







一、基本原理
感知音频编码的设计思想
1)人耳听觉特性
- 临界频带
人类听觉系统大致等效于一个在0Hz到20KHz频率范围内由25个重叠的带通滤波器组成的滤波器组,这25个频带被称为临界频带,人耳不能区分同一频带内同时发生的不同声音。
掩蔽效应
一个较弱的声音的听觉感受被另一个较强的声音影响的现象称为人耳的听觉掩蔽效应。掩蔽作用与信号频率和强度有关。掩蔽效应在一定频率范围内不随带宽增大而改变,直至超过某个频率值。心理声学模型
听觉系统中存在一个听觉阈值电平,低于这个电平的声音信号就听不到听觉阈值的大小随声音频率的改变而改变。一个人是否听到声音取决于声音的频率,以及声音的幅度是否高于这种频率下的听觉阈值,即听觉阈值电平是自适应的,会随听到的不同频率声音而发生变化。
利用心理声学模型可以消除更多的冗余数据,听不见的可以不编码,主要声音成分用较多的比特数表示,引入的量化噪声在低于听觉阈值时,不会对声音的感觉造成影响,从而获得更大的压缩效率。
2)子带编码
- 由于不同频带的掩蔽特性不同,因此可以将原始信号分解为若干个子频带,对其分别进行不同的编码处理,接收端再合成为全频带信号,从而获得更大的压缩比,这种方法叫子带编码。
- 可以用信号分解的方法,划分出不同的子序列,递归使用分解方法,得到子序列,称为分析—综合,可利用数字滤波器实现。
- 临界频带

