










补充:mp引擎切换为tez、解决yarn 8081端口报错问题
解决hive comment中文乱码问题:hive-site配置如下
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://10.4.151.58:3306/hive?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false&verifyServerCertificate=false</value>
背景
随着公司业务飞速发展,数据体量急剧上升、运营指标需求多样化、精细化;为解决上述问题和实现合理化、规范化数据管理,提供稳定、可靠和适配的数据服务能力,大数据平台的建设迫在眉睫。
另一方面,在对市场调研之后,由于我司业务处于政务环境网(与公有网进行了全方位隔离),只能通过成熟的云产品进行私有化部署,但价格不菲。例如
阿里云大数据敏捷版本(功能相对不够完善:200万以上/年,持续付费/年)
阿里云大数据企业版本(功能完善:1000万以上/年,持续付费/年)
蚂蚁Oceanbase基础版(仅提供分布式高可用存储:100万左右/年,持续)
其他垂直领域大数据厂商(150万以上/年,持续付费)
因此,无论从解决公司业务问题的角度思考、数据价值输出的角度思考、或者节省经费消耗的角度思考,自研大数据平台建设是具有里程碑意义的一个转折点,基于数据驱动业务,赋能业务!
所用组件
- hadoop
- hive
- yarn
- squirrle(不错的数据开发可视化客户端,支持mysql hive 等等。。。)
- zookeepker(高可用)
- datax(数据集成)
- dolphinScheduler(本土自研调度平台,欢迎有志之士加入我们,贡献开源)
- mysql

环境依赖
JDK1.8 以上
CentOS Linux release 7.4.1708 (Core)
psmisc-22.20-15.el7.x86_64
Apache Maven 3.x (Compile DataX)
若无,安装语句:yum install psmisc
安装步骤
Hadoop安装(版本2.7.5)
非高可用版本,但是安装高可用版本,需要在此版本安装成功以后进行
概要
接下来介绍大数据平台Hadoop的分布式环境搭建、以下为Hadoop节点的部署图,将NameNode部署在master1,SecondaryNameNode部署在master2,slave1、slave2、slave3中分别部署一个DataNode节点。
一共需要准备五台服务器,ip对应如下:
| 服务器ip | Hadoop节点分配 | 服务器host名 |
| ip1 | NameNode | master1 |
| ip2 | SecondaryNameNode | master2 |
| ip3 | DataNode | slave1 |
| ip4 | DataNode | slave2 |
| ip5 | DataNode | slave3 |
前期准备
(一)关闭所有服务器防火墙
systemctl stop firewalld
systemctl disable firewalld(二)分别修改五台服务器的/etc/hosts文件,内容如下
ip1 master1
ip2 master2
ip3 slave1
ip4 slave2
ip5 slave3注:对应修改每个服务器的/etc/hostname文件,里面的内容分别是master1、master2、slave1、slave2、slave3,hostname对应前期准备中的资源分配的host名
(三)分别在各台服务器创建一个普通用户与组
groupadd hadoop #增加新用户组
useradd hadoop -m -g hadoop #增加新用户
passwd hadoop #修改hadoop用户的密码注:切换至hadoop用户:su hadoop 进行部署,使用root用户部署会存在较多权限问题
(四)每个服务器间的免密码登录配置,分别在各自服务中执行一次
ssh-keygen -t rsa #一直按回车,会生成公私钥
ssh-copy-id hadoop@master1 #拷贝公钥到master1服务器
ssh-copy-id hadoop@master2 #拷贝公钥到master2服务器
ssh-copy-id hadoop@slave1 #拷贝公钥到slave1服务器
ssh-copy-id hadoop@slave2 #拷贝公钥到slave2服务器
ssh-copy-id hadoop@slave3 #拷贝公钥到slave3服务器注:以上步骤是在hadoop用户下,进行的操作
开始安装
(一)创建hadoop安装目录
mkdir -p /home/hadoop/app/hadoop/{tmp,hdfs/{data,name}}(二)将安装包解压至/home/hadoop/app/hadoop下
tar zxf tar -zxf hadoop-2.7.5.tar.gz -C /home/hadoop/app/hadoop(三)配置hadoop的环境变量,修改/etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_131
JRE_HOME=/usr/java/jdk1.8.0_131/jre
HADOOP_HOME=/home/hadoop/app/hadoop/hadoop-2.7.5
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH(四)刷新环境变量
source /etc/profile配置Hadoop
(一)配置core-site.xml
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/core-site.xml<configuration>
<property>
<!-- 配置HDFS的NameNode所在节点服务器 -->
<name>fs.defaultFS</name>
<value>hdfs://master1:9000</value>
</property>
<property>
<!-- 配置Hadoop的临时目录 -->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop/tmp</value>
</property>
<property>
<!-- 配置hive2连接用户权限 -->
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>默认配置地址:http://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-common/core-default.xml
(二)配置hdfs-site.xml
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/hdfs-site.xml<configuration>
<property>
