







开篇
近日,阿里云机器学习PAI平台关于图神经网络统一高性能IR的论文《uGrapher》被系统领域顶会ASPLOS 2023接收。
为了解决当前图神经网络中框架中不同的图算子在不同图数据上静态kernel的性能问题,uGrapher通过将所有图算子抽象为统一的中间表达形式,解耦图算子的计算和调度,并定义了在GPU上优化图算子的设计空间,以针动态变化的图算子和图数据自适应的生成并行执行策略,为图神经网络中的图算子提供高性能的计算支持。对比DGL [1], PyG[2], GNNAdvisor[3],uGrapher平均可以取得3.5倍的性能提升。
背景
近年来,图神经网络(Graph Neural Networks, GNNs)因其在非欧几里德空间中对图结构进行学习和推断的强大能力而受到学术界和产业界的广泛关注。GNNs将基于DNN的特征变换和基于图的操作结合起来,沿着图结构传播和聚合信息。现有的GNN框架如DGL和PyTorch-Geometric(PyG)扩展了DNN 框架(如TensorFlow 和PyTorch),并引入了“消息”这一概念,它是与每个边相关联的特征向量的中间值。对于图
上的任何操作,可以根据数据的属性和数据移动的方向分为三个阶段,即消息创建、消息聚合和特征更新,公式化如下图:
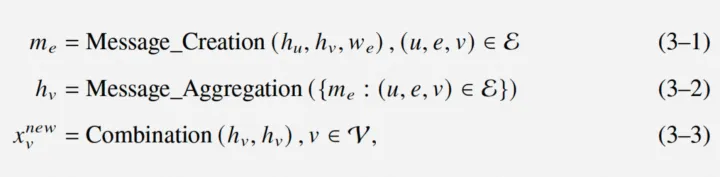
其中,
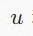
和
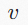
是顶点索引,
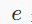
是

和
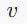
之间的边索引;
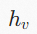
是顶点
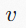
的特征向量,
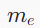
是边
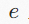
上的消息。
uGrapher将需要遍历输入图结构的操作符定义为图算子。图算子包括“消息创建”、“消息聚合”和“融合聚合”三类。其中,“融合聚合”是指当“消息创建”是一个简单的复制操作时,它可以与“消息聚合”融合在一起,以避免冗余访问,DGL和PyG采用了这种融合优化。
以GAT模型为例,它包含几个具有不同计算模式的图操作符。第一个“消息创建”操作非常轻量级,它将每个边的源顶点和目标顶点的特征相加作为消息以计算注意力权重;第二个“融合聚合”操作首先从源顶点复制特征,然后逐边乘注意力权重,最后将变换后的边上的消息聚合为顶点的新特征。第二个操作比第一个操作更加计算密集。
由于图结构引起的不规则内存行为,再加上这些图算子中复杂的算术计算,图神经网络中图算子的高性能计算成为重要挑战。
现有的图神经网络框架依靠手写静态kernel来实现图算子的计算。然而,随着图神经网络算法演进,图算子的可变性和复杂性不断增加,其计算也变得更加复杂;同时,不同分布的图数据作为输入也给图神经网络的计算带来了特有的复杂性,这导致静态算子难以维持较好的性能。因此,本文探索了如何在变化的图数据和图模型上进行图算子的计算优化。
挑战
(1)图神经网络引入了图算子的复杂性和图数据的变化性两大特征,导致了图算子计算优化上的难题。
下表根据输入和输出数据类型将DGL支持的160个图操作符进行了分类。即使具有相同的输入或者输出数据类型,图算子也可以执行不同的计算模式。图算子的复杂性导致很难找到静态的方式为所有图算子的计算操作提供高性能支持。
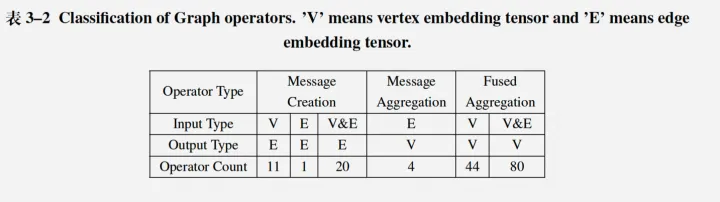
真实世界中的图数据集有很大的差异。图的规模,即顶点和边的数量,图的平衡程度,即邻接矩阵行的非零值的标准差,以及特征和类大小,这些属性在不同的图之间有显著的差异。而这些差异影响了图算子的内存使用和计算复杂性。
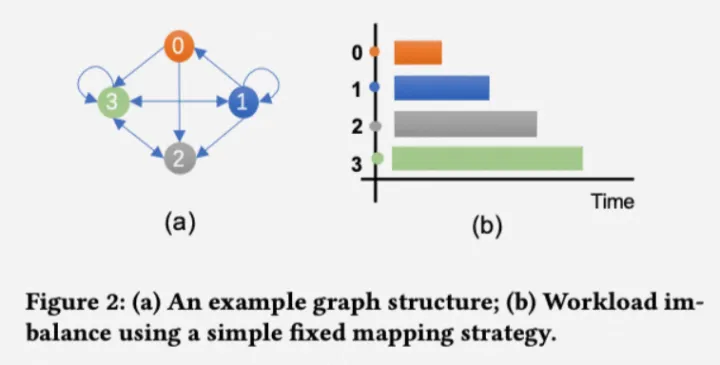
(2)由于缺乏系统优化方法,现有GNN框架使用的底层CUDA kernel存在低效和缺乏灵活性的问题。
DGL 在支持上文中的消息传递编程接口时调用静态CUDA kernel,这些静态kernel不能适应变化的计算场景。比如,在执行不平衡图时,GPU 的低占用率导致了硬件资源的浪费。当执行小图时,GPU 性能通常受到并行性的限制,而执行大图时,由于低局部性,访问带宽成为瓶颈。同时,这些指标在不同图算子之间也会有所差异。
破局
uGrapher使用嵌套循环作为图算子的调度表达,并允许用户定制输入张量和不同阶段的函数操作来表示不同的图算子运算。
下图为面向图神经网络中的图算子统一的抽象细节。

edge_op实现了边上的访存和计算的函数表示,而gather_op实现了边到顶点的合并函数表示。另外还有三个输入张量,可以为源顶点嵌入张量(Src_V),目的地顶点嵌入张量(Dst_V),边嵌入张量(Edge),以及NULL的任意一种。 张量的数据类型还确定了循环计算中不同的寻址模式(第10 至12 行)。
下面的公式正式定义了uGrapher的统一抽象,其中,
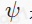
是edge_op 函数,