2.MPEG-1AudioLayerII编码器原理
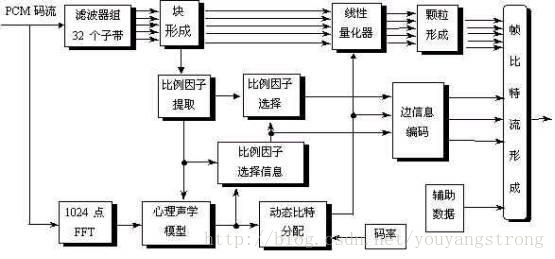
1)样本变换到频域
- 多相滤波器组将输入信号分成32个子带信号。
- 等分的子带并不能精确地反映人耳的听觉特性,模型需要更精细的频率分辨率,而且计算掩蔽阈值也需要每个频率的幅值,因此引入FFT补偿频率分辨率不足的问题,所以LayerII采用了1024点FFT。
- 时频分析的矛盾:滤波时希望输入的样点越少越好(样本窗口大小T0越小越好),通过子带分析滤波器组能使信号具有高的时间分辨率,确保在短暂冲击信号情况下,编码的声音信号具有足够高的质量;而FFT变换时则希望输入的样点越多越好(F0=fs/T0,T0越大F0越小),使信号通过FFT运算具有高的频率分辨率,因为掩蔽阈值是从功率谱密度推出来的。因此Layer II 采用1024样本窗口,每帧1152个样本点,32个子带,每个子带3组,1组12个样点。
2)计算掩蔽阈值
- 计算单独掩蔽阈值:分成某频带内的乐音和噪声分别计算,噪声是临界带宽内所有的非乐音部分的集中
- 计算全局掩蔽阈值:绝对阈值加上单独阈值
- 计算子带掩蔽阈值:选择出本子带中最小的阈值作为子带阈值,对高频不正确,因为高频区的临界频带很宽,可能跨越多个子带,当一个子带在很宽的频带内却远离代表频率时,无法得到准确的非音调掩蔽值,但计算量低
3)码率分配
- 码率分配的目标是使整帧和每个子带的总噪声—掩蔽比最小。
- 在调整到固定的码率之前:先确定可用于样值编码的有效比特数,这个数值取决于比例因子、比例因子选择信息、比特分配信息以及辅助数据所需比特数。
- 对各个子带每12个样点进行一次比例因子计算。先定出12个样点中绝对值的最大值。查比例因子表中比这个最大值大的最小值作为比例因子。用6比特表示。第2层的一帧对应36个子带样值,是第1层的三倍,原则上要传三个比例因子。为了降低比例因子的传输码率,每帧中每个子带的三个比例因子被一起考虑,划分成特定的几种模式,用比例因子选择信息(每子带2比特)表示,如果一个比例因子和下一个只有很小的差别,就只传送大的一个,这种情况对于稳态信号经常出现。
- 比特分配的过程
- 对每个子带计算MNR(掩蔽噪声比),MNR = SNR (信噪比)–SMR(信号掩蔽比),其中SMR = 信号能量/ 掩蔽阈值,由心理声学模型对FFT结果计算得出
- 对最低MNR的子带分配比特,使获益最大的子带的量化级别增加一级
- 重新计算分配了更多比特子带的MNR,循环上一步骤,直至没有比特可用
二、实验要求
输出音频的采样率和目标码率
选择某个数据帧
- 输出该帧所分配的比特数
- 输出该帧的比例因子
- 输出该帧的比特分配结果
三、关键代码分析
在m2aenc.c文件的main函数中加入如下代码:
……
#else
/*************add by zml****************/
if(frameNum==2)
{
fprintf(outinfo,"采样率:%.1fkhz\n",s_freq[header.version][header.sampling_frequency]);
fprintf(outinfo,"目标码率:%dMbps\n",bitrate[header.version][header.bitrate_index]);
fprintf(outinfo,"第2帧所用比特数:%d\n",adb);
}
/*************add by zml end*************/
transmission_pattern (scalar, scfsi, &frame);
main_bit_allocation (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
if (error_protection)
CRC_calc (&frame, bit_alloc, scfsi, &crc);
encode_info (&frame, &bs);
if (error_protection)
encode_CRC (crc, &bs);
encode_bit_alloc (bit_alloc, &frame, &bs);
encode_scale (bit_alloc, scfsi, scalar, &frame, &bs);
subband_quantization (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
*subband, &frame);
sample_encoding (*subband, bit_alloc, &frame, &bs);
/***********add by zml*************/
if(frameNum==2)
{
fprintf(outinfo,"比例因子\n");
for ( cha = 0; cha < nch; cha++ )//声道
{
fprintf(outinfo,"声道%d\n",cha);
fprintf(outinfo,"子带\t组1\t组2\t组3\t\n");
for ( sbd = 0; sbd < frame.sblimit; sbd++ )//子带
{
fprintf(outinfo,"%4d\t",sbd);
for( gro = 0; gro < 3; gro++ )//组
{
fprintf(outinfo,"%3d\t",scalar[cha][gro][sbd]);
}
fprintf(outinfo,"\n");
}
}
fprintf(outinfo,"帧比特分配:\n");
for ( cha = 0; cha < nch; cha++ )//声道
{
fprintf(outinfo,"声道%d\n",cha);
for ( sbd = 0; sbd < frame.sblimit; sbd++ )//子带
{
fprintf(outinfo,"子带%2d:\t",sbd);
fprintf(outinfo,"%2d\n",bit_alloc[cha][sbd]);
}
}
if(outinfo)
fclose(outinfo);
/********************add by zml end******************/
}
#endif
/* If not all the bits were used, write out a stack of zeros */
for (i = 0; i < adb; i++)
put1bit (&bs, 0);
if (header.dab_extension) {
/* Reserve some bytes for X-PAD in DAB mode */
putbits (&bs, 0, header.dab_length * 8);
……四、实验结果及分析
输入test.wav文件
输出test.mp2文件
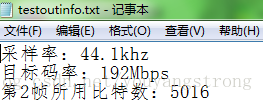
test.mp2的采样率、目标码率、第2帧所分配的比特数
第2帧比例因子和比特分配结果

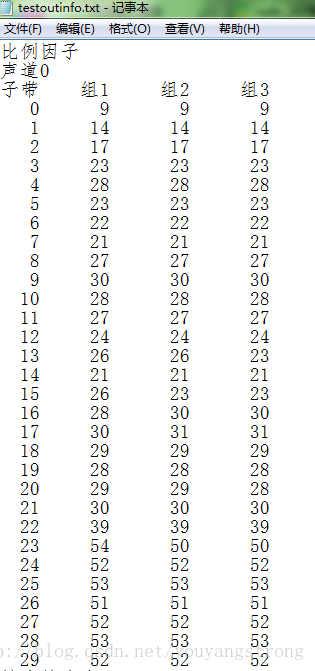

根据输出结果可以发现,同一子带3个组的比例因子非常接近,且大部分都一样,因此采用加入比例因子选择信息的方法,可以压缩很多的冗余数据。
帧比特分配结果表明,越高频比特数分配得越少,很多高频子带分配的比特数都是0,因为高频大部分都是噪音。
相比之前的2.83Mb的wav文件,压缩后的MPEG文件只有791kb,压缩比为3.58。














 4657
4657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









