






一、 redis多线程流程
Redis 虽然也实现了多线程,但是却不是标准的 Multi-Reactors/Master-Workers 模式。
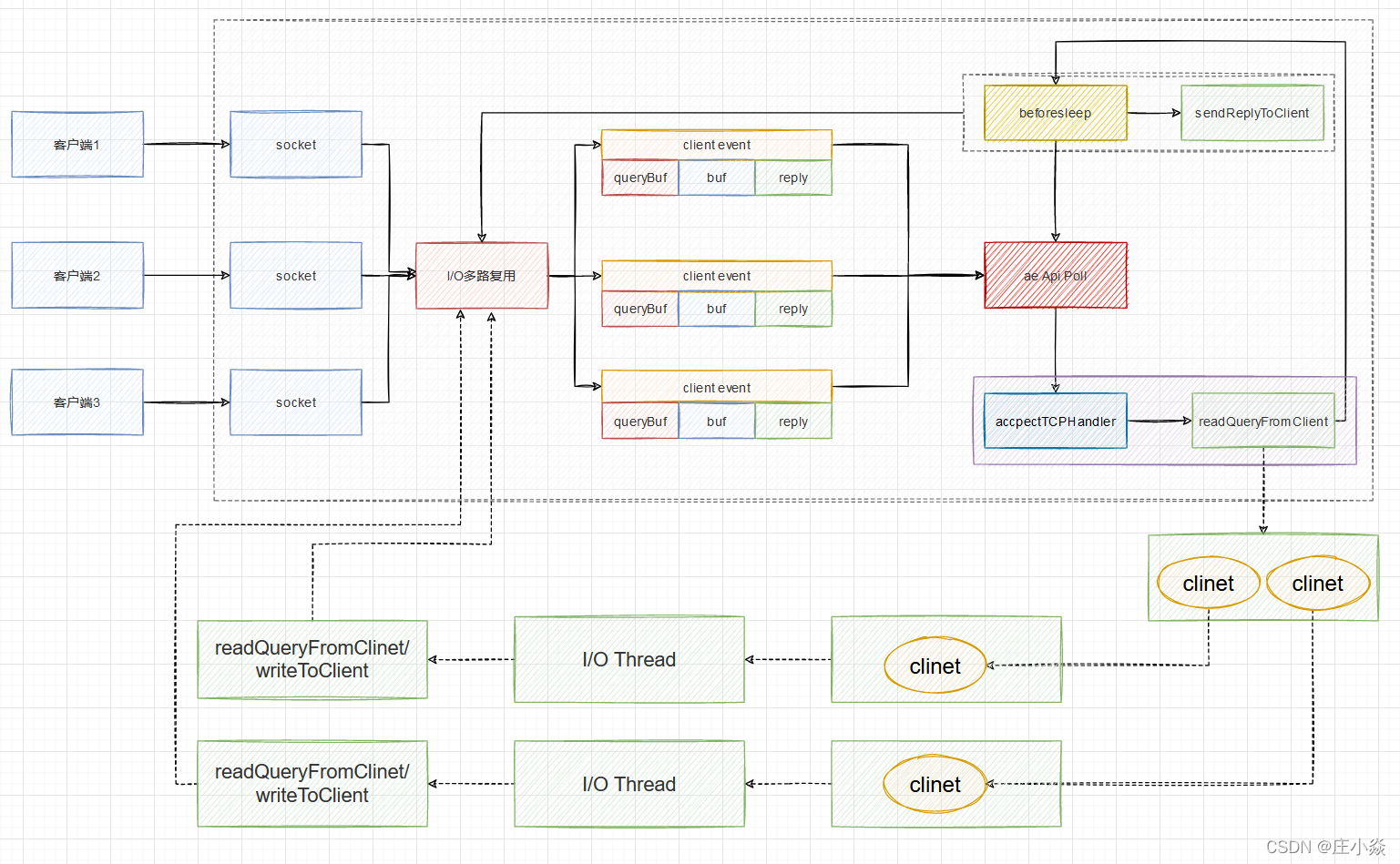
1. Redis 服务器启动,开启主线程事件循环(Event Loop),注册 acceptTcpHandler 连接应答处理器到用户配置的监听端口对应的文件描述符,等待新连接到来;
2. 客户端和服务端建立网络连接;
3. acceptTcpHandler 被调用,主线程使用 AE 的 API 将 readQueryFromClient 命令读取处理器绑定到新连接对应的文件描述符上,并初始化一个 client 绑定这个客户端连接;
4. 客户端发送请求命令,触发读就绪事件,服务端主线程不会通过 socket 去读取客户端的请求命令,而是先将 client 放入一个 LIFO 队列 clients_pending_read;
5. 在事件循环(Event Loop)中,主线程执行 beforeSleep() -->handleClientsWithPendingReadsUsingThreads(),利用 Round-Robin 轮询负载均衡策略,把 clients_pending_read队列中的连接均匀地分配给 I/O 线程各自的本地 FIFO 任务队列 io_threads_list[id] 和主线程自己,I/O 线程通过 socket 读取客户端的请求命令,存入 client->querybuf 并解析第一个命令,但不执行命令,主线程忙轮询,等待所有 I/O 线程完成读取任务;
6. 主线程和所有 I/O 线程都完成了读取任务,主线程结束忙轮询,遍历 clients_pending_read 队列,执行所有客户端连接的请求命令,先调用 processCommandAndResetClient 执行第一条已经解析好的命令,然后调用 processInputBuffer 解析并执行客户端连接的所有命令,在其中使用 processInlineBuffer 或者 processMultibulkBuffer 根据 Redis 协议解析命令,最后调用 processCommand 执行命令;
7. 根据请求命令的类型(SET, GET, DEL, EXEC 等),分配相应的命令执行器去执行,最后调用 addReply 函数族的一系列函数将响应数据写入到对应 client 的写出缓冲区:client->buf 或者 client->reply ,client->buf 是首选的写出缓冲区,固定大小 16KB,一般来说可以缓冲足够多的响应数据,但是如果客户端在时间窗口内需要响应的数据非常大,那么则会自动切换到 client->reply 链表上去,使用链表理论上能够保存无限大的数据(受限于机器的物理内存),最后把 client 添加进一个 LIFO 队列 clients_pending_write;
8. 在事件循环(Event Loop)中,主线程执行 beforeSleep --> handleClientsWithPendingWritesUsingThreads,利用 Round-Robin 轮询负载均衡策略,把 clients_pending_write 队列中的连接均匀地分配给 I/O 线程各自的本地 FIFO 任务队列 io_threads_list[id] 和主线程自己,I/O 线程通过调用 writeToClient 把 client 的写出缓冲区里的数据回写到客户端,主线程忙轮询,等待所有 I/O 线程完成写出任务;
9. 主线程和所有 I/O 线程都完成了写出任务, 主线程结束忙轮询,遍历 clients_pending_write 队列,如果 client 的写出缓冲区还有数据遗留,则注册 sendReplyToClient 到该连接的写就绪事件,等待客户端可写时在事件循环中再继续回写残余的响应数据。
