







一. MapReduce执行过程
MapReduce运行的时候, 会通过Mapper运行的任务读取HDFS中的数据文件, 然后调用自己的方法处理数据, 最后输出. Reduce任务会接受Mapper任务输出的数据, 作为自己输入的数据, 然后调用自己的方法, 最后输出到HDFS的文件中.
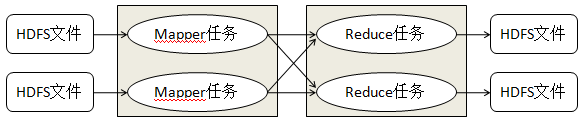
map-reduce的思想就是“分而治之”,mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”执行,这些的话数据或计算规模相对于原任务会大大缩小,并行计算大大提高效率,就近计算能减少数据在网络中的传输。
二. Mapper任务执行过程
每个Mapper任务都是一个java进程, 它会读取HDFS中的文件, 解析成很多键值对, 经过我们覆盖的map方法处理后, 转换成很多的键值对再输出, 整个Mapper任务的处理过程可以分为以下几个阶段:
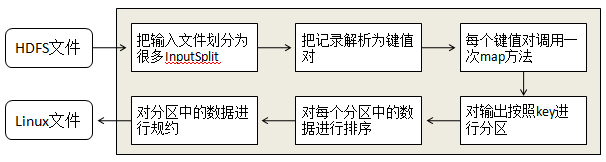
第一阶段是把输入文件按照一定的标准分片(InputSplit),每个输入片的大小是固定的。默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。如果数据块(Block)的大小是默认值64MB,输入文件有两个,一个是32MB,一个是72MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片。一共产生三个输入片。每一个输入片由一个Mapper 进程处理。这里的三个输入片,会有三个Mapper 进程处理。
第二阶段是对输入片中的记录按照一定的规则解析成键值对。有个默认规则是把每一行文本内容解析成键值对。“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
第三阶段是调用Mapper 类中的map 方法。第二阶段中解析出来的每一个键值对,调用一次map 方法。如果有1000 个键值对,就会调用1000 次map 方法。每一次调用map 方法会输出零个或者多个键值对。
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。比较是基于键进行的。比如我们的键表示省份(如北京、上海、山东等),那么就可以按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认是只有一个区。分区的数量就是Reducer 任务运行的数量。默认只有一个Reducer 任务。
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到本地的linux 文件中。
第六阶段是对数据进行归约处理,也就是reduce 处理。键相等的键值对会调用一次reduce 方法。经过这一阶段,数据量会减少。归约后的数据输出到本地的linxu 文件中。本阶段默认是没有的,需要用户自己增加这一阶段的代码。
三. Reduce任务执行过程
每个Reducer任务都是一个Java进程, Reducer任务接受Mapper任务的输出, 归约处理后写入HDFS中

第一阶段是Reducer 任务会主动从Mapper 任务复制其输出的键值对。Mapper 任务可能会有很多,因此Reducer 会复制多个Mapper 的输出。
第二阶段是把复制到Reducer 本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
第三阶段是对排序后的键值对调用reduce 方法。键相等的键值对调用一次reduce 方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS 文件中。在整个MapReduce 程序的开发过程中,我们最大的工作量是覆盖map 函数和覆盖reduce 函数。
四. Hadoop的数据类型
1. 序列化:(序列化相当于加密,反序列化相当于解密)
IntWritable、LongWritable、VintWritable、VlongWritable、Text、BytesWritable、NullWritable、ObjectWritable
ArrayWritable、TwoDArrayWritable、MapWritable
以上类型都实现了接口Writable、Comparable
2. SequenceFile:
SequenceFile可以把大量小文件一起放到一个block中, 在存储相同数量的文件时, 可以明显减少block的数量。
五. 输入格式化类:InputFormat
类InputFormat是负责把HDFS中的文件经过一系列处理变成 map 函数的输入部分的,这个类做了3件事情:
1. 验证输入信息的合法性, 包括输入路径是否存在等。
2. 把HDFS中的文件按照一定规则拆分成InputSplit,每个InputSplit由一个Mapper执行。
3. 提供Recordreader, 把InputSplit中的每一行解析出来供map函数处理。
子类1: FileInputFormat
子类2:TextInputFormat
六. 输出格式化类:OutputFormat
OutputFormat
子类1: FileOutputFormat
该类是对类FileSystem操作执行输出的, 会对运算的结果先写入到一个临时文件夹中,待运算结束后, 再移动到最终的输出目录中。
子类2: TextOutputFormat
该类专门输出普通文本文件的。
七. MapReduce性能调优
1. 对于输入文件,大文件要优于小文件
2. 减少网络传输,压缩map的输出
3. 设置多少个reducer比较合适?
reducer可以通过job.setNumReduceTasks(num)来进行设置,首先reducers数必须小于mappers数。
TaskTrackers中有个slots的东东,它类似资源池,每个任务执行时都必须获得一个slot才能继续,否则只能等待。当一个任务完成后,该任务就归还slot,该过程类似释放资源到资源池中。slots分为mapper slots和reducer slots,分别对应可并行执行的mapper数和reducer数,用户可以通过设置mapred-site.xml配置文件中的mapred.tasktracker.map.tasks.maximum和mapred.tasktracker.reduce.tasks.maximum来设置slot的值,默认为2.
因此reducers数目应该略小于reducer slots的总数。














 622
622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









