







前情提要
算法描述
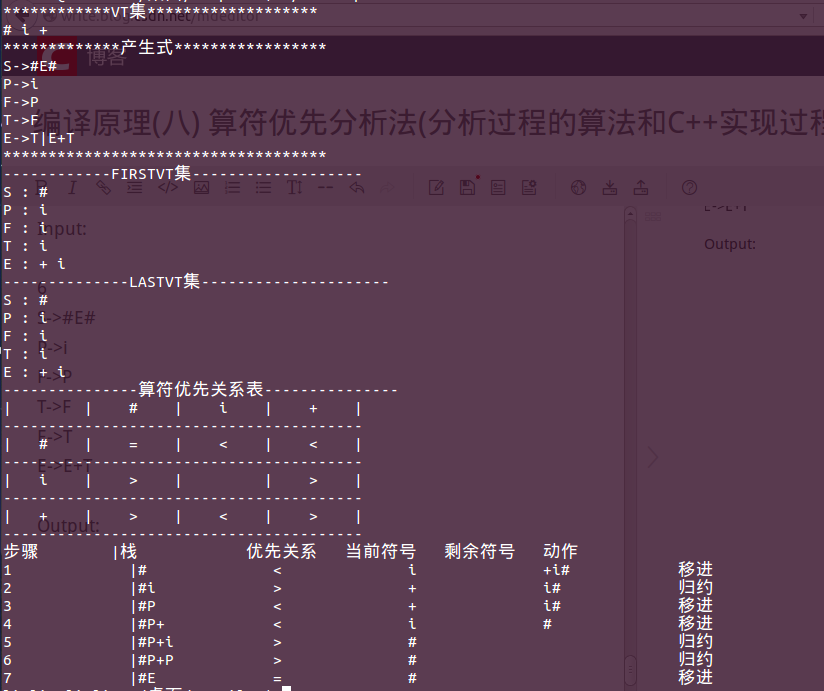
算符优先关系主要用于界定右句型的句柄:
<标记句柄的左端;
=出现在句柄的内部;
>标记句柄的右端。
发现句柄的过程:
- 从左端开始扫描串,直到遇到第一个>为止。
- 向左扫描,跳过所有的=,直到遇到一个<为止。
- 句柄包括从上一步遇到的<右部到第一个>左部之间的所有符号,包括介于期间或者两边的非终结符
非终结符的处理:
因为非终结符不能影响语法分析,所以不需要区分它们,于是只用一个占位符来代替它们
算法的主体思想:
用栈存储已经看到的输入符号,用优先关系指导移动归约语法分析器的动作
如果栈顶的终结符和下一个输入符之间的优先关系是<或=,则语法分析器移动,表示还没有发现句柄的右端
如果是>关系,就调用归约
算法描述:
输入:输入字符串ω和优先关系表
输出:如果ω是语法产生的一个句子,则输出其用来归约的产生式;如果有错误,则转入错误处理
Input:
6
S->#E#
P->i
F->P
T->F
E->T
E->E+T
Output:















 8949
8949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