这里大部分逻辑和之前的单线程模型是一致的,变动的地方仅仅是把读取客户端请求命令和回写响应数据的逻辑异步化了,交给 I/O 线程去完成,这里需要特别注意的一点是:I/O 线程仅仅是读取和解析客户端命令而不会真正去执行命令,客户端命令的执行最终还是要在主线程上完成。
二、redis多线程源码分析
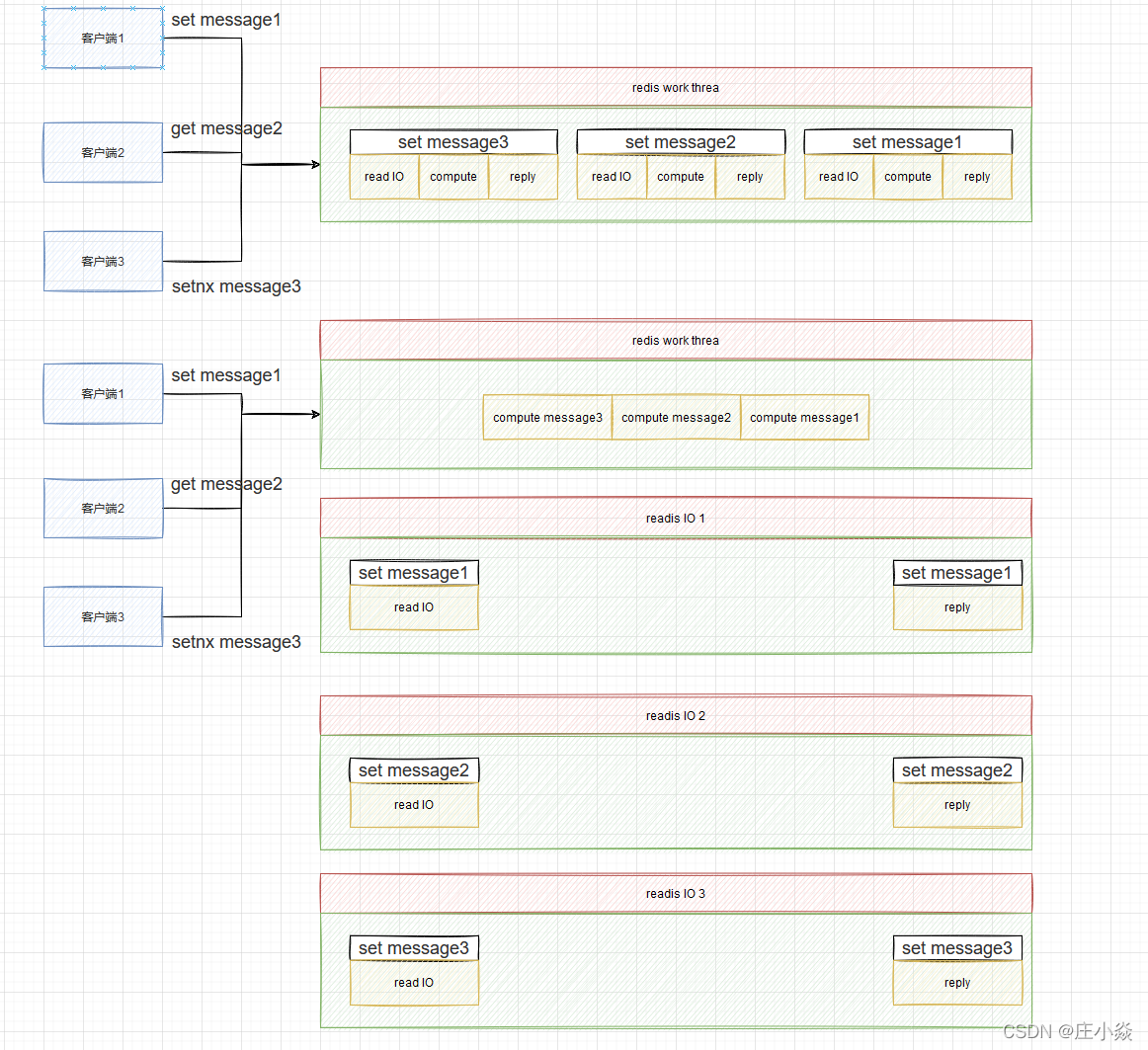
2.1 多线程初始化
void initThreadedIO(void) {
server.io_threads_active = 0; /* We start with threads not active. */
// 如果用户只配置了一个 I/O 线程,则不会创建新线程(效率低),直接在主线程里处理 I/O。
if (server.io_threads_num == 1) return;
if (server.io_threads_num > IO_THREADS_MAX_NUM) {
serverLog(LL_WARNING,"Fatal: too many I/O threads configured. "
"The maximum number is %d.", IO_THREADS_MAX_NUM);
exit(1);
}
// 根据用户配置的 I/O 线程数,启动线程。
for (int i = 0; i < server.io_threads_num; i++) {
// 初始化 I/O 线程的本地任务队列。
io_threads_list[i] = listCreate();
if (i == 0) continue; // 线程 0 是主线程。
// 初始化 I/O 线程并启动。
pthread_t tid;
// 每个 I/O 线程会分配一个本地锁,用来休眠和唤醒线程。
pthread_mutex_init(&io_threads_mutex[i],NULL);
// 每个 I/O 线程分配一个原子计数器,用来记录当前遗留的任务数量。
io_threads_pending[i] = 0;
// 主线程在启动 I/O 线程的时候会默认先锁住它,直到有 I/O 任务才唤醒它。
pthread_mutex_lock(&io_threads_mutex[i]);
// 启动线程,进入 I/O 线程的主逻辑函数 IOThreadMain。
if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize IO thread.");
exit(1);
}
io_threads[i] = tid;
}
}initThreadedIO 会在 Redis 服务器启动时的初始化工作的末尾被调用,初始化 I/O 多线程并启动。Redis 的多线程模式默认是关闭的,需要用户在 redis.conf 配置文件中开启:
io-threads 4
io-threads-do-reads yes
2.2 读取请求
当客户端发送请求命令之后,会触发 Redis 主线程的事件循环,命令处理器 readQueryFromClient 被回调,在以前的单线程模型下,这个方法会直接读取解析客户端命令并执行,但是多线程模式下,则会把 client 加入到 clients_pending_read 任务队列中去,后面主线程再分配到 I/O 线程去读取客户端请求命令:
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
int nread, readlen;
size_t qblen;
// 检查是否开启了多线程,如果是则把 client 加入异步队列之后返回。
if (postponeClientRead(c)) return;
// 省略代码,下面的代码逻辑和单线程版本几乎是一样的。
...
}
int postponeClientRead(client *c) {
// 当多线程 I/O 模式开启、主线程没有在处理阻塞任务时,将 client 加入异步队列。
if (server.io_threads_active &&
server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ)))
