









阿里分布式数据库服务实践
云学习小组 2015-12-13 14:31:53 浏览14119
沈询: 阿里巴巴资深技术专家,08年加入阿里巴巴,一直从事阿里分布式数据层方面的研发工作,参与了公司大部分的去IOE工作,具备较多实操经验。目前主要负责淘宝分布式数据层(TDDL),阿里分布式数据库服务(DRDS),阿里分布式消息服务(Notify,MetaQ)的开发和架构设计工作。
经过近一年的运营,阿里巴巴的分布式数据库(DRDS)已经协助电商,电信,银行,政府等多种类型的系统进行过业务分布式改造,在系统实施的过程中,我们碰到和解决了哪些问题? 他们是怎么解决的?背后的思考是什么?未来在何方? 以下来分享下精彩内容。
DRDS简介
起源
DRDS 脱胎于 alibaba的cobra 分布式数据库引擎,06年上线使用,在alibaba有近百应用在使用,目前已经开源,DRDS的80%的代码出自cobra proxy(Sql解析器,执行流程,配置)。
DRDS吸收了taobao TDDL分布式数据库引擎的大量优秀经验和解决方案,08年上线使用,目前在使用的应用近千个,大量实际应用解决方案支持分布式join,支持分布式aggregation (group sum max min),支持异步索引构建,支持Auto sharding ,自动扩容缩容。
从TDDL到DRDS,
DRDS专门针对外部用户进行了配置的重新设计:简化了配置操作规范与流程;尽可能使得应用像操作一个数据库一样的操作DRDS;用户的专业化指导。
场景广泛:互联网应用,企业内大数据应用,政务类应用,物联网应用。
应用场景
应用的业务需求单机已经无法满足,一个RDS数据库的最大实例也无法满足用户的需求,可能遇到容量瓶颈、事务数瓶颈、读取瓶颈,我们就可以考虑使用分布式数据库了。
Scale out(多机水平扩展),使用廉价数据库阵列来满足用户需求—DRDS。
优势:更轻量的使用数据库,未来更换的成本小;一次重构,以后基本再无需担心系统瓶颈。劣势:重构迁移需要付出成本;分布式环境下一些查询会被限制不允许执行;完成相同功能需要比单机扩展付出更多成本。

图1
理想状态就是Scale out 与scale up结合。如图1所示,让系统架构具备scale out的能力,尽可能提升单机利用率,但不要过早过度设计。

图2
何时应该选择Sharding方案?图2中的概要图给出了分析。
DRDS功能介绍
分布式MySQL执行引擎
具有非常高的兼容性,MySQL 5.5 的各类复杂查询都能做到,包括复杂的join,复杂的嵌套,复杂的函数。降低了迁移时候的成本。
智能下推的功能,减少网络传输,减少计算量,充分发挥下层存储的全部能力。
智能下推有两个典型的例子,图3为表A 分库分表3个的例子,图4为全表distinct groupby的执行计划的例子。

图3

图4
弹性扩展
自动扩容、缩容是另外一个重要功能。如图5,DRDS可以做到原来一个库,下一步变成两个库,依然可以扩,对一些特殊需求也可以实现自动化后台迁移,自动扩容缩容。
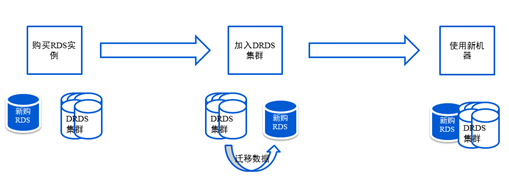
图5
小表异步广播

图6
如图6的跨机join的优势是一致性,空间比较节省。劣势是网络消耗和延迟增加。
图7
图7小表广播join的优势是性能高,延迟低,网络消耗小,劣势是最终一致性,小表更新量不能太巨大。
DRDS实践
分布式查询优化
最终的目标是让所有请求可以水平扩展,要想达到这个目的,有两个基本的原则:1尽可能让所有查询发生在尽可能少的下层存储节点上,最好是只发生在一台上。将跨网络请求尽可能减少,减少并行查询时的机器消耗。2选择的shardingKey要能够让所有存储节点均衡的负载读写请求。系统可以简单加机器来扩展,没有系统瓶颈。案例1如图8所示是一个订单的场景,应该选择哪个列作为切分条件?按照买家ID的查询(买家查看自己买了哪些商品)。

图8
案例2如图9所示的过程就是数据的切分,应该选择哪个列作为切分条件?按照买家ID的查询(买家查看自己买了哪些商品);按照卖家ID的查询(卖家查看自己卖了哪些商品。

图9
图10表达了异构复制,数据通过后台自动化逻辑复制过去,建立一个新的全表索引。

图10
案例三如图11所示,在原来表里加了type,关联两个表,但这两个表不在一台机器上,遇到这种场景就需要如图12所示的小表异步广播。

图11
图12
事务的分布式优化
事务的分布式优化的目标是完整的事务支持,既要支持ACID,又可按需无限拓展。然而这种模型是不可能实现的。
那么我们该怎么办呢?优化事务的最重要的手段就是从强一致到最终一致。把这种情况拟人化场景为:李雷家住长江头,梅梅家住长江尾,日日思君不见君,送只玫瑰表心意。李雷希望(ACID):花别丢了,送不到给我退回来(原子性,A);花能瞬时送到梅梅家(强一致性和强隔离性,C&I);花别在路上坏了(D)。其中瞬时就是当李雷去检查的时候,要么花在李雷那,要么花在韩梅梅那。
实现方案一:李雷做火车到长江尾,亲手交给了梅梅。方案二:李雷将花交给邮递员,邮递员做飞机把花送给韩梅梅,李雷电话打了一天,韩梅梅都没接,邮递员把花交给韩梅梅,韩梅梅接起电话,告诉李雷收到花。方案二就是强一致,它的优势是编程模型简单,不用考虑邮递员运输中的各种并发问题。它的劣势是并发性能低,李雷一天都不用干活了。
真的遇到这种情况时,我们该采用最终一致进行优化,上述情景大体不变,更改为李雷打电话韩梅梅告诉他还没收到,李雷就去做了其他事情。最终一致的优势是无阻塞情况,并发性能好。劣势是复杂度略高,需要考虑玫瑰已经发出,但对方还没收到的情况应该如何处理。
图13展现了单机和分布式事务情况。所以我们建议结合最终一致和强一致,单机可以使用强一致,跨机建议使用最终一致。

图13
从单机存储到DRDS迁移流程
迁移的目标是:保证业务线上正常运转;平滑过渡;减少运维。
迁移的步骤有三步:SETP1:读写在原来的单机数据库;数据通过“愚公数据迁移平台”写入云上DRDS。SETP2:验证云上数据是否正确;验证云上DRDS是否能够很好的应对读流量压力。SETP3:夜间,停写几分钟;读写切换到DRDS;数据通过“愚公数据迁移平台”写回到云下单机数据库。
PPT下载地址:http://club.alibabatech.org/resource_detail.htm?topicId=156
本文首发在云栖社区,遵循云栖社区版权声明:本文内容由互联网用户自发贡献,版权归用户作者所有,云栖社区不为本文内容承担相关法律责任。云栖社区已在2020年6月升级到阿里云开发者社区。如果您发现有涉嫌抄袭的内容,请填写侵权投诉表单进行举报,一经查实,阿里云开发者社区将协助删除涉嫌侵权内容。















 1620
1620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









