







计算机视觉:模型、学习和原理
本博文乃自学为主,转载需要声明,并且我也不知道能坚持编写多久,故而尽力为之,最近进行计算机视觉的学习的研究生阶段,时间上委实不多。
学习的书采用了《计算机视觉:模型、学习和推理》,这本书的英文名为《Computer vision:models, learning and inference》,是一本不错的教材,但是可惜的是在习题上有点困难,就是没有提供自学者完整的答案,故而很是可惜。另外,所介绍的数学部分,相对有些难度,而且说明不是很详细和清楚,我的目的是通过博客进行学习,学习的过程中,加上一些自己的理解,而且我会适当加和减一些内容,还有就是本书一些配套的习题,想自己试着写写,如果有不对的地方,欢迎提出来让我进行修改。
绪论
什么是计算机视觉?
计算机视觉是一门用计算机模拟生物视觉的学说,简而言之,让计算机代替人眼实现对目标的识别、分类、跟踪和场景理解。
为此有人提出一个疑虑,就算机器视觉和计算机视觉,两者是否是同一个概念。现在不纠结这个问题,而是说明在《计算机视觉:模型、学习和推理》中,尤其是绪论第一段说到,The goal of computer vision is to extract useful information from images. This has proved a surprisingly challenging task; it has occupied thousands of intelligent and creative minds over the last four decades, and despite this we are still far from being able to build a general-purpose ”seeing machine”.我觉得中文翻译得不对,computer vision,应该翻译为计算机视觉而不是机器视觉。所以我觉得应该翻译为,计算机视觉旨在从图形中提取有用的消息,已被证实是一个极具挑战性的任务。在过去四十年里,成千上万智慧和创造性的思维致力于这一任务,尽管如此,我们还远远没有能够建立一个通用的“视觉机器”
计算机视觉和机器视觉
计算机视觉(computer vision)和机器视觉(machine vision)在很多文献没有区分,但是这个两个术语是有区别又有联系。
