







为什么要做接口测试?
接口的由来: 连接前后端以及移动端。
因为不同端的工作进度不一样,所以需要对开始出来的接口进行接口测试。
做接口测试的好处:
1、节约时间,缩短项目成本
2、提高工作效率
3、提高系统的健壮性
你在项目中如何做接口测试?
首先,当面试官问你这个问题的时候,不要忙着回答,因为我们知道:接口测试分为接口功能测试、接口性能测试、接口安全测试、接口自动化测试;所以你要先明确面试官的出发点是什么,可以进一步的明确面试官的问题,在进行回答。
其次,接口测试的几大模块你都要知道怎么做。
接口功能测试: 使用什么工具,比如使用Postman、Fillder、Jmeter来进行功能测试,请求参数是什么,返回的参数是什么,会去校验返回的格式和值,校验一些额外的什么内容。
接口性能测试: 使用测试工具或者自行编写测试脚本,对接口进行压力测试,当压力测试并发值达到多少,当接口的响应值达到多少的时候,会根据报告去分析性能问题,定位问题。
接口安全测试: 在测试这个接口的时候,是否考虑到存在一些安全问题,要考虑在调用端的时候是否存在SQL注入,以及接口的参数是否做了一些强校验,等等。
接口自动化测试: 使用的语言Java/Python + HttpRunner去做接口自动化测试;介绍你的接口自动化测试框架,以及框架内的各模块的介绍,等等。
cookie、session和token
为什么要有cookie/session?
在客户端浏览器向服务器发送请求,服务器做出响应之后,二者便会断开连接(一次会话结束)。那么下次用户再来请求服务器,服务器没有任何办法去识别此用户是谁。比如web系统常用的用户登录功能,如果没有cookie机制支持,那么只能通过查询数据库实现,并且要命的是每次刷新页面都要重新输入表单信息查询一次数据库才可以识别用户,这会给开发人员带来大量冗余工作并且简单的用户登录功能会给服务器带来巨大的压力。
在此背景下,就急需一种机制来解决此问题。分析可知,以上需求的实现就要客户端每次访问服务器时从客户端带上一些数据(相当于身份证)告知服务器自己是谁。这个数据就是cookie!并且客户端访问服务器时不能将所有cookie都带过去,比如访问百度就不能把谷歌的cookie带给百度,这个设置方式在后面介绍。
那么有了cookie,为什么还要有session呢?有了cookie可以向服务器证明用户身份了,我们的web系统中是不是需要将用户的详细信息储存在某个位置供页面调用呢?用户的详细信息就包括姓名,年龄,性别等信息。而cookie是存在于客户端的,将用户详细信息通过网络发送到客户端保存是极不安全的。且cookie大小不能超过4k,不能支持中文。这就限制cookie不能满足存储用户信息的需求。这就需要一种机制在服务器端的某个域中存储一些数据,这个域就是session。
总而言之,cookie/session的出现就是为了解决http协议无状态的弊端,为了让客户端和服务端建立长久联系而出现的。
cookie 概念
cookie是保存在本地终端的数据。cookie由服务器生成,发送给浏览器,浏览器把cookie以kv形式保存到某个目录下的文本文件内,下一次请求同一网站时会把该cookie发送给服务器。由于cookie是存在客户端上的,所以浏览器加入了一些限制确保cookie不会被恶意使用,同时不会占据太多磁盘空间,所以每个域的cookie数量是有限的。
cookie的组成有:名称(key)、值(value)、有效域(domain)、路径(域的路径,一般设置为全局:"")、失效时间、安全标志(指定后,cookie只有在使用SSL连接时才发送到服务器(https))。下面是一个简单的js使用cookie的例子:
用户登录时产生cookie:
document.cookie = “id=”+result.data[‘id’]+"; path=/";
document.cookie = “name=”+result.data[‘name’]+"; path=/";
document.cookie = “avatar=”+result.data[‘avatar’]+"; path=/";
session和token概念
session和token算是一类的,他们是两种不同的服务器的验证方式。
通俗来说,cookie会存一个value在客户端本地,然后将value附到HTTP上发给服务器,那么服务器是怎么通过这个value来判断用户是否是登录态的呢?这就是session和token做的事情。
session,服务器使用session把用户的信息临时保存在了服务器上,用户离开网站后session会被销毁。这种用户信息存储方式相对cookie来说更安全,可是session有一个缺陷:如果web服务器做了负载均衡,那么下一个操作请求到了另一台服务器的时候session会丢失。
token的意思是“令牌”,是用户身份的验证方式,最简单的token组成:uid(用户唯一的身份标识)、time(当前时间的时间戳)、sign(签名,由token的前几位+以哈希算法压缩成一定长的十六进制字符串,可以防止恶意第三方拼接token请求服务器)。还可以把不变的参数也放进token,避免多次查库。
session过程
请求过程:
1、客户端向服务器请求,发送用户名和密码
2、服务器生成sessionId,绑定用户数据存储在数据库
3、服务器返回sessionId给客户端
4、客户端用cookie存储sessionId,以后的请求都带上这个sessionId
5、服务器如果收到这个sessionId,那么就去数据库查找用户数据,如果找到了说明验证通过
6、服务器把验证结果返回客户端

token过程
请求过程:
1、客户端向服务器请求,发送用户名和密码
2、服务器根据用户信息通过加密生成token,用户信息包括账号,token过期时间等,具体由服务器自定义。
3、服务器返回token给客户端
4、客户端用cookie存储token,以后的请求都带上这个token
5、服务器把token解密,确认用户信息是否正确,如经过正确就说明验证通过。
6、服务器把验证结果返回客户端

cookie/session的区别与联系
区别:
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
考虑到减轻服务器性能方面,应当使用COOKIE。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie,而session理论上没有做限制。
5、所以个人建议:
将登陆信息等重要信息存放为SESSION
其他信息如果需要保留,可以放在COOKIE中
联系:
session虽说存放在服务器端,但是仔细看刚才的执行流程你会明白,session是依赖于cookie的,这一点也是本篇文章想要着重强调的
cookie/session使用注意事项
1.cookie大小有限制 4k
2.cookie不能跨浏览器
3.cookie不支持中文
4.如果是安全性较高的数据应存放在session中,因为cookie存放在客户端总会轻易被不法分子获取
5.如果是访问量特别大的网站,尽量不要在session中存储用户数据,因为每个用户存一个session会给服务器造成很大的压力
session、token优劣
session
由于sessionId和用户信息相互绑定的数据库存在服务器,所以服务器可以随时让发送出去的一个sessionId失效。这是保障安全的一种重要手段。
App通常用restful api跟server打交道。Rest是stateless的,也就是app不需要像browser那样用cookie来保存session,因此用session token来标示自己就够了,session/state由api server的逻辑处理。 如果你的后端不是stateless的rest api, 那么你可能需要在app里保存session.可以在app里嵌入webkit,用一个隐藏的browser来管理cookie session.
token
token的好处是比session更省空间和时间,服务器不需要去管理sessionId和用户信息的数据库,服务器收到token直接解密就可以验证,不需要去数据库查找验证。
但是token发送出去之后,就只能等待它达到过期时间后才会失效,后台无法对其进行控制。
新手使用session时常踩的坑
很多人使用session时希望用户信息可以保存一段时间比如保存7天,于是配置了Tomcat的
<session-config>
<session-timeout>7天</session-timeout>
</session-config>
配置完后发现,关闭浏览器后再访问还是取不到session。这是因为session的配置没起作用吗?不是的,其实session还是存在于服务器的,只是没有设置cookie持久化,cookie默认就会在浏览器关闭时销毁,所以叫做JSESSIONID的cookie也被销毁了,再到服务器的时候没有这个叫JSESSIONID的cookie就取不到相关的session了。
所以,如果想7天内都能访问到session,需要将cookie也设置持久化!
以上内容来自博主:许佳佳333 、 IT_zhang81 、天空之城–
HTTPS与HTTP协议的区别,以及HTTP的8种请求方法
前言:
超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。
为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
一、HTTP和HTTPS的基本概念
HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
HTTPS:是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
HTTPS协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
二、HTTP与HTTPS有什么区别?
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
HTTPS和HTTP的区别主要如下:
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是 80,后者是 443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
三、HTTPS的工作原理
我们都知道HTTPS能够加密信息,以免敏感信息被第三方获取,所以很多银行网站或电子邮箱等等安全级别较高的服务都会采用HTTPS协议。

客户端在使用HTTPS方式与Web服务器通信时有以下几个步骤,如图所示。
(1)客户使用https的URL访问Web服务器,要求与Web服务器建立SSL连接。
(2)Web服务器收到客户端请求后,会将网站的证书信息(证书中包含公钥)传送一份给客户端。
(3)客户端的浏览器与Web服务器开始协商SSL连接的安全等级,也就是信息加密的等级。
(4)客户端的浏览器根据双方同意的安全等级,建立会话密钥,然后利用网站的公钥将会话密钥加密,并传送给网站。
(5)Web服务器利用自己的私钥解密出会话密钥。
(6)Web服务器利用会话密钥加密与客户端之间的通信。

四、HTTPS的优点
尽管HTTPS并非绝对安全,掌握根证书的机构、掌握加密算法的组织同样可以进行中间人形式的攻击,但HTTPS仍是现行架构下最安全的解决方案,主要有以下几个好处:
(1)使用HTTPS协议可认证用户和服务器,确保数据发送到正确的客户机和服务器;
(2)HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全,可防止数据在传输过程中不被窃取、改变,确保数据的完整性。
(3)HTTPS是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本。
(4)谷歌曾在2014年8月份调整搜索引擎算法,并称“比起同等HTTP网站,采用HTTPS加密的网站在搜索结果中的排名将会更高”。
五、HTTPS的缺点
虽然说HTTPS有很大的优势,但其相对来说,还是存在不足之处的:
(1)HTTPS协议握手阶段比较费时,会使页面的加载时间延长近50%,增加10%到20%的耗电;
(2)HTTPS连接缓存不如HTTP高效,会增加数据开销和功耗,甚至已有的安全措施也会因此而受到影响;
(3)SSL证书需要钱,功能越强大的证书费用越高,个人网站、小网站没有必要一般不会用。
(4)SSL证书通常需要绑定IP,不能在同一IP上绑定多个域名,IPv4资源不可能支撑这个消耗。
(5)HTTPS协议的加密范围也比较有限,在黑客攻击、拒绝服务攻击、服务器劫持等方面几乎起不到什么作用。最关键的,SSL证书的信用链体系并不安全,特别是在某些国家可以控制CA根证书的情况下,中间人攻击一样可行。
六、http切换到HTTPS
如果需要将网站从http切换到https到底该如何实现呢?
