义一个掩码同时定义一些说明常数,这也是可以接受的。 主要考点:说明常数、|=和&=~操作。 七、访问固定的内存位置(Accessing fixed memory locations) 嵌入式系统经常具有要求程序员去访问某特定的内存位置的特点。在某工程中,要求设置一绝对地址为0x67a9的整型变量的值为0xaa66。编译器是一个纯粹的ANSI编译器。写代码去完成这一任务。 这一问题测试你是否知道为了访问一绝对地址把一个整型数强制转换(typecast)为一指针是合法的。这一问题的实现方式随着个人风格不同而不同。典型的类似代码如下: int *ptr; ptr = (int *)0x67a9; //把地址转化为指针 *ptr = 0xaa55; 一个较晦涩的方法是: *(int * const)(0x67a9) = 0xaa55;
建议采用第一种方法;
八、代码例子(Code examples) 1.下面的代码输出是什么,为什么?(考查有符号类型与无符号类型之间的转换) void foo(void) { unsigned int a = 6; int b = -20; (a+b > 6) ? puts("> 6") : puts("<= 6"); } 这个问题测试你是否懂得C语言中的整数自动转换原则; 这无符号整型问题的答案是输出是“>6”。 原因是当表达式中存在有符号类型和无符号类型时所有的操作数都自动转换为无符号类型。 因此-20变成了一个非常大的正整数,所以该表达式计算出的结果大于6。这一点对于应当频繁用到无符号数据类型的嵌入式系统来说是丰常重要的。 2. 评价下面的代码片断:(考查是否懂得处理器字长) unsigned int zero = 0; unsigned int compzero = 0xFFFF; /*1's complement of zero */ 对于一个int型不是16位的处理器为说,上面的代码是不正确的。应编写如下: unsigned int compzero = ~0; 这一问题真正能揭露出应试者是否懂得处理器字长的重要性。好的嵌入式程序员非常准确地明白硬件的细节和它的局限,然而PC机程序往往把硬件作为一个无法避免的烦恼。 九、Typedef Typedef作用是声明一个新的类型名代替已有的类型名; 也可以用预处理器做类似的事。例如,思考一下下面的例子: #define dPS struct s * typedef struct s * tPS; 以上两种情况的意图都是要定义dPS 和 tPS 作为一个指向结构s指针。哪种方法更好呢?(如果有的话)为什么? 这是一个非常微妙的问题,任何人答对这个问题(正当的原因)是应当被恭喜的。答案是:typedef更好。思考下面的例子: dPS p1,p2; tPS p3,p4;
第一个扩展为
struct s * p1, p2;
上面的代码定义p1为一个指向结构的指,p2为一个实际的结构,这也许不是你想要的。第二个例子正确地定义了p3 和p4 两个指针。
另外, #define 在预编译时处理,只作简单的字符串替换;typedef 在编译时处理,不是简单的字符串替换;
1、 int x = 3,y=4,z=5;
printf("%d",~((x^y)&&!z));
输出结果 -1
2、char s[] = "912\0912"; printf("%d",strlen(s));
输出结果 3
3、int a[100][200];
printf("%d",&a[50][4]-&a[0][3]);
输出结果 1001
4、enum months{JAN = 1,FEB,MAR,APR,MAY=3,JUN,JUL,AUG,SEP,NOV,DEC}; printf("%d",(MAR&AUG)^!JAN);
输出结果 2
5、
union foo { char s[13]; int i; }; union foo f; printf("%d",sizeof(f));
输出结果 16
6、
int cnt=0; for(int a=-1;a>0;a++) { cnt++; } printf("%d %d",a,cnt);
输出结果 -1 0
7、
char a; a=255; printf("%d\n",a++);
输出结果-1
char是一个8位的有符号类型,他的取值范围是-128 ~ 127,当超过最大值时,自动从最小值开始往上加,也就是说如果a=128,那么他实际上是-128。
8、char ch='\376'; printf( "%d" ,ch);
输出结果 -2;
9、printf("12345"+3); 输出 45
10、
char * s1 = "hello"; char * s2 = "hello"; if(s1==s2) { cout<<"equal"<<endl; } else { cout<<"not equal"<<endl; }
输出 “equal”
11、(来自锐捷网络)
int (*ptr)[5] = (int(*)[5])100; printf("%d",(int)(&(*(ptr+1))[2]));
输出 128???