计算机视觉是采用图像处理、模式识别、人工智能技术相结合的手段,着重与一幅或多幅图像的计算机分析。图像可以由单个或者多个传感器获取,也可以是单个传感器在不同时刻获取的图像序列。分析是对目标物体的识别,确定目标物体的位置和姿态,对三维景物进行符号描述和解释。在计算机视觉的研究中,经常使用几何模型、复杂的知识表达,采用基于模型的匹配和搜索技术,搜索的策略常使用自底向上、自顶向下、分层和启发式控制策略。
机器视觉偏重于计算机视觉技术工程化,能够自动获取和分析特定图像,以控制相应的行为。
两者的联系在于,计算机视觉为机器视觉提供图像和景物分析的理论及算法基础,机器视觉为计算机视觉的实现提供传感器模型、系统构造和实现手段。
因此可以认为,一个机器视觉系统就是一个能自动获取一幅或多幅目标物体图像,对所获取图像的各种特征量进行处理、分析和测量,并对测量结果做出定性分析和定量解释,从而得到有关目标物体的某种认识并做出相应决策的系统。机器视觉系统的功能包括:物体定位、特征检测、缺陷判断、目标识别、计数和运动跟踪。
下面给出个图,是从维基百科搬来的。
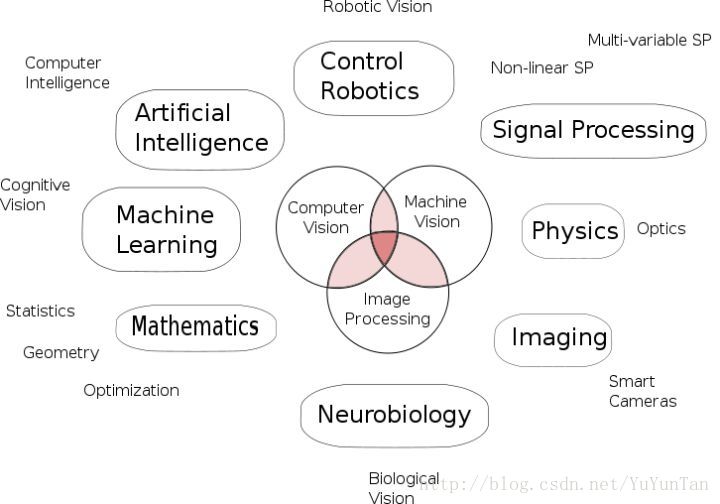
维基认为,计算机视觉的研究对象主要是映射到单幅或多幅图像上的三维场景,例如三维场景的重建。计算机视觉的研究很大程度上针对图像的内容。而机器视觉主要是指工业领域的视觉研究,例如自主机器人的视觉,用于检测和测量的视觉。这表明在这一领域通过软件硬件,图像感知与控制理论往往与图像处理得到紧密结合来实现高效的机器人控制或各种实时操作。
总结来说,计算机视觉和机器视觉是有区别而且又有联系。两者用于地方不同,有交叉点。所学的书是以计算机视觉为主。
绪论内容继续讲解
回归主要内容,前面说过,本书绪论说,我们远远没有能够建立一个通用的“视觉机器”,那么这个原因是什么导致的?是可视视觉的复杂性所导致。
考虑到下面一幅图像(图1),场景中有数百物体。这些物体没有呈现出“特定”的姿态,几乎所有物体都被部分遮挡。对于一个计算机视觉算法,很难确定某个物体的结束和另一个物体的开始。比如,背景中天空和白色建筑物之间的边界上,图像在亮度上几乎没有变化。然而,即使没有物体的边界或材质的变化,前景中SUV后窗上的亮度也有明显的亮度。
若非这是一件事情:我们有具体的证据去证明计算机视觉是可研究的,因为我们自己的视觉系统能够毫不费力地处理复杂的图像,如图1所示,恐怕我们可能已经对开发有用的计算机视觉算法的可能性感到沮丧。如果要求你统计该图像中的树的总数或绘制街道布局的草图,你很容易做到这点。甚至于你可能通过提取微妙的视觉线索,比如人的种族、车和树的种类以及天气等,找出这张照片是在世界上哪个位置拍的。