这里需要将页面中所有的链接,例如js,css,图片等等链接都由http改为https。例如:http://www.baidu.com改为https://www.baidu.com
BTW,这里虽然将http切换为了https,还是建议保留http。所以我们在切换的时候可以做http和https的兼容,具体实现方式是,去掉页面链接中的http头部,这样可以自动匹配http头和https头。例如:将http://www.baidu.com改为//www.baidu.com。然后当用户从http的入口进入访问页面时,页面就是http,如果用户是从https的入口进入访问页面,页面即是https的。
HTTP请求的方法:
1、OPTIONS
返回服务器针对特定资源所支持的HTTP请求方法,也可以利用向web服务器发送‘*’的请求来测试服务器的功能性
2、HEAD
向服务器索与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以再不必传输整个响应内容的情况下,就可以获取包含在响应小消息头中的元信息。
3、GET
向特定的资源发出请求。它本质就是发送一个请求来取得服务器上的某一资源。资源通过一组HTTP头和呈现数据(如HTML文本,或者图片或者视频等)返回给客户端。GET请求中,永远不会包含呈现数据。
4、POST
向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 Loadrunner中对应POST请求函数:web_submit_data,web_submit_form
5、PUT
向指定资源位置上传其最新内容
6、DELETE
请求服务器删除Request-URL所标识的资源
7、TRACE
回显服务器收到的请求,主要用于测试或诊断
8、CONNECT
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
GET和 POST区别
1、区别:
get请求无消息体,只能携带少量数据
post请求有消息体,可以携带大量数据
2、携带数据的方式:
get请求将数据放在url地址中
post请求将数据放在消息体中(Body)
GET请求请提交的数据放置在HTTP请求协议头中,而POST提交的数据则放在实体数据中;
GET方式提交的数据最多只能有1024字节,而POST则没有此限制。
HTTP 状态码详解
1xx(临时响应)
2xx(成功)
3xx(重定向)
4xx(请求错误)
5xx(服务器错误)
1xx(临时响应)
100(继续) 请求者应继续进行请求。服务器返回此代码以表示,服务器已收到某项请求的第一部分,正等待接收剩余部分。
101(切换协议) 请求者已要求服务器切换协议,服务器已确认并准备进行切换。
2xx(成功)
200(成功) 说明服务器成功处理了相应请求。通常,这表示服务器已提供了请求的网页。如果您的 robots.txt 文件显示为此状态,则表示 检测工具 已成功检索到该文件。
201(已创建) 请求成功且服务器已创建了新的资源。
202(已接受) 服务器已接受相应请求,但尚未对其进行处理。
203(非授权信息) 服务器已成功处理相应请求,但返回了可能来自另一来源的信息。
204(无内容) 服务器已成功处理相应请求,但未返回任何内容。
205(重置内容) 服务器已成功处理相应请求,但未返回任何内容。与 204 响应不同,此响应要求请求者重置文档视图(例如清除表单内容以输入新内容)。
206(部分内容) 服务器成功处理了部分 GET 请求。
3xx(重定向)
300(多种选择) 服务器可以根据请求来执行多项操作,例如:按照请求者(用户代理)的要求来选择某项操作或者展示列表以便请求者选择其中某项操作。
301(永久移动) 请求的网页已永久移动到新位置。服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。您应使用此代码通知 检测工具 某个网页或网站已被永久移动到新位置
302(临时移动) 服务器目前正从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置。但由于 检测工具 会继续抓取原有位置并将其编入索引,因此您不应使用此代码来通知 检测工具 某个页面或网站已被移动。
303(查看其他位置) 当请求者应对不同的位置进行单独的 GET 请求以检索响应时,服务器会返回此代码。对于除 HEAD 请求之外的所有请求,服务器会自动转到其他位置
304(未修改) 请求的网页自上次请求后再也没有修改过。当服务器返回此响应时,不会返回相关网页的内容。如果网页自请求者上次请求后再也没有更改过,您应当将服务器配置为返回此响应(称为 If-Modified-Since HTTP 标头)。服务器可以告诉 检测工具 自从上次抓取后网页没有变更,进而节省带宽和开销。
305(使用代理) 请求者只能使用代理访问请求的网页。如果服务器返回此响应,那么,服务器还会指明请求者应当使用的代理。
307(临时重定向) 服务器目前正从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置。但由于 检测工具 会继续抓取原有位置并将其编入索引,因此您不应使用此代码来通知 检测工具 某个页面或网站已被移动。
4xx(请求错误)
400(错误请求) 服务器不理解相应请求的语法。
401(未授权) 请求要求进行身份验证。登录后,服务器可能会返回对页面的此响应。
403(已禁止) 服务器正在拒绝相应请求。如果 检测工具 在尝试抓取网站的有效网页时收到此状态代码(您可在网站站长工具中运行工具下的抓取错误页上进行查看),则可能是因为您的服务器或主机正在阻止 检测工具 进行访问。
404(未找到) 服务器找不到请求的网页。例如,如果相应请求是针对服务器上不存在的网页进行的,那么服务器通常会返回此代码。如果您的网站上没有 robots.txt 文件,而您在 网站站长工具中的已拦截的网址页上看到此状态,那么这就是正确的状态。然而,如果您有 robots.txt 文件而又发现了此状态,那么,这说明您的 robots.txt 文件可能是命名错误或位于错误的位置。(该文件应当位于顶级域名上,且应当名为 robots.txt)。
405(方法禁用) 禁用相应请求中所指定的方法。
406(不接受) 无法使用相应请求的内容特性来响应请求的网页。
407(需要代理授权) 此状态代码与 401(未授权)类似,但却指定了请求者应当使用代理进行授权。如果服务器返回此响应,那么,服务器还会指明请求者应当使用的代理。
408(请求超时) 服务器在等待请求时超时。
409(冲突) 服务器在完成请求时遇到冲突。服务器必须在响应中包含该冲突的相关信息。服务器在响应与前一个请求相冲突的 PUT 请求时可能会返回此代码,同时会提供两个请求的差异列表。
410(已删除) 如果请求的资源已被永久删除,那么服务器会返回此响应。该代码与 404(未找到)代码类似,但在资源以前有但现在已经不复存在的情况下,有时会替代 404 代码出现。如果资源已永久删除,您应使用 301 指定资源的新位置。
411(需要有效长度) 服务器不会接受包含无效内容长度标头字段的请求。
412(未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。
413(请求实体过大) 服务器无法处理相应请求,因为请求实体过大,已超出服务器的处理能力。
414(请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法进行处理。
415(不支持的媒体类型) 相应请求的格式不受请求页面的支持。
416(请求范围不符合要求) 如果相应请求是针对网页的无效范围进行的,那么服务器会返回此状态代码。
417(未满足期望值) 服务器未满足“期望”请求标头字段的要求。
5xx(服务器错误)
500(服务器内部错误) 服务器遇到错误,无法完成相应请求。
501(尚未实施) 服务器不具备完成相应请求的功能。例如,当服务器无法识别请求方法时,可能便会返回此代码
502(错误网关) 服务器作为网关或代理,从上游服务器收到了无效的响应。
503(服务不可用) 目前无法使用服务器(由于超载或进行停机维护)。通常,这只是暂时状态。
504(网关超时) 服务器作为网关或代理,未及时从上游服务器接收请求。
505(HTTP 版本不受支持) 服务器不支持相应请求中所用的 HTTP 协议版本。
.
.