<!-- 配置HDFS的DataNode的备份数量 -->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/app/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/app/hadoop/hdfs/data</value>
</property>
<property>
<!-- 配置HDFS的权限控制 -->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<!-- 配置SecondaryNameNode的节点地址 -->
<name>dfs.namenode.secondary.http-address</name>
<value>master2:50090</value>
</property>
</configuration>默认配置地址:http://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
(三)配置mapred-site.xml
$ cp /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml.template /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml<configuration>
<property>
<!-- 配置MR运行的环境 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(四)配置yarn-site.xml
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/yarn-site.xml<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 配置ResourceManager的服务节点 -->
<name>yarn.resourcemanager.hostname</name>
<value>master1</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master1:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
<description>该节点上YARN可使用的物理内存总量,默认是8192(MB)</description>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>3072</value>
<description>单个容器/调度器可申请的最少物理内存量,提示物理内存溢出,提高这个值</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>默认配置地址:http://hadoop.apache.org/docs/r2.7.5/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
(五)配置slaves
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/slavesslave1
slave2
slave3slaves文件中配置的是DataNode的所在节点服务
(六)配置hadoop-env
修改hadoop-env.sh文件的JAVA_HOME环境变量,操作如下:
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/hadoop-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_131(七)配置yarn-env
修改yarn-env.sh文件的JAVA_HOME环境变量,操作如下:
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/yarn-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_131(八)配置mapred-env
修改mapred-env.sh文件的JAVA_HOME环境变量,操作如下:
$ vi /home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop/mapred-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_131(九)将master1中配置好的hadoop分别远程拷贝至maser2、slave1 、slave2、slave3服务器中
$ scp -r /home/hadoop/app/hadoop hadoop@master2:/home/hadoop/app/
$ scp -r /home/hadoop/app/hadoop hadoop@slave1:/home/hadoop/app/
$ scp -r /home/hadoop/app/hadoop hadoop@slave2:/home/hadoop/app/
$ scp -r /home/hadoop/app/hadoop hadoop@slave3:/home/hadoop/app/集群测试
hdfs测试
(一)在master1节点中初始化Hadoop集群
$ hadoop namenode -format(二)启动Hadoop集群
$ start-dfs.sh
$ start-yarn.sh(三)验证集群是否成功
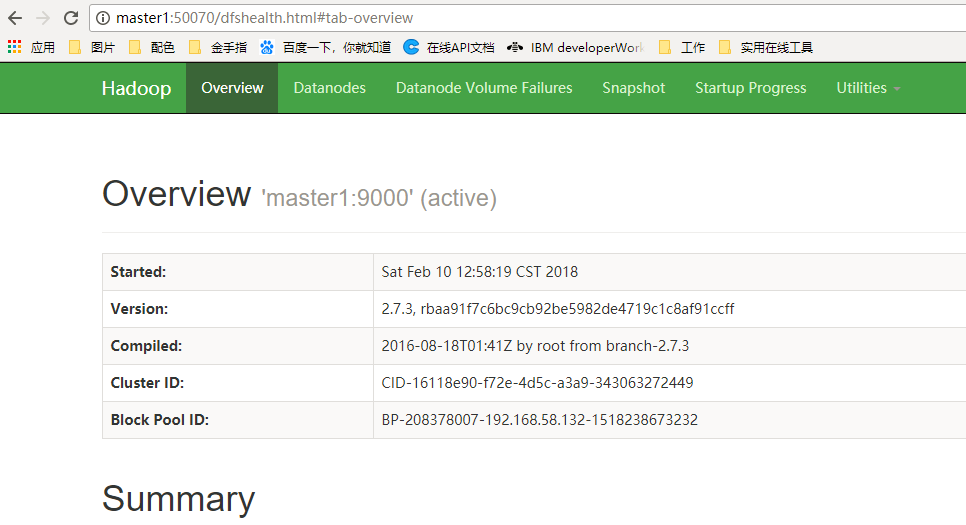
浏览器中访问50070的端口,如下证明集群部署成功
节点状态地址:master1:50070
yarn资源地址:master1:8088
mapreduce测试
(一)新建hdfs文件夹
hadoop fs -mkdir /input(二)新建测试文件,输入一些英文字母即可
vi word_test.txt(三)将 word_test.txt
hadoop fs -put /home/hadoop/app/hadoop/hadoop-2.7.5/share/hadoop/mapreduce/word_test.txt /input(四)进入 wordcount测试脚本路径
cd /home/hadoop/app/hadoop/hadoop-2.7.5/share/hadoop/mapreduce(五)运行hadoop wordcount测试脚本
hadoop jar hadoop-mapreduce-examples-2.7.5.jar wordcount /input/word_test.txt /output注意:/output 不能在hdfs上存在
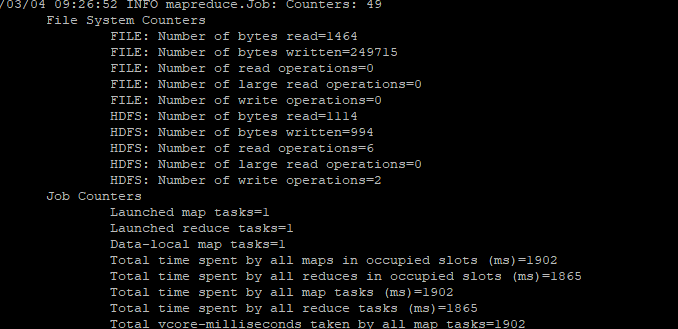
(六)运行成功
(七)查看结果
hadoop fs -cat /output/part-r-00000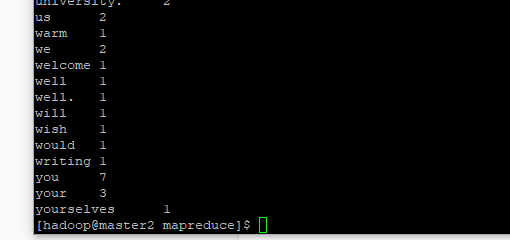