{
// 给 client 打上 CLIENT_PENDING_READ 标识,表示该 client 需要被多线程处理,
// 后续在 I/O 线程中会在读取和解析完客户端命令之后判断该标识并放弃执行命令,让主线程去执行。
c->flags |= CLIENT_PENDING_READ;
listAddNodeHead(server.clients_pending_read,c);
return 1;
} else {
return 0;
}
}接着主线程会在事件循环的 beforeSleep() 方法中,调用 handleClientsWithPendingReadsUsingThreads:
int handleClientsWithPendingReadsUsingThreads(void) {
if (!server.io_threads_active || !server.io_threads_do_reads) return 0;
int processed = listLength(server.clients_pending_read);
if (processed == 0) return 0;
if (tio_debug) printf("%d TOTAL READ pending clients\n", processed);
// 遍历待读取的 client 队列 clients_pending_read,
// 通过 RR 轮询均匀地分配给 I/O 线程和主线程自己(编号 0)。
listIter li;
listNode *ln;
listRewind(server.clients_pending_read,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 设置当前 I/O 操作为读取操作,给每个 I/O 线程的计数器设置分配的任务数量,
// 让 I/O 线程可以开始工作:只读取和解析命令,不执行。
io_threads_op = IO_THREADS_OP_READ;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count;
}
// 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
readQueryFromClient(c->conn);
}
listEmpty(io_threads_list[0]);
// 忙轮询,累加所有 I/O 线程的原子任务计数器,直到所有计数器的遗留任务数量都是 0,
// 表示所有任务都已经执行完成,结束轮询。
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
if (tio_debug) printf("I/O READ All threads finshed\n");
// 遍历待读取的 client 队列,清除 CLIENT_PENDING_READ 和 CLIENT_PENDING_COMMAND 标记,
// 然后解析并执行所有 client 的命令。
while(listLength(server.clients_pending_read)) {
ln = listFirst(server.clients_pending_read);
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_READ;
listDelNode(server.clients_pending_read,ln);
if (c->flags & CLIENT_PENDING_COMMAND) {
c->flags &= ~CLIENT_PENDING_COMMAND;
// client 的第一条命令已经被解析好了,直接尝试执行。
if (processCommandAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid
* processing the client later. So we just go
* to the next. */
continue;
}
}
processInputBuffer(c); // 继续解析并执行 client 命令。
// 命令执行完成之后,如果 client 中有响应数据需要回写到客户端,则将 client 加入到待写出队列 clients_pending_write
if (!(c->flags & CLIENT_PENDING_WRITE) && clientHasPendingReplies(c))
clientInstallWriteHandler(c);
}
/* Update processed count on server */
server.stat_io_reads_processed += processed;
return processed;
}这里的核心工作是:
遍历待读取的 client 队列 clients_pending_read,通过 RR 策略把所有任务分配给 I/O 线程和主线程去读取和解析客户端命令。
忙轮询等待所有 I/O 线程完成任务。
最后再遍历 clients_pending_read,执行所有 client 的命令。
2.3 写回响应
完成命令的读取、解析以及执行之后,客户端命令的响应数据已经存入 client->buf 或者 client->reply 中了,接下来就需要把响应数据回写到客户端了,还是在 beforeSleep 中, 主线程调用 handleClientsWithPendingWritesUsingThreads:
int handleClientsWithPendingWritesUsingThreads(void) {
int processed = listLength(server.clients_pending_write);
if (processed == 0) return 0; /* Return ASAP if there are no clients. */
// 如果用户设置的 I/O 线程数等于 1 或者当前 clients_pending_write 队列中待写出的 client
// 数量不足 I/O 线程数的两倍,则不用多线程的逻辑,让所有 I/O 线程进入休眠,
// 直接在主线程把所有 client 的相应数据回写到客户端。
if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) {
return handleClientsWithPendingWrites();
}
// 唤醒正在休眠的 I/O 线程(如果有的话)。
if (!server.io_threads_active) startThreadedIO();
if (tio_debug) printf("%d TOTAL WRITE pending clients\n", processed);
// 遍历待写出的 client 队列 clients_pending_write,
// 通过 RR 轮询均匀地分配给 I/O 线程和主线程自己(编号 0)。
listIter li;
listNode *ln;
listRewind(server.clients_pending_write,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
/* Remove clients from the list of pending writes since
* they are going to be closed ASAP. */
if (c->flags & CLIENT_CLOSE_ASAP) {
listDelNode(server.clients_pending_write, ln);
continue;
}
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 设置当前 I/O 操作为写出操作,给每个 I/O 线程的计数器设置分配的任务数量,