TCP与UDP的区别
TCP 是面向连接的,UDP 是面向无连接的
UDP程序结构较简单
TCP 是面向字节流的,UDP 是基于数据报的
TCP 保证数据正确性,UDP 可能丢包
TCP 保证数据顺序,UDP 不保证
什么是面向连接,什么是面向无连接
在互通之前,面向连接的协议会先建立连接,如 TCP 有三次握手,而 UDP 不会
TCP 为什么是可靠连接
- 通过 TCP 连接传输的数据无差错,不丢失,不重复,且按顺序到达。
- TCP 报文头里面的序号能使 TCP 的数据按序到达
- 报文头里面的确认序号能保证不丢包,累计确认及超时重传机制
- TCP 拥有流量控制及拥塞控制的机制
UDP 的主要应用场景
- 需要资源少,网络情况稳定的内网,或者对于丢包不敏感的应用,比如 DHCP 就是基于 UDP 协议的。
- 不需要一对一沟通,建立连接,而是可以广播的应用。因为它不面向连接,所以可以做到一对多,承担广播或者多播的协议。
- 需要处理速度快,可以容忍丢包,但是即使网络拥塞,也毫不退缩,一往无前的时候
基于 UDP 的几个例子
- 直播。直播对实时性的要求比较高,宁可丢包,也不要卡顿的,所以很多直播应用都基于 UDP 实现了自己的视频传输协议
- 实时游戏。游戏的特点也是实时性比较高,在这种情况下,采用自定义的可靠的 UDP 协议,自定义重传策略,能够把产生的延迟降到最低,减少网络问题对游戏造成的影响
- 物联网。一方面,物联网领域中断资源少,很可能知识个很小的嵌入式系统,而维护 TCP 协议的代价太大了;另一方面,物联网对实时性的要求也特别高。比如 Google 旗下的 Nest 简历 Thread Group,推出了物联网通信协议 Thread,就是基于 UDP 协议的
TCP/IP 四层协议
也可参考文章:TCP/IP协议组——完整工作过程分析
应用层
传输层
网络层
数据链路层
(物理层)
2.分层的目的:
(1)将网络的通信过程划分为小一些、简单一些的部件,有助于各个部件的开发、设计和故障排除;
(2)通过网络组件的标准化,允许多个供应商开发,鼓励产业标准化;
(3)允许各种类型的网络硬件和软件相互通信;
(4)防止某一层的改动影响到其它层,有利于开发(主要)。
3.各层的主要协议:
(1)应用层: HTTP(超文本传输协议 80), HTTPS(更安全的超文本传输协议 443), FTP(文件传输协议), SMTP(简单邮件传输协议), DNS(域名服务),ping命令(调试网络环境),OSPF(开放最短路径优先);
应用层处理应用程序的逻辑,且应用层在用户空间。
(2)传输层: UDP(用户数据报协议), TCP(传输控制协议);
传输层采用端到端的通信方式,其中:
UDP:不可靠的,无连接的,基于数据报的协议;
TCP:可靠的,面向连接的,基于字节流的协议;
(3)网络层: IP(因特网协议), ICMP(控制报文协议), ARP(地址解析协议), RARP(反向地址转换协议);
网络层主要实现数据包的选路和转发。
(4)数据链路层: 传输单位是帧,分为逻辑链路控制子层(LLC),媒体访问控制子层(MAC);
数据链路层是网卡接口的驱动程序,处理数据在物理媒介的传输
(5)物理层: 传输单位是比特流
传输的主要介质:集线器、中继器、调制解调器、网线、双绞线、同轴电缆。
1、一次完整的HTTP请求与响应涉及了哪些知识?(包括TCP三次握手和TCP的四次挥手)
TCP 的三次握手 建立连接
所有的问题,首先都要建立连接,所以首先是连接维护的问题
TCP 的建立连接称为三次握手,可以简单理解为下面这种情况
A:您好,我是 A
B:您好 A,我是 B
A:您好 B
至于为什么是三次握手我这里就不细讲了,可以看其他人的博客,总结的话就是通信双方全都有来有回
对于 A 来说它发出请求,并收到了 B 的响应,对于 B 来说它响应了 A 的请求,并且也接收到了响应。
TCP 的三次握手除了建立连接外,主要还是为了沟通 TCP 包的序号问题。
A 告诉 B,我发起的包的序号是从哪个号开始的,B 同样也告诉 A,B 发起的 包的序号是从哪个号开始的。
双方建立连接之后需要共同维护一个状态机,在建立连接的过程中,双方的状态变化时序图如下所示
状态变化时序图

这是网上经常见到的一张图,刚开始的时候,客户端和服务器都处于 CLOSED 状态,先是服务端主动监听某个端口,处于 LISTEN 状态。然后客户端主动发起连接 SYN,之后处于 SYN-SENT 状态。服务端接收了发起的连接,返回 SYN,并且 ACK ( 确认 ) 客户端的 SYN,之后处于 SYN-SENT 状态。客户端接收到服务端发送的 SYN 和 ACK 之后,发送 ACK 的 ACK,之后就处于 ESTAVLISHED 状态,因为它一发一收成功了。服务端收到 ACK 的 ACK 之后,也处于 ESTABLISHED 状态,因为它也一发一收了。
TCP 四次挥手
说完建立连接,再说下断开连接,也被称为四次挥手,可以简单理解如下
A:B 啊,我不想玩了
B:哦,你不想玩了啊,我知道了
这个时候,只是 A 不想玩了,即不再发送数据,但是 B 可能还有未发送完的数据,所以需要等待 B 也主动关闭。
B:A 啊,好吧,我也不玩了,拜拜
A:好的,拜拜
这样整个连接就关闭了,当然上面只是正常的状态,也有些非正常的状态(比如 A 说完不玩了,直接跑路,B 发起的结束得不到 A 的回答,不知道该怎么办或则 B 直接跑路 A 不知道该怎么办),TCP 协议专门设计了几个状态来处理这些非正常状态

断开的时候,当 A 说不玩了,就进入 FIN_WAIT_1 的状态,B 收到 A 不玩了的消息后,进入 CLOSE_WAIT 的状态。
A 收到 B 说知道了,就进入 FIN_WAIT_2 的状态,如果 B 直接跑路,则 A 永远处与这个状态。TCP 协议里面并没有对这个状态的处理,但 Linux 有,可以调整 tcp_fin_timeout 这个参数,设置一个超时时间。
如果 B 没有跑路,A 接收到 B 的不玩了请求之后,从 FIN_WAIT_2 状态结束,按说 A 可以跑路了,但是如果 B 没有接收到 A 跑路的 ACK 呢,就再也接收不到了,所以这时候 A 需要等待一段时间,因为如果 B 没接收到 A 的 ACK 的话会重新发送给 A,所以 A 的等待时间需要足够长。
Linux查看某个特定的文件名路径的命令
find . -name '*.py' #查看以.py结尾的文件路径
#获得所有py文件路径,去重复,删除开头的“./”字符
find . -name '*.py' -exec dirname {} \;
Linux查看日志ERROR出现次数的命令
查找Error日志并统计次数
# 查找Error日志并统计次数
grep -o -E 'ERROR'| sort | uniq -c
查找error日志并存储到指定文件
#查找日志文件testLog.log中的ERROR并将其存储到指定的文件error.log里面
tail -f testLog.log | grep -o -E 'Error' >> error.log
Linux 替换文件内容
sed命令下批量替换文件内容
格式: sed -i “s/查找字段/替换字段/g” grep 查找字段 -rl 路径 文件名
-i 表示inplace edit,就地修改文件
-r 表示搜索子目录
-l 表示输出匹配的文件名
s表示替换,d表示删除
示例:sed -i “s/shan/hua/g” lishan.txt
把当前目录下lishan.txt里的shan都替换为hua
Linux 面试题:
Linux命令,在当前目录的所有log文件中找到包含error单词的行,并把error替换成warn后,存入test文件。(并未实际验证准确性)
tail -f testLog.log | grep -o -E 'Error'| sed -i "s/Error/warn/g" >> test.log
Linux查看文件前几行和后几行的命令
可以使用head(查看前几行)、tail(查看末尾几行)两个命令。例如:
查看/etc/profile的前10行内容,应该是:
head -n 10 /etc/profile
查看/etc/profile的最后5行内容,应该是:
tail -n 5 /etc/profile
如果想同时查看可以将前10行和后5行的显示信息通过输出重定向的方法保存到一个文档,这样查看文档即可一目了然。
例如:
将内容输出到/home/test文件中
head -n 10 /etc/profile >>/home/test
tail -n 5 /etc/profile>>/home/test
tail -f a.log #实时查看日志文件
tail -100f a.log #实时查看日志文件后100行
tail -f -n 100 a.log #查看日志文件后100行
查看的话只需要打开test文件即可。
cat /home/test
【一】从第3000行开始,显示1000行。即显示3000~3999行
cat filename | tail -n +3000 | head -n 1000
【二】显示1000行到3000行
cat filename| head -n 3000 | tail -n +1000
*注意两种方法的顺序
分解:
tail -n 1000:显示最后1000行
tail -n +1000:从1000行开始显示,显示1000行以后的
head -n 1000:显示前面1000行
【三】用sed命令
sed -n '5,10p' filename这样你就可以只查看文件的第5行到第10行。
Linux 查看错误日志的Shell命令:
awk命令:
awk '/ERROR[12]/ {
err1_cnt+=gsub(/ERROR1/, "");
err2_cnt+=gsub(/ERROR2/, "");
}
END {
print err1_cnt, err2_cnt;
}' /tmp/a.log
Linux系统监控命令整理汇总-掌握CPU,内存,磁盘IO等找出性能瓶颈
答案:
例子请点击这里
Linux 压缩与解压命令
压缩
// 将目录里所有jpg文件打包成 tar.jpg
tar –cvf jpg.tar *.jpg
// 将目录里所有jpg文件打包成 jpg.tar 后,
//并且将其用 gzip 压缩,生成一个 gzip 压缩过的包,命名为 jpg.tar.gz
tar –czf jpg.tar.gz *.jpg
// 将目录里所有jpg文件打包成 jpg.tar 后,
//并且将其用 bzip2 压缩,生成一个 bzip2 压缩过的包,命名为jpg.tar.bz2
tar –cjf jpg.tar.bz2 *.jpg
// 将目录里所有 jpg 文件打包成 jpg.tar 后,并且将其用 compress 压缩,生成一个 umcompress 压缩过的包,命名为jpg.tar.Z
tar –cZf jpg.tar.Z *.jpg
// rar格式的压缩,需要先下载 rar for linux
rar a jpg.rar *.jpg
// zip格式的压缩,需要先下载 zip for linux
zip jpg.zip *.jpg
解压
tar –xvf file.tar // 解压 tar 包
tar -xzvf file.tar.gz // 解压 tar.gz
tar -xjvf file.tar.bz2 // 解压 tar.bz2
tar –xZvf file.tar.Z // 解压 tar.Z
unrar e file.rar // 解压 rar
unzip file.zip // 解压 zip
总结
1、*.tar 用 tar –xvf 解压
2、*.gz 用 gzip -d或者gunzip 解压
3、*.tar.gz和*.tgz 用 tar –xzf 解压
4、*.bz2 用 bzip2 -d或者用bunzip2 解压
5、*.tar.bz2用tar –xjf 解压
6、*.Z 用 uncompress 解压
7、*.tar.Z 用tar –xZf 解压
8、*.rar 用 unrar e解压
9、*.zip 用 unzip 解压
Java系列
题目要求:给定一个字符串数组,判断每个字符出现多少次?
