







MapReduce时内存溢出,报如下图错误,
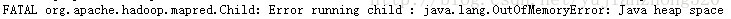
通过修改配置文件mapred-site.xml,增加如下属性,默认是200M,提高到400M,不用重启Hadoop集群。
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx400m</value>
</property>
Map和Reduce任务运行时Java虚拟机指定的内存的大小,默认-Xmx200m,分配给每个任务200MB内存
应该也可以通过代码设置,采用代码设置就针对本个Job起作用
conf.set("mapred.child.java.opts", "-Xmx400m");
Task任务超时,报 failed to report status for 600 seconds. Killing!
控制超时的属性是:mapred.task.timeout,默认600000ms,即600s。
修改配置文件mapred-site.xml 对所有Job起作用
也可以直接设置,设置为0时,不超时。对本个Job起作用
conf.set("mapred.task.timeout", "0");















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