Hadoop安装注意事项
一、需要打开所有服务器的端口,保证机器之间的互通,若集群无法启动,首先查看防火墙、端口连接等情况
二、hadoop namenode -format HDFS初始化命令会清楚文件系统,慎用
三、若使用了HDFS文件格式化的命令,需要在五台机器上,重新使用hadoop创建文件的命令,分别创建文件
mkdir -p /home/hadoop/app/hadoop/{tmp,hdfs/{data,name}}Hadoop安装(HA高可用)
概要
在Hadoop 2.0.0之前,一个Hadoop集群只有一个NameNode,那么NameNode就会存在单点故障的问题。幸运的是Hadoop 2.0.0之后解决了这个问题,即支持NameNode的HA高可用。NameNode的高可用是通过集群中冗余两个NameNode,并且这两个NameNode分别部署到不同的服务器中,其中一个NameNode处于Active状态,另外一个处于Standby状态,如果主NameNode出现故障,那么集群会立即切换到另外一个NameNode来保证整个集群的正常运行。
Zookeeper安装(版本3.6.0)
| NN | DN | ZK | ZKFC | JN | |
| master1 | √ | √ | |||
| master2 | √ | √ | |||
| slave1 | √ | √ | √ | ||
| slave2 | √ | √ | √ | ||
| slave3 | √ | √ | √ |
注:Hadoop版本: Hadoop 2.7.5,与前文的hadoop一样
NN(NameNode 名称节点)、DN(DataNode 数据节点)、ZK(Zookeeper)、ZKFC(ZKFailoverController)、JN(JournalNode 元数据共享节点)、RM(ResourceManager 资源管理器)、DM(DataManager 数据节点管理器)开始安装
首先在slave1中安装zookeeper
(一)解压zookeeper安装包
tar -zxvf apache-zookeeper-3.6.0-bin.tar.gz(二)进入zookeeper conf目录
cd zookeeper-3.6.0/conf(三)重命名文件
cp zoo_sample.cfg zoo.cfg(四)修改zoo.cfg配置文件
vim zoo.cfg 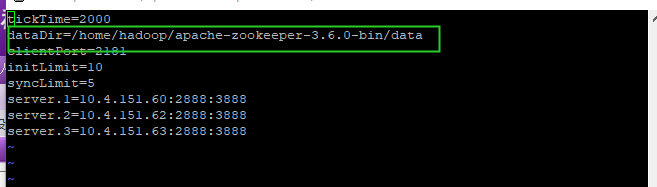
上面红色框住的内容即是我们修改的内容:
①、tickTime:基本事件单元,这个时间是作为Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,每隔tickTime时间就会发送一个心跳;最小 的session过期时间为2倍tickTime
②、dataDir:存储内存中数据库快照的位置,除非另有说明,否则指向数据库更新的事务日志。注意:应该谨慎的选择日志存放的位置,使用专用的日志存储设备能够大大提高系统的性能,如果将日志存储在比较繁忙的存储设备上,那么将会很大程度上影像系统性能。
③、client:监听客户端连接的端口。
④、initLimit:允许follower连接并同步到Leader的初始化连接时间,以tickTime为单位。当初始化连接时间超过该值,则表示连接失败。
⑤、syncLimit:表示Leader与Follower之间发送消息时,请求和应答时间长度。如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
⑥、server.A=B:C:D
A:其中 A 是一个数字,表示这个是服务器的编号;
B:是这个服务器的 ip 地址;
C:Leader选举的端口;
D:Zookeeper服务器之间的通信端口。
我们需要修改的第一个是 dataDir ,在指定的位置处创建好目录。
第二个需要新增的是 server.A=B:C:D 配置,其中 A 对应下面我们即将介绍的myid 文件。B是集群的各个IP地址,C:D 是端口配置。
(五)在 上一步 dataDir 指定的目录下,创建 myid 文件
然后在该文件添加上一步 server 配置的对应 A 数字。
比如我们上面的配置:
dataDir=/home/hadoop/apache-zookeeper-3.6.0-bin/data然后下面配置是:
server.1=ip1:2888:3888
server.2=ip2:2888:3888
server.3=ip3:2888:3888那么就必须在10.4.151.60 机器的的/home/hadoop/apache-zookeeper-3.6.0-bin/data 目录下创建 myid 文件,然后在该文件中写上 1即可。

后面的机器依次在相应目录创建myid文件,写上相应配置数字即可。
(六)环境变量配置
#set zookeeper environment
export ZK_HOME=/home/hadoop/apache-zookeeper-3.6.0-bin
export PATH=$PATH:$ZK_HOME/bin(七)环境变量生效
source /etc/profle启动命令:
zkServer.sh start停止命令:
zkServer.sh stop重启命令:
zkServer.sh restart查看集群节点状态:
zkServer.sh status成功后状态

注意事项:1、三个节点需要同时起zk的任务,在全部任务起来之后,才能查看节点状态,不然会报错
2、推荐使用现在的3.6.0的版本,因为其他版本可能存在版本问题,比如3.4.9
Hadoop-HA模式安装
HA模式需要在前文hadoop安装成功之后,Zookeeper安装之后之后,才能够去配置和部署。
配置修改
(一)修改hdfs-site.xml,内容如下:
<configuration>
<!--HDFS HA的逻辑服务名称配置-->
<property>
<name>dfs.nameservices</name>
<value>masters</value>
</property>
<!--NameNode的唯一标识服务名,注意这里namenodes.masters中的masters必须是上面的dfs.nameservices中的逻辑服务名,下面同理-->
<property>
<name>dfs.ha.namenodes.masters</name>
<value>master1,master2</value>
</property>
<!--NameNode的rpc监听地址-->
<property>
<name>dfs.namenode.rpc-address.masters.master1</name>
<value>master1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.masters.master2</name>
<value>master2:8020</value>
</property>