解决思路: 利用Map的特性:即Map集合中如果两个key(键)值是一样相同的,那么,后放(put)入的值会将前面存在的value(值)替换掉,也就是覆盖了前面的value。
所以把字符数组中的字符当作key,每遇到相同的key,value值加1即可。代码如下:
public class HsahMapTest{
/**
* 给定一个字符串数组,判断其中每个字符出现了多少次,并打印输出
* @param args
*/
public static void main(String[] args){
HashMap<String,Integer> map = new HashMap<String,Integer>();
String[] str = {"a", "hello", "a", "hello", "b", "c","b"};
for(int i = 0; i < str.length; i ++){
if(map.get(str[i]) == null){
map.put(str[i], 1);
}else{
map.put(str[i], map.get(str[i])+1);
}
}
//遍历map
Set<String> keys = map.keySet();
for(Iterator<String> iter = keys.iterator(); iter.hasNext(); ){
String key = iter.next();
System.out.println(key + "=" + map.get(key));
}
}
}
Java面试题:两个数组合并排序的java实现
Java面试题:两个有序数组合并到一个有序数组(时间复杂度低)
答案:java 两个有序数组合并到一个有序数组(时间复杂度低)
Java面试题:统计一个字符串中最长连续子串
in:aabbbaa
out:aaa
in:abba
out:bb
答案:
package firstJob;
import java.util.ArrayList;
import java.util.List;
public class calMaxLengthSub {
public static void main(String... args) throws Exception {
String str = "010011000011100";
List<String> list = getSubs(str, 0);
list.stream().forEach(s -> System.err.println(s));
}
/**
* 统计连续相同字符的子串
* @param str
* @param idx
* @return
*/
public static List<String> getSubs(String str, int idx) {
List<String> result = new ArrayList<>();
if(str != null) {
int len = str.length();
if(len > 0) {
String sub = subStr(str, idx);
System.err.println("sub => " + sub);
int tLen = sub.length();
if(tLen > 1) {
result.add(sub);
}
if(idx < len - 1) {
int endIdx = idx + tLen;
if(endIdx < len - 1) {
result.addAll(getSubs(str, endIdx));
}
}
}
}
return result;
}
/**
* 获取连续相同字符子串
* @param str
* @param idx
* @return
*/
public static String subStr(String str, int idx) {
char c = str.charAt(idx);
StringBuffer result = new StringBuffer();
result.append(c);
if(idx < str.length() -1) {
if(c == str.charAt(idx + 1)) {
result.append(subStr(str, idx + 1));
}
}
return result.toString();
}
}
Java面试题:编写程序在控制台输出斐波那契数列前20项,每输出5个数换行
参考博文:随风fds
解法一:定义三个变量
public class Demo1 {
// 定义三个变量方法
public static void main(String[] args) {
int a = 1, b = 1, c = 0;
System.out.println("斐波那契数列前20项为:");
System.out.print(a + "\t" + b + "\t");//输出第一二项
//因为前面还有两个1、1 所以i<=18
for (int i = 1; i <= 18; i++) {
c = a + b;
a = b;
b = c;
System.out.print(c + "\t");
if ((i + 2) % 5 == 0)
System.out.println();
}
}
}
解法二:定义数组方法
public class Demo2 {
// 定义数组方法
public static void main(String[] args) {
int arr[] = new int[20];
arr[0] = arr[1] = 1;
for (int i = 2; i < arr.length; i++) {
arr[i] = arr[i - 1] + arr[i - 2];
}
System.out.println("斐波那契数列的前20项如下所示:");
for (int i = 0; i < arr.length; i++) {
if (i % 5 == 0)
System.out.println();
System.out.print(arr[i] + "\t");
}
}
}
解法二:使用递归方法
public class Demo3 {
// 使用递归方法
private static int getFibo(int i) {
if (i == 1 || i == 2)
return 1;
else
return getFibo(i - 1) + getFibo(i - 2);
}
public static void main(String[] args) {
System.out.println("斐波那契数列的前20项为:");
for (int j = 1; j <= 20; j++) {
System.out.print(getFibo(j) + "\t");
if (j % 5 == 0)
System.out.println();
}
}
}
Java面试题:实现斐波那契数列输出指定的第f(n)个
参考博主:瓜牛呱呱
1,1,2,3,5,8,13
输出:
f(2)=2
f(3)=3
思路:
其实很简单,可以理解为:
F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=3,n∈N*)
比如这样一个数列:1、1、2、3、5、8、13、21、34、……
下面我们就来实现,给定一个n,求f(n)的值
解法一:递归解法
递归方法其实是对方法定义完美的一对一实现,但是时间复杂度为O(2的n次方)
通过递归的代码发现,其实有很大一部分是重复算的,如果n趋近于无限大,那么就有一半是重复计算的。
代码如下:
/**
* 采用递归的方式实现的
* 时间复杂度为O(2的N次方)
* @param n
* @return
*/
public static int f1(int n){
if (n == 0){
return 0;
}
if (n == 1){
return 1;
}
return f1(n-1) + f1(n-2);
}
解法二:遍历解法
遍历的方式相比于递归的方式时间复杂度好很多,为O(n)
但是遍历的方式还不是时间复杂度最低的解决方案!更短请看解法三。
代码如下:
/**
* 采用遍历的方式实现
* 时间复杂度为O(N)
* @param n
* @return
*/
public static int f2(int n){
int f0 = 0;
if (n == 0) {
return f0;
}
int f1 = 1;
if (n == 1) {
return f1;
}
int f2 = 0;
for (int i=2; i<=n; i++){
f2 = f0 + f1;
f0 = f1;
f1 = f2;
}
return f2;
}
解法三:矩阵解法
实现的推导原理如下:
数列的递推公式为:f(1)=1,f(2)=2,f(n)=f(n-1)+f(n-2)(n>=3)
用矩阵表示为:

进一步,可以得出直接推导公式:

也有如下的推导(这一块不是很理解,懂的可以帮忙在评论区解释一下哈):

矩阵的解法时间复杂度为O(logn)
代码如下:
/**
* 采用矩阵的解法
* 时间复杂度为O(logN)
* @param n
* @return
*/
public static int f3(int n){
if (n == 0){
return 0;
}
int[][] fbnq = fbnq(n);
return fbnq[0][1];
}
/*矩阵处理核心代码*/
private static final int[][] UNIT = {{1,1}, {1,0}};
private static int[][] fbnq(int n){
if (n == 1){
return UNIT;
}
if (n % 2 == 0){
int[][] matrix = fbnq(n / 2);
return matrixMultiply(matrix, matrix);
}else {
int[][] matrix = fbnq((n-1) / 2);
return matrixMultiply(UNIT, matrixMultiply(matrix, matrix));
}
}
/*矩阵乘法*/
private static int[][] matrixMultiply(int[][] a, int[][] b){
int rows = a.length;
int cols = b[0].length;
int[][] matrix = new int[rows][cols];
for (int i = 0; i < a.length; i++) {
for (int j = 0; j < b[0].length; j++) {
for (int k = 0; k < a[i].length; k++) {
matrix[i][j] += a[i][k] * b[k][j];
}
}
}
return matrix;
}
方法四:利用数组
但是递归算法会增加整个过程的复杂度,例如我要求fib(7)的时候要算fib(6)+fib(5),而fib(6)=fib(5)+fib(4),此时计算机只会非常愚蠢的再算一次fib(5),从而增加了整体的复杂度,所以解决办法是建立一个数组将每次前面算出来的fib(i)进行存储,以免以后造成重复的运算,此时的代码如下:
//利用数组 动态规划实现斐波那契数
public static long dp_fib(long i) {
long[] arr = new long[(int)i];
arr[0] = 1;
arr[1] = 1;
if(i <= 0) return 0;
if(i == 1 || i == 2)
return 1;
else {
int j;
for( j=2;j<i;j++) {
arr[j] = arr[j-1] + arr[j-2];
}
return arr[(int)(i-1)];
}
}
测试上述结果:
public static void main(String[] args) {
//输出前10个数
for (int i = 0; i < 10; i++) {
System.out.println("========"+i+"========");
System.out.println("递归方式:" + f1(i));
System.out.println("遍历方式:" + f2(i));
System.out.println("矩阵二分的方式:" + f3(i));
}
}
Java面试题:输出固定长度n的数字+字母的字符串
package TestDemo;
import java.util.Random;
public class GetNumberWords {
public static void main(String[] args) {
for(int i = 0;i < 10;i++){
String password = getRandomPassword(8);
System.out.println(password);
}
}
//指定长度的随机密码生成
public static String makeRandomPassword(int len){
char charr[] = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890~!@#$%^&*.?".toCharArray();
StringBuilder sb = new StringBuilder();
Random r = new Random();
for (int x = 0; x < len; ++x) {
sb.append(charr[r.nextInt(charr.length)]);
}
return sb.toString();
}
//获取验证过的随机密码
public static String getRandomPassword(int len) {
String result = null;
result = makeRandomPassword(len);
if (result.matches(".*[a-z]{1,}.*") && result.matches(".*[A-Z]{1,}.*") && result.matches(".*[0-9]{1,}.*") && result.matches(".*[~!@#$%^&*\\.?]{1,}.*")) {
return result;
}
return getRandomPassword(len);
}
}
Java面试题:输出9*9乘法表
public static void main(String[] args) {
for(int i=1;i<10;i++) {
for(int j=1;j<=i;j++) {
System.out.print(j+"*"+i+"="+(i*j)+"\t");// \t 跳到下一个TAB位置
}
System.out.println("");
}
输出:
1×1=1
1×2=2 2×2=4
1×3=3 2×3=6 3×3=9
1×4=4 2×4=8 3×4=12 4×4=16
1×5=5 2×5=10 3×5=15 4×5=20 5×5=25
1×6=6 2×6=12 3×6=18 4×6=24 5×6=30 6×6=36
1×7=7 2×7=14 3×7=21 4×7=28 5×7=35 6×7=42 7×7=49
1×8=8 2×8=16 3×8=24 4×8=32 5×8=40 6×8=48 7×8=56 8×8=64
1×9=9 2×9=18 3×9=27 4×9=36 5×9=45 6×9=54 7×9=63 8×9=72 9×9=81
变换一下顺序如下:
public class MultiplicationTable {
public static void main(String[] args) {
for(int i=9;i>0;i--) {
for(int j=1,k=10-i;j<=i;j++,k++) {
System.out.print(j+"×"+k+"="+k*j+"\t");// \t 跳到下一个TAB位置
}
System.out.println();
}
}
}
输出
11=1 22=4 33=9 44=16 55=25 66=36 77=49 88=64 99=81
12=2 23=6 34=12 45=20 56=30 67=42 78=56 89=72
