







参考链接:
画图解释SQL连接
sql语句的解析过程
orderby实现原理
mysql性能优化
前言
一直以来,sql语句都会显得很简单,命令部分由四个组成(增删改查),然后是字段名,然后是FROM子句,后跟数据源,然后是WHERE子句,然后是group by再然后是oderby子句。这样就可以构造成一条很复杂的SQL语句。
但是当我们系统遇到瓶颈时,数据量到百万级、千万级时,我们常常不知所措,不知道时间都花在了哪里,当然更不知道如何去优化。
直到看到伯乐在线的一篇博文,sql语句的解析过程,很浅显的解释了sql语句的解析过程,然后再综合了多篇博文,经自己理解重新汇总成此文。
为了方便说明,我们设计如下两张表:
TableA
id、name、age
1 nameA 10
2 nameB 4
3 nameC 6
4 nameD 8
TableB
1 nameA 10
2 nameB 5
3 nameF 7
4 nameE 4
核心之核心
我们以前对sql语句感到困惑,大致可以分为两方面:sql语句操作的基本单位是什么?数据流是如何流动的?
关系型数据库的理论基础是关系代数,关系代数的核心是集合。所以很多问题上需要从集合的观点来看待。
sql语句操作的基本单位是表 表 表,重要的事情说三遍,这个概念也是第一次从sql语句的解析过程中这篇博文中看到的,然后就一下子被点清了。
数据流的流动并不是按照sql语句的顺序来执行的,因为SQL语句是一种声明性语句,声明性语句指的是
“我告诉你我想要什么样的数据,但是我并不知道这些数据是在哪里,是怎么存储的,你是怎么把这些数据提取出来给我的,因为我不care。”
正是由于声明性语句的特点,所以我们程序员需要自己知道数据流是如何进行流动的。先说结论,SQL语句的执行过程分别为:FROM(on)\ WHERE\ GROUP BY\ HAVING\ SELECT\ ORDER BY.
FROM
因为sql语句的基本单位是表,所以很自然的,先要找到数据源,而数据源是由FROM来标明的。
当我们需要从多个表中获取数据时,我们往往会关联多个表来查询。而这多个表往往是存在某个字段可以进行关联的。
select * from a,b where a.id = b.id;
select * from a join b on a.id=b.id;这部分曾经困扰了我很长时间,这两者之间有啥共同点和不同点。
相同点在于,这两种都是一种称为连接的关系。不同的是,这是不同的连接。
连接类型大致可以分为三种:
- 内连接
- 外连接
- 既不是内连接也不是外连接
内连接
内连接的意思是对两个集合取交操作,通常使用inner join或join与on一起使用来完成。
select * from TableA join TableB on TableA.name = TableB.name结果如下:

外连接
内连接的特点是只返回两个集合相交的部分,但是如果我们希望有,比如表A,即使没有与表A相匹配的表B,我们也希望返回怎么办?答案是使用外连接。那么问题又来了,如果使用外连接,那么对于只属于A而不属于B的部分,那缺省的项咋办呢?使用NULL来代替。
外连接又分为三种:左外连接、右外连接和全外连接。
- 左外连接:基准在左侧,sql语句为left join/left outer join
- 右外连接:基准在右侧,sql语句为right join/right outer join
- 全外连接:基准在两侧,sql语句为full join
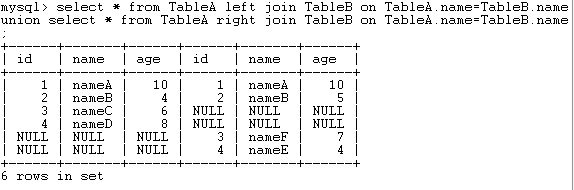
select * from TableA left join TableB on TableA.name=TableB.name;结果如下:

select * from TableA right join TableB on TableA.name=TableB.name;结果如下:
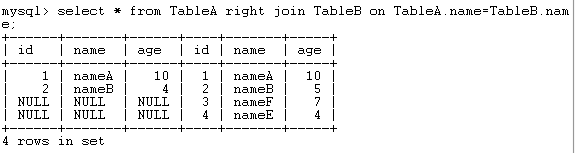
mysql并不支持全外连接,如full join和full outer join等。如果一定要得到全外连接,可以使用如下语句:
第三种
第三种用法称为笛卡尔积,笛卡尔积是非常可怕的,因为生成的临时新表里的数据量为M*N。如果一个表中数据为百万,另外一个表数据为百万,那么一旦笛卡尔积之后就是百万*百万,里面有多少个0,我就数不清了。
笛卡尔积的SQL语句可以用join表示,或者简单的”,”
select * from TableA,TableB;结果如下:
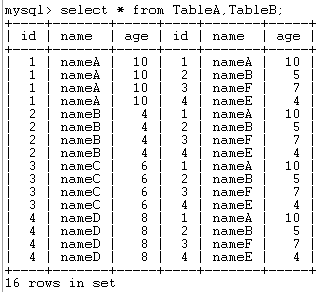
实际上,在所有连接生成过程中都是先得到笛卡尔积的组合,然后再通过条件进行筛选,因为笛卡尔积并没有什么物理上的意义。
那这样的话,也就明白了一条数据库优化的原理:先将单表进行过滤之后在进行多表连接。因为这样的话生成的交叉连接(笛卡尔积)表数据量会有明显幅度的减少。
在第一部分中提到过,sql语句操作的基本单位是表,数据流动的基本单位也是表,因此在FROM结束之后将会得到一张虚拟表(临时表),然后这张虚拟表将传递到WHERE子句部分。
WHERE
where子句用来处理From子句中生成的临时表,注意到,因为此时数据并没有流动到select子句,所以不可以再where子句中使用select子句中定义的alias,比如:
select name as n from TableA where n=‘nameA’; 错误!!但是可以使用from子句中对表的alias,
select * from TableA as A,TableB as B where A.name=B.name;结果如下(与内连接一样):

另外,ON 与where有啥不同,我们一般知道ON 与join配套使用,而where就通用的多,更多一层是,当我们使用ON对数据进行过滤之后,如果当前使用外连接,那么会自动将一些数据补足。如果不需要使用外连接,那ON和where作用是系统的,不过通常将复杂的过滤操作放在where中,而ON语句常常用来对表进行连接。
GROUP BY
group by子句将把上一步生成的临时表中的数据进行分组,每一行都会分到且只会分到同一个组中。
select count(id),age from TableA group by age;结果如下:
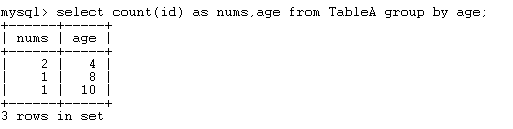
在分组最后返回的结果中,每个分组最多只能返回一行(多于一行将会被覆盖)。这样的话,在group by后面要处理的子句,如select,having子句等将只能使用group by出现的列或者使用聚合函数。
当然这并不是语法上的强制要求。但是如果不是这样的话,返回结果没有任何意义。
结果如下:虽然返回结果中也可以返回name项,但是同一组中只有一项返回了,其余的都被覆盖了,这样的话,其实没有太大意义。

having
having子句用来过滤group by生成的临时表,比如
select age,count(id) as nums from TableA group by age having count(id)>1;
这里有个很容易出错的问题:count(*)和count(column)等价吗?
答案是:不等价,count(*)是返回的结果集中有多少记录(record),而count(column)是返回的结果集中某一列的行数,但是会忽略NULL的内容。因为NULL代表为空,空的意思是未定义,未定义的意思是可能为任何内容,这里很有意思的内容,就是如果我们希望读取某字段为空的内容。那如果使用where column=NULL,这样是错误的。因为它会返回column字段中名字为NULL的行。
这里,一般会建议不要用未定义列,如果一定会存在未定义的列,那可以使用特殊的字符内容,比如-1或者就添加NULL来进行标识。
select
终于到了大家熟悉的select子句,select子句返回的表将最终返回给调用者,select子句主要分为两阶段:计算表达式、处理distinct。
在select之后将得到一个虚拟表,然后通过distinct可以对VT去重。
Order by
order by 对select返回的语句进行排序,根据orderby子句指定的顺序,返回游标。order by子句也是唯一一个可以使用select子句创建的别名的地方。
orderby一般有两种,如果orderby后的字段恰好是索引,我们知道索引排布通常是有序的,所以此时并没有真正的排序操作,此时速度也是最快的(也是优化手段之一哦~);如果非常不幸,不是索引咋办?那就需要进行文件排序。文件排序是指将取出的数据在内存中进行排序,所需要的内存区域大小可以通过sort_buffer_size系统变量来设置。
文件排序也有两种算法:1、首先根据相应条件取出相应的排序字段和可以直接定位行数据的行指针信息,然后再sort buffer中排序。2、一次性取出满足条件行的所有字段,然后在sortbuffer中排序。
这里,mysql主要根据设定的系统参数max_length_for_sort_data的大小和查询语句所需要数据量大小来选择排序算法。
一个很有趣的问题:
select * 比select column 要访问的数据量更大吗。
答案:错误,因为在文件系统中,数据是以块为单位进行存储的,而对于数据库的数据而言,一般会一行存储在一个结构体中,在文件系统中也会密排,在进行IO操作时,通常是以块为基本单位,而不会再对块中的数据进行选择。所以,二者的IO数据量是一样的。
但是要尽量少使用select *,虽然磁盘IO时并没有减少数据量,但是会在内存中占据较大空间,而在使用orderby时会比较大程度上降低我们的排序效率。














 4127
4127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