图1:一个视觉场景包含许多物体,而几乎所有物体都是部分遮挡的。红圈所示场景中几乎没有亮度的变化指示天空和建筑之间的边界。绿圈所示区域中有很大的亮度变化而这实际上跟亮度没关系,这里没有物体边界或物体材质的变化。
可以得出结论,研究计算机视觉并非不可能,只是它具有挑战性。计算机视觉领域取得了长足进步,并在个人消费领域首次大规模部署,比如大多数数码相机已经嵌入人脸检测算法。那么计算机视觉迅速发展的原因,最明显的是计算机的处理能力、内存以及存储能力有巨大的提升。另一个原因是机器学习的广泛应用。机器学习提供许多有用的工具,有助于以新的视角理解已知算法及联系。
计算机视觉简史
计算机视觉过去30年主要发展如下图所示(图2)
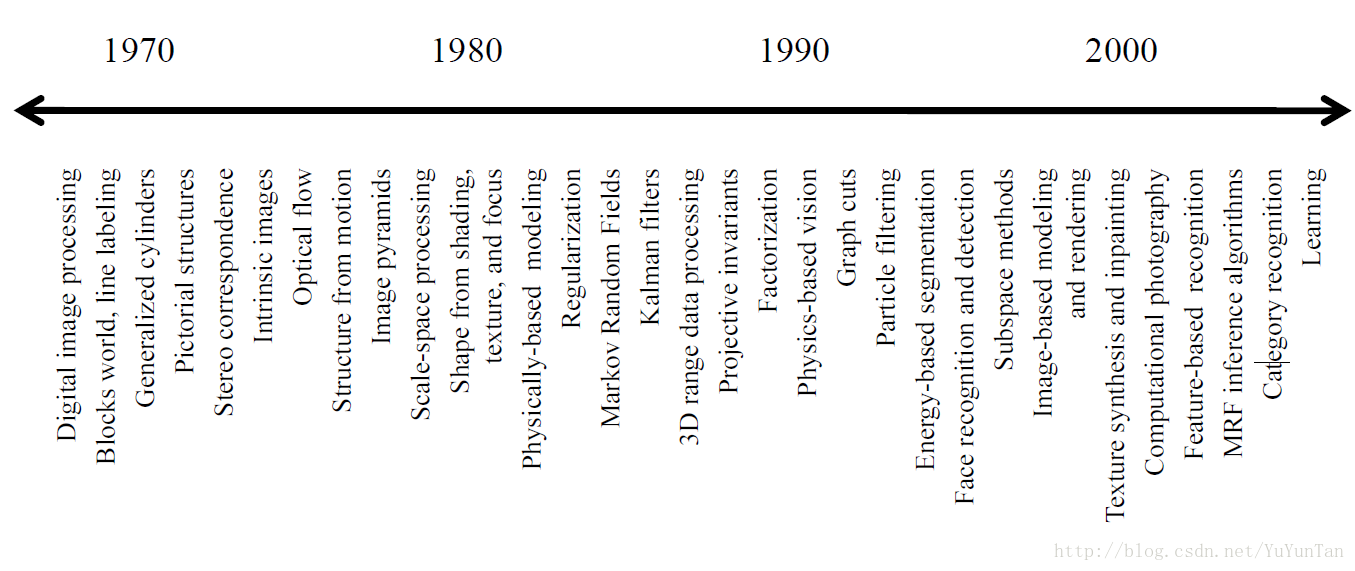
图2:从左到右依次是:(1)数字图像处理,(2)积木世界,线条标注,(3)广义圆锥,(4)图案结构,(5)立体视觉对应,(6)本征图像,(7)光流,(8)由运动到结构,(9)图像金字塔,(10)尺度空间处理,(11)由阴影,纹理,变焦到形状,(12)基于物理的建模,(13)正则化,(14)马尔科夫随机场(MRF),(15)卡尔曼滤波,(16)3D距离数据处理,(17)投影不变量,(18)因子分解,(19)基于物理的视觉,(20)图割,(21)粒子滤波,(22)基于能量的分割,(23)人脸识别和检测,(24)子空间方法,(25)基于图像的建模和绘制,(26)纹理合成与修图,(27)计算投影学,(28)基于特征的识别,(29)MRF推断算法,(30)类属识别,(31)学习
1958年加拿大科学家大卫•休伯尔和瑞典科学家托斯坦•维厄瑟尔对猫视觉皮层的研究,提出在计算机模式识别中,和生物识别类似,边缘是用来描述物体形状的最关键信息。1963年,美国计算机科学家拉里•罗伯茨在MIT博士毕业论文《Machine perception of Three-Dimensional Solids》,对输入图像进行梯度操作,进一步提取边缘,然后从3D模型中提取出简单形状结构,然后利用这些结构像搭积木一样去描述场景中无疑的关系,最后获得从另一角度看图像物体的渲染图。这篇论文中,从二维图像恢复图像中物体的三维模型的尝试,正是计算机视觉和传统图像处理学科思想上最大的不同:计算机视觉的目的是让计算机理解图像的内容。