13=3 24=8 35=15 46=24 57=35 68=48 79=63
14=4 25=10 36=18 47=28 58=40 69=54
15=5 26=12 37=21 48=32 59=45
16=6 27=14 38=24 49=36
17=7 28=16 39=27
18=8 29=18
1*9=9
==与equals的区别与联系
== 比较的是变量(栈)内存中存放的对象的(堆)内存地址,用来判断两个对象的地址是否相同,即是否是指相同一个对象。比较的是真正意义上的指针操作。
equals用来比较的是两个对象的内容是否相等,由于所有的类都是继承自java.lang.Object类的,所以适用于所有对象,如果没有对该方法进行覆盖的话,调用的仍然是Object类中的方法,而Object中的equals方法返回的却是== 的判断。
java中的数据类型可以分为两大类:
1、8种基本数据类型
byte, short, char, int, long, float, double, boolean
基本数据类型之间的比较需要用双等号(==),因为他们比较的是值
封装类:Byte, Short, Character, Integer, Long, Float, Double, Boolean
2、引用数据类型
接口、类、数组等非基本数据类型
Java中的字符串String属于引用数据类型。因为String是一个类
equals()方法介绍
Java中所有的类都是继承与Object这个基类的,在Object类中定义了一个equals方法,这个方法的初始行为是比较对象的内存地址,但在一些类库中已经重写了这个方法(一般都是用来比较对象的成员变量值是否相同),比如:String,Integer,Date 等类中,所以他们不再是比较类在堆中的地址了、
Object类中源码
public boolean equals(Object var1) {
return this == var1;
}
String类中重写后的代码
public boolean equals(Object var1) {
if (this == var1) {
return true;
} else {
if (var1 instanceof String) {
String var2 = (String)var1;
int var3 = this.value.length;
if (var3 == var2.value.length) {
char[] var4 = this.value;
char[] var5 = var2.value;
for(int var6 = 0; var3-- != 0; ++var6) {
if (var4[var6] != var5[var6]) {
return false;
}
}
return true;
}
}
return false;
}
}
总结:
对于复合数据类型之加粗样式间进行equals比较,在没有覆写equals方法的情况下,他们之间的比较还是内存中的存放位置的地址值,跟双等号(==)的结果相同;如果被复写,按照复写的要求来。
== 的作用:
基本类型:比较的就是值是否相同
引用类型:比较的就是地址值是否相同
equals 的作用:
引用类型:默认情况下,比较的是地址值,重写该方法后比较对象的成员变量值是否相同。
以上内容来自博主 流逝的青春
Java实现两个字符串的比较
JAVA中字符串比较equals是用来比较字符串是否相等的,==比较是否为相同reference,不能用做字符串的比较.如果要比较大小应该用compareto(String),它是依次比较字符串的每个字符的大小。
字符串常用的比较如下:
equals() //作用:比较值
equalsIgnoreCase() //作用:比较值,不区分大小
regionMatches() //判断string的子串是否相同
compareTo() //作用:按字典顺序比较两个字符串
contains() //作用:包含
Java重写与重载的区别
1.重写(Override)
从字面上看,重写就是 重新写一遍的意思。其实就是在子类中把父类本身有的方法重新写一遍。子类继承了父类原有的方法,但有时子类并不想原封不动的继承父类中的某个方法,所以在方法名,参数列表,返回类型(除过子类中方法的返回值是父类中方法返回值的子类时)都相同的情况下, 对方法体进行修改或重写,这就是重写。但要注意子类函数的访问修饰权限不能少于父类的。
例如:
public class Father {
public static void main(String[] args) {
// TODO Auto-generated method stub
Son s = new Son();
s.sayHello();
}
public void sayHello() {
System.out.println("Hello");
}
}
class Son extends Father{
@Override
public void sayHello() {
// TODO Auto-generated method stub
System.out.println("hello by ");
}
}
重写 总结:
- 发生在父类与子类之间
- 方法名,参数列表,返回类型(除过子类中方法的返回类型是父类中返回类型的子类)必须相同
- 访问修饰符的限制一定要大于被重写方法的访问修饰符(public>protected>default>private)
- 重写方法一定不能抛出新的检查异常或者比被重写方法申明更加宽泛的检查型异常
2.重载(Overload)
在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同甚至是参数顺序不同)则视为重载。同时,重载对返回类型没有要求,可以相同也可以不同,但不能通过返回类型是否相同来判断重载。
例如:
public class Father {
public static void main(String[] args) {
// TODO Auto-generated method stub
Father s = new Father();
s.sayHello();
s.sayHello("wintershii");
}
public void sayHello() {
System.out.println("Hello");
}
public void sayHello(String name) {
System.out.println("Hello" + " " + name);
}
}
重载 总结:
- 重载Overload是一个类中多态性的一种表现
- 重载要求同名方法的参数列表不同(参数类型,参数个数甚至是参数顺序)
- 重载的时候,返回值类型可以相同也可以不相同。无法以返回型别作为重载函数的区分标准
Java - 面试时,问:重载(Overload)和重写(Override)的区别?
答:方法的重载和重写都是实现多态的方式
区别在于重载实现的是编译时的多态性,而重写实现的是运行时的多态性。
重载发生在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)则视为重载;
重写发生在子类与父类之间,重写要求子类被重写方法与父类被重写方法有相同的参数列表,有兼容的返回类型,比父类被重写方法更好访问,不能比父类被重写方法声明更多的异常(里氏代换原则)。重载对返回类型没有特殊的要求,不能根据返回类型进行区分。
浅谈JDK、JRE、JVM区别与联系
JDK是 Java 语言的软件开发工具包(SDK)。在JDK的安装目录下有一个jre目录,里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需要的类库,而jvm和 lib合起来就称为jre。
一、JDK
JDK(Java Development Kit) 是整个JAVA的核心,包括了Java运行环境(Java Runtime Envirnment),一堆Java工具(javac/java/jdb等)和Java基础的类库(即Java API 包括rt.jar)。
JDK是java开发工具包,基本上每个学java的人都会先在机器 上装一个JDK,那他都包含哪几部分呢?在目录下面有 六个文件夹、一个src类库源码压缩包、和其他几个声明文件。其中,真正在运行java时起作用的 是以下四个文件夹:bin、include、lib、 jre。有这样一个关系,JDK包含JRE,而JRE包 含JVM。
bin: 最主要的是编译器(javac.exe)
include:java和JVM交互用的头文件
lib:类库
jre:java运行环境
(注意:这里的bin、lib文件夹和jre里的bin、lib是 不同的)
总的来说JDK是用于java程序的开发,而jre则是只能运行class而没有编译的功能。
二、JRE
JRE(Java Runtime Environment,Java运行环境),包含JVM标准实现及Java核心类库。JRE是Java运行环境,并不是一个开发环境,所以没有包含任何开发工具(如编译器和调试器)
JRE是指java运行环境。光有JVM还不能成class的 执行,因为在解释class的时候JVM需要调用解释所需要的类库lib。 (jre里有运行.class的java.exe)
JRE ( Java Runtime Environment ),是运行 Java 程序必不可少的(除非用其他一些编译环境编译成.exe可执行文件……),JRE的 地位就象一台PC机一样,我们写好的Win64应用程序需要操作系统帮 我们运行,同样的,我们编写的Java程序也必须要JRE才能运行。
三、JVM
JVM(Java Virtual Machine),即java虚拟机, java运行时的环境,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。针对java用户,也就是拥有可运行的.class文件包(jar或者war)的用户。里面主要包含了jvm和java运行时基本类库(rt.jar)。rt.jar可以简单粗暴地理解为:它就是java源码编译成的jar包。Java虚拟机在执行字节码时,把字节码解释成具体平台上的机器指令执行。这就是Java的能够“一次编译,到处运行”的原因。
四、JDK、JRE、JVM三者的联系与区别
1.三者联系:
JVM不能单独搞定class的执行,解释class的时候JVM需要调用解释所需要的类库lib。在JDK下面的的jre目录里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需要的类库,而jvm和 lib和起来就称为jre。JVM+Lib=JRE。总体来说就是,我们利用JDK(调用JAVA API)开发了属于我们自己的JAVA程序后,通过JDK中的编译程序(javac)将我们的文本java文件编译成JAVA字节码,在JRE上运行这些JAVA字节码,JVM解析这些字节码,映射到CPU指令集或OS的系统调用。
2.三者区别:
a.JDK和JRE区别:在bin文件夹下会发现,JDK有javac.exe而JRE里面没有,javac指令是用来将java文件编译成class文件的,这是开发者需要的,而用户(只需要运行的人)是不需要的。JDK还有jar.exe, javadoc.exe等等用于开发的可执行指令文件。这也证实了一个是开发环境,一个是运行环境。
b.JRE和JVM区别:JVM并不代表就可以执行class了,JVM执行.class还需要JRE下的lib类库的支持,尤其是rt.jar。
经典SQL面试题
sql查询:部门工资前三高的员工和部门工资最高的员工
创建表:
Create table If Not Exists Employee (Id int, Name varchar(255), Salary int, DepartmentId int);
Create table If Not Exists Department (Id int, Name varchar(255));
Truncate table Employee;
insert into Employee (Id, Name, Salary,DepartmentId) values (‘1’, ‘Joe’, ‘70000’, ‘1’);
insert into Employee (Id, Name, Salary,DepartmentId) values (‘2’, ‘Henry’, ‘80000’, ‘2’);
insert into Employee (Id, Name, Salary,DepartmentId) values (‘3’, ‘Sam’, ‘60000’, ‘2’);
insert into Employee (Id, Name, Salary,DepartmentId) values (‘4’, ‘Max’, ‘90000’, ‘1’);
insert into Employee (Id, Name, Salary,DepartmentId) values (‘5’, ‘Randy’, ‘85000’, ‘1’);
Truncate table Department;
insert into Department (Id, Name) values(‘1’, ‘IT’);
insert into Department (Id, Name) values(‘2’, ‘Sales’);
部门工资前三高的员工
Employee 表包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id 。
±-----±------±-------±-------------+
| Id | Name | Salary | DepartmentId |
±-----±------±-------±-------------+
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Randy | 85000 | 1 |
±-----±------±-------±-------------+
Department 表包含公司所有部门的信息。
±—±---------+
| Id | Name |
±—±---------+
| 1 | IT |
| 2 | Sales |
±—±---------+
SQL题目: 编写一个 SQL 查询,找出每个部门工资前三高的员工。例如,根据上述给定的表格,查询结果应返回:
±-----------±---------±-------+
| Department | Employee | Salary |
±-----------±---------±-------+
| IT | Max | 90000 |
| IT | Randy | 85000 |
| IT | Joe | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
±-----------±---------±-------+
答案:
SELECT Department.Name AS Department, e1.Name AS Employee, e1.Salary AS Salary
FROM Employee e1
JOIN Department
ON e1.DepartmentId = Department.Id
WHERE 3 > (
SELECT COUNT(DISTINCT e2.Salary)
FROM Employee e2
WHERE e2.Salary > e1.Salary AND e1.DepartmentId = e2.DepartmentId
)
ORDER BY Department.Name, e1.Salary DESC
解析:
不妨假设e1=e2=[6,5,4,3],则子查询的过程如下:
1、e1.Salary=3;则e2.Salary可以取4、5、6;COUNT(DISTINCT e2.Salary)=3
2、e1.Salary=4;则e2.Salary可以取5、6;COUNT(DISTINCT e2.Salary)=2
3、e1.Salary=5;则e2.Salary可以取6;COUNT(DISTINCT e2.Salary)=1
4、e1.Salary=6;则e2.Salary无法取值;COUNT(DISTINCT e2.Salary)=0
则要令COUNT(DISTINCT e2.Salary) < 3 的情况有上述的4、3、2.