12、
char p; char buf[10] = {1,2,3,4,5,6,9,8}; p = (buf+1)[5];
printf("%d",p);
输出结果为 9
13、
int a[5] = {1,2,3,4,5}; int *ptr = (int*)(&a+1); printf("%d,%d\n",*(a+1),*(ptr-1));
输出结果为 2 5
14、
int x=1; int y=2; int t; if(--x&&++y) t=0; else t=1; printf("%d",y);
输出结果 y = 2
15、
int a=2, b = 0, c; c = a || ++b; cout<<"a="<<a<<" b="<<b<<" c="<<c<<endl;
输出结果 a=2 b=0 c=1
16、
i+++j++;//合法 ++i+++j;//不合法
17
int i=1; int j; j = (++i)+(++i)+(i++)+(i++)+(++i); printf("%d,%d",i,j)
输出 6 16
18、
fun()//统计x的二进制数中1的个数 { while(x) { countx++; x = x&(x-1); } return countx; }
输出为 8
 assert宏的原型定义在<assert.h>中,其作用是如果它的条件返回错误,则终止程序执行,原型定义: #include <assert.h> void assert( int expression );
assert的作用是现计算表达式 expression ,如果其值为假(即为0),那么它先向stderr打印一条出错信息, 然后通过调用 abort 来终止程序运行。
请看下面的程序清单badptr.c: #include <stdio.h> #include <assert.h> #include <stdlib.h>
int main( void ) { FILE *fp; fp = fopen( "test.txt", "w" );//以可写的方式打开一个文件,如果不存在就创建一个同名文件 assert( fp ); //所以这里不会出错 fclose( fp ); fp = fopen( "noexitfile.txt", "r" );//以只读的方式打开一个文件,如果不存在就打开文件失败 assert( fp ); //所以这里出错 fclose( fp ); //程序永远都执行不到这里来
return 0; }
[root@localhost error_process]# gcc badptr.c [root@localhost error_process]# ./a.out a.out: badptr.c:14: main: Assertion `fp' failed. 已放弃
使用assert的缺点是,频繁的调用会极大的影响程序的性能,增加额外的开销。 在调试结束后,可以通过在包含#include <assert.h>的语句之前插入 #define NDEBUG 来禁用assert调用,示例代码如下: #include <stdio.h> #define NDEBUG #include <assert.h>
用法总结与注意事项: 1)在函数开始处检验传入参数的合法性 如:
int resetBufferSize(int nNewSize) { //功能:改变缓冲区大小, //参数:nNewSize 缓冲区新长度 //返回值:缓冲区当前长度 //说明:保持原信息内容不变 nNewSize<=0表示清除缓冲区 assert(nNewSize >= 0); assert(nNewSize <= MAX_BUFFER_SIZE);
... }
2)每个assert只检验一个条件,因为同时检验多个条件时,如果断言失败,无法直观的判断是哪个条件失败
不好: assert(nOffset>=0 && nOffset+nSize<=m_nInfomationSize);
好: assert(nOffset >= 0); assert(nOffset+nSize <= m_nInfomationSize);
3)不能使用改变环境的语句,因为assert只在DEBUG个生效,如果这么做,会使用程序在真正运行时遇到问题 错误: assert(i++ < 100) 这是因为如果出错,比如在执行之前i=100,那么这条语句就不会执行,那么i++这条命令就没有执行。 正确: assert(i < 100) i++; 4)assert和后面的语句应空一行,以形成逻辑和视觉上的一致感 5)有的地方,assert不能代替条件过滤
const定义的常量在超出其作用域之后其空间会被释放,而static定义的静态常量在函数执行后不会释放其存储空间。
static表示的是静态的。类的静态成员函数、静态成员变量是和类相关的,而不是和类的具体对象相关的。即使没有具体对象,也能调用类的静态成员函数和成员变量。一般类的静态函数几乎就是一个全局函数,只不过它的作用域限于包含它的文件中。
在C++中,static静态成员变量不能在类的内部初始化。在类的内部只是声明,定义必须在类定义体的外部,通常在类的实现文件中初始化,如:double Account::Rate=2.25;static关键字只能用于类定义体内部的声明中,定义时不能标示为static
在C++中,const成员变量也不能在类定义处初始化,只能通过构造函数初始化列表进行,并且必须有构造函数。
const数据成员 只在某个对象生存期内是常量,而对于整个类而言却是可变的。因为类可以创建多个对象,不同的对象其const数据成员的值可以不同。所以不能在类的声明中初始化const数据成员,因为类的对象没被创建时,编译器不知道const数据成员的值是什么。
const数据成员的初始化只能在类的构造函数的初始化列表中进行。要想建立在整个类中都恒定的常量,应该用类中的枚举常量来实现,或者static cosnt。
下面是一个他们的应用实例
[cpp] view plaincopy
assert宏的原型定义在<assert.h>中,其作用是如果它的条件返回错误,则终止程序执行,原型定义: #include <assert.h> void assert( int expression );
