







出处:http://my.oschina.net/MrMichael/blog/220787
感谢您的文章
先介绍下查询与过滤的区别和联系,其实查询(各种Query)和过滤(各种Filter)之间非常相似,可以这样说只要用Query能完成的事,用过滤也都可以完成,它们之间可以相互转换,最大的区别就是使用过滤返回的结果集不带评分操作,而使用Query返回的结果都是带相关性评分的,所以当我们如果有一些跟评分操作没有关系的业务,优先使用Filter操作,将会获取更好的性能,其实这也是Solr里面的q参数跟fq参数的区别。
下面,开始进入正题,在这之前,老生常谈的先来了解一下Lucene里面有关于Filter的整体知识
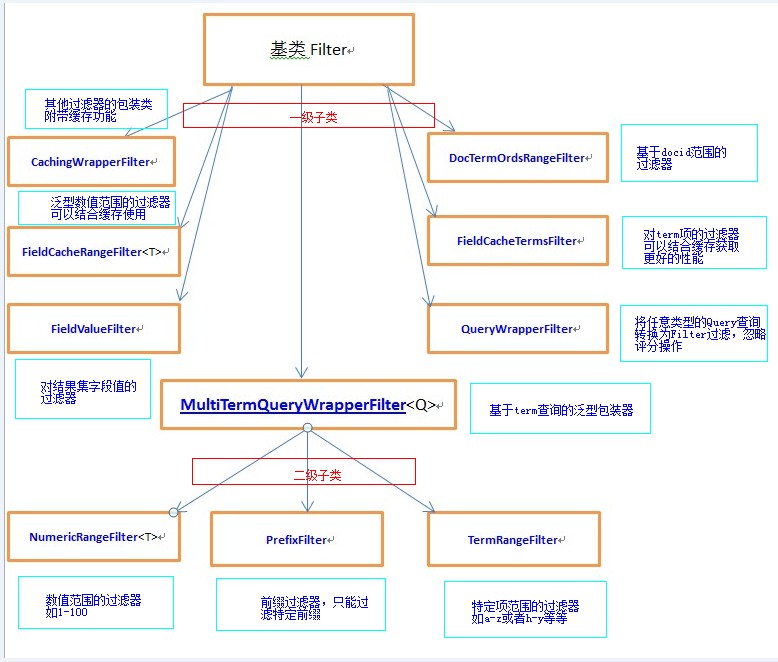
下面,我们来看下具体的在代码里怎么实现,先来看下我们的测试数据
|
1
2
3
4
5
6
7
8
9
|
id score bookname ename type price date
1
1
飘渺之旅 pmzl 小说 52.23
201005
2
1
三国演义 sgyy 小说 36.13
201207
3
1
数据库实战 sjksz 技术 77.13
200811
4
1
编程宝典 bcbd 技术 100.3
200501
5
1
职场关系论 zcgxl 职场 36.59
200501
6
1
健康生活 jksh 生活 20.47
200008
7
1
看清本质 kqbz 社会 10.37
201004
8
1
编程,编程 bcbc 社会 10.37
201004
|
核心代码
|
1
2
3
4
|
//使用过滤器 最后一个为true时包含边界部分,为false时不包含边界部分
//倒数第二个为true时,包含查询边界,为false时不包含
TermRangeFilter filter=new
TermRangeFilter("ename", new
BytesRef("h"), new
BytesRef("n"), true, true);
TopDocs topDocs=searcher.search(new
MatchAllDocsQuery(),filter,10000);//默认无排序方式
|
输出结果
|
1
2
|
6
1
健康生活 jksh 生活 20.47
200008
7
1
看清本质 kqbz 社会 10.37
201004
|
核心代码
|
1
2
|
NumericRangeFilter<Double> filter=NumericRangeFilter.newDoubleRange("price", 10D, 40D, true, false);
TopDocs topDocs=searcher.search(new
MatchAllDocsQuery(),filter,10000);//默认无排序方式
|
输出结果
|
1
2
3
4
5
|
2
1
三国演义 sgyy 小说 36.13
201207
5
1
职场关系论 zcgxl 职场 36.59
200501
6
1
健康生活 jksh 生活 20.47
200008
7
1
看清本质 kqbz 社会 10.37
201004
8
1
编程,编程 bcbc 社会 10.37
201004
|
核心代码
|
1
2
3
|
//使用缓存过滤
Filter filter=FieldCacheRangeFilter.newDoubleRange("price", 20D, 50D, true, true);
TopDocs topDocs=searcher.search(new
MatchAllDocsQuery(),filter,10000);//默认无排序方式
|
输出结果
|
1
2
3
|
2
1
三国演义 sgyy 小说 36.13
201207
5
1
职场关系论 zcgxl 职场 36.59
200501
6
1
健康生活 jksh 生活 20.47
200008
|
核心代码
|
1
2
3
|
// 缓存域过滤特定的类别
Filter filter=new
FieldCacheTermsFilter("type", new
String[]{"技术","社会"});
TopDocs topDocs=searcher.search(new
MatchAllDocsQuery(),filter,10000);//默认无排序方式
|
输出结果
|
1
2
3
4
|
3
1
数据库实战 sjksz 技术 77.13
200811
4
1
编程宝典 bcbd 技术 100.3
200501
7
1
看清本质 kqbz 社会 10.37
201004
8
1
编程,编程 bcbc 社会 10.37
201004
|
核心代码
|
1
2
3
|
//使用QueryWrapperFilter类包装一个Query
QueryWrapperFilter filter=new
QueryWrapperFilter(new
TermQuery(new
Term("type", "技术")));