也即是说,这等价于取e1.Salary最大的三个值。
查询部门工资最高的员工:
方法1:
select d.Name as Department,e.Name as Employee,e.Salary
from Department d,Employee e
where e.DepartmentId=d.Id and
e.Salary=(Select max(Salary) from Employee where DepartmentId=d.Id)
方法2:
select d.Name as Department,e.Name as Employee,Salary
from Employee e join Department d on e.DepartmentId=d.Id
where (e.Salary,e.DepartmentId) in (select max(Salary),DepartmentId from Employee group by DepartmentId)
SQL 查询数据
–1.学生表
Student(S#,Sname,Sage,Ssex) --S# 学生编号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别
–2.课程表
Course(C#,Cname,T#) --C# --课程编号,Cname 课程名称,T# 教师编号
–3.教师表
Teacher(T#,Tname) --T# 教师编号,Tname 教师姓名
–4.成绩表
SC(S#,C#,score) --S# 学生编号,C# 课程编号,score 分数
*/
–创建测试数据
create table Student(S# varchar(10),Sname nvarchar(10),Sage datetime,Ssex nvarchar(10))
insert into Student values('01' , N'赵雷' , '1990-01-01' , N'男')
insert into Student values('02' , N'钱电' , '1990-12-21' , N'男')
insert into Student values('03' , N'孙风' , '1990-05-20' , N'男')
insert into Student values('04' , N'李云' , '1990-08-06' , N'男')
insert into Student values('05' , N'周梅' , '1991-12-01' , N'女')
insert into Student values('06' , N'吴兰' , '1992-03-01' , N'女')
insert into Student values('07' , N'郑竹' , '1989-07-01' , N'女')
insert into Student values('08' , N'王菊' , '1990-01-20' , N'女')
create table Course(C# varchar(10),Cname nvarchar(10),T# varchar(10))
insert into Course values('01' , N'语文' , '02')
insert into Course values('02' , N'数学' , '01')
insert into Course values('03' , N'英语' , '03')
create table Teacher(T# varchar(10),Tname nvarchar(10))
insert into Teacher values('01' , N'张三')
insert into Teacher values('02' , N'李四')
insert into Teacher values('03' , N'王五')
create table SC(S# varchar(10),C# varchar(10),score decimal(18,1))
insert into SC values('01' , '01' , 80)
insert into SC values('01' , '02' , 90)
insert into SC values('01' , '03' , 99)
insert into SC values('02' , '01' , 70)
insert into SC values('02' , '02' , 60)
insert into SC values('02' , '03' , 80)
insert into SC values('03' , '01' , 80)
insert into SC values('03' , '02' , 80)
insert into SC values('03' , '03' , 80)
insert into SC values('04' , '01' , 50)
insert into SC values('04' , '02' , 30)
insert into SC values('04' , '03' , 20)
insert into SC values('05' , '01' , 76)
insert into SC values('05' , '02' , 87)
insert into SC values('06' , '01' , 31)
insert into SC values('06' , '03' , 34)
insert into SC values('07' , '02' , 89)
insert into SC values('07' , '03' , 98)
1、查询“01”课程比“02”课程成绩高的所有学生的学号;
select a.S#,a.score,b.score from
(select * from SC where SC.C#='01') a,
(select * from SC where SC.C#='02') b
where a.score>b.score and a.S#=b.S#
2、查询平均成绩大于60分的同学的学号和平均成绩;
select SC.S#,AVG(SC.score) avgScore from SC
group by SC.S#
having AVG(SC.score)>60
3、查询所有同学的学号、姓名、选课数、总成绩;
select SC.S#,Student.Sname,COUNT(SC.C#) 选课数, AVG(SC.score) 平均分
from SC left join Student on SC.S#=Student.S#
group by SC.S#,Student.Sname
order by SC.S#
4、查询姓“李”的老师的个数;
select COUNT(distinct(Teacher.TName)) from Teacher
where Teacher.Tname like '李%'
5、查询没学过“叶平”老师课的同学的学号、姓名;
select Student.S#,Student.Sname from Student
where Student.S# not in(
select SC.S# from Course,SC,Teacher
where SC.C#=Course.C# and Teacher.T#=Course.T# and Teacher.Tname='叶平'
)
6、查询学过“01”并且也学过编号“02”课程的同学的学号、姓名;
select *, Student.S#,Student.Sname from Student left join SC on Student.S#=SC.S#
where SC.C# ='01' and exists (
select * from SC SC_1 where SC_1.S#=Student.S# and SC_1.C#='02'
)
7、查询没有学全所有课的同学的学号、姓名;
select Student.S#,Student.Sname from Student,SC
where Student.S#=SC.S#
group by Student.S#,Student.Sname
having COUNT(SC.C#)< (select COUNT(Course.C#) from Course)
测试用例设计经典面试题——电梯,杯子,笔,桌子,洗衣机
例子请点击这里
首先说明的是,遇到这样的测试题目,首先应该反问面试官,需求是什么样的,比如是测什么样的杯子。
因为设计测试用例的规则应该是根据需求分析文档设计用例,客户需求什么,就测试什么。但是在没有需求分析文档的前提下, 来设计测试用例,可以考查一个测试人员的基本功,比如考虑问题是否全面,设计测试用例的方法是否合理等。一般是根据自己的日常经验和测试的思维来设计测试用例。在设计测试用例时一般从以下几个方面进行分析:功能测试,性能测试,界面测试,安全性测试,兼容性测试,可用性测试,可靠性测试,本地化/国际化测试。
1、测试项目——电梯
需求测试:查看电梯使用说明书,安全说明书等。
功能测试:
1、上升键和下降键,电梯的楼层按钮是否正常;
2、开关键是否正常,报警装置是否安装,报警电话是否可用;
3、通风状况如何,是否有手机信号;
4、在电梯上升过程中的测试,比如电梯在1楼,有人按了18楼,在上升到5楼的时候,有人按了10楼,电梯会不会停;
5、在电梯下降过程中的测试,比如电梯下降到10层时显示满员,若有人在5楼等待,此时还会不会停。
压力测试:
看电梯的最大承重重量,在电梯超重时,报警装置是否启用,在一定时间内让电梯连续的上升和下降,看在最大负载条件下平稳运行的时间。
界面测试:
查看电梯的外观,电梯的按钮是否好用(开和关按钮设计的图标不容易区分),电梯的说明书是否有错别字。
可用性测试:
电梯的按钮是否符合人的使用习惯。
用户文档:
使用手册是否对电梯的使用,限制等有描述。
2、测试项目——杯子
需求测试:查看杯子的使用说明书,安全说明书等。
功能测试:
1、杯子能否装水;
2、可以装多少L的水;
3、杯子是否可以放冰箱;
4、水可不可以被喝到。
安全性测试:
1、杯子有没有毒和细菌;
2、杯子从高处坠落,是否已破;
3、杯子是否有缺口,容易滑倒嘴巴;
4、将杯子放入微波炉中,是否爆炸或融化;
性能测试:
1、看杯子能够容纳的最大体积和最高温度;
2、将杯子盛上水,经过24小时后查看杯子的泄露情况和时间(可分别使用水和汽油做测试);
3、将杯子装上填充物,看不会摔破的最高度;
4、用根针并在针上面不断加重量,看压强多大时会穿透;
可用性测试:杯子是否好拿,是否烫手,是否防滑,是否方便饮用。
兼容性测试:除了装水,是否还可以装其它的液体,比如果汁,汽油等。
界面测试:查看杯子的外观:杯子是什么材质的,颜色,外形,重量,图案是否合理,是否有异味。
用户文档:使用手册是否对杯子的用法、限制、使用条件等有详细描述。
3、测试项目——笔
1、需求测试:查看使用说明书。
2、功能测试:能不能写字 。
3、界面测试:查看笔的外观 。
4、可靠性:笔从不同高度落下摔坏的程度。
5、安全性:笔有没有毒或细菌 。
6、可移植性:笔在不同的纸质、温度等环境下是否可以使用。
7、兼容性:笔是否可以装不同颜色、大小的笔芯 。
8、易用性:是否方便使用、方便携带 。
9、压力测试:给笔不断的增加重力,观察压力多大时压坏。
10、震动测试:笔在包装时,各面震动,检查是否能应对恶劣的公路、铁路、航空运输。
11、跌落测试:笔包装时,在多高的情况下摔不坏。
4、测试项目——桌子
需求测试:查看桌子相关的使用说明书。
功能测试:桌子是办公用的还是防治东西用的,桌子的面积大小是否适合;
界面测试:桌子的桌面是否平滑,有没有凹凸不平的地方;
安全性测试:桌子的支撑点是否可靠;将桌子推倒后,它的损坏情况;
压力测试:桌子可以承受的重量;
可用性测试:桌子是否好移动;它的重量是否合适;
5、测试项目——洗衣机
需求测试:查看洗衣机的使用说明书。
功能测试:洗衣机是否正常的洗衣服;
安全性测试:洗衣机是否漏电;
兼容性测试:除了洗衣服是否还可以洗其它的;
性能测试:使用时电量如何,是否满足客户需求;加到一定量的衣服后,过一段时间,看洗衣机是否正常洗;通过逐步增加系统负 载,最终确定在什么负载条件下系统性能将处于崩溃状态,以此获得系统能提供的最大服务
界面测试:洗衣机的外观是否符合用户的需求;
可用性测试:洗衣机的操作是否简单已操作;
等价类划分–三角形测试用例设计
性能测试
JMeter学习 内存溢出解决方法
1、windows环境下,修改jmeter.bat:
set HEAP=-Xms256m -Xmx256m
set NEW=-XX:NewSize=128m -XX:MaxNewSize=128m
改为:
set HEAP=-Xms256m -Xmx1024m
set NEW=-XX:NewSize=128m -XX:MaxNewSize=512m
根据经验,heap最多设置为物理内存的一半,默认设置为512M.如果heap超过物理内存的一半,可能运行jmeter会慢,甚至出现内存溢出,原因java比较吃内存,占CPU.
注意: JDK32位的电脑Xmx不能超过1500m,最大1378m.否则在启动Jmeter时会报错:
2、linux环境下,修改jmeter.sh:
java $JVM_ARGS -Xms1G -Xmx5G -XX:MaxPermSize=512m -Dapple.laf.useScreenMenuBar=true -jar dirname $0/ApacheJMeter.jar “$@”
微众银行面试
1、Linux基础命令?如何查看Error日志?如何查看日志中出现Error的次数?
2、Java笔试题
3、说说Java的重载与重写的区别
3、说说你自己的项目;然后从项目中挑选一些问题。
4、当你遇到测试任务与上线时间冲突的时候,如何面对?