assert的作用是现计算表达式 expression ,如果其值为假(即为0),那么它先向stderr打印一条出错信息, 然后通过调用 abort 来终止程序运行。
请看下面的程序清单badptr.c: #include <stdio.h> #include <assert.h> #include <stdlib.h>
int main( void ) { FILE *fp; fp = fopen( "test.txt", "w" );//以可写的方式打开一个文件,如果不存在就创建一个同名文件 assert( fp ); //所以这里不会出错 fclose( fp ); fp = fopen( "noexitfile.txt", "r" );//以只读的方式打开一个文件,如果不存在就打开文件失败 assert( fp ); //所以这里出错 fclose( fp ); //程序永远都执行不到这里来
return 0; }
[root@localhost error_process]# gcc badptr.c [root@localhost error_process]# ./a.out a.out: badptr.c:14: main: Assertion `fp' failed. 已放弃
使用assert的缺点是,频繁的调用会极大的影响程序的性能,增加额外的开销。 在调试结束后,可以通过在包含#include <assert.h>的语句之前插入 #define NDEBUG 来禁用assert调用,示例代码如下: #include <stdio.h> #define NDEBUG #include <assert.h>
用法总结与注意事项: 1)在函数开始处检验传入参数的合法性 如:
int resetBufferSize(int nNewSize) { //功能:改变缓冲区大小, //参数:nNewSize 缓冲区新长度 //返回值:缓冲区当前长度 //说明:保持原信息内容不变 nNewSize<=0表示清除缓冲区 assert(nNewSize >= 0); assert(nNewSize <= MAX_BUFFER_SIZE);
... }
2)每个assert只检验一个条件,因为同时检验多个条件时,如果断言失败,无法直观的判断是哪个条件失败
不好: assert(nOffset>=0 && nOffset+nSize<=m_nInfomationSize);
好: assert(nOffset >= 0); assert(nOffset+nSize <= m_nInfomationSize);
3)不能使用改变环境的语句,因为assert只在DEBUG个生效,如果这么做,会使用程序在真正运行时遇到问题 错误: assert(i++ < 100) 这是因为如果出错,比如在执行之前i=100,那么这条语句就不会执行,那么i++这条命令就没有执行。 正确: assert(i < 100) i++; 4)assert和后面的语句应空一行,以形成逻辑和视觉上的一致感 5)有的地方,assert不能代替条件过滤
const定义的常量在超出其作用域之后其空间会被释放,而static定义的静态常量在函数执行后不会释放其存储空间。
static表示的是静态的。类的静态成员函数、静态成员变量是和类相关的,而不是和类的具体对象相关的。即使没有具体对象,也能调用类的静态成员函数和成员变量。一般类的静态函数几乎就是一个全局函数,只不过它的作用域限于包含它的文件中。
在C++中,static静态成员变量不能在类的内部初始化。在类的内部只是声明,定义必须在类定义体的外部,通常在类的实现文件中初始化,如:double Account::Rate=2.25;static关键字只能用于类定义体内部的声明中,定义时不能标示为static
在C++中,const成员变量也不能在类定义处初始化,只能通过构造函数初始化列表进行,并且必须有构造函数。
const数据成员 只在某个对象生存期内是常量,而对于整个类而言却是可变的。因为类可以创建多个对象,不同的对象其const数据成员的值可以不同。所以不能在类的声明中初始化const数据成员,因为类的对象没被创建时,编译器不知道const数据成员的值是什么。
const数据成员的初始化只能在类的构造函数的初始化列表中进行。要想建立在整个类中都恒定的常量,应该用类中的枚举常量来实现,或者static cosnt。
下面是一个他们的应用实例
[cpp] view plaincopy
- #include <iostream>
- using namespace std;
- class A
- {
- public:
- A(int a);
- static void print();//静态成员函数
- private:
- static int aa;//静态数据成员的声明
- static const int count;//常量静态数据成员(可以在构造函数中初始化)
- const int bb;//常量数据成员
- };
- int A::aa=0;//静态成员的定义+初始化
- const int A::count=25;//静态常量成员定义+初始化
- A::A(int a):bb(a)//常量成员的初始化
- {
- aa+=1;
- }
- void A::print()
- {
- cout<<"count="<<count<<endl;
- cout<<"aa="<<aa<<endl;
- }
-
- void main()
- {
- A a(10);
- A::print();//通过类访问静态成员函数
- a.print();//通过对象访问静态成员函数
- }
