









对于大多数数据,在一维空间或者说是低维空间都是很难完全分割的,但是在高纬空间间往往可以找到一个超平面,将其完美分割。
引用The Curse of Dimensionality in Classification的例子来说明:
想象下我们有一系列图片,每张图描述的不是猫就是狗。现在我们想利用这些图片来做一个可以判断猫狗的分类器。首先,我们需要找到一些描述猫狗特征,利用这些特征,分类器能够识别猫狗。比如可以通过颜色来区分它们,一种分类方法是将红、绿、蓝三种颜色作为识别特征。以简单的线性分类器为例,将这三种特征结合起来的分类算法为:
If 0.5*red + 0.3*green + 0.2*blue > 0.6 : return cat;
else return dog;
然而,将这三种颜色作为特征来区分猫狗明显是不够的。为此,我们决定增加一些特征,比如x、y轴方向上的梯度dx、dy,那么现在就有5个特征了。
为了得到更精确的分类器,基于颜色和、纹理、统计动差等,我们还需要更多的特征。通过将特征增加到好几百,我们能得到一个完美的分类器吗?回答可能会出乎你们的意料:不能!事实上,过了某个临界点,如果还持续的增加特征,那么分类器的性能会下降。看图1,这就是我们经常说的“维度灾难curse of dimension”。
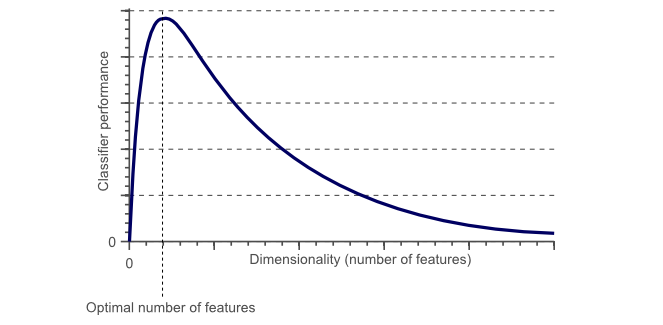
维度灾难和过拟合的关系:
假设在地球上有无数只猫和狗,但由于种种原因,我们总共只有10张描述猫狗的图片。我们的最终目的是利用这10张图片训练出一个很牛的分类器,它能准确的识别我们没见过的各种无数的猫、狗。
如果只使用一维特征,例如红色进行训练,在一维特征轴上展开

我们可以发现,分类效果并不好,因此我们准备再加入一个图像平均绿色的特征。

在红绿构成的二维特征空间中,我们发现还是没法找到一条线将他们分开。我们准备再加一个特征,把空间拓展到3维。
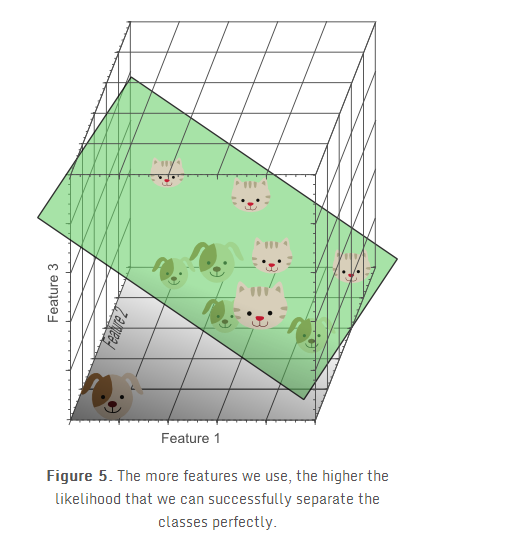
终于我们找到了一个平面可以将10个样本完美的分开。
从这个例子我们好像可以看出,分类器的效果随着特征维度的增加变得更好了,我们应该不停的增加特征维度直到分类器获得最好的结果为止,但是我们在上文论述过,从图1可以看出,实际上这是有问题的。
在1特征空间为1维时(如图2),10个训练实例覆盖在一维轴上,假设轴长为5,那么每个样本平均每个单位有2个样本。特征空间为2维时(如图3),我们仍然用10个实例进行训练,此时二维空间的面积是5x5=25,样本密度是10/25=0.4,即每个单位面积有0.4个样本。在特征空间为3维时,10个样本的密度是10/(5x5x5)=0.08,即每个单位体积有0.08个样本。
如果我们不断的增加特征,特征维度就会不断变大,同时变得越来越稀疏。由于稀疏的原因,随着特征维度的不断变大,我们很容易的就找到一个能将样本按类别完美分开的超平面,因为训练样本落到该空间的最优超平面错误一边的概率会随着维度增加无限变小。然而,如果将高维分类映射回低维,我们能很容易发现一个严重的问题:
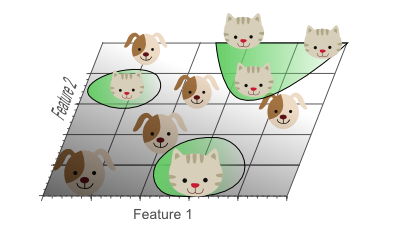
图6:使用太多的特征导致了过拟合。分类器学习了很多异常特征(如噪声等),因此对于新的数据泛化性能不好。
图6展示了3D分类结果投影到2D空间中的情景,我们可以看不像高维空间中,在低维空间中,数据并没有显示出可分性。而实际上,通过增加第三维度来获得最优分类效果等价于在低维空间使用复杂的非线性分类器,而往往复杂的模型结构也是导致过拟合的原因之一。结果就是分类器学习到了很多数据集中的特例,因此对于现实数据往往会效果较差,因为现实数据是没有这些噪声以及异常特性的。
因此说,过拟合是维度灾难带来的最直接结果。