5、你是如何在工作中提高工作效率的?
6、为什么离职?
7、你对我司的了解如何,说说看;你对我司的期待如何?
8、说说你的测试流程;说说你的自动化测试流程。
10、HTTP和HTTPS的区别
11、你常用的HTTP请求类型有哪些?简单说说他们之间的区别(比如GET和POST)
数据结构部分
堆、队列、栈的区别
队列(Queue): 是限定只能在表的一端进行插入和在另一端进行删除操作的线性表;
栈(Stack): 是限定只能在表的一端进行插入和删除操作的线性表。
区别:
一、规则不同
1. 队列:先进先出(First In First Out)FIFO
队列 就像一条路,有一个入口和一个出口,先进去的就可以先出去。
2. 栈:先进后出(First In Last Out )FILO
栈就像一个箱子,后放的在上边,所以后进先出
二、对插入和删除操作的限定不同
1. 队列:只能在表的一端进行插入,并在表的另一端进行删除;
2. 栈:只能在表的一端插入和删除。
三、遍历数据速度不同
1. 队列:基于地址指针进行遍历,而且可以从头部或者尾部进行遍历,但不能同时遍历,无需开辟空间,因为在遍历的过程中不影响数据结构,所以遍历速度要快;
2. 栈:只能从顶部取数据,也就是说最先进入栈底的,需要遍历整个栈才能取出来,而且在遍历数据的同时需要为数据开辟临时空间,保持数据在遍历前的一致性。
深信服软件测试岗面试:
https://blog.csdn.net/xp731574722/article/details/82868560
https://zhuanlan.zhihu.com/p/346173389
1、面向对象编程与面向过程编程的区别
2、Java的特性:抽象,继承,封装,多态
3、冒泡排序过程
4、测试一个数字输入框,可输入的数字是5-10,说说你的测试思路。
5、静态路由与动态路由的区别(原理)
静态路由以及动态路由的区别
- 1、静态路由是指由网络管理员手工配置的路由信息。当网络的拓扑结构或链路的状态发生变化时,网络管理员需要手工去修改路由表中相关的静态路由信息。静态路由信息在缺省情况下是私有的,不会传递给其他的路由器。当然,网管员也可以通过对路由器进行设置使之成为共享的。静态路由一般适用于比较简单的网络环境,在这样的环境中,网络管理员易于清楚地了解网络的拓扑结构,便于设置正确的路由信息。
静态路由:安全,占用带宽小,简单,高效,转发效率高;一般用于网络规模不大、拓扑结构固定的网络中。 - 2、动态路由是指路由器能够自动地建立自己的路由表,并且能够根据实际实际情况的变化适时地进行调整。动态路由机制的运作依赖路由器的两个基本功能:对路由表的维护;路由器之间适时的路由信息交换。
动态路由:灵活性高;适用于网络规模大、网络拓扑复杂的网络。
6、TCP的连接是如何实现的?
(如上)
7、安全测试的SQL注入是怎么实现的?
https://www.jianshu.com/p/078df7a35671
8、Java设计模式,单例模式,工厂模式
http://c.biancheng.net/view/1338.html
9、linux 查找文件名,查看日志,查看CPU
(如上)
TCL智能电视事业部测试工程师面试题
1、从您的实际工作案例中阐述,您是如何解决软件测试“杀虫剂”现象的?
PS 以下仅供参考
“【杀虫剂”现象存在是因为测试人员个体之间的差异性导致的思维方式差异,测试人员往往容易陷入一种惯性思维,所以测试人员编写测试用例的时就会存在一些局限性。
结合我的实际工作,我认为做到以下几点可以尽可能的避免“杀虫剂”现象:
1)、首先了解清楚业务需求和功能,在需求评审阶段就带领测试人员介入其中,第一时间掌握需求情况;
2)、测试人员定期评审测试用例:包括测试人员之间,以迭代周期或产品测试周期为准;每个月与开发和PO进行用例评审;
3)、借用“结对编程”的概念,同一个产品模块的测试任务让多个测试人员交叉领取测试任务,比如一个模块的开发往往细分为多个开发Tickets,让不同的QA一起负责该模块的测试。
4)、重要功能逻辑提测通过后尽可能让PO再次确认其是否满足需求;
5)、测试人员需要维护用例,根据产品设计和功能需求的更新而进行相应的维护。】
2、‘能够发现难以发现的缺陷的测试用例才是好的测试用例’,结合您的实际工作,是否认同,为什么?
PS 以下仅供参考
【不认同。
我们编写的测试用例包括正/反向测试:等价类划分、边界值分析、错误推断等,并不是所有的测试用例都能够发现软件缺陷,也不能说没发现缺陷的测试用例就不是好的测试用例;编写好的测试用例,应该按照设计测试用例的方法结合实际项目去覆盖到软件产品的功能和需求。】
3、请阐述一个软件漏测事故,并写出此事故给你带来的启迪。
PS 以下仅供参考
事故:跟日期相关的产品在2月29号的时候异常,4年才会出现一次,漏测。
启迪:测试用例设计覆盖不全;漏测是不可避免的,在整个软件项目过程中,或多或少都会遇到漏测事故,为了避免更多类似情况的发生,我们有建立统一的漏测事故记录,出现漏测之后与组员进行分享,一起改进后续的测试流程。
【漏测原因主要集中在:
1)需求不明确,导致用例不精确;
2)需求变更,测试用例未及时更新;
3)设计测试用例是场景覆盖不全,漏测;
4)测试时间不足,无法覆盖更多的细节测试;
解决:
团队进行需求评审和测试用例评审;】
4、画出软件测试流程图,拍照上传附件。
5、请具体说明您上传的测试流程不足之处,以及改进建议。
PS 以下仅供参考
【在用例设计、评审、执行阶段可能会出现需要再次确认需求的情况,需要再次重新与需求人员进行需求确认,而提高测试覆盖度。】
6、在测试用例中编写UI的绝对路径,例如: 文件->设置->高级->保存账号,这样写的优缺点是什么,遇到这种情况你如何来设计?
PS 以下仅供参考
【优点:绝对路径精准定位,一目了然;
缺点:复用性差;一旦位置发生改变,但功能不变,就得对应进行维护。
设计思路:
根据该功能的属性,需求和设计是否会存在经常变动:
如果UI界面位置固定不变,使用绝对路径;
如果UI界面位置会经常发生改动,使用相对路径。】
7、python基础面试题:python 列表 a=[1,2,3,4,5,6,7],将列表a的值赋值给列表b,在不影响列表a的情况下,将列表b的值每间隔一个元素替换成6,请写代码实现?
a = [1,2,3,4,5,6,7]
b = []
for i in a:
if i%2==0:
i=6
b.append(i)
else:
b.append(i)
print(a)
print(b)
8、Python基础面试题:让用户输入用户名密码,成功打印欢迎信息,输错提示还剩几次机会,三次机会仍然错误推出程序,请代码实现?
user='peter zhang'
pwd='szTCL666'
count = 0
for i in range(3):
username=input("UserName:")
password=input('PassWord:')
if username == user and password == pwd:
print("欢迎登陆TCL, Peter!")
count = 3
break;
else:
print('您输入的用户名或密码错误,请仔细检查!')
count += 1
print("你还可以尝试",2-i,"次")
实用:python中求2个字符串的最长公共子串
s1 = 'abcdefg'
s2 = 'cdefghi'
def fn(s1,s2):
if len(s1) < len(s2):
s1,s2 = s2,s1
maxstr = s1
substr_maxlen = max(len(s1),len(s2))
for sublen in range(substr_maxlen,-1,-1):
for i in range(substr_maxlen-sublen+1):
if maxstr[i:i+sublen] in s2:
return maxstr[i:i+sublen]
fn(s1,s2)
Python编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 “”。
示例 1:
输入: [“flower”,“flow”,“flight”]
输出: “fl”
示例 2:
输入: [“dog”,“racecar”,“car”]
输出: “”
解释: 输入不存在公共前缀。
说明:所有输入只包含小写字母 a-z 。
def longestCommonPrefix(strs):
"""
:type strs: List[str]
:rtype: str
"""
if not strs:
return ''
s1 = min(strs)
s2 = max(strs)
for i, c in enumerate(s1):
if c != s2[i]:
return s1[:i]
return s1
Python实现一个函数,功能如下:
输入一个字符串、一个前缀、一个后缀,返回字符串中以【前缀开头+后缀结尾的所有子串】
原型:def query_substring(string,prefix,postfix)
例如:输入abxxb,a,b,返回[ab,abxxb]
例如:输入xxabbxx,a,b,返回[ab,abb]
def query_substring(str, prefix, postfix):
#print(str)
substr_len = len(str)
for i in range(substr_len,-1,-1):
for j in range(substr_len-i+1):
strr = str[j:i+j]
if strr.startswith(prefix) and strr.endswith(postfix):
print(strr)
return strr
if __name__ == '__main__':
str = "xxabbxx"
prefix = 'a'
postfix = 'b'
query_substring(str, prefix, postfix)
冒泡排序
冒泡排序原理:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较
Python实现:
def bubble_sort(nums):
for i in range(len(nums) - 1): # 这个循环负责设置冒泡排序进行的次数
for j in range(len(nums) - i - 1): # j为列表下标
if nums[j] > nums[j + 1]:
nums[j], nums[j + 1] = nums[j + 1], nums[j]
return nums
print(bubble_sort([45, 32, 8, 33, 12, 22, 19, 97]))
# 输出:[8, 12, 19, 22, 32, 33, 45, 97]
Java实现
public static void bubbleSort(int arr[]) {
for(int i =0 ; i<arr.length-1 ; i++) {
for(int j=0 ; j<arr.length-1-i ; j++) {
if(arr[j]>arr[j+1]) {
int temp = arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
}
Java面试题:
给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。 不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。
思路:
- 如果数组长度为0或者为1 ,直接返回数字长度;
- 定义一个临时变量temp和一个计数器k(这个k就代表不重复的数字的个数,从1开始计数),初始值为nums [ 0 ] ,循环比较temp和nums[i],假设nums [ i ]不等于temp,说明下标位于0~i-1之间的数字等于nums[0],把nums[i]赋给temp和nums[k],k自增
class Solution {
public int removeDuplicates(int[] nums) {
if(nums.length ==0 || nums.length == 1) {
return nums.length;
}
int temp = nums[0];
int k=1;
for(int i=1;i<nums.length;i++) {
if(temp != nums[i]) {
temp = nums[i];
nums[k] = nums[i];
k++;
}
}
return k;
}
}
明源云链笔试题:
1、SQL基础:student(学生表)、class(班级表)结构如下、其中class表的主键id是student表c_id的外键:
Student(学生表):
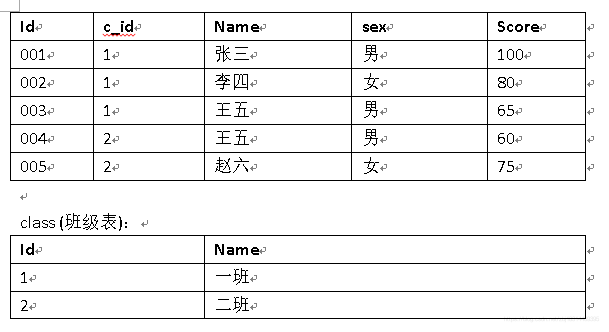
1.1 查询一班得分在80分以上的学生:
SELECT * FROM student WHERE Score>80 AND c_id in (SELECT id FROM class WHERE Name='一班')
#优化
SELECT * FROM student AS s, class AS c WHERE s.c_id=c.id AND s.score>80 AND c.name='一班'
1.2 用一条SQL语句查询出各个班级的男生人数和平均分:
SELECT c.id, c.name, count(1) AS man_count, avg(score) AS avg_score
FROM student AS s, class AS c
WHERE s.c_id=c.c_id AND sex='男'
GROUP BY c.id, c.name
2、接口测试题:接口测试中依赖登录状态的接口是如何测试的?