<!--NameNode的http地址配置-->
<property>
<name>dfs.namenode.http-address.masters.master1</name>
<value>master1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.masters.master2</name>
<value>master2:50070</value>
</property>
<!--NameNode的edits文件的共享地址配置,及JournalNodes的节点配置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave1:8485;slave2:8485;slave3:8485/masters</value>
</property>
<!--指定JournalNode在本地磁盘存放数据的位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-HA/data/journal</value>
</property>
<!--配置将由DFS客户端使用的Java类的名称,以确定哪个NameNode当前正在服务于客户端请求-->
<property>
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--HA切换时的免密登录的秘钥访问路径配置-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!--开启NameNode失败自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置HDFS的DataNode的备份数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/app/hadoop-HA/data/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/app/hadoop-HA/data/hdfs/data</value>
</property>
<!--HDFS访问是否开启权限控制-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>(二)修改core-site.xml文件,内容如下:
<configuration>
<!--这里的masters值需与hdfs-site.xml中的dfs.nameservices配置项的值相同-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://masters</value>
</property>
<!-- 配置hadoop的临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-HA/data/tmp</value>
</property>
<!--Zookeeper服务配置-->
<property>
<name>ha.zookeeper.quorum</name>
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
<!--表示客户端连接服务器失败尝试的次数-->
<property>
<name>ipc.client.connect.max.retries</name>
<value>10</value>
</property>
<!--表示客户端每次连接服务器需要等待的毫秒数,默认1s,如不配置则使用start-dfs.sh启动可能会导致NameNode连接JournalNode超时,如果单独一个个节点启动则无需此配置项-->
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
</property>
</configuration>(三)修改slaves文件,内容如下:
slave1
slave2
slave3(四)创建文件夹,五台机器都需要建立
mkdir -p /home/hadoop/app/hadoop-HA/data/tmp
mkdir -p /home/hadoop/app/hadoop-HA/data/hdfs/data
mkdir -p mkdir -p /home/hadoop/app/hadoop-HA/data/hdfs/name
/home/hadoop/app/hadoop-HA/data/journal初始化集群和启动
(一)分别启动三个JournalNode
hadoop-daemon.sh start journalnode(二)在其中一个NameNode节点中初始化NameNode,这里选择master1上的NameNode
hdfs namenode -format(三)启动第2步初始化好的NameNode服务
hadoop-daemon.sh start namenode(四)在master2服务器中运行下面命令来同步master1上的NameNode的元数据
hdfs namenode -bootstrapStandby(五)在其中一个NameNode节点中初始化ZKFC的状态,这里选择master1上的NameNode
hdfs zkfc -formatZK(六)启动Hadoop的HA集群
start-dfs.sh测试是否切换成功
(一)通过浏览器中查看 http:master1:50070 和 http:master2:50070 可以确定哪个NameNode处理激活状态
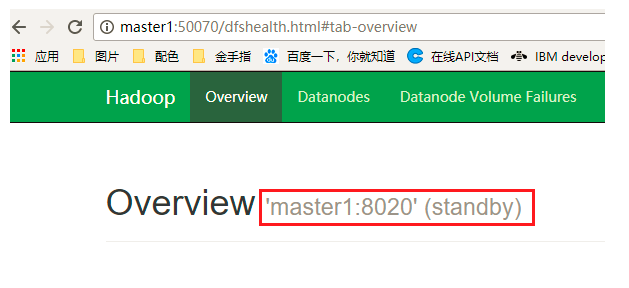
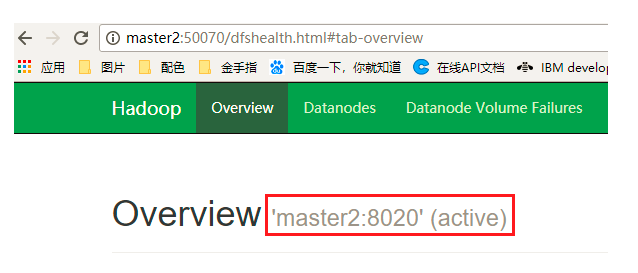
(二)如上图master2的状态为active,则通过kill杀死master2中的NameNode进程,然后查看master1中的NameNode是否由standby状态转换为了active状态,是的话说明切换成功!
注:在测试Hadoop的HA切换中,发现切换失败,在kill掉NameNode的节点中查看日志:
vi hadoop-2.7.5/logs/hadoop-hadoop-zkfc-master2.log
发现报错:PATH=$PATH:/sbin:/usr/sbin fuser -v -k -n tcp 8020 via ssh: bash: fuser: 未找到命令
解决办法:缺少psmisc依赖包,每个NameNode节点服务器上安装即可:
yum install psmisc
Hive安装
在安装Hive之前,需要保证你的Hadoop集群已经正常启动,且是在hadoop用户下进行安装,用root权限安装会出现权限问题
另外,需要提前安装mysql数据库
开始安装
(一)解压Hive安装包
tar zxvf apache-hive-2.3.8-bin.tar.gz -C /home/hadoop(二)配置hive环境变量
vi /etc/profile#HIVE
export HIVE_HOME=/home/hadoop/hive-2.3.8
