







在上一篇博客:hadoop入门级总结一:HDFS中,简单的介绍了hadoop分布式文件系统HDFS的整体框架及文件写入读出机制。接下来,简要的总结一下hadoop的另外一大关键技术之一分布式计算框架:Map/Reduce。
一、Map/Reduce是什么:
Map/Reduce是在2004年谷歌的一篇论文中提出大数据并行编程框架,由两个基本的步骤Map(映射)和Reduce(化简)组成,Map/Reduce由此得名。同时,由于它隐藏了分布式计算中并行化
、容错
、数据分布
、负载均衡等内部细节,实际的使用中普通编程人员/应用人员只需关系map/reduce两个过程的实现,大大的降低了实现分布式计算的要求,因此在日志分析、海量数据排序等等场合中广泛应用。
二、hadoop中Map/Reduce的框架原理:
尽管对应用人员而言,不必太在意
Map/Reduce的内部实现细节,但了解
Map/Reduce的基本框架对实现更复杂的数据分析或者性能优化等方面多少有些好处:
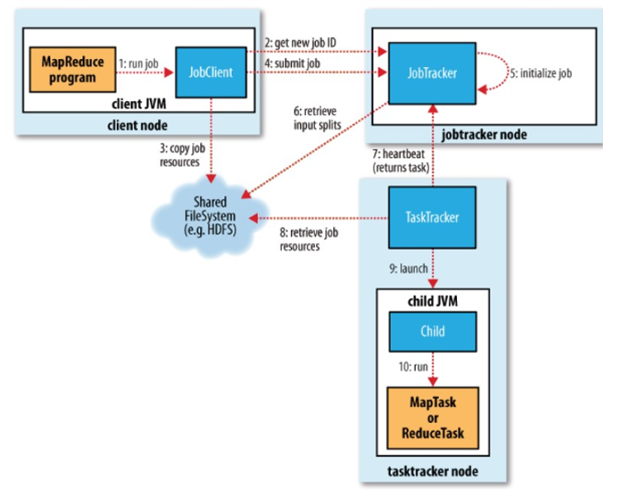
上图是Map/Reduce的一个比较经典的框架原理图,实际上随着hadoop从1.0升级到2.0版本,会有一些改进,但整体思路是基本不会变的。整个Map/Reduce框架包括3部分:JobClient、JobTracker、TaskTracker三部分组成,同时出入数据和输出数据是存储在HDFS中的。
JobClient:Map/Reduce客户端程序,负责向JobTracker发起分布式计算的请求,并上传分布式计算程序和配置文件。
JobTracker:可以说是Map/Reduce的中枢神经系统了,负责接收JobClient提交的分布式计算请求,并向TaskTracker分发计算任务,是整个Map/Reduce系统额资源管理者和协调者。
TaskTracker:负责具体的map、Reduce任务的执行,并与JobTracker通信汇报自己的工作进展。
三、hadoop中Map/Reduce的任务的执行过程:
hadoop中一个Map/Reduce任务拆解为两个过程:Map过程和Reduce过程,两个过程可能在不同的计算节点上完成,以下是一个经典的Map/Reduce过程图:
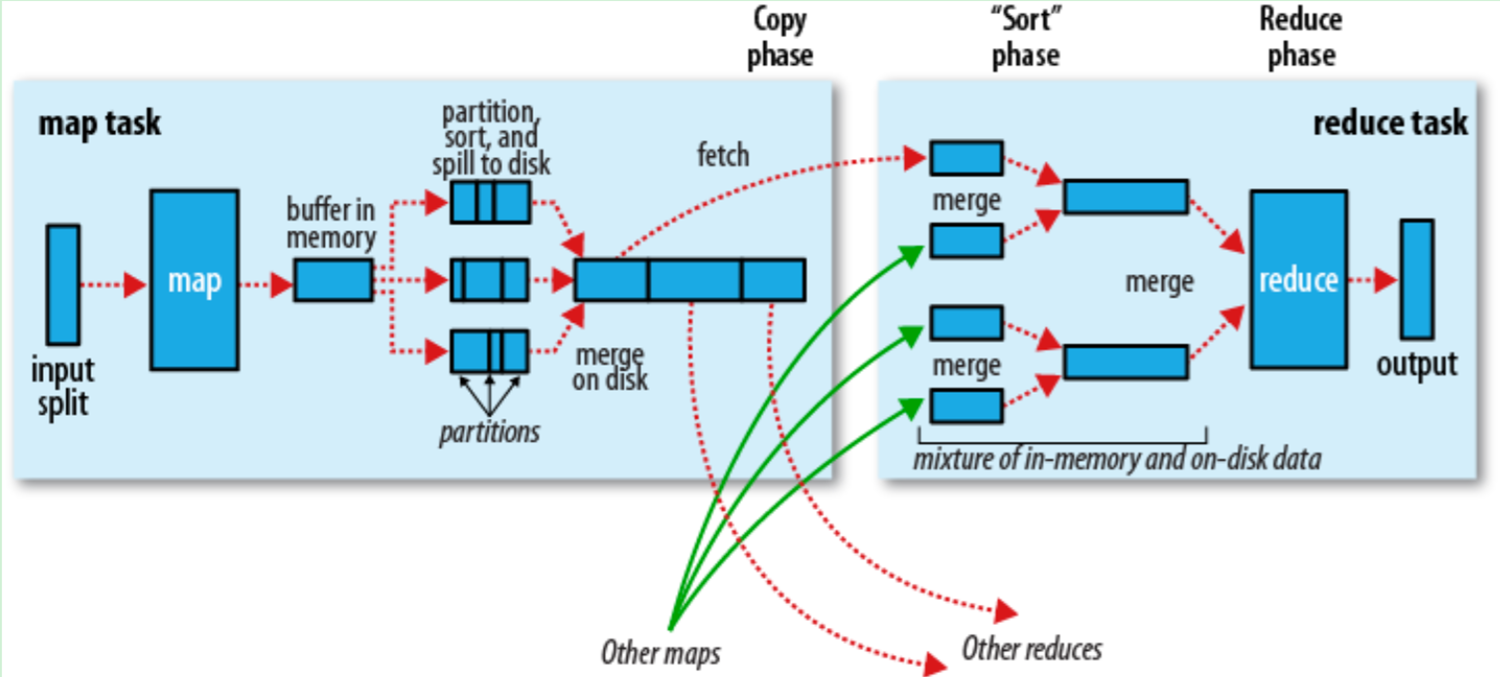
