







概述
最近翻Flume官网又有了新的收获,准备对Flume进行一个详细的描述,Fume到底是什么,有什么用,怎么用,选型问题,各种参数选择。当然对于参数的选择作者在以前刚开始学习的时候遇到过不少坑,不同的版本参数是不一样的,大家一定要对应着自己的版本去官网查找,官网是最权威的。有什么不对的地方大家相互交流学习。
Flume介绍
老规矩官网地址
Flume是一种分布式,可靠,高可用的服务,用于有效地从许多不同的源端收集,聚合和移动大量日志数据到集中
式数据存储。 它具有基于流数据流的简单灵活的架构、它具有可靠性机制和许多故障转移和恢复机制,具有强大
的容错能力。 它使用简单的可扩展数据模型,允许在线分析应用程序。
Apache Flume的使用不仅限于日志数据聚合。 由于数据源是可定制的,因此Flume可用于传输大量事件数据,
包括但不限于网络流量数据,社交媒体生成的数据,电子邮件消息以及几乎任何可能的数据源。
看完上面一段话相信大家可能看的也是云里雾里的,最简单的大家可以理解Flume为日志收集的工具,后面会对上面的每句话做个详细的解读。
Flume历史
Flume目前有两种版本代码行,版本0.9.x和1.x.
0.9x以前叫做Flume OG(original generation),属于 cloudera。但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,日志传输不稳定的现象尤为严重,为了解决这些问题,1.X后对Flume进行了重构重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。Apache Flume是Apache Software Foundation的顶级项目。
Flume产生背景
我们知道对于关系型数据库我们可以使用sqoop进行数据的处理,导入hive,hdfs,mysql等。那对于一些日志该怎么处理呢?(From outside To inside ),怎么样定时收集ng产生的日志到HDFS呢?
我们可能想到直接使用shell写一个脚本,使用crontab进行调度,这样不就行了吗。。但是大家有没有想到一个问题呢,如果日志量太大,涉及到存储格式、压缩格式、序列化等等一些大数据中常用的东西怎么办呢?要从不同的源端收集是不是要写多个脚本呢?同样我要存到不同的地方发该怎么办呢?肯定不止这些问题。所以Flume出现了来帮助我们解决这些问题。
Flume基本概念
可以参考以前的博客博客地址,
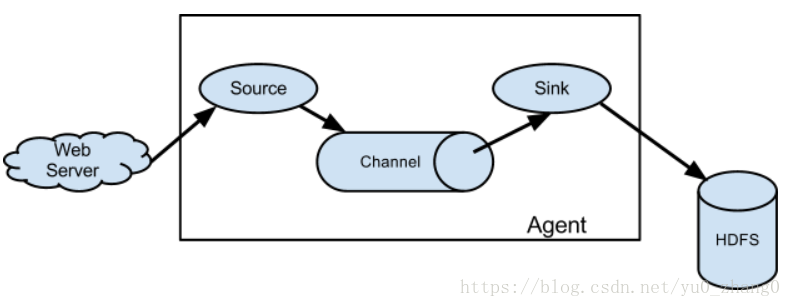
Event: Event是Flume事件处理的最小单元,Flume在读取数据源时,会将一行数据(也就是遇到\r\n)包装成一个Event,它主要有俩个部分,Header和Body, Header主要是以Key,Value的形式用来记录该数据的一些冗余信息,可用来标记数据唯一信息,利用Header的信息,我们可以对数据做出一些额外的操作,如对数据进行一个简单过滤,Body则是存入真正数据的地方。
Agent: 代表一个独立的Flume进程,包含组件Source、 Channel、 Sink。(Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources、channel和sinks。)
flume之所以这么神奇,是源于它自身的一个设计,这个设计就是agent,agent本身是一个java进程,运行在日志收集节点—所谓日志收集节点就是服务器节点。
1. Source:负责从源端采集数据,输出到channel中,常用的Source有exec/Spooling Directory/Taildir Source/NetCat
2. Channel:负责缓存Source端来的数据,常用的Channel有Memory/File
3. Sink:处理Channel而来的数据写到目标端,常用的Sink有HDFS/Logger/Avro/Kafka
总结:Flume处理数据的最小单元是Event,一个Agent代表一个Flume进程,一个Agent=Source+Channel+Sink 组成。Flume牛逼之处也在于他的组成部分,可以进行各种组合选型。
讲到这里相信大家会有个简单的了解了,下面就要对Flume介绍中说的进行详细的剖析。
Flume特点
前面进行简单的讲解,现在我们来总结Flume具有的一些特点:
1. 可以从不同的源端收集数据;
2. 输出结果可以到不同的地方,下一个Agent、HDFS、Kafka等。
3. 架构简单灵活,可配置化,可插拔
4. 有多种Interceptor可供选择
5. 具有可靠性和可恢复性
6. 具有容错机制和负载均衡机制(Flume Sink Processors)
7. 具有复制和多路复用机制(flume channel selectors)
Flume详细剖析
对于分布式我们这里就不多说了,大数据场景下必然是的。我们重点讲解下高可靠,高可用,怎么达到可靠,高可用。
可靠性
Flume可靠性:Flume 使用事务性的方式保证传送Event整个过程的可靠性。 Sink 必须在Event 被存入 Channel 后,或者,已经被传达到下一站agent里,又或者已经被存入外部数据目的地之后,才能把 Event 从 Channel 中 remove 掉。这样数据流里的 event 无论是在一个 agent 里还是多个 agent 之间流转,都能保证可靠,因为以上的事务保证了 event 会被成功存储起来。这就保证了端到端的可靠性。比如 Flume支持在本地保存一份文件 channel 作为备份,而memory channel 将event存在内存 queue 里,速度快,但丢失的话无法恢复,所以channel的选型,维护也很重要。
flume使用这种事物的方式保证events传输的可靠性所以这就不得不提Flume的事务机制(类似数据库的事务机制):Flume使用两个独立的事务分别负责从soucrce到channel,以及从channel到sink的事件传递。
比如spooling directory source 为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到channel且提交成功,那么source就将该文件标记为完成。同理,事务以类似的方式处理从channel到sink的传递过程,如果因为某种 原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到channel中,等待重新传递。
可恢复性
events被存储在channel里面,如果flume挂了可以从channel中恢复,保证数据不会丢失(不是绝对的),你可以选择不同类型的channel根据业务需求,例如file channel存储在本地磁盘,可以保证数据不会丢失,
也有memory channel,他简单将event存储在内存队列中,速度快,但是agent挂掉可能会使得缓存在内存中的数据丢失。
总的来说Flume整体架构的设计和选型(扇入,扇出),使得它具有可靠性和可恢复性。以及后面还会讲解的Flume Sink Processors和flume channel selectors也是很重要的一点。
讲到这里大家就可以先进行简单的操作了,官网也有些例子,对于新手来说看起来还是比较吃力的,可以参考我以前写的博客Flume基本操作和flume常用场景。大家一定要自己去练习。
架构
未完待续…(最近工作任务稍多,后面会继续怼)














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









