







“人工智能源于数据科学,大数据成就了人工智能”-----郭毅可
数据对人工智能来说尤为关键,我国人工智能发展如此之迅速,其中就因为我国的人口基数大.但当某些数据缺失时,怎么解决呢?
举个最简单的例子,我有一张数据表有1000条数据,里面有性别,谈恋爱次数,恋爱次数与人品,恋人的颜值,第三者出现时的做法等,但是在第100-110行中有一个字段的数据丢失了,假如缺少的是性别.那么,我是不是可以通过完整的数据去判断那10行缺的数据呢?
刚好最近在学习<<概率论与数理统计及其应用第二版>>,其中就讲到了全概率公式以及贝叶斯公式,有了一定的理论基础后,我开始尝试制作用于预测性别的贝叶斯算法模型.
我们先来学习一下基本理论, <<概率论与数理统计及其应用第二版>>这本书里的概念不容易理解,我在网上找了一些比较好理解的解释,经过总结后,跟大家分享:
先验概率
事件发生前的预判概率。可以是基于历史数据的统计,可以由背景常识得出,也可以是人的主观观点给出。一般都是单独事件概率,如P(x),P(y)
条件概率公式
设A,B是两个事件,且P(B)>0,则在事件B发生的条件下,事件A发生的条件概率(conditional probability)为:P(A|B)=P(AB)/P(B)
P(A|B)是在B发生的情况下A发生的可能性
乘法公式
由条件概率公式得:P(AB)=P(A|B)P(B)=P(B|A)P(A)
对于任何正整数n≥2,当P(A1A2…An-1) > 0 时,有:
P(A1A2…An-1An)=P(A1)P(A2|A1)P(A3|A1A2)…P(An|A1A2…An-1)
加法公式
设A和B是任意二事件,则
P(A∪B)= P(A)+P(B)-P(A∩B)
全概率公式
当直接计算P(A)较为困难,而P(Bi),P(A|Bi) (i=1,2,…)的计算较为简单时,可以利用全概率公式计算P(A)。将事件A分解成几个小事件,通过求小事件的概率,然后相加从而求得事件A的概率,而将事件A进行分割的时候,不是直接对A进行分割,而是先找到样本空间Ω的一个个划分B1,B2,…Bn,这样事件A就被事件AB1,AB2,…ABn分解成了n部分,即A=AB1+AB2+…+ABn, 每一Bi发生都可能导致A发生相应的概率是P(A|Bi),则:
P(A)=P(AB1)+P(AB2)+…+P(ABn)=P(A|B1)P(B1)+P(A|B2)P(B2)+…+P(A|Bn)P(PBn)
贝叶斯公式
与全概率公式解决的问题相反,贝叶斯公式是建立在条件概率的基础上寻找事件发生的原因(即大事件A已经发生的条件下,分割中的小事件Bi的概率),设B1,B2,…是样本空间Ω的一个划分,则对任一事件A(P(A)>0),有
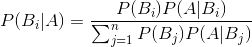
简单来说,朴素贝叶斯是生成模型,根据已有样本进行贝叶斯估计学习出先验概率P(Y)和条件概率P(X|Y),进而求出联合分布概率P(XY),最后利用贝叶斯定理求解P(Y|X)
说到方法,我的思路是:男生和女生在谈恋爱次数,恋爱次数与人品,恋人的颜值和第三者出现时的做法上在某种程度上是有关联的,因此可以根据一个人在心理上的行为判断性别.
首先,我们先来分析一下已有的数据:性别,谈恋爱次数,恋爱次数与人品,恋人的颜值,第三者出现时的做法.性别只有男和女,谈恋爱次数就可以有很多可能了(至今没有,一次,两次,多得不得了),恋爱次数是否与人品有关只有两种可能,恋人的颜值是否重要也是两种情况,第三者出现时的做法也有很多可能(感到茫然无措,说明事情忠于恋人,对其冷淡但维持友谊,等瞒着恋人与其交往).