这项研究也就成了计算机视觉相关最早的研究。之后MIT人工智能实验室的明斯基发起了“暑期视觉项目”,目的是集中暑假的闲散劳动力解决计算机视觉问题,力争产出模式识别研发的里程碑式的结果。而广为人知的描述中,可以获知,当时明斯基只是让组里的一个学本科生杰拉德•杰伊•萨斯曼将摄像机连接在计算机上,尝试利用暑假的时间让计算机描述它所看到的东西,这个项目当时没有成功,但是计算机视觉作为一个专门的课题出现在了历史上。
将计算机视觉与已经存在的数字图像处理领域相区别的是期望从图像恢复世界的三维结构并以此为跳板得到完整场景理解。Winston(1975)和Hanson and Riseman(1978)提供了这个早期时代的两本较好的经典论文集。
场景理解的早期尝试涉及物体即“积木世界”的边缘提取及随后的从2D线条的拓扑结构推断其3D结构(Roberts 1965)。那是提出了一些线条标注算法(Huffman 1971;Clowes 1971;Waltz 1975;Rosenfeld,Hummel,and Zucker 1976;Kanade 1980)。那时边缘检测也是很活跃的研究领域。此外,人们还对非多边形物体的三维建模进行了研究,流行做法是使用了广义椎,即旋转体和封闭曲线扫描体。20世纪70年代一般是关于图像内容建模,如三维模型、立体视觉等。很有代表性的是弹簧模型和广义圆柱体模型。David Marr(戴维•马尔)(1982)《视觉计算理论》(Vision:A computational investigation into the human representation and processing of visual information)总结那个时代的视觉原理工作。他将视觉信息处理分为三个层次:计算理论、表达和算法和硬件实现。在如今看来,或许有些不合理,但是却将计算机视觉作为了一门正式学科的研究。而且其方法论到今天仍然是表达和解决问题的好向导。值得一提的是,1987年成立的ICCV(国际计算机视觉大会)给计算机视觉领域做出重要贡献的人颁发奖项,奖项名字叫马尔奖。
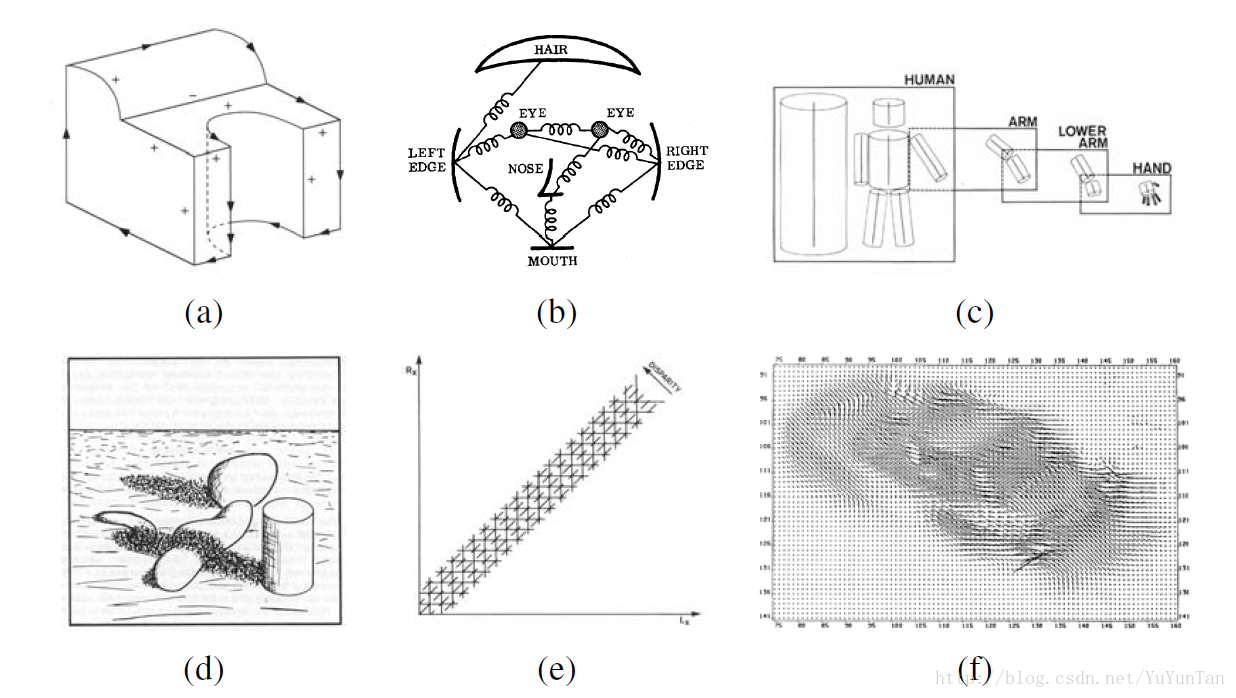
图3:计算机视觉算法早期例子:a)线条标注;b)图案结构;c)关节身体模型;d)本征图像;e)立体视觉对应;f)光流