TopDocs topDocs=searcher.search(new
MatchAllDocsQuery(),filter,10000);//默认无排序方式
|
输出结果
|
1
2
|
3
1
数据库实战 sjksz 技术 77.13
200811
4
1
编程宝典 bcbd 技术 100.3
200501
|
最后我来看下,如何继承Filter基类,来定制我们自己的filter,自定义的Filter,虽然某些时候,功能很强大灵活,但是有几个缺点,我们的了解1,保证是内容不重复的字段,例如主键,如果重复,默认返回第一个作为结果集显示2,保证不能被分词的内容,如果是分词的字段,则可能会出现一些不正确的结果。
自定义Filter类
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
package
com.sanjiesanxian.test;
import
java.io.IOException;
import
java.util.BitSet;
import
org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import
org.apache.lucene.index.AtomicReaderContext;
import
org.apache.lucene.index.DocsEnum;
import
org.apache.lucene.index.Term;
import
org.apache.lucene.search.DocIdSet;
import
org.apache.lucene.search.Filter;
import
org.apache.lucene.util.AttributeSource;
import
org.apache.lucene.util.Bits;
import
org.apache.lucene.util.DocIdBitSet;
import
org.apache.lucene.util.FixedBitSet;
import
org.apache.lucene.util.OpenBitSet;
/***
*^_^ ^_^ ^_^
* QQ交流探讨群:324714439
* 自定义过滤器
* @author 三劫散仙
* */
public
class
MyCustomFilter extends
Filter{
public
MyCustomFilter() {
// TODO Auto-generated constructor stub
}
private
String[] terms;//限制返回的数据字典
public
MyCustomFilter(String ...terms) {
// TODO Auto-generated constructor stub
this.terms=terms;
}
@Override
public
DocIdSet getDocIdSet(AtomicReaderContext arg0, Bits arg1)
throws
IOException {
FixedBitSet bits=new
FixedBitSet(arg0.reader().maxDoc()) ;//获取没有所有的docid包括未删除的
int
base=arg0.docBase;//段的相对基数,保证多个段时相对位置正确
//int limit=base+arg0.reader().maxDoc();//计算最大限制值
for(String s:terms){
DocsEnum doc=arg0.reader().termDocsEnum(new
Term("id", s));//必须是唯一的不重复
//保证是单个不重复的term,如果重复的话,默认会取第一个作为返回结果集,分词后的term也不适用自定义term
if(doc.nextDoc()!=-1){
bits.set(doc.docID());//对付符合条件约束的docid循环添加到bits里面
}
}
return
bits;
}
}
|
测试查询代码
|
1
2
|
MyCustomFilter filter=new
MyCustomFilter("3","5","2");//随意指定1之多个需要过滤的项
TopDocs topDocs=searcher.search(new
MatchAllDocsQuery(),filter,10000);
|
输出结果
|
1
2
3
|
2
1
三国演义 sgyy 小说 36.13
201207
3
1
数据库实战 sjksz 技术 77.13
200811
5
1
职场关系论 zcgxl 职场 36.59
200501
|
自定义过滤器虽然有缺点,但是某些场景下却能发挥很灵活的作用,特别是对没有分词的字段进行过滤操作。















 186
186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