// 让 I/O 线程可以开始工作,把写出缓冲区(client->buf 或 c->reply)中的响应数据回写到客户端。
io_threads_op = IO_THREADS_OP_WRITE;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count;
}
// 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
writeToClient(c,0);
}
listEmpty(io_threads_list[0]);
// 忙轮询,累加所有 I/O 线程的原子任务计数器,直到所有计数器的遗留任务数量都是 0。
// 表示所有任务都已经执行完成,结束轮询。
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
if (tio_debug) printf("I/O WRITE All threads finshed\n");
// 最后再遍历一次 clients_pending_write 队列,检查是否还有 client 的写出缓冲区中有残留数据,
// 如果有,那就为 client 注册一个命令回复器 sendReplyToClient,等待客户端写就绪再继续把数据回写。
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 检查 client 的写出缓冲区是否还有遗留数据。
if (clientHasPendingReplies(c) &&
connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR)
{
freeClientAsync(c);
}
}
listEmpty(server.clients_pending_write);
/* Update processed count on server */
server.stat_io_writes_processed += processed;
return processed;
}这里的核心工作是:
检查当前任务负载,如果当前的任务数量不足以用多线程模式处理的话,则休眠 I/O 线程并且直接同步将响应数据回写到客户端。
唤醒正在休眠的 I/O 线程(如果有的话)。
遍历待写出的 client 队列 clients_pending_write,通过 RR 策略把所有任务分配给 I/O 线程和主线程去将响应数据写回到客户端。
忙轮询等待所有 I/O 线程完成任务。
最后再遍历 clients_pending_write,为那些还残留有响应数据的 client 注册命令回复处理器 sendReplyToClient,等待客户端可写之后在事件循环中继续回写残余的响应数据。
2.4 I/O 线程主逻辑
void *IOThreadMain(void *myid) {
/* The ID is the thread number (from 0 to server.iothreads_num-1), and is
* used by the thread to just manipulate a single sub-array of clients. */
long id = (unsigned long)myid;
char thdname[16];
snprintf(thdname, sizeof(thdname), "io_thd_%ld", id);
redis_set_thread_title(thdname);
// 设置 I/O 线程的 CPU 亲和性,尽可能将 I/O 线程(以及主线程,不在这里设置)绑定到用户配置的
// CPU 列表上。
redisSetCpuAffinity(server.server_cpulist);
makeThreadKillable();
while(1) {
// 忙轮询,100w 次循环,等待主线程分配 I/O 任务。
for (int j = 0; j < 1000000; j++) {
