




 文章介绍了MySQL的ONDUPLICATEKEYUPDATE语句,用于在数据导入时实现数据的插入或更新。该特性简化了开发,提高了效率,特别是在批量操作中。然而,它不是SQL标准语法,可能造成迁移问题,并且在复杂或大数据量环境下可能引发问题。文章提供了一个存储股票每日数据的案例,展示了如何利用此特性处理联合唯一索引的表。
文章介绍了MySQL的ONDUPLICATEKEYUPDATE语句,用于在数据导入时实现数据的插入或更新。该特性简化了开发,提高了效率,特别是在批量操作中。然而,它不是SQL标准语法,可能造成迁移问题,并且在复杂或大数据量环境下可能引发问题。文章提供了一个存储股票每日数据的案例,展示了如何利用此特性处理联合唯一索引的表。
【Mysql】 on duplicate key update用法、优缺点以及使用案例
1. 应用场景:
导入数据功能,需要实现数据不存在时进行新建,有数据修改时则进行更新。
在实现时,思路通常为先判断数据是新增还是更新,除了我们在代码层面实现,Mysql本身提供了
ON DUPLICATE KEY UPDATE 一步实现(Mysql独有语法)
2. ON DUPLICATE KEY UPDATE 简介:
在MySQL数据库中,如果在insert语句后面带上ON DUPLICATE KEY UPDATE 子句,而要插入的行与
表中现有记录的惟一索引或主键中产生重复值,那么就会发生旧行的更新;如果插入的行数据与现有表
中记录的唯一索引或者主键不重复,则执行新记录插入操作。
简而言之:**数据存在则更新,无则创建**
ON DUPLICATE KEY UPDATE sql 模板
INSERT INTO 表名
(字段名1, 字段名2 )
VALUES
(字段值1, 字段值2)
ON DUPLICATE KEY UPDATE
字段名1 = VALUES(字段名1),
字段名2 = VALUES(字段名2)
3.ON DUPLICATE KEY UPDATE 优缺点
优点:
a. 开发简单,对已有表批量插入新数据时尤其方便;
b. 可以减少网络连接开销(减少了数据查询、操作次数),在一定量的数据操作时,效率上也提高。
缺点:
a. MySQL私有语法,非SQL92标准语法,当迁移数据时会造成麻烦,需要改写代码。例如MySQL迁移PgSQL;
b. 当环境复杂时,数据量大的情况下,会出现意想不到的问题。(数据量大、产生并发,建议还是用原子操作);
c. 业务逻辑分散在应用逻辑层和数据层,会对项目维护留下隐患。
4.案例(存储股票每日数据):
a.创建 以 `symbol`和`date`组成的联合唯一索引 的表 `financial_stocks_data`
CREATE TABLE `financial_stocks_data` (
`id` int NOT NULL AUTO_INCREMENT,
`symbol` varchar(255) DEFAULT NULL,
`date` varchar(255) DEFAULT NULL,
`open_price` varchar(255) DEFAULT NULL,
`close_price` varchar(255) DEFAULT NULL,
`volume` varchar(255) DEFAULT NULL,
`modify_time` datetime(6) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `financial_stocks_data_symbol_date_7ee4c125_uniq` (`symbol`,`date`),
KEY `financial_stocks_data_modify_time_a40a61a2` (`modify_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
b.通过唯一索引,使用 ON DUPLICATE KEY UPDATE 实现 批量更新或创建sql语句
# financial_stocks_data 将插入或更新这两条数据
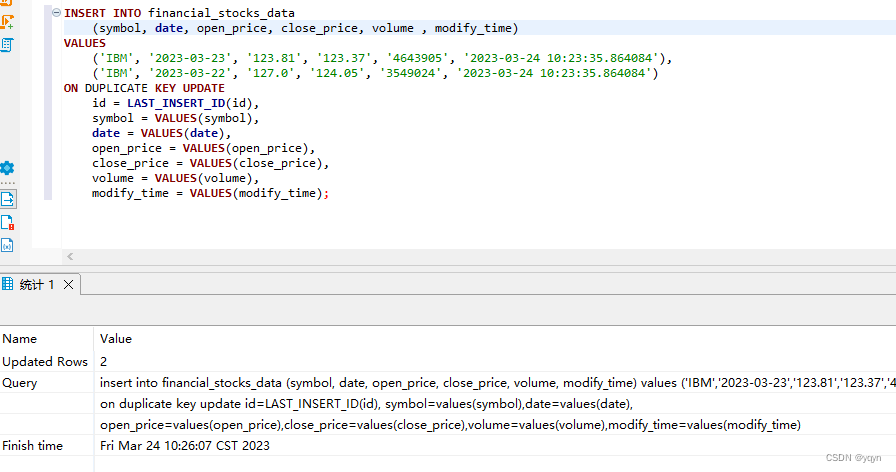
INSERT INTO financial_stocks_data
(symbol, date, open_price, close_price, volume , modify_time)
VALUES
('IBM', '2023-03-23', '123.81', '123.37', '4643905', '2023-03-24 10:23:35.864084'), -- 需要插入的数据
('IBM', '2023-03-22', '127.0', '124.05', '3549024', '2023-03-24 10:23:35.864084')
ON DUPLICATE KEY UPDATE
id = LAST_INSERT_ID(id), -- 自增ID
symbol = VALUES(symbol),
date = VALUES(date),
open_price = VALUES(open_price),
close_price = VALUES(close_price),
volume = VALUES(volume),
modify_time = VALUES(modify_time);
PS 执行sql成功截图


















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