我们从图的左边开始看,input split为从HDFS中读取过来的数据,由于HDFS中文件是按照block来组织的,在这里读取的时候,也是按照block读取进来开始计算的,一般来说,数据是边读取边计算的一个流式的过程。之后数据通过map映射,会转换会一些基本<key,value>的形式,这个时候并不是直接把map后的数据发送给reduce端,因为第一直接map后的数据是无序的、第二直送发送会占用大量的网络IO资源。因此在中间会经过一个shuffle的过程。
所谓shuffle,其实就是将数据打乱再整理的一个过程,这样出来的数据就是干净有序的了。shuffle过程包括partition、sort、spill三个过程。
shuffle:
map之后的数据会写入一个内存缓冲区,一条原始记录进过map后转换成<key,value>的形式进入内存缓冲区,但是此时并不知道这个<key,value>对应该发送给哪个reducetask,这个时候partition开始派上用场了,partition根据key的值和reducetask的数量确定这个<key,value>具体应该发送给哪个reducetask。确定的过程是这样的:partition计算key的hash值,将hash对reducetask的数量的数量求模 来确定要发送的reducetask的ID (实际上,由于key值得非均衡分布 这种算法可能会导致发送给某台reducetask的数据过多 而另外的reducetask收到的数据过程,hadoop允许我们自己实现partition接口来实现数据的均衡)。
内存缓冲区的大小当然是有限制的,默认是100MB,Map的输出数据一般会比这个大,因此但内存缓冲区快要写满时,hadoop即启动一个线程来讲缓冲区的数据输出到磁盘,这个过程叫做溢写 spill,对应的有一个溢写比例spill.percent,如果将其值设置为0.8,则当内存缓冲区的数据达到80MB大小时,溢写线程启动并锁定这个80MB的内存区域,开始对80MB内部的数据做排序并写出至本地磁盘。这个时候map的输出就只能往剩下的20MB的内存区域中写数据了。这样写一次的话就是一个80MB的文件了。当溢写很多次的话,就会在本地生成很多的小文件。
将这些小文件发送给reducetask并不是一个很好的主意,溢写之后hadoop同时会进行combine操作和merge操作,combine是将具有相同key值得<key,value>组合,merge将小文件合并为大文件等待map过程结束后进行发送。
