







分表记录完了,我们知道降低数据库存储压力:
分表:整个库的数据量不是很大,但是某个(些)表的数据量较大.
分库:
竖直:数据库之间是异构的.就是按照模块或者功能划分库。
水平:数据库之间是同构的.(数据存储范围不同),水平切割。
今天记录分库应用的学习,一般分库可以采用多种不同的方式,根据开发系统的功能要求来具体实施不同方案,大部分是模块,我印象中淘宝就是模块划分,加分布式系统管理,这个项目考虑到增加数据库压力的是答案部分,因为一套试题就会有成千个答案,所以我们对answer表水平分库,就是调查id为奇数存入主库,为偶数就存入从库。
具体操作就是:首先创建从库,然后配置多个数据源,由隔离级别数据源路由器分配存储:
<!-- 数据源(主库) 数据库连接信息存入分散配置文件:jdbc.properties中 -->
<bean id="dataSource_main" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driverclass}" />
<property name="jdbcUrl" value="${jdbc.url}" />
<property name="user" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<property name="maxPoolSize" value="${c3p0.pool.size.max}" />
<property name="minPoolSize" value="${c3p0.pool.size.min}" />
<property name="initialPoolSize" value="${c3p0.pool.size.ini}" />
<property name="acquireIncrement" value="${c3p0.pool.size.increment}" />
</bean>
<!-- 数据源(从库) -->
<bean id="dataSource_1" parent="dataSource_main">//定义parent属性将从库与主库相同的部分省略,相当于引用主库
<property name="jdbcUrl" value="jdbc:mysql://localhost:3306/surveypark_1" />
</bean>
先创建数据源路由器,然后在Spring的bean.xml中配置路由器bean:自定义数据源继承AbstractRoutingDataSource类,是Spring框架中自带的路由管理器
<bean id="dataSource_main" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driverclass}" />
<property name="jdbcUrl" value="${jdbc.url}" />
<property name="user" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<property name="maxPoolSize" value="${c3p0.pool.size.max}" />
<property name="minPoolSize" value="${c3p0.pool.size.min}" />
<property name="initialPoolSize" value="${c3p0.pool.size.ini}" />
<property name="acquireIncrement" value="${c3p0.pool.size.increment}" />
</bean>
<!-- 数据源(从库) -->
<bean id="dataSource_1" parent="dataSource_main">//定义parent属性将从库与主库相同的部分省略,相当于引用主库
<property name="jdbcUrl" value="jdbc:mysql://localhost:3306/surveypark_1" />
</bean>
先创建数据源路由器,然后在Spring的bean.xml中配置路由器bean:自定义数据源继承AbstractRoutingDataSource类,是Spring框架中自带的路由管理器
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
/**
* 自定义数据源路由器
*/
public class SurveyparkDataSourceRouter extends AbstractRoutingDataSource {
protected Object determineCurrentLookupKey() {
SurveyToken token = SurveyToken.getCurrentToken();
if(token != null){
int id = token.getCurrentSurvey().getId();
//解除绑定
SurveyToken.unbindToken();
return (id % 2) == 0?"even":"odd" ;
}
return null;
}
}
/**
* 自定义数据源路由器
*/
public class SurveyparkDataSourceRouter extends AbstractRoutingDataSource {
protected Object determineCurrentLookupKey() {
SurveyToken token = SurveyToken.getCurrentToken();
if(token != null){
int id = token.getCurrentSurvey().getId();
//解除绑定
SurveyToken.unbindToken();
return (id % 2) == 0?"even":"odd" ;
}
return null;
}
}
bean.xml文件中配置上面的数据源
<!-- 数据源路由器 -->
<bean id="dataSource_router" class="cn.zeb.surveypark.datasource.SurveyparkDataSourceRouter">
<property name="targetDataSources">
<map>
<entry key="odd" value-ref="dataSource_main" />
<entry key="even" value-ref="dataSource_1" />
</map>
</property>
<property name="defaultTargetDataSource" ref="dataSource_main" />
</bean>
<!-- 数据源路由器 -->
<bean id="dataSource_router" class="cn.zeb.surveypark.datasource.SurveyparkDataSourceRouter">
<property name="targetDataSources">
<map>
<entry key="odd" value-ref="dataSource_main" />
<entry key="even" value-ref="dataSource_1" />
</map>
</property>
<property name="defaultTargetDataSource" ref="dataSource_main" />
</bean>
看上面的代码你会发现我们为了控制调查id传递给数据源路由器(action和数据源隔十万八千里),采取了线程绑定机制就是threadLocal,通过线程既能解决多并发问题,也能实现数据的友好传递。
**
* 调查令牌,绑定到当前的线程,传播到数据源路由器.进行分库判断
*/
public class SurveyToken {
private Survey currentSurvey ;
private static ThreadLocal<SurveyToken> t = new ThreadLocal<SurveyToken>();
* 调查令牌,绑定到当前的线程,传播到数据源路由器.进行分库判断
*/
public class SurveyToken {
private Survey currentSurvey ;
private static ThreadLocal<SurveyToken> t = new ThreadLocal<SurveyToken>();
这里省略具体代码,以后可以在这里知道去哪里查看就可以了。
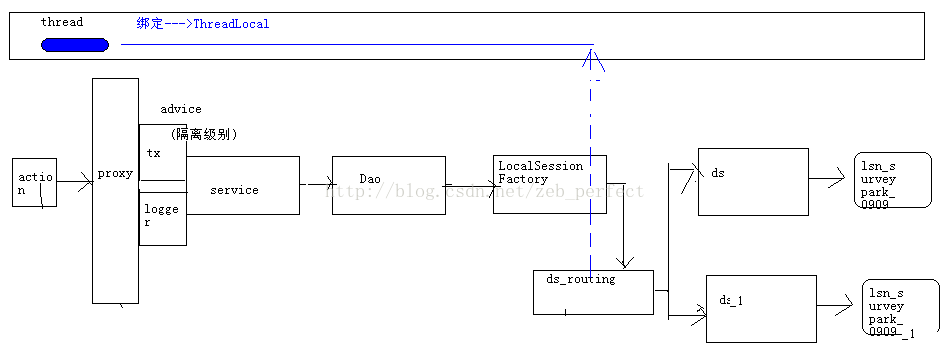
但是后来又出现了一个问题,就是日志表存储提示表不存在,研究知道它是要存入从库中,可是我们希望日志表存入主库,为什么会存从库那,这是因为事务是AOP的环绕通知方式,而且具有传播性的,当偶数调查答案事务完成后,数据源控制答案存入从库,完成后数据源并没有解除id绑定,那么日志事务执行就默认走从库,进而出错,流程图如下:

显然不符合我们要求,于是就有了下面的流程图:
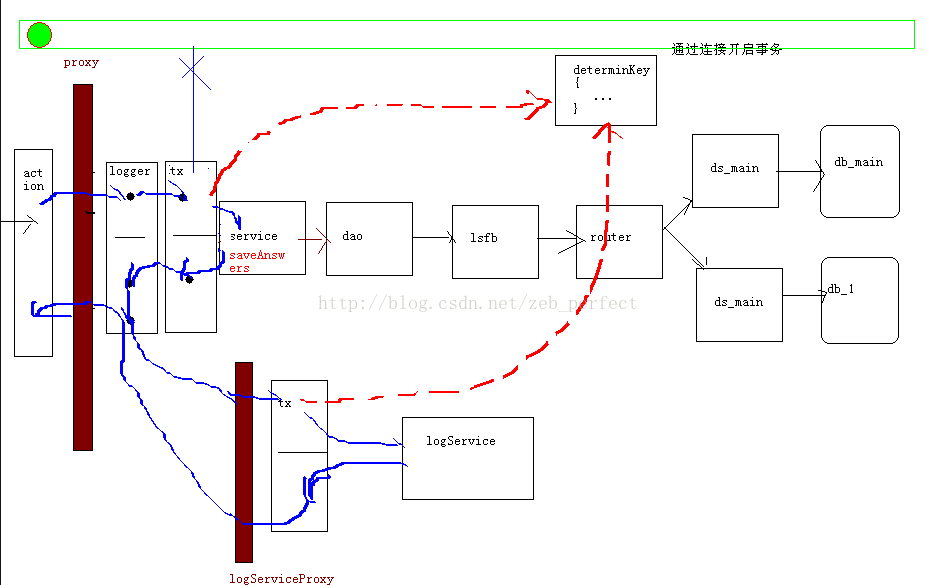
就是调整事务和日志的前后顺序,然后在数据源路由器获取到调查id后,随即解除对id的绑定,这时再到日志操作时,因为没有了id,数据源采用默认库操作,就存到了主库中,我们目的就达到了。总的来说,这种问题单靠自己是很难发现和解决的,希望以后能多尝试,多总结,多学习。
这样,分库就完成了,可以发现,分库是对整个项目的总结,也是对框架知识的整体回顾,包括action执行流程,事务,日志的切面操作等等,算是对自己学习成果的考验。















 1859
1859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