图7展示了使用2个特征的线性分类器的训练结果,尽管这个分类边界看起来不如图5中的分类器,但是简单的分类器对于未知的数据具有更好的泛化性能,因为其不会学习到训练集中偶然出现的特例。换句话说,维度灾难可以通过使用更少的特征来避免,同时这样分类器就不会对训练数据过拟合。
下面从另一个角度来阐述,我们假设每个特征的范围是从0-1,同时每个猫和狗都具有不同的特征。如果我们想使用全数据的20%的数据来训练模型,那么在一维的情况下,我们的特征范围只需要取20%的范围,也就是0.2就够了。当上升到2维的情况下,我们需要45%的每维特征(0.45*0.45=0.2)才可以覆盖特征空间中的20%,当上升到3维空间时,我们则需要每维58%的特征范围(0.58^3 = 0.2)。
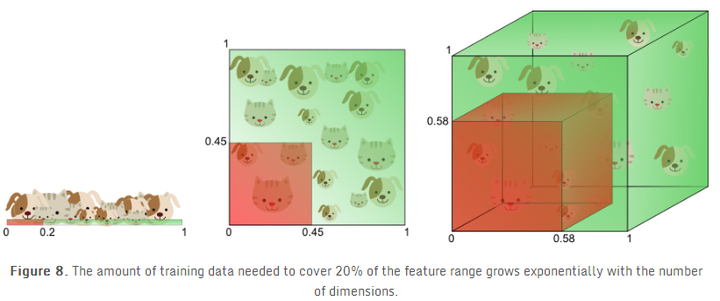
换句话说,如果特征数目一定,那么随着维度增加过拟合就会出现。另一方面,如果持续增加维度,那么训练数据需要指数级的增加才能保持同样的距离分布来避免过拟合。
举个例子:例如在一维空间中,样本密度是1000个/单位,那么我们在任意测试样本0.001的单位距离都可以找到一个样本。但是如果到2维空间,那么我们需要1000^2个样本才能保证,任意样本的0.001单位距离内都有一个样本。
换个角度来看,如果我们吧100个点丢到0-1的区间内,并且吧0-1分成每个0.1一共10个区间,那么极有可能每个区间都会有点存在,但是如果还是100个点丢到2维空间内,那么边长为0.1的单位单元就有100个,几乎不可能每个单元都有一个点。当拓展到3维就有1000个单元,ur data is “lost in space” as we go to higher dimensions.这就是数据的稀疏性。
在上面的例子中,我们通过演示数据的稀疏性展示了维数灾难,即:在分类中我们使用的特征数量越多,那么由于高维下数据的稀疏性我们不得不需要更多的训练数据来对分类器的参数进行估计(高维数下分类器参数的估计将变得更加困难)。维数灾难造成的另外一个影响是:数据的稀疏性致使数据的分布在空间上是不同(实际上,数据在高维空间的中心比在边缘区域具备更大的稀疏性,数据更倾向于分布在空间的边缘区域)。举个栗子更好理解:
假设一个二维的单位正方形代表了2维空间,特征的平均值作为特征空间的中点,所有距离特征空间单位距离内得点都在一个特征空间的内接圆内,而在内接圆外的点则分布在空间的角落,他们相对来说更难被区分,因为他们的特征差距很大。因此单位圆内的样本越多,那么分类任务就越简单:

在这里一个有趣的问题就是随着维度的增长,超球体所占的空间和超立方体的空间的相对比例是如何变化的。超立方体的体积在维度d的情况下永远是1^d=1,超球题的体积在半径为0.5的情况下可以由以下公式计算:
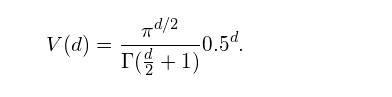
其体积-维度图画出来大概是这样的:
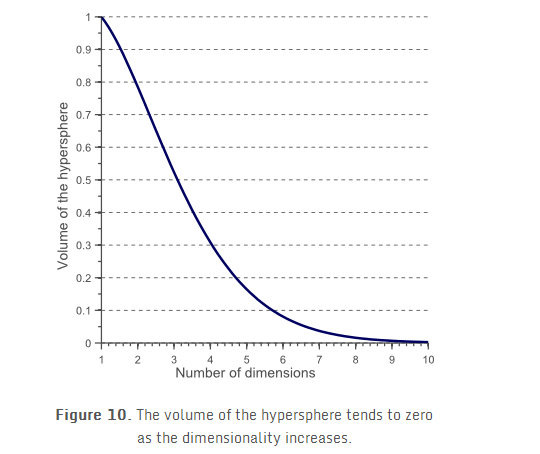
我们可以明显的发现,当维度不断增大,内接球的体积会趋于0,而超立方体的体积还是1,这种反直觉的发现解释了分类器维度灾难的相关问题:在高维空间中,大部分训练数据都位于定义的特征空间立方体的拐角处。正如前面提到的,样例在拐角处比样例在内接球体内是更难分类的。图11更明显的展示了这一点:
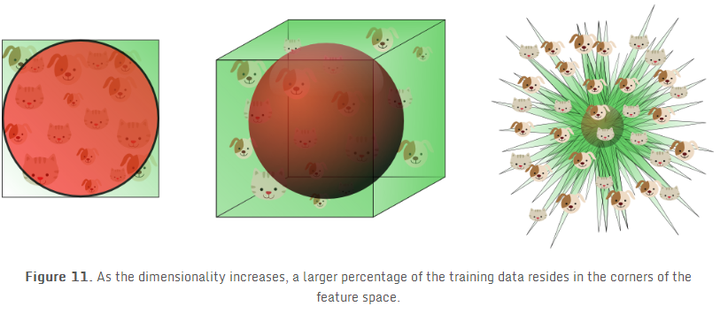
对于8维的超立方体,大概有98%的数据位于它的256个拐角处。当维度趋近于无穷大时,样本点到中心点的欧式距离的最大值和最小值的差值与最小值的比例趋近于0,:
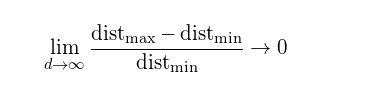
因此,在某种意义上,几乎所有的高维空间都远离其中心,或者从另一个角度来看,高维单元空间可以说是几乎完全由超立方体的“边角”所组成的,没有“中部”,这对于理解卡方分布是很重要的直觉理解。 给定一个单一分布,由于其最小值和最大值与最小值相比收敛于0,因此,其最小值和最大值的距离变得不可辨别。
因此,在高维空间用距离来衡量样本相似性的方法已经渐渐失效。所以以距离为标准的分类算法(欧氏距离,曼哈顿距离,马氏距离)在低维空间会有更好的表现。类似的,高斯分布在高维空间会变得更加平坦,而且尾巴也会更长。
对于使用距离测度的机器学习算法的影响:
由于维度灾难的影响,正如前面所说的在高维空间中,欧式距离的测度会失去意义,当维度趋于无穷时,数据集中任意两点的距离会趋向收敛,意思是任意两点的最大距离和最小距离会变为相同。
因此基于欧式距离的k-means算法,会无法进行聚类(因为距离会趋于收敛)。而K-NN会的临近K个点中,会出现更多非同类的点(远多于低维度的情况)。
参考网页:
Curse of dimensionality
The Curse of Dimensionality in Classification














 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