- 上一篇:C++中类的构造函数与析构函数(成员初始化列表)这是<C++ primmer>中的一部分: Lvalues and Rvalues 左值和右值 We'll have more to say about expressions in Chapter 5, but for now it is useful to know that there are two kinds of expressions in C++: 我们在第五章再详细探讨表达式,现在先介绍 C++ 的两种表达式: lvalue (pronounced "ell-value"): An expression that is an lvalue may appear as either the left-hand or right-hand side of an assignment. 左值(发音为 ell-value):左值可以出现在赋值语句的左边或右边。 rvalue (pronounced "are-value"): An expression that is an rvalue may appear on the right- but not left-hand side of an assignment. 右值(发音为 are-value):右值只能出现在赋值的右边,不能出现在赋值语句的左边。 Variables are lvalues and so may appear on the left-hand side of an assignment. Numeric literals are rvalues and so may not be assigned. Given the variables: 变量是左值,因此可以出现在赋值语句的左边。数字字面值是右值,因此不能被赋值。给定以下变量: int units_sold = 0; double sales_price = 0, total_revenue = 0; it is a compile-time error to write either of the following: 下列两条语句都会产生编译错误: // error: arithmetic expression is not an lvalue units_sold * sales_price = total_revenue; // error: literal constant is not an lvalue 0 = 1; Some operators, such as assignment, require that one of their operands be an lvalue. As a result, lvalues can be used in more contexts than can rvalues. The context in which an lvalue appears determines how it is used. For example, in the expression 有些操作符,比如赋值,要求其中的一个操作数必须是左值。结果,可以使用左值的上下文比右值更广。左值出现的上下文决定了左值是如何使用的。例如,表达式 units_sold = units_sold + 1; the variable units_sold is used as the operand to two different operators. The + operator cares only about the values of its operands. The value of a variable is the value currently stored in the memory associated with that variable. The effect of the addition is to fetch that value and add one to it. 中,units_sold 变量被用作两种不同操作符的操作数。+ 操作符仅关心其操作数的值。变量的值是当前存储在和该变量相关联的内存中的值。加法操作符的作用是取得变量的值并加 1。 The variable units_sold is also used as the left-hand side of 可以看出,左值和右值是跟左和右挂钩的
- L-value or L value may refer to: A value (computer science) that has an address The value assigned to an L-shell, a particular set of planetary magnetic field lines A measure of brightness of a lunar eclipse on the Danjon scale From Wikipedia, the free encyclopedia Jump to: navigation, search R-value can refer to: Properties of materials: R-value (insulation), the efficiency of insulation R-value (soils), stability of soils and aggregates for pavement construction r-value, in computer science, a value that does not have an address in a computer language R-factor (crystallography), a measure of the agreement between the crystallographic model and the diffraction data In statistics, r (or r value) refers to the Pearson product-moment correlation coefficient, often called simply correlation coefficient
-
















 126
126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