在现实生活中,通常只能使用一个小数据集。基于少量观测数据所训练出的模型往往会过度拟合,产生不准确的结果。所以即使可用的数据是极其有限的,也需要了解如何避免过度拟合,并获得准确的预测。
大数据和数据科学这两个概念常常被一并提及。人们认为,数据科学可以从大量数据的万亿字节中得出一些有价值的见解。的确,理论上可以。
通过收集上来的数据,知道了每个字段都有哪些属性后,我们就可以算出事件发生前的预判概率,有了这个先验概率后,我们就可以算出在事件B发生的条件下,事件A发生的条件概率.在条件概率的基础上使用贝叶斯定理算出概率,如果女生的概率大,则输出女生.
然而,在实际的场景中,能用来解决问题的数据通常是有限的。因为收集一个庞大的数据集可能会非常昂贵,或者根本就不可能(例如,在进行时间序列分析时,只有来自特定时间段的记录)。因此,时常除了使用一个小数据集来尽可能获得准确的预测外,别无选择。
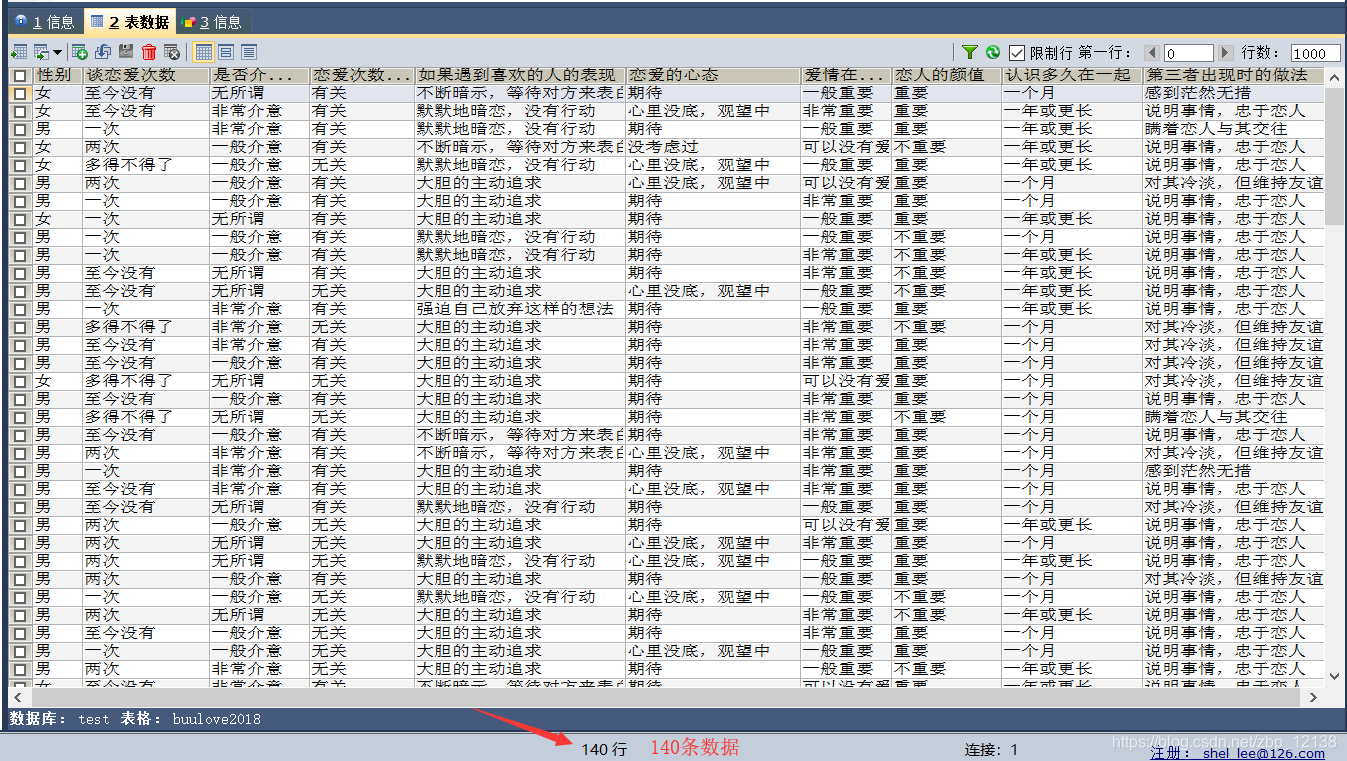
我目前应用于该模型的数据是我自己通过问卷调查的方式获得的,只有140条,属于小数据,以下是我收集到的部分数据:
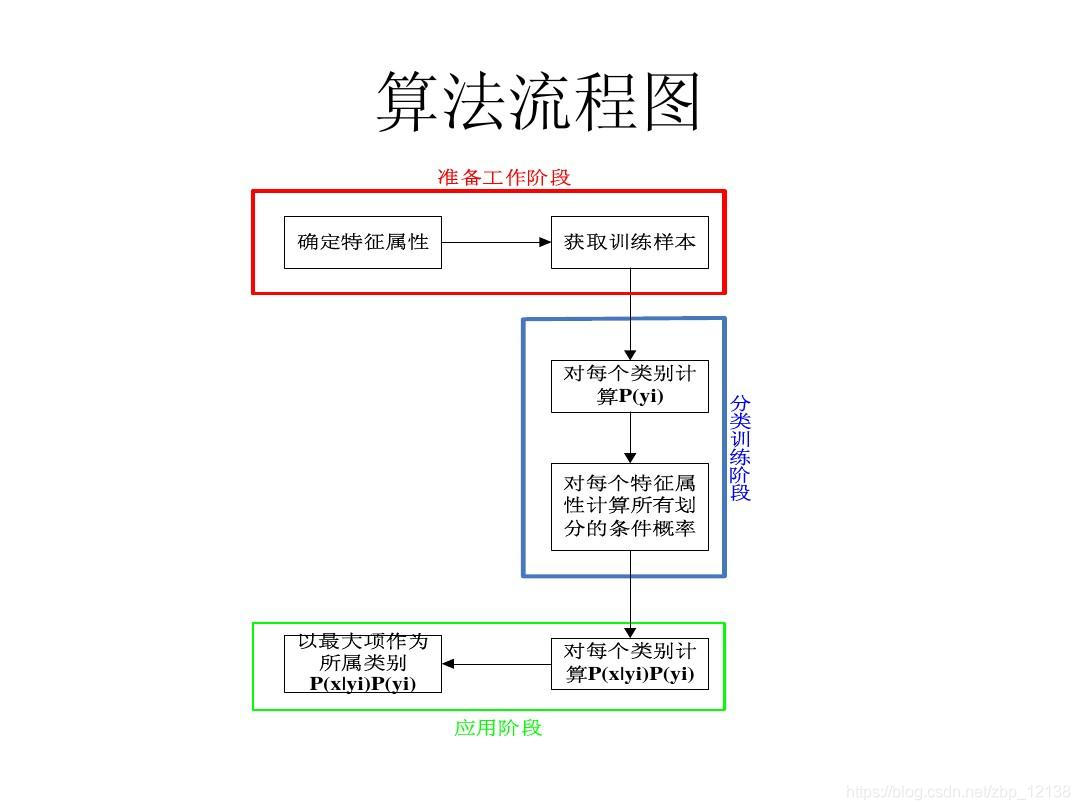
朴素贝叶斯算法分为三个阶段:
- 准备工作阶段
这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。其中,数据的质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量以及样本大小决定。
- 分类器训练阶段
这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面公式可以由程序自动计算完成。
- 应用阶段
这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
好了,有了这些基础以后,我们就可以开始编写代码了!
因为今天做的是模型,所以我建立了一个类,并在里面定义了有关方法:
class BAYES_DEMO(): #贝叶斯模型
def __init__(self): #封装
pass
def con_sql(self): #连接数据库
pass
def train(self, taglist, cla): # 训练,每次插入一条数据
pass
def P_C(self, cla): # 计算分类 cla 的先验概率
pass
def P_all_C(self):  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5148
5148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