通常是使用Cookies/Token来验证登录态,在测试这类接口时需要获取Cookie/Token然后再依次进行后续接口的测试事实上也就是上下接口的数据依赖,只不过依赖的数据是Cookies/Token。
- 1、如果已知的登陆接口,那就直接使用登录接口来获取Cookies/Token,已被后续接口的测试使用。
- 2、比如使用JMeter TokenbasedAuth等,或者是添加中间变量来进行存储;使用Postman的话是创建环境变量或者全局变量,使用Pre-script通过代码来获取已经存储的变量。
- 3、如果是未知登陆接口的话可以通过抓包来获取Cookie/Token。
3、根据下面的报表完成下面的题目:
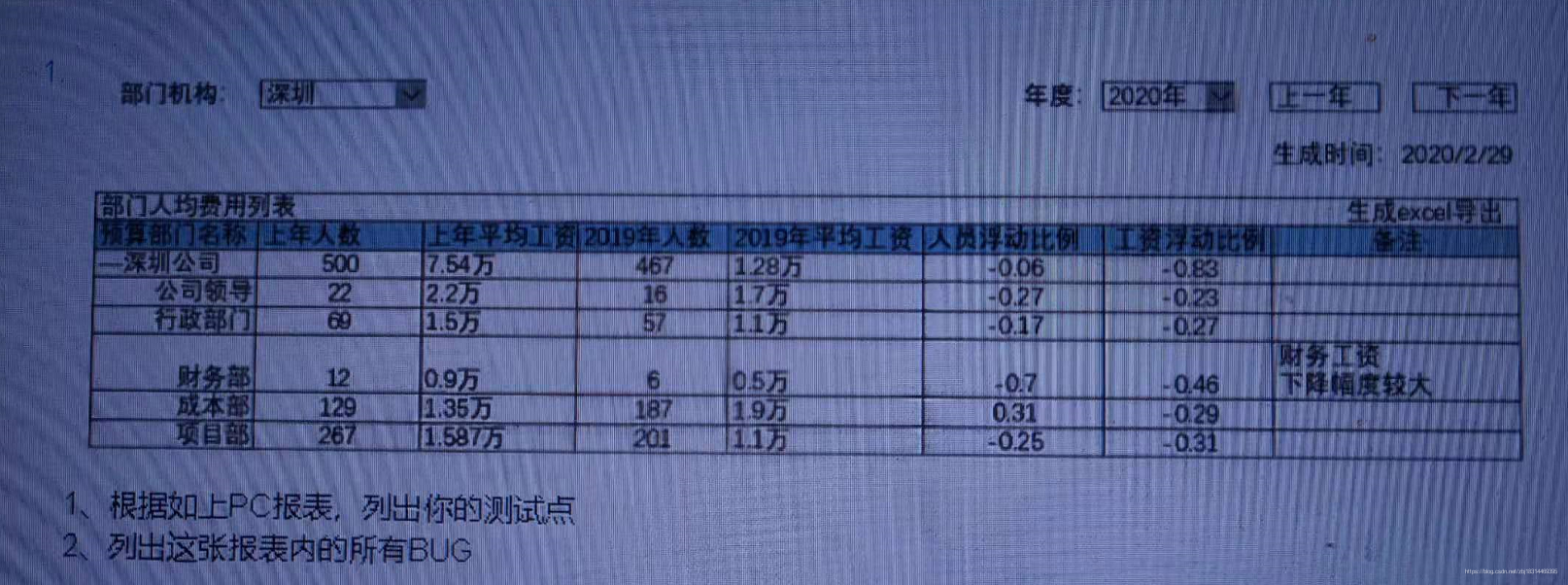
3.1 根据如上的PC报表,列出你的测试点。

3.2 列出这张报表内所有的BUG点。
- a、时间显示错误,年度选框显示2020年,表头显示2019
- b、若“生成Excel导出”是一个功能按钮,则为UI显示错误。
- c、“上年人数”与“2019年人数”与“人员浮动比”三列不在一起;“上年平均工资”列与“浮动比”三列不在一起;
- d、表内整体位置凌乱,可调整为统一居左/中,财务部的“备注”列导致整行宽度变宽。
- e、比例换成百分比更直观
- f、单位“万”可以单独提取在列名背后备注
4、UI自动化执行用例不够稳定(有时候正常有时候报错),一般有几种解决办法?
UI自动化常见的5大不稳定因素:
- 非预计的弹出对话框。
- 页面控件属性的细微变化
- 别扯系统的A/B测试
- 随机的页面延迟造成控件识别失败
- 测试的数据问题
a、解决办法:
非预计的弹出对话框
产生原因:有的网站可能会某一时刻产生广告之类的弹框。随机出现,影响自动化用例的执行。
解决策略:在规定时间内,定位不到页面属性时,可能存在弹框,将异常捕获,执行(确定,取消等按钮)。
b、页面控件属性的细微变化
产生原因:前端稍微修改之后,导致页面的控件定位发生错误。
解决策略:采用相对路径,更重要的是对UI自动化进行封装,当我对UI自动化脚本进行封装4次之后,每次前端修改,只要不是大型的改动,只需要几分钟就可以更改调试成功。
c、被测系统的A/B测试
产生原因:一个网址可能跳转到不同的一个或者几个页面
解决策略:针对不同的版本进行分支处理
d、随机的页面延迟造成控件识别失败
产生原因: 网络延迟或者丢包卡顿等。
解决办法: 显示等待,隐性等待机制。但是根据我个人的经验,最好的做法是对selenium接口进行二次封装,解决等待问题,而且,隐式等待机制最好是用在页面跳转上。
e、测试数据问题
产生原因: 有的网站测试数据只能使用一次,例如,注册用户姓名不能重复,订单不能重复等问题
解决办法: 在运行脚本之前,链接到数据库,通过脚本,将原来的数据删除掉。
.
.
.
以上说法仅供参考,Web UI自动化测试的不稳定性有两个层面:
5、编程题: 有字符串“aabbcdbaaabc”,用你熟悉的语言实现去除“ab”子串。
str = 'aabbcdbaaabc'
excStr = str.replace('ab','')
while 'ab' in excStr:
excStr=excStr.replace('ab','')
print(excStr)
上题延伸:记录一次笔试题:【去除str = [“aababbc”, “badabcab”] 中的“ab”,语言不限】
str = ["aababbc", "badabcab"]
for str1 in str:
str2 = str1.replace('ab', '')
while 'ab' in str2:
str2 = str2.replace('ab', '')
print(str2)
深信服二面:
1、Linux配置网络在那里实现,或者说在哪个根目录下?
2、如何查询第10行日志?
3、Selenium你是如何定位的?
4、当有一个高并发的场景无法模拟的时候,你怎么处理?
编程题:
用你熟悉的语言,统计list中各个元素出现的次数
如:list=[“aa”,“b”,“c”,“aa”,“b”,“a”]
ps: 面试的时候没想清楚,后来查了一下,发现真的是Python基础,就一个List和字典的基础。
Python:
"""
方法零 使用for循环
"""
list=["aa","b","c","aa","b","a"]
result_dic={} #定义一个空的字典
for item in list:
if item not in result_dic:
result_dic[item]=1
else:
result_dic[item]+=1
print(result_dic) #输出一个字典,Key是字符串,Value是出现的次数
#对字典进行排序 根据字典的Value排序
new_sys2 = sorted(result_dic.items(), key=lambda d: d[1], reverse=True)
print(new_sys2)
#延申学习
#根据字典的key排序 d[0]
#new_sys2 = sorted(result_dic.items(), key=lambda d: d[0], reverse=True)
#对于统计一个列表中每个元素出现的次数,还有如下几种方法:
"""
方法一:使用函数Counter,可以迅速获取list中每个元素出现的次数
"""
from collections import Counter
arr=[1,2,5,1,1,5,6,3,3,2,2,4,8]
# arr=Counter(lists)
# print(arr)
def counter(arr):
return Counter(arr)
print(counter(arr))
#两种写法的结果都是Counter({1: 3, 2: 3, 5: 2, 3: 2, 6: 1, 4: 1, 8: 1})
"""
方法二:利用list中的函数count,获取每个元素的出现次数
"""
list1=[1,5,5,2,2,2,1,3]
def all_list(list1):
result = {}
for i in set(list1):
result[i]=list1.count(i)
return result
print(all_list(list1))
"""
方法三:利用Numpy索引,获取每个元素的出现次数
"""
import numpy as np
list2=[5,5,5,8,8,9,1]
def num(lis):
lis=np.array(lis)
key=np.unique(lis)
result={}
for k in key:
mask =(lis == k)
list_new=lis[mask]
v=list_new.size
result[k]=v
return result
print(num(list2))
"""
Python的pandas包下的value_counts方法
"""
import pandas as pd
a = [1, 2, 3, 1, 1, 2]
result = pd.value_counts(a)
print result















 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











