







Change Buffer有什么用
问题
- change buffer 有什么作用?
- 什么情况下会用到change buffer
准备工作
select * from information_schema.innodb_metrics where name like '%ibuf%';
可以查看到change buffer 的相关信息:
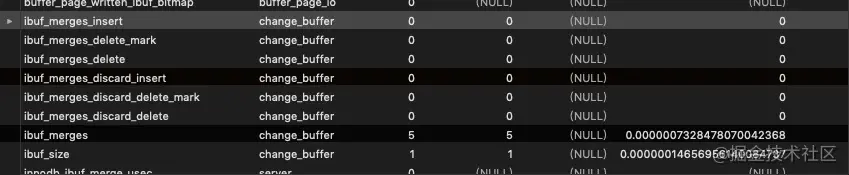
创建张表:
CREATE TABLE `author_1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `index_name` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
author_1 有主键索引,和一个index_name 的二级索引,假设该表存在以下数据。
聚簇索引的结构类似于:
| 页6 | 页6 | 页6 |
|---|---|---|
| 1 | 2 | 3 |
| abc | jack | zrr |
| 234 | 24 | 23 |
二级索引的value 存的是主键,此例子中二级索引的结构类似于:
| 页65 | 页65 | 页65 |
|---|---|---|
| abc | jack | zrr |
| 1 | 2 | 3 |
如果没有Change Buffer ,一条更新语句是如何执行的?
update author_1 set name = 'xxx' where id = 1
这个语句需要修改 2 个页面的数据:
- 第一处是聚簇索引中的 id =1 条中的数据。
- 第二处是修改二级索引的 name 的数据。
更新流程是:
首先在 Buffer Pool 中查找对应的页(也就是页6、页65),这里产生了2种情况:
- 页6和页65在Buffer Pool中,那么只要更新内存中的记录,并写redo log。
- 页6和页65不在Buffer Pool中,那么需要从磁盘中进行读取,放入内存后,再修改,并写redo log。
磁盘IO比较耗时,所以Mysql为了优化这一步骤,引入了Change Buffer。
Change Buffer 作用场景
强调:Change Buffer是针对非唯一的二级索引的优化。
那么也就是主键,以及唯一索引是用不了这个优化的。对应到例子中, 即使引入了Change Buffer,如果页6不在Buffer Pool 中,无论如何都需要从磁盘中读取,然后修改。
页65则不同了,这个时候页65,不需要从磁盘中进行读取了,InnoDB会直接写一条信息到Change Buffer中,然后写redo log 。这样无需进行磁盘IO就可以完成更新。
Change Buffer 只有 对非唯一的二级索引的数据页,并且该数据页不存在Buffer Pool中,才会被使用到。
change buffer和redo log的数据为了持久化是会被刷入磁盘的。也许会有疑问?这还不是进行磁盘操作了吗?是进行磁盘操作了,但是change buffer和redo log都是进行顺序写效率较高(磁盘顺序写和随机写性能差异很大)。
修改后立即读取会如何
select * from school where name = 'xxx'
由于会用到index_name索引,所以需要将页65读取到Buffer Pool,但此时页面65页中只有记录 ‘abc’,那么读取页面65之后,InnoDB首先把Change Buffer中的数据与读取的数据merge,然后存储在Buffer Pool中,这个时候页65中的数据就是正确的数据了。
为什么唯一索引无法使用Change Buffer
唯一索引在插入修改时都要进行唯一判断。如果不读取数据无法进行判断,既然数据无论如何都必须读取到Buffer Pool中 自然就不会用到Change Buffer了。
总结
change buffer提升了对非唯一二级索引的写性能。如果业务上对字段没有唯一性要求,那么应该尽量使用普通索引,避免唯一索引。对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时change buffer的使用效果最好。

















 2800
2800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