if (io_threads_pending[id] != 0) break;
}
// 如果 100w 次忙轮询之后如果还是没有任务分配给它,则通过尝试加锁进入休眠,
// 等待主线程分配任务之后调用 startThreadedIO 解锁,唤醒 I/O 线程去执行。
if (io_threads_pending[id] == 0) {
pthread_mutex_lock(&io_threads_mutex[id]);
pthread_mutex_unlock(&io_threads_mutex[id]);
continue;
}
serverAssert(io_threads_pending[id] != 0);
if (tio_debug) printf("[%ld] %d to handle\n", id, (int)listLength(io_threads_list[id]));
// 注意:主线程分配任务给 I/O 线程之时,
// 会把任务加入每个线程的本地任务队列 io_threads_list[id],
// 但是当 I/O 线程开始执行任务之后,主线程就不会再去访问这些任务队列,避免数据竞争。
listIter li;
listNode *ln;
listRewind(io_threads_list[id],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 如果当前是写出操作,则把 client 的写出缓冲区中的数据回写到客户端。
if (io_threads_op == IO_THREADS_OP_WRITE) {
writeToClient(c,0);
// 如果当前是读取操作,则socket 读取客户端的请求命令并解析第一条命令。
} else if (io_threads_op == IO_THREADS_OP_READ) {
readQueryFromClient(c->conn);
} else {
serverPanic("io_threads_op value is unknown");
}
}
listEmpty(io_threads_list[id]);
// 所有任务执行完之后把自己的计数器置 0,主线程通过累加所有 I/O 线程的计数器
// 判断是否所有 I/O 线程都已经完成工作。
io_threads_pending[id] = 0;
if (tio_debug) printf("[%ld] Done\n", id);
}
}I/O 线程启动之后,会先进入忙轮询,判断原子计数器中的任务数量,如果是非 0 则表示主线程已经给它分配了任务,开始执行任务,否则就一直忙轮询一百万次等待,忙轮询结束之后再查看计数器,如果还是 0,则尝试加本地锁,因为主线程在启动 I/O 线程之时就已经提前锁住了所有 I/O 线程的本地锁,因此 I/O 线程会进行休眠,等待主线程唤醒。
主线程会在每次事件循环中尝试调用 startThreadedIO 唤醒 I/O 线程去执行任务,如果接收到客户端请求命令,则 I/O 线程会被唤醒开始工作,根据主线程设置的 io_threads_op 标识去执行命令读取和解析或者回写响应数据的任务,I/O 线程在收到主线程通知之后,会遍历自己的本地任务队列 io_threads_list[id],取出一个个 client 执行任务:
如果当前是写出操作,则调用 writeToClient,通过 socket 把 client->buf 或者 client->reply 里的响应数据回写到客户端。
如果当前是读取操作,则调用 readQueryFromClient,通过 socket 读取客户端命令,存入 client->querybuf,然后调用 processInputBuffer 去解析命令,这里最终只会解析到第一条命令,然后就结束,不会去执行命令。
在全部任务执行完之后把 自己的原子计数器置 0,以告知主线程自己已经完成了工作。
void processInputBuffer(client *c) {
// 省略代码
...
