







并行化指令
- parallel:将代码发送到不同的线程中去执行。
- for:将for循环中的计算过程分发到不同的线程中去。
- reduction:并行的程序运行结束时,对并行区域内的一个或者多个变量执行一个操作,每个并行的程序将创建参数的一个副本,在运行结束时对各个副本进行+,-,×,/等操作。
- shared(v1,v2,…):声明变量v1,v2,…是共享变量,如果写共享变量时注意对共享变量加以写保护,在循环体内的临时变量都是私有变量。
- num_threads(n_thread):设置线程数目。
OpenMP的向量内积
# include <stdlib.h>
# include <stdio.h>
# include <math.h>
# include <omp.h>
int main ( int argc, char *argv[] );
double oriDot( int n, double x[], double y[] );
double dot1(int n, double* x, double* y);
double dot (int n,int n_thread , double* x, double* y);
int main ( int argc, char *argv[] )
{
int n_thread = atoi(argv[1]);
double factor;
int i;
int n;
double wtime;
double *x;
double xdoty;
double *y;
printf("Number of processors available = %d\n", omp_get_num_procs());
printf("Number of threads = %d\n", omp_get_max_threads());
n = 10000;
FILE* fp1 = fopen("ori_dot.txt", "w");
FILE* fp2 = fopen("dot.txt", "w");
FILE* fp3 = fopen("dot1.txt", "w");
FILE* fp4 = fopen("n.txt", "w");
while ( n < 100000000 )
{
n = n + 1000000;
fprintf(fp4, "%d\n", n);
x = ( double * ) malloc ( n * sizeof ( double ) );
y = ( double * ) malloc ( n * sizeof ( double ) );
factor = ( double ) ( n );
factor = 1.0 / sqrt ( 2.0 * factor * factor + 3 * factor + 1.0 );
for ( i = 0; i < n; i++ )
{
x[i] = (double)rand() / RAND_MAX;
}
for ( i = 0; i < n; i++ )
{
y[i] = (double)rand() / RAND_MAX;
}
printf ( "\n" );
//顺序执行计算向量内积
wtime = omp_get_wtime ( );
xdoty = oriDot( n, x, y );
wtime = omp_get_wtime ( ) - wtime;
printf("Sequential %8d %14.6e %15.10f\n", n, xdoty, wtime );
fprintf(fp1, "%f\n", wtime);
#OpenMP计算向量内积
wtime = omp_get_wtime ( );
xdoty = dot1( n, x, y );
wtime = omp_get_wtime ( ) - wtime;
printf("Parallel-Test2 %8d %14.6e %15.10f\n", n, xdoty, wtime );
#OpenMP计算向量内积
fprintf(fp3, "%f\n", wtime);
wtime = omp_get_wtime();
xdoty = dot(n, n_thread, x, y);
wtime = omp_get_wtime() - wtime;
printf("Parallel-dot %8d %14.6e %15.10f\n", n, xdoty, wtime);
fprintf(fp2, "%f\n", wtime);
free (x);
free (y);
}
fclose(fp1);
fclose(fp2);
fclose(fp3);
fclose(fp4);
printf ( "Done\n" );
return 0;
}
double oriDot(int n, double* x, double* y)
{
int i;
double xdoty;
xdoty = 0.0;
for ( i = 0; i < n; i++ )
{
xdoty = xdoty + x[i] * y[i];
}
return xdoty;
}
double dot1(int n, double* x, double* y)
{
int i;
double xdoty;
xdoty = 0.0;
# pragma omp parallel shared ( n, x, y ) private ( i )
# pragma omp for reduction ( + : xdoty )
for ( i = 0; i < n; i++ )
{
xdoty = xdoty + x[i] * y[i];
}
return xdoty;
}
double dot(int n, int n_thread, double* x, double* y)
{
int i;
double xdoty;
xdoty = 0.0;
# pragma omp simd
# pragma omp parallel for shared(n, x, y) private(i) num_threads(n_thread) reduction ( + : xdoty )
for ( i = 0; i < n; i++ )
{
xdoty = xdoty + x[i] * y[i];
//printf("thread id is %d\n", omp_get_thread_num());
}
return xdoty;
}编译命令
g++ dot_product.cpp -o dot_product -fopenmp
结果曲线
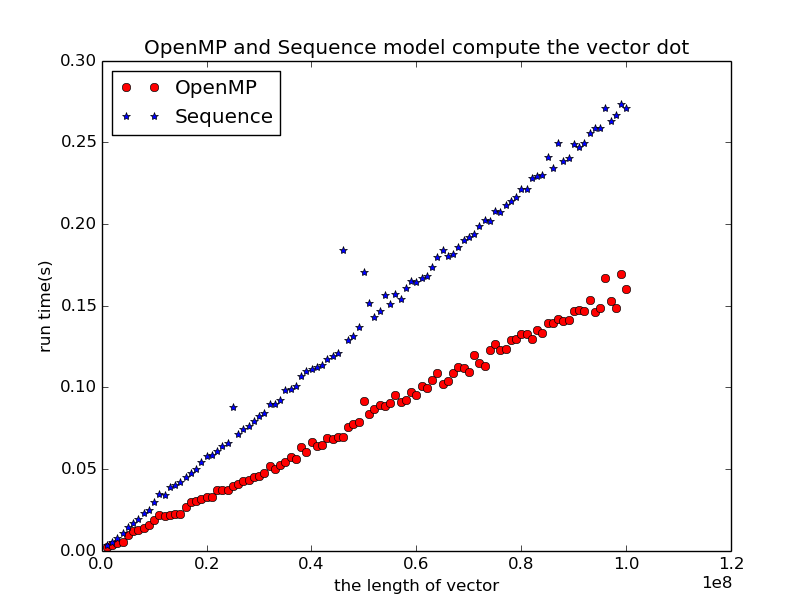
下图是不同长度的向量做内积计算时OpenMP和顺序执行时的时间,可以发现OpenMP的计算优势
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