每个maptask的工作量有大有小,有的很早就完成了任务,有的还在辛勤工作,一部分完成了工作的maptask向JobTracker发送消息告知分配的任务已经完成。这个时候reducetask也没有闲着,reducetask向JobTracker发送消息,查询已经完成任务的maptask,并从该maptask的本地文件系统拉取数据,由于有很多的maptask,因此reducetask也会得到很多的小文件,reducetask拉取数据的同时会对这些文件做merge操作,为即将开始的reduce任务做准备。
当Map过程和shuffle过程真正结束的时候,reducetask才开始reduce过程,最后将结果输出至HDFS。
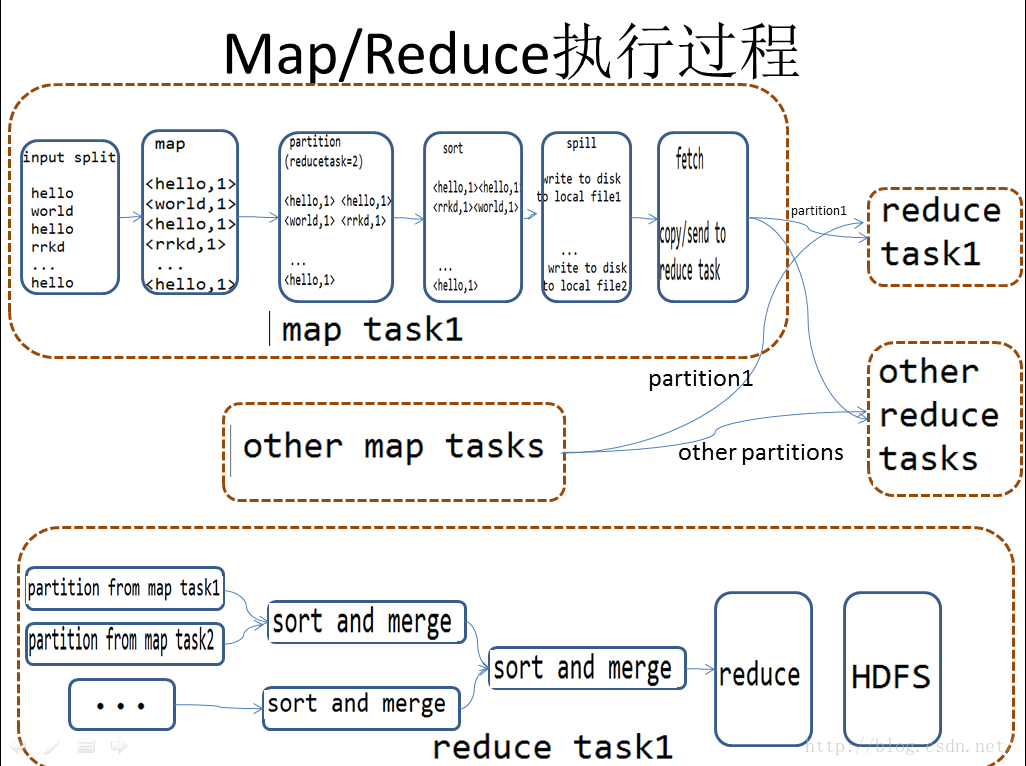
一个word_count实例,一图看明白整个Map/reduce过程到底干了些啥:
四、hadoop中Map/Reduce的编程如何搞:
由于Map/Reduce框架是由JAVA语言实现的,因此允许应用人员继承Map/Reduce框架提供的类或者实现其接口来完成map、reduce工作。当然,对于很多人而言,不熟悉JAVA或者JAVA打包比较麻烦,想快速的实现一个map、reduce来完成我们的数据分析,又该咋整呢?
hadoop为应用人员提供了另外一套方法:hadoop-streaming。hadoop-streaming框架允许任何程序语言实现的程序 在Hadoop MapReduce中使用,方便已有程序向Hadoop平台移植。实现方法是基于标准的输入输出,应用人员的程序由标准输入获得原始数据 并map,通过标准输出将中间结果输出,reduce端通过标准输入获得中间结果 并进行reduce操作 在通过标准输出将结果输出给hadoop的后续处理过程。在此过程中,用户只需要实现map函数和reduce函数,并将程序和配置信息通过hadoop shell提交给hadoop就可以了。
基本的map函数实现:

基本的reduce函数实现:
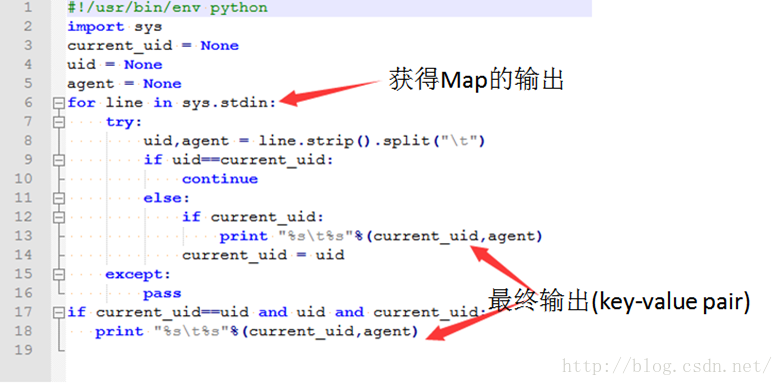
这里是用python实现的,当然,也可以由c/c++/go等等其他的语言来实现map/reduce,并提交Job给hadoop运行。
hadoop的两大核心组件(HDFS和Map/Reduce)至此总结完了,后续将总结一下hbase和hive方面的东西。
由于shuffle比较复杂,上面的内容都是查阅资料后个人整理总结所得,不免有错误或者疏漏之处,敬请指出。















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