while(c->qb_pos < sdslen(c->querybuf)) {
/* Return if clients are paused. */
if (!(c->flags & CLIENT_SLAVE) && clientsArePaused()) break;
/* Immediately abort if the client is in the middle of something. */
if (c->flags & CLIENT_BLOCKED) break;
/* Don't process more buffers from clients that have already pending
* commands to execute in c->argv. */
if (c->flags & CLIENT_PENDING_COMMAND) break;
/* Multibulk processing could see a <= 0 length. */
if (c->argc == 0) {
resetClient(c);
} else {
// 判断 client 是否具有 CLIENT_PENDING_READ 标识,如果是处于多线程 I/O 的模式下,
// 那么此前已经在 readQueryFromClient -> postponeClientRead 中为 client 打上该标识,
// 则立刻跳出循环结束,此时第一条命令已经解析完成,但是不执行命令。
if (c->flags & CLIENT_PENDING_READ) {
c->flags |= CLIENT_PENDING_COMMAND;
break;
}
// 执行客户端命令
if (processCommandAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid exiting this
* loop and trimming the client buffer later. So we return
* ASAP in that case. */
return;
}
}
}
...
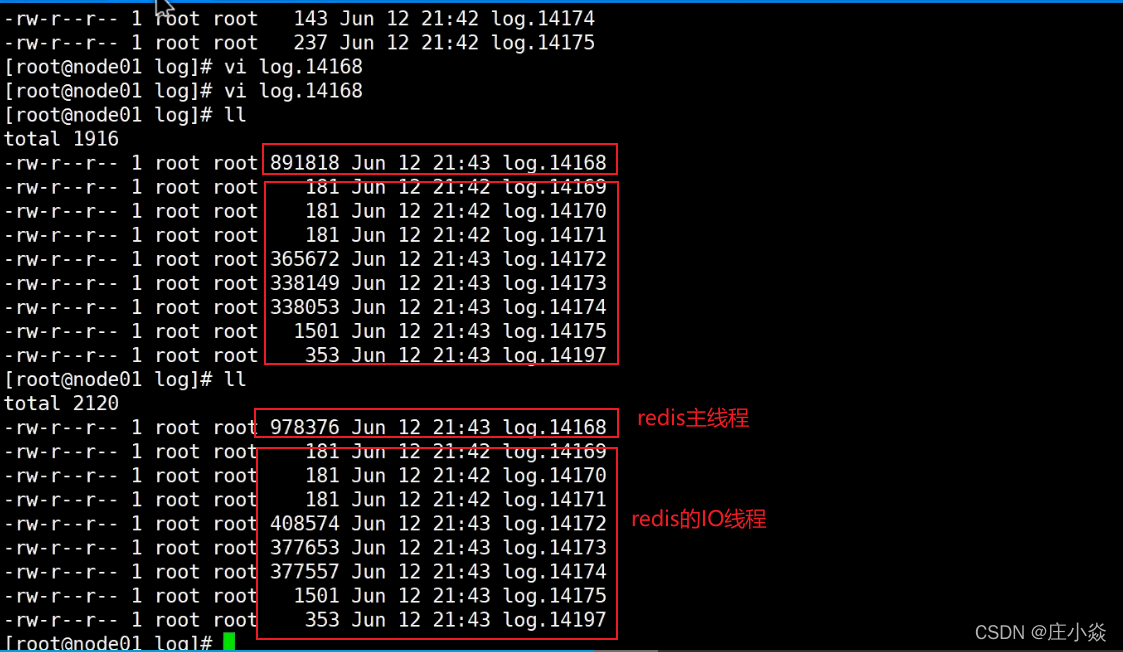
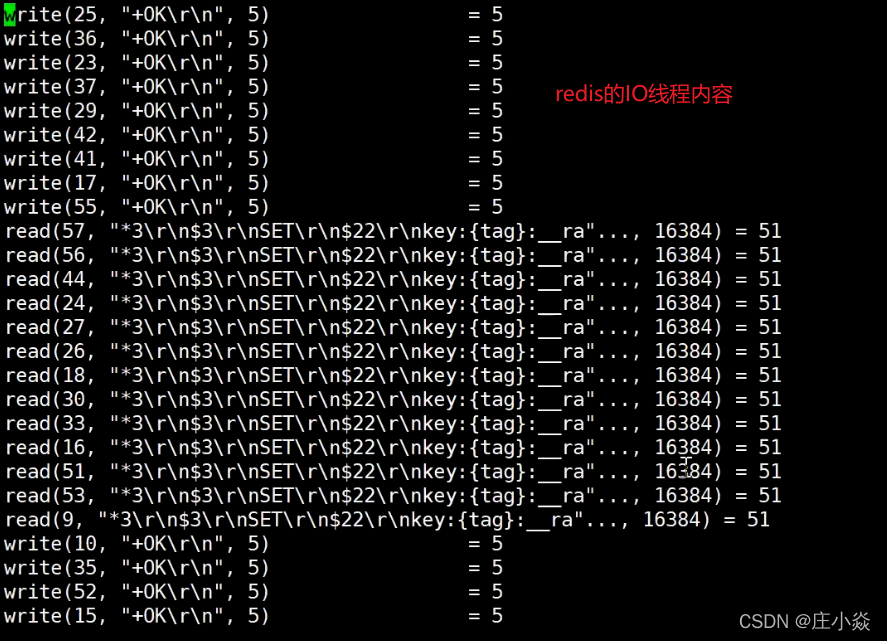
}三、实验
io-threads 4
io-threads-do-reads yes