export HIVE_CONF_DIR=$HIVE_HOME/conf
PATH=$HIVE_HOME/bin:$PATH(三)生效配置环境
source /etc/profile(四)创建hive-site.xml
cd $HIVE_CONF_DIR
cp hive-default.xml.template hive-site.xml(五)由于hive-site.xml目录有如下默认配置
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
<description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. </description>
</property>(六)创建相应目录
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -chmod -R 777 /user/hive/warehouse
hdfs dfs -mkdir -p /tmp/hive
hdfs dfs -chmod -R 777 /tmp/hive
hdfs dfs -ls /配置Hive本地临时目录
将 hive-site.xml 文件中的 ${system:java.io.tmpdir} 替换为hive的本地临时目录,例如我使用的是 /usr/local/hive-2.3.8/tmp ,如果该目录不存在,需要先进行创建,并且赋予读写权限。
cd $HIVE_HOME
mkdir tmp/
chmod -R 777 tmp/
cd $HIVE_CONF_DIR
vim hive-site.xml(八)在vim命令模式下执行如下命令完成替换
:%s#${system:java.io.tmpdir}#/usr/local/hive-2.3.8/tmp#g将原来配置
<property>
<name>hive.exec.local.scratchdir</name>
<value>${system:java.io.tmpdir}/${system:user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>替换为:
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/hive-2.3.8/tmp/${system:user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>配置Hive用户名
将 hive-site.xml 文件中的 ${system:user.name} 替换为操作Hive的账户的用户名,例如我的是 hadoop 。
在vim命令模式下执行如下命令完成替换:
:%s#${system:user.name}#hadoop#g将初始配置
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/hive-2.3.8/tmp/${system:user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>替换为:
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/hive-2.3.8/tmp/hadoop</value>
<description>Local scratch space for Hive jobs</description>
</property>修改Hive数据库配置
在 hive-site.xml 中,与Hive数据库相关的配置有如下几个:
| 属性名称 | 描述 |
| javax.jdo.option.ConnectionDriverName | 数据库的驱动类名称 |
| javax.jdo.option.ConnectionURL | 数据库的JDBC连接地址 |
| javax.jdo.option.ConnectionUserName | 连接数据库所使用的用户名 |
| javax.jdo.option.ConnectionPassword | 连接数据库所使用的密码 |
将原始配置改为mysql数据库配置
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master1:3306/hive?createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root@123</value>
<description>password to use against metastore database</description>
</property>此外,还需要将MySQL的驱动包拷贝到Hive的lib目录下:
cp /home/hadoop/mysql-connector-java-5.1.43.jar $HIVE_HOME/lib/配置hive-env.sh
cd $HIVE_CONF_DIR
cp hive-env.sh.template hive-env.sh
vim hive-env.sh将hive-env.sh内容设置为如下:
export HADOOP_HOME=/home/hadoop/app/hadoop/hadoop-2.7.5
export HIVE_CONF_DIR=/home/hadoop/hive-2.3.8/conf
export HIVE_AUX_JARS_PATH=/home/hadoop/hive-2.3.8/libHive数据库初始化
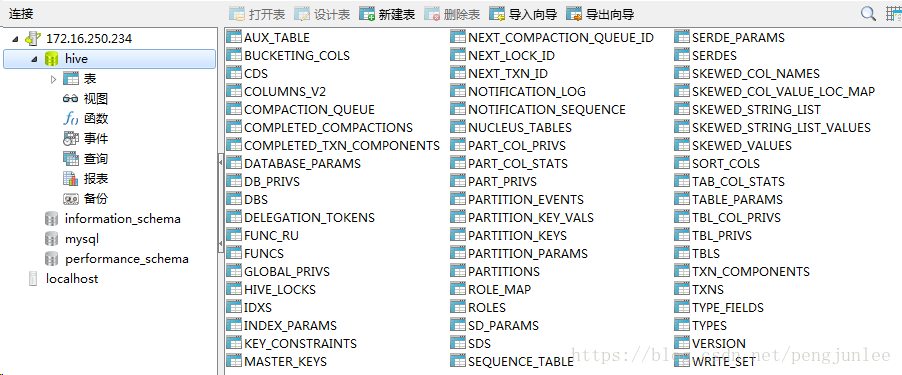
cd $HIVE_HOME/binschematool -initSchema -dbType mysql数据库初始化完成之后,会在MySQL数据库里生成如下metadata表用于存储Hive的元数据信息
启动Hive
cd $HIVE_HOME/bin
./hive测试Hive
在Hive所在主机上新建一个 user_sample.txt 用来保存测试数据,内容如下:
1. 0612,Terry,M,22
2. 0613,Sherry,F,22
3. 0614,Smith,M,25
4. 0615,Tracy,F,24
5. 0616,Lucy,F,19
6. 0617,Sherry,F,23执行新建库、表以及导入数据测试
hive> create database user_test;
OK
Time taken: 5.633 seconds
# 切换数据库
hive> use user_test;
OK
Time taken: 0.021 seconds
# 创建数据表测试
hive> create table user_sample
(
user_num bigint,
user_name string,
user_gender string,
user_age int
) row format delimited fields terminated by ',';
OK