视觉计算理论提出后,计算机视觉进入20世纪80年代,一个蓬勃发展的年代,提出了主动视觉理论和定性视觉理论等,这些理论认为人类视觉重建过程不是马尔理论那样直接,而是主动的,有目的性和选择性的。这个时期很多研究关注于定量的图像和场景分析的更复杂的数学方法。比如图像金字塔开始广泛应用于完成诸如图像混合这样的任务和由粗到精的对应搜索。使用尺度空间处理的概念也建立起了金字塔的连续版本,到了20世纪80年代后期,小波在一些应用中开始取代或增强规范的图像金字塔。这个时期还提出了Canny边缘检测算法,图像分割和立体视觉,基于人工神经网络的计算机视觉研究尤其是模式识别也在这时候火了起来。首先说说,立体视觉,这时期使用定量的形状线索使用的立体视觉扩展到由X到形状的各种各样的方法,包括由阴影到形状、光度测定学立体视觉、由纹理到形状以及由聚集到形状。其次说边缘和轮廓检测,这时期Canny边缘检测提出,还包括动态演化轮廓跟踪器的引入,比如蛇行。还有基于三维物理量的模型的引入。这时期的研究人员发现,很多立体视觉、流、由X到形状以及边缘检测算法,如果作为变分优化问题来处理,可以用相同的数学框架来统一或至少来描述,且可以使用正则化方法使其更鲁棒(适定的)。与此同时。German(1984)指出这类问题同样可以通过离散马尔科夫随机场模型(MRF)来很好地表达,这样就能使用更好的(全局)搜索和优化算法,比如“模拟退火”。之后出现了卡尔曼滤波来对不确定性进行建模和更新的MRF算法的在线变形。人们也尝试了将正则化及MRF算法映射到并行硬件。这个时期活跃的研究领域还包括了三维距离数据处理(获取、归并、建模和识别)。
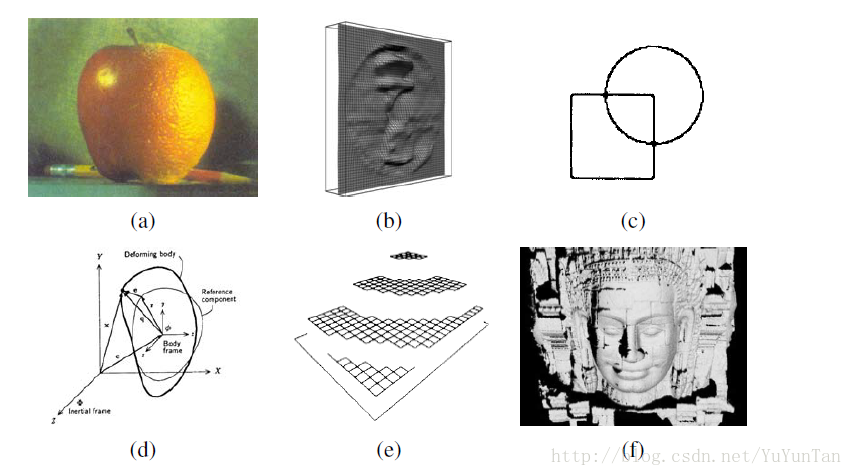
图4:20世纪80年代计算机视觉算法例子:a)金字塔混合;b)由阴影到形状;c)边缘检测;d)基于物理量的模型;e)基于正则化的表面重建;f)距离数据获取和归并
20世纪90年代,在识别中使用投影不变量的研究呈现爆发性增长,演变为解决从运行到结构问题的共同努力。最初很多研究是针对投影重建问题的。它不需要摄像机标定的结果。同时,提出了因子分解方法来高效地解决近似正交投影的问题,而后扩展到了透视投影的情况。最终,该领域开始使用完全的全局优化方法,这在后来被认为与摄像测量学中常用的“光束平差法”相同。使用这些方法建立了完全自动的(稀疏)3D建模系统。这个时期,从80年代开始的,使用颜色和亮度的精细测量,并与精确的辐射传输和形成彩色图像的物理模型相结合,构成一个称作“基于物理的视觉”的子领域。同时,光流方法得到了不断的改进,稠密立体视觉对应算法方面也取得了很多进展,其中最大的突破是使用“图割”(graph cut)方法的全局优化算法。另外,产生完整3D表面的多视角立体视觉算法到现在都依旧活跃。从二值的轮廓产生3D体描述的方法仍然还在研究中。