# 开启redis多线程
strace -ff -o log redis服务 path conf-path# redis 压测命令
redis-benchmark -t set -c 50

三、redis线程模型总结
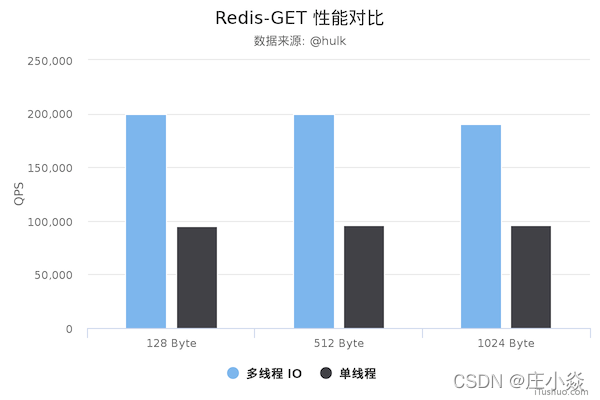
测试数据表明,如果在4核的时候,redis6.0的数据的QPS将变成20W。同时在8个I/O的thread的时候能够弥补内核和app之间的系统调用的损耗的。。Redis 在使用多线程模式之后性能大幅提升,达到了一倍。更详细的性能压测数据。
模型缺陷
首先第一个就是我前面提到过的,Redis 的多线程网络模型实际上并不是一个标准的 Multi-Reactors/Master-Workers 模型,和其他主流的开源网络服务器的模式有所区别,最大的不同就是在标准的 Multi-Reactors/Master-Workers 模式下,Sub Reactors/Workers 会完成 网络读 -> 数据解析 -> 命令执行 -> 网络写 整套流程,Main Reactor/Master 只负责分派任务,而在 Redis 的多线程方案中,I/O 线程任务仅仅是通过 socket 读取客户端请求命令并解析,却没有真正去执行命令,所有客户端命令最后还需要回到主线程去执行,因此对多核的利用率并不算高,而且每次主线程都必须在分配完任务之后忙轮询等待所有 I/O 线程完成任务之后才能继续执行其他逻辑。
Redis 之所以如此设计它的多线程网络模型,我认为主要的原因是为了保持兼容性,因为以前 Redis 是单线程的,所有的客户端命令都是在单线程的事件循环里执行的,也因此 Redis 里所有的数据结构都是非线程安全的,现在引入多线程,如果按照标准的 Multi-Reactors/Master-Workers 模式来实现,则所有内置的数据结构都必须重构成线程安全的,这个工作量无疑是巨大且麻烦的。
Redis 多线程网络模型的设计方案:
使用 I/O 线程实现网络 I/O 多线程化,I/O 线程只负责网络 I/O 和命令解析,不执行客户端命令。
利用原子操作+交错访问实现无锁的多线程模型。
通过设置 CPU 亲和性,隔离主进程和其他子进程,让多线程网络模型能发挥最大的性能。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