是gather_op 函数。该抽象捕捉了图算子的完整语义,包括其计算和内存移动模式。
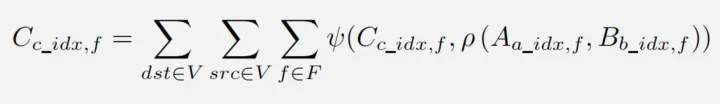
根据图算子统一的抽象,uGrapher构建了算子优化的设计空间,以实现高性能的图算子执行。
uGrapher使用局部性、并行性和工作效率来描述GPU上图算子性能的指标。对嵌套循环应用tiling 或者blocking 技术可以提高图算子的局部性;通过启动更多的线程、warp 或线程块可以提高图算子的并行性;工作效率用额外开销的倒数表示,同一运算符的不同执行策略可能会引入额外的计算,例如地址计算等,共享顶点的边并行计算可能需要原子指令。
现有图处理系统中有两种经典并行化策略:线程-顶点和线程-边并行。前者降低了并行性,但提高了输出数据的重用性和局部性。后者降低了工作效率,因为可能需要原子更新操作。
由于GNN 中的顶点/边特征是向量,GNN增加了特征维度的并行化策略,为warp-顶点和warp-边,相对线程-顶点/边策略,可以启动更多的warp,从而增加并行性。然而,由于每个warp 的缓存容量减少,这个策略也会损害局部性。
因此,没有一种单一的策略可以同时提高这三个指标,uGrapher通过上述统一的IR表达,设计了统一的高性能计算接口,来探索优化空间,进行性能的权衡。整体架构如下图所示。
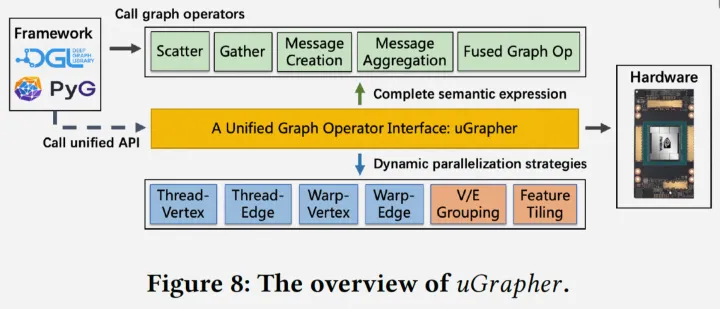
uGrapher提供的图算子统一高性能计算接口设计如下图所示。

uGrapher 接口包含三个参数:graph_tensor,表示图数据;op_info,用于传递edge_op、gather_op 和输入张量的计算信息;parallel_info,用于指定并行化策略。
uGrapher 的接口设计将算子计算、图数据和并行化策略分离,使得用户可以通过手动,或者针对不同的算子和图结构提出自己的启发式算法来选择执行策略。同时,当用户未指定任何并行化策略时,uGrapher会利用LightGBM[4]训练决策模型,选择并行化空间中的最优策略来自动调整到最佳并行化策略,以在不同的GPU架构和图数据集上为所有图神经网络中的图算子提供专门和最优的计算调度。uGrapher实现了每种并行化策略的CUDA 内核模板,并为每种图算子保留设备函数接口,并实现了端到端的代码生成,包含了算子合并和设备函数生成,以支持灵活和高效的算在实现。更多的细节请阅读我们ASPLOS 2023的论文。
目前,我们正在将uGrapher的关键设计集成进PAI自研的大规模图神经网络框架GraphLearn中,从而为工业级别的图神经网络应用带来性能加速。
第五板块:
论文名字:
uGrapher: High-Performance Graph Operator Computation via Unified Abstraction for Graph Neural Networks
论文作者:
周杨杰,冷静文,宋曜旭,卢淑文,王勉, 李超,过敏意, 沈雯婷,李永,林伟,刘湘雯,吴翰清
论文pdf链接:
https://dl.acm.org/doi/10.1145/3575693.3575723
参考文献:
[1] M. Wang, D. Zheng, Z. Ye, Q. Gan, M. Li, X. Song, J. Zhou, C. Ma, L. Yu, Y. Gai et al., “Deep graph library: A graph-centric, highly-performant package for graph neural networks,” arXiv preprint arXiv:1909.01315, 2019.
[2] M. Fey and J. E. Lenssen, “Fast graph representation learning with pytorch geometric,” arXiv preprint arXiv:1903.02428, 2019.
[3] Y. Wang, B. Feng, G. Li, S. Li, L. Deng, Y. Xie, and Y. Ding, “GNNAdvisor: An adaptive and efficient runtime system for GNN acceleration on GPUs,” in 15th USENIX Symposium on Operating Systems Design and Implementation (OSDI 21), 2021, pp. 515–531.
[4] Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. 2017. Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems 30 (2017).
作者:周杨杰、沈雯婷
本文为阿里云原创内容,未经允许不得转载。















 447
447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