因为伴随着计算机视觉在交通和医疗等工业领域的应用越来越多,其他一些基础视觉研究方向,比如跟踪算法、图像分割等这个时期有了一定的发展。比如基于跟踪的算法,诸如使用“活动轮廓”方法的轮廓跟踪(例,蛇行、例子滤波器和水平集方法还有基于亮度的(直接)方法,常用于跟踪人脸和整个物体),此外还有重建光滑的遮挡轮廓的研究。
另外,图像分割,从计算机视觉早期开始一直是重要的方向和活跃的研究话题,90年代产生了基于最小能量的方法和最小描述长度方法,规范化割方法以及均值移位方法。统计学习的方法也是在这个时期流行起来,最初用于人脸识别的主分量本征脸分析和曲线跟踪的线性动态系统。从进入20世纪90年代,伴随着各种机器学习算法的全面开花。机器学习开始成为计算机视觉,尤其是识别、检测和分类等应用中一个不可分割的重要工具。各种识别和检测算法迎来了大发展。尤其是人脸识别在这个时期迎来研究的小高草。各种用描述图像特征的算子不断被发明出来,耳熟能详的SIFT算法也是在20实际90年代末被提出。

图5:20世纪90年代计算机视觉算法的例子:a)基于因子分解的从运动到结构;b)稠密立体视觉匹配;c)多视觉重建;d)人脸跟踪;e)图像分割;f)人脸识别
进入21世纪以后,计算机视觉俨然成为计算机领域一个大学科,国际计算机视觉与模式识别会议(CVPR)和ICCV已经成为人工智能领域甚至是整个计算机领域内的大型盛会。计算机视觉领域最显著的发展是与计算机图形学之间的交互增多了,尤其是基于图像的建模和绘制这个交叉学科领域。直接操作真实世界的影像来创建动画的想法最初是从图像变成方法开始变得显著起来,后来用于视角插值、全景图拼接和全光场绘制。同时也出现了从图像汇集自动创建具有真实感3D模型的基于图像的建模方法。随着计算机视觉和图形学的相互影响加深,最为明显的是,在基于图像绘制下,产生了图像拼接、光场获取和绘制以及通过曝光包围进行的高动态范围图像捕获,这些都被重新命名为计算摄影学。例如,通过曝光包围创建高动态范围图像得到快速采纳,使得色调映射算法发展成为必要,以便将这样的图像转变为可显示的结果。处理归并多个曝光之外,也出现了闪光图像和其对应的非闪光图像归并的方法以及交互地或自动地从交叠的图像中选择不同区域的方法。
