






背景
Relational Cache是EMR Spark支持的一个重要特性,主要通过对数据进行预组织和预计算加速数据分析,提供了类似传统数据仓库物化视图的功能。除了用于提升数据处理速度,Relational Cache还可以应用于其他很多场景,本文主要介绍如何使用Relational Cache跨集群同步数据表。
通过统一的Data Lake管理所有数据是许多公司追求的目标,但是在现实中,由于多个数据中心,不同网络Region,甚至不同部门的存在,不可避免的会存在多个不同的大数据集群,不同集群的数据同步需求普遍存在,此外,集群迁移,搬站涉及到的新老数据同步也是一个常见的问题。数据同步的工作通常是一个比较痛苦的过程,迁移工具的开发,增量数据处理,读写的同步,后续的数据比对等等,需要很多的定制开发和人工介入。基于Relational Cache,用户可以简化这部分的工作,以较小的代价实现跨集群的数据同步。
下面我们以具体示例展示如何通过EMR Spark Relational Cache实现跨集群的数据同步。
使用Relational Cache同步数据
假设我们有A,B两个集群,需要把activity_log表的数据从集群A同步到集群B中,且在整个过程中,会持续有新的数据插入到activity_log表中,A集群中activity_log的建表语句如下:
CREATE TABLE activity_log (
user_id STRING,
act_type STRING,
module_id INT,
d_year INT)
USING JSON
PARTITIONED BY (d_year)
插入两条信息代表历史信息:
INSERT INTO TABLE activity_log PARTITION (d_year = 2017) VALUES("user_001", "NOTIFICATION", 10), ("user_101", "SCAN", 2)
为activity_log表建一个Relational Cache:
CACHE TABLE activity_log_sync
REFRESH ON COMMIT
DISABLE REWRITE
USING JSON
PARTITIONED BY (d_year)
LOCATION "hdfs://192.168.1.36:9000/user/hive/data/activity_log"
AS SELECT user_id, act_type, module_id, d_year FROM activity_log
REFRESH ON COMMIT表示当源表数据发生更新时,自动更新cache数据。通过LOCATION可以指定cache的数据的存储地址,我们把cache的地址指向B集群的HDFS从而实现数据从集群A到集群B的同步。此外Cache的字段和Partition信息均与源表保持一致。
在集群B中,我们也创建一个activity_log表,创建语句如下:
CREATE TABLE activity_log (
user_id STRING,
act_type STRING,
module_id INT,
d_year INT)
USING JSON
PARTITIONED BY (d_year)
LOCATION "hdfs:///user/hive/data/activity_log"
执行MSCK REPAIR TABLE activity_log自动修复相关meta信息,然后执行查询语句,可以看到在集群B中,已经能够查到之前集群A的表中插入的两条数据。
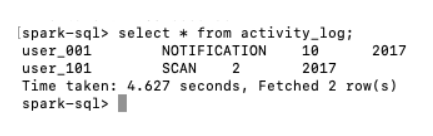
在集群A中继续插入新的数据:
INSERT INTO TABLE activity_log PARTITION (d_year = 2018) VALUES("user_011", "SUBCRIBE", 24);
然后在集群B中执行MSCK REPAIR TABLE activity_log并再次查询activity_log表,可以发现数据已经自动同步到集群B的activity_log表中,对于分区表,当有新的分区数据加入时,Relational Cache可以增量的同步新的分区数据,而不是重新同步全部数据。
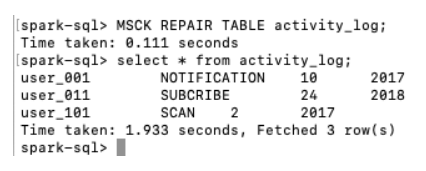
如果集群A中activity_log的新增数据不是通过Spark插入的,而是通过Hive或其他方式外部导入到Hive表中,用户可以通过REFRESH TABLE activity_log_sync语句手工或通过脚本触发同步数据,如果新增数据是按照分区批量导入,还可以通过类似REFRESH TABLE activity_log_sync WITH TABLE activity_log PARTITION (d_year=2018)语句增量同步分区数据。
Relational Cache可以保证集群A和集群B中activity_log表的数据一致性,依赖activity_log表的下游任务或应用可以随时切换到集群B,同时用户也可以随时将写入数据到集群A中activity_log表的应用或服务暂停,指向集群B中的activity_log表并重启服务,从而完成上层应用或服务的迁移。完成后清理集群A中的activity_log和activity_log_sync即可。
总结
本文介绍了如何通过Relational Cache在不同大数据集群的数据表之间同步数据,非常简单便捷。除此之外,Relational Cache也可以应用到很多其他的场景中,比如构建秒级响应的OLAP平台,交互式的BI,Dashboard应用,加速ETL过程等等,之后我们也会和大家分享在更多场景中Relational Cache的最佳实践。
原文链接
本文为云栖社区原创内容,未经允许不得转载。















 306
306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









