








Linux系统主要提供3种方式支持并发:进程,线程和I/O多路复用。
Tcp并发服务器过程图:
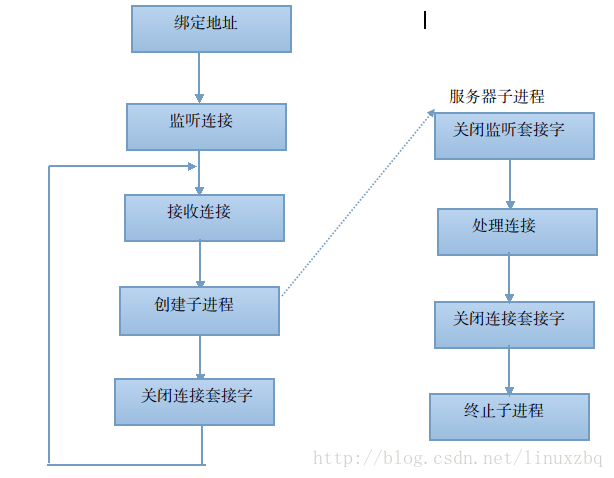
一. 进程创建
Linux下可以通过调用fork或vfork函数来创建进程。在创建进程时,要进行资源拷贝。Linux有3种资源拷贝的方式:
(1)共享: 新老进程共享通用的资源。当共享资源时,两个进程共用一个数据结构,不需要为新进程另建。
(2)直接拷贝: 将父进程的文件,文件系统,虚拟内存登结构直接拷贝到子进程中。子进程创建建后,父子进程拥有相同的结构。
(3)Copy on Write:(写时复制)拷贝虚拟内存页是相当困难和耗时的工作,所以能不拷贝就最好不拷贝,如果必须拷贝,也要尽可能地少拷贝,
为此,Linux采用Copy on Write技术,把真正的虚拟内存拷贝推迟到两个进程中的任一个试图写虚拟页的时候,如果某虚拟内存页上没有出现写
的动作,父子进程就一直共享该页而不用拷贝。
二,函数介绍
fork()和vfork(),其中,fork用于普通进程的创建,采用的是Copy on Write方式;而vfork用于完全共享的创建,新老进程共享同样的资源,完全没有拷贝。
fork()函数如下:
#include<unistd.h>
pid_t fork(void);
函数调用失败返回-1.fork函数调用失败的原因主要有两个: 1.系统中已经有太多的进程。2.该实际用户ID的进程总数超过了系统限制。
而如果调用成功,该函数调用会返回两次,在调用进程也就是父进程中,它的返回一次,值为新派生的子进程ID号;而在子进程中它还返回一次,值为0,
因此可以通过返回值来区别当前进程是子进程还是父进程。
为什么在fork的子进程中返回的值为0,而不是父进程的id呢? 原因在于: 每一子进程都只有一个父进程,它可以通过调用getppid函数来得到父进程ID;而对
于父进程,他又很多个子进程,他没办法通过一个函数得到各子进程的ID,如果父进程想跟踪所有子进程的ID,它必须记住fork的返回值。
fork调用之后,父子进程的执行顺序是不确定的,这取决于系统内核所使用的调度算法。
vfork是完全共享的创建,新老进程共享同样的资源,完全没有拷贝。但使用vfork()函数创建新进程时,父进程将被暂时阻塞,而子进程则可以借用
父进程的地址空间运行。这个奇特的状态持续到子进程退出或调用execve()函数,至此父进程才继续执行。
vfork()函数如下:
#include<unistd.h>
pid_t vfork(void);
vfork()和fork()函数一样,调用一次返回两次,父进程中他的返回值时新派生的子进程ID号,而在子进程中它的返回值为0.如果返回为-1,表示调用失败。
vfork调用之后,先是子进程执行完或调用execve()函数后,父进程才开始执行。
三.fork的典型应用
(1) 父,子进程各自执行不同的程序段,这是非常典型的网络服务器。父进程等待客户端请求。当这种请求到达时,父进程调用fork函数,产生一个子进程,
由子进程对该请求做处理。父进程则继续等待下一个客户的服务请求。这种情况下,在fork函数之后,父,子进程需要关闭各自不使用的描述符。
(2)每个进程要执行不同的程序。这种情况下,子进程在从fork函数返回后立即调用exec函数执行其他程序。

















 211
211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