Time taken: 0.645 seconds
# 从本地主机上加载数据到hive
hive> load data local inpath '/home/hadoop/user_sample.txt' into table user_sample;
Loading data to table user_test.user_sample
OK
Time taken: 0.589 seconds
# 查看加载内容
hive> select * from user_sample;
OK
612 Terry M 22
613 Sherry F 22
614 Smith M 25
615 Tracy F 24
616 Lucy F 19
617 Sherry F 23
Time taken: 0.173 seconds, Fetched: 6 row(s)DataX安装
开始安装
(一)确保环境依赖满足条件
Linux
JDK(1.8以上,推荐1.8)
Python(推荐Python2.6.X或者python2.7也可以)
Apache Maven 3.x (Compile DataX)(二)下载datax安装包
https://github.com/alibaba/DataX/blob/master/userGuid.md
(三)解压文件夹
tar -zxvf datax.tar.gz -C /opt/datax/(四)进入bin目录,开始自检
python datax.py ../job/job.json示例
(一)mysql2hive的配置
{
"job": {
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"user_id",
"user_name",
"phone",
"id_card",
"company_no",
"del_flag",
"create_by",
"create_time",
"update_by",
"update_time"
],
"connection": [{
"jdbcUrl": [
"jdbc:mysql://10.4.151.21:3307/test"
],
"table": [
"biz_user"
]
}],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [{
"name": "user_id",
"type": "BIGINT"
},
{
"name": "user_name",
"type": "STRING"
},
{
"name": "phone",
"type": "STRING"
},
{
"name": "id_card",
"type": "STRING"
},
{
"name": "company_no",
"type": "STRING"
},
{
"name": "del_flag",
"type": "STRING"
},
{
"name": "create_by",
"type": "STRING"
},
{
"name": "create_time",
"type": "TIMESTAMP"
},
{
"name": "update_by",
"type": "STRING"
},
{
"name": "update_time",
"type": "TIMESTAMP"
}
],
"defaultFS": "hdfs://master1:8020",
"fieldDelimiter": "\t",
"fileName": "20200311",
"fileType": "text",
"path": "/user/hive/warehouse/finance/biz_user",
"writeMode": "append"
}
}
}],
"setting": {
"speed": {
"channel": "1"
}
}
}
}(二)在datax/bin 目录下运行
python datax.py mysql2hive.json(三) HA模式下同步配置
在同步任务的json配置中加入如下配置,可解决datax只能在namenode(active)进行同步的问题
"defaultFS": "hdfs://masters",
"hadoopConfig":{
"dfs.nameservices": "masters",
"dfs.ha.namenodes.masters": "master1,master2",
"dfs.namenode.rpc-address.masters.master1": "master1:8020",
"dfs.namenode.rpc-address.masters.master2": "master2:8020",
"dfs.client.failover.proxy.provider.masters": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},Mysql安装
开源资源包
📎apache-zookeeper-3.6.0-bin.tar.gz
SQuirrel客户端安装(windowa)
开始安装
(一)下载客户端安装包
(二)安装好客户端
开始配置
Hive驱动配置
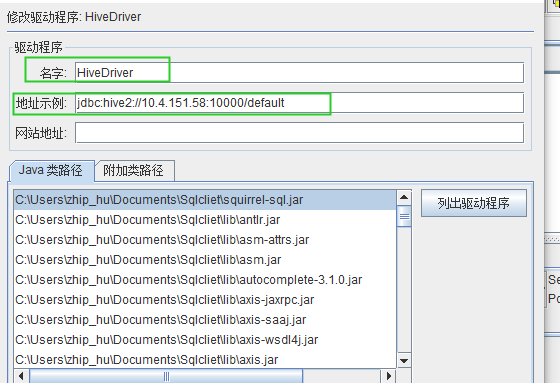
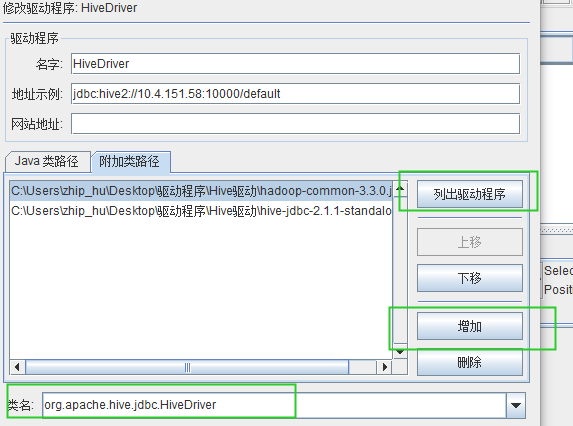
(一)新建驱动程序
注意:名字:随便起
地址示例:按安装hive的配置进行配置
(二)附加类路径
1、增加两个驱动包
2、列出驱动程序会把hive的驱动列出来
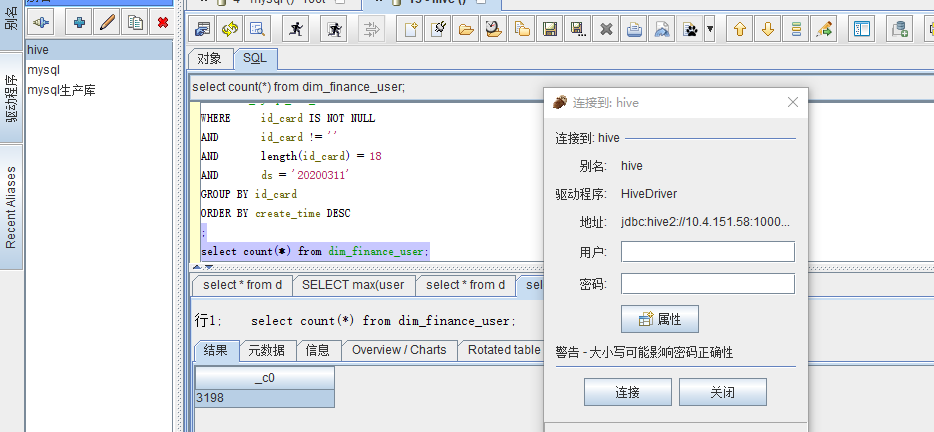
(三)连接
1、确保Hive已经运行起了服务 hiveservece2,具体可以到/hive/bin/路径下去启动
2、用户、密码不用输入,因为之前在配置的时候用"*"代替,表示空值;输入其他字符后会报错
3、完成连接
使用hive client
(一)确定使用哪个数据库(如 use finance;)
(二)运行sql时如果报错,/tmp 路径没有权限,解决方法如下
vi /ect/profile
在 profile中 增加如下配置:export HADOOP_USER_NAME=hadoop
source /ect/profile 生效配置,对集群所有机器都运行
##下列语句仅master上运行就可以##
hdfs fs -chmod -R 777 /tmpDophinScheduler安装
用户权限配置
# 配置sudo免密
sed -i '$ahadoop ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers
# 修改目录权限,使得部署用户对dolphinscheduler-bin目录有操作权限
chown -R hadoop:hadoop dolphinscheduler-bin
注意:
- 因为任务执行服务是以 sudo -u {linux-user} 切换不同linux用户的方式来实现多租户运行作业,所以部署用户需要有 sudo 权限,而且是免密的。初学习者不理解的话,完全可以暂时忽略这一点