纹理合成、绗缝(quilting)和修图也被划入计算机摄影学的另外一些研究方向,因为它们把输入图像样例重新结合以产生新的照片。
21世纪以来,显著趋势还有物体识别中基于特征方法(与学习方法相结合),该领域著名的论文有星群模型(Weakly Supervised Scale-Invariant Learning of Models for Visual Recognition,2007)和图案架构(Pictorial Structures for Object Recognition,2005)。基于特征的方法也主导了其他识别任务,例如场景识别和全景图以及位置识别。虽然兴趣点特征趋于主导当前研究,有些研究小组也在从事基于轮廓的识别研究和基于趋于分割的识别研究。
纹理合成、绗缝(quilting)和修图也被划入计算机摄影学的另外一些研究方向,因为它们把输入图像样例重新结合以产生新的照片。
21世纪以来,还有一个发展趋势是发展更高效求解全局优化问题的算法。这一趋势始于图割方面的工作,但在消息传递的算法也取得了许多进展,例如,带环的置信转播。
21世纪以来,还有一个趋势是复杂的机器学习方法在计算机视觉问题中的应用和深度学习在计算机视觉的应用,有意思的是,2010开始举办的大规模视觉识别挑战比赛(ImageNet),在2012年举办的那一届出现了一个使用神经网络AlexNet的研究生阿厉克斯•克里泽夫斯基,完胜第二名,此后基于深度学习的检测和识别、基于深度学习的图像分割、基于深度学习的立体视觉如雨后春笋般一夜之间全冒出来。

图6:21世纪以来的计算机视觉例子:a)基于图像的绘制;b)基于图像的建模;c)交互色调映射;d)纹理合成;e)基于特征的识别;f)基于区域的识别
所自学书籍的结构
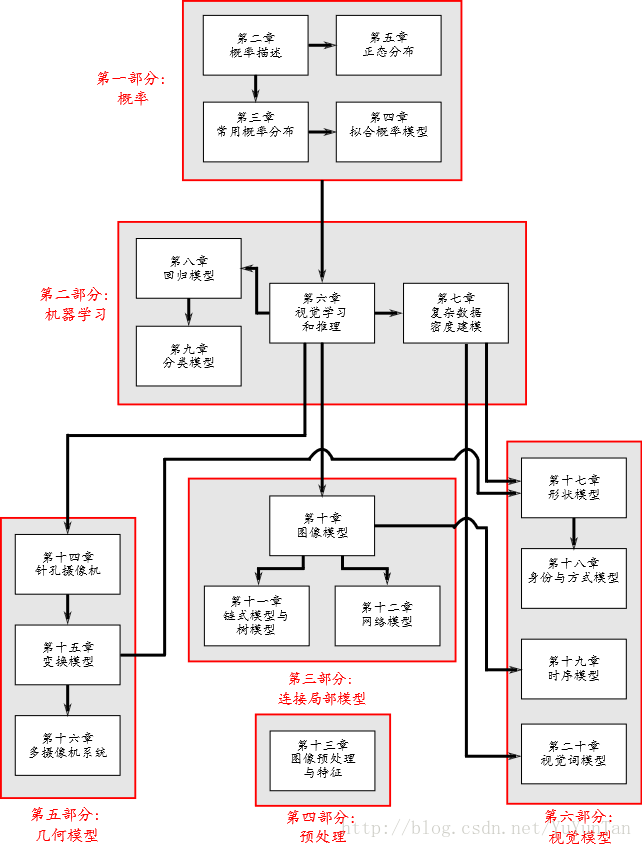
总结
本次博文主要是以《计算机视觉:模型、学习和推理》为主,先介绍了计算机视觉的定义,而后介绍计算机视觉的简史,最后描述该书的架构,对计算机视觉有一个完整的认知和技术的发展。最后值得说明的是,本书在之后的概率论部分,有些委实难懂。所以需要一定的基础之外,还需要强大理解能力。















 1178
1178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