- 如果发现/etc/sudoers文件中有"Default requiretty"这行,也请注释掉
- 如果用到资源上传的话,还需要给该部署用户分配操作`本地文件系统或者HDFS或者MinIO`的权限数据库初始化
- 进入数据库,默认数据库是PostgreSQL,如选择MySQL的话,后续需要添加mysql-connector-java驱动包到DolphinScheduler的lib目录下
mysql -uroot -p- 进入数据库命令行窗口后,执行数据库初始化命令,设置访问账号和密码。注: {user} 和 {password} 需要替换为具体的数据库用户名和密码
mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'%' IDENTIFIED BY '{password}';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'localhost' IDENTIFIED BY '{password}';
mysql> flush privileges;- 创建表和导入基础数据
-
- 修改 conf 目录下 datasource.properties 中的下列配置
vi conf/datasource.properties-
- 如果选择 MySQL,请注释掉 PostgreSQL 相关配置(反之同理), 还需要手动添加 [ mysql-connector-java 驱动 jar ] 包到 lib 目录下,这里下载的是mysql-connector-java-5.1.47.jar,然后正确配置数据库连接相关信息
# postgre
#spring.datasource.driver-class-name=org.postgresql.Driver
#spring.datasource.url=jdbc:postgresql://localhost:5432/dolphinscheduler
# mysql
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://xxx:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true 需要修改ip,本机localhost即可
spring.datasource.username=xxx 需要修改为上面的{user}值
spring.datasource.password=xxx 需要修改为上面的{password}值-
- 修改并保存完后,执行 script 目录下的创建表及导入基础数据脚本
sh script/create-dolphinscheduler.sh注意: 如果执行上述脚本报 ”/bin/java: No such file or directory“ 错误,请在/etc/profile下配置 JAVA_HOME 及 PATH 变量
修改运行参数
- 修改 conf/env 目录下的
dolphinscheduler_env.sh环境变量(以相关用到的软件都安装在/opt/soft下为例)
export HADOOP_HOME=/home/hadoop/app/hadoop/hadoop-2.7.5
export HADOOP_CONF_DIR=/home/hadoop/app/hadoop/hadoop-2.7.5/etc/hadoop
export JAVA_HOME=/home/hadoop/jdk1.8.0_271
export HIVE_HOME=/home/hadoop/hive-2.3.8
export DATAX_HOME=/home/hadoop/datax/bin/datax.py
export PATH=$HADOOP_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH:$DATAX_HOME:$PATH注: 这一步非常重要,例如 JAVA_HOME 和 PATH 是必须要配置的,没有用到的可以忽略或者注释掉;如果找不到dolphinscheduler_env.sh, 请运行 ls -a- 将jdk软链到/usr/bin/java下(仍以 JAVA_HOME=/opt/soft/java 为例)
sudo ln -s /home/hadoop/jdk1.8.0_271/bin/java /usr/bin/java修改一键部署配置文件 conf/config/install_config.conf中的各参数,特别注意以下参数的配置
# 这里填 mysql or postgresql
dbtype="mysql"
# 数据库连接地址
dbhost="localhost:3306"
# 数据库名
dbname="dolphinscheduler"
# 数据库用户名,此处需要修改为上面设置的{user}具体值
username="xxx"
# 数据库密码, 如果有特殊字符,请使用\转义,需要修改为上面设置的{password}具体值
password="xxx"
#Zookeeper地址,单机本机是localhost:2181,记得把2181端口带上
zkQuorum="localhost:2181"
#将DS安装到哪个目录,如: /opt/soft/dolphinscheduler,不同于现在的目录
installPath="/opt/soft/dolphinscheduler"
#使用哪个用户部署,使用第3节创建的用户
deployUser="hadoop"
# 邮件配置,以qq邮箱为例
# 邮件协议
#mailProtocol="SMTP"
# 邮件服务地址
#mailServerHost="smtp.qq.com"
# 邮件服务端口
#mailServerPort="25"
# mailSender和mailUser配置成一样即可
# 发送者
#mailSender="xxx@qq.com"
# 发送用户
#mailUser="xxx@qq.com"
# 邮箱密码
#mailPassword="xxx"
# TLS协议的邮箱设置为true,否则设置为false
#starttlsEnable="true"
# 开启SSL协议的邮箱配置为true,否则为false。注意: starttlsEnable和sslEnable不能同时为true
#sslEnable="false"
# 邮件服务地址值,参考上面 mailServerHost
#sslTrust="smtp.qq.com"
# 业务用到的比如sql等资源文件上传到哪里,可以设置:HDFS,S3,NONE,单机如果想使用本地文件系统,请配置为HDFS,因为HDFS支持本地文件系统;如果不需要资源上传功能请选择NONE。强调一点:使用本地文件系统不需要部署hadoop
resourceStorageType="HDFS"
# 这里以保存到本地文件系统为例
#注:但是如果你想上传到HDFS的话,NameNode启用了HA,则需要将hadoop的配置文件core-site.xml和hdfs-site.xml放到conf目录下,本例即是放到/opt/dolphinscheduler/conf下面,并配置namenode cluster名称;如果NameNode不是HA,则修改为具体的ip或者主机名即可
defaultFS="hdfs://localhost:8020" #hdfs://{具体的ip/主机名}:8020
# 如果没有使用到Yarn,保持以下默认值即可;如果ResourceManager是HA,则配置为ResourceManager节点的主备ip或者hostname,比如"192.168.xx.xx,192.168.xx.xx";如果是单ResourceManager请配置yarnHaIps=""即可
# 注:依赖于yarn执行的任务,为了保证执行结果判断成功,需要确保yarn信息配置正确。
yarnHaIps="localhost"
# 如果ResourceManager是HA或者没有使用到Yarn保持默认值即可;如果是单ResourceManager,请配置真实的ResourceManager主机名或者ip
singleYarnIp="yarnIp1"
# 资源上传根路径,支持HDFS和S3,由于hdfs支持本地文件系统,需要确保本地文件夹存在且有读写权限
resourceUploadPath="/dolphinscheduler"
# 具备权限创建resourceUploadPath的用户
hdfsRootUser="hadoop"
#在哪些机器上部署DS服务,本机选localhost
ips="localhost"
#ssh端口,默认22
sshPort="22"
#master服务部署在哪台机器上
masters="localhost"
#worker服务部署在哪台机器上,并指定此worker属于哪一个worker组,下面示例的default即为组名
workers="localhost:hadoop"
#报警服务部署在哪台机器上
alertServer="master1"
#后端api服务部署在在哪台机器上
apiServers="localhost"注:如果打算用到资源中心功能,请执行以下命令:
sudo mkdir /data/dolphinscheduler
sudo chown -R dolphinscheduler:dolphinscheduler /data/dolphinscheduler一键部署
- 切换到部署用户,执行一键部署脚本
sh install.sh
注意:
第一次部署的话,在运行中第3步`3,stop server`出现5次以下信息,此信息可以忽略
sh: bin/dolphinscheduler-daemon.sh: No such file or directory- 脚本完成后,会启动以下5个服务,使用
jps命令查看服务是否启动(jps为java JDK自带)
MasterServer ----- master服务
WorkerServer ----- worker服务
LoggerServer ----- logger服务
ApiApplicationServer ----- api服务
AlertServer ----- alert服务如果以上服务都正常启动,说明自动部署成功
部署成功后,可以进行日志查看,日志统一存放于logs文件夹内
logs/
├── dolphinscheduler-alert-server.log
├── dolphinscheduler-master-server.log
|—— dolphinscheduler-worker-server.log
|—— dolphinscheduler-api-server.log
|—— dolphinscheduler-logger-server.log登录系统
- 访问前端页面地址,接口ip(自行修改) http://10.4.151.58:12345/dolphinscheduler
启停服务
- 一键停止集群所有服务
sh ./bin/stop-all.sh - 一键开启集群所有服务
sh ./bin/start-all.sh - 启停Master
sh ./bin/dolphinscheduler-daemon.sh start master-server
sh ./bin/dolphinscheduler-daemon.sh stop master-server- 启停Worker
sh ./bin/dolphinscheduler-daemon.sh start worker-server
sh ./bin/dolphinscheduler-daemon.sh stop worker-server- 启停Api
sh ./bin/dolphinscheduler-daemon.sh start api-server
sh ./bin/dolphinscheduler-daemon.sh stop api-server- 启停Logger
sh ./bin/dolphinscheduler-daemon.sh start logger-server
sh ./bin/dolphinscheduler-daemon.sh stop logger-server- 启停Alert
sh ./bin/dolphinscheduler-daemon.sh start alert-server
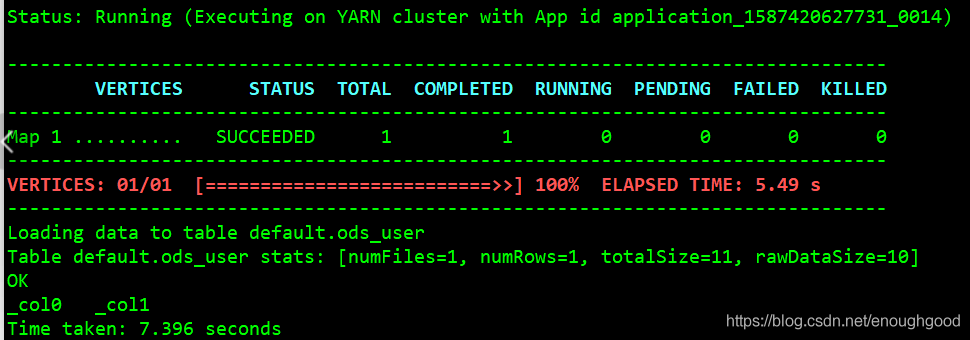
sh ./bin/dolphinscheduler-daemon.sh stop alert-server出现图中情况,说明引擎切换成功
集群停止、启动过程
停止集群过程
1. 登录10.4.151.58服务器
2. 切换hadoop用户:su – Hadoop 密码:hadoop
3. 在任意目录下,都可停止集群服务:sh stop-all.sh
4. 进入dolphinscheduler/bin 目录: cd /home/hadoop/dolphinscheduler-bin/bin
5. 在步骤3所处路径下,停止dolphinscheduler服务: sh stop-all.sh
6. jps 查看服务情况,若全部停止之后,jps显示无服务
7. 切换root用户:su – root 密码:root@123
8. 停止mysql服务:service mysql stop
启动集群过程
1. 分别登录60、62、63服务器,启动zk:zkServer.sh start,当三台服务器启动完成之后,成功后状态
注意事项:1、三个节点需要同时起zk的任务,在全部任务起来之后,才能查看节点状态,不然会报错
2. 登录10.4.151.58服务器,切换root用户
3. 启动mysql服务:service mysql start
4. 切换hadoop用户,启动hadoop集群:start-all.sh
5. 进入dolphinscheduler目录,启动dolphinscheduler服务:sh start-all.sh
6. jps查看服务














 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